python下载音乐
不知从何时开始我们手机音乐app里的歌单,好多歌曲不是变灰了就是变成vip歌曲,普通用户只能试听几十秒,作为一名白嫖党怎么能忍,干脆撸起袖子自己动手把喜欢的歌曲全部保存下来。
- 咕米音乐网页版:https://music.migu.cn/v3
说句题外话我觉得咕米音乐这个网站真的挺良心的,个人很喜欢,几乎所有的音乐都可以无损播放。简直不要太友好。不像某些大厂吃相太难看了,试听只能普通音质,想要无损必须办会员,那渣音质还不如不听。关键是咕米音乐还能免费听周董的歌【笑】
打开咕米音乐首页,搜索自己喜欢的歌手进入他的主页,如下图:
点击播放一首音乐,页面进行跳转,右键F12打开开发者模式重新刷新页面,如图所示:
我们分析请求信息得出如下链接即为歌曲请求的api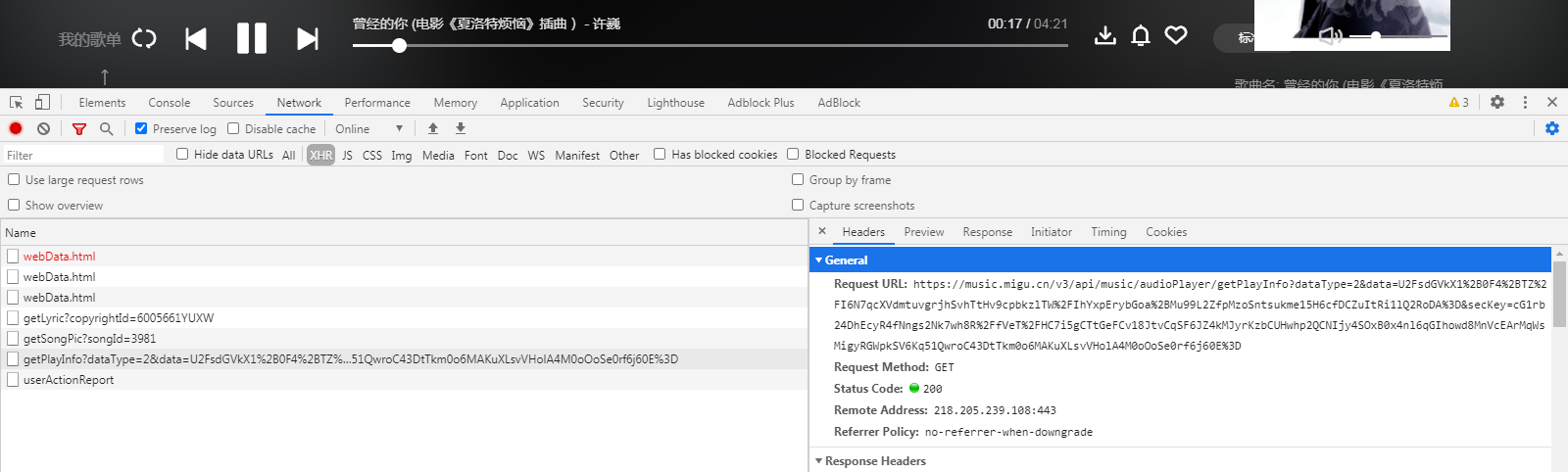
在response里便是服务端返回的歌曲信息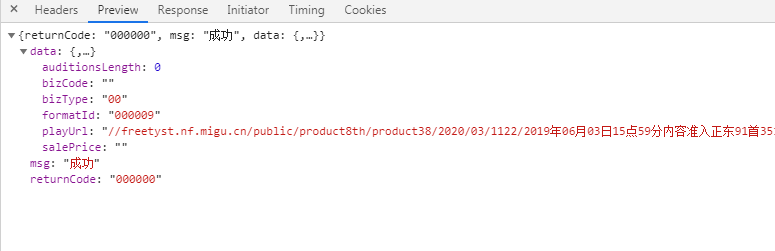
分析请求的参数,搜索参数名称有如下结果,很容易就定位到加密参数的生成位置
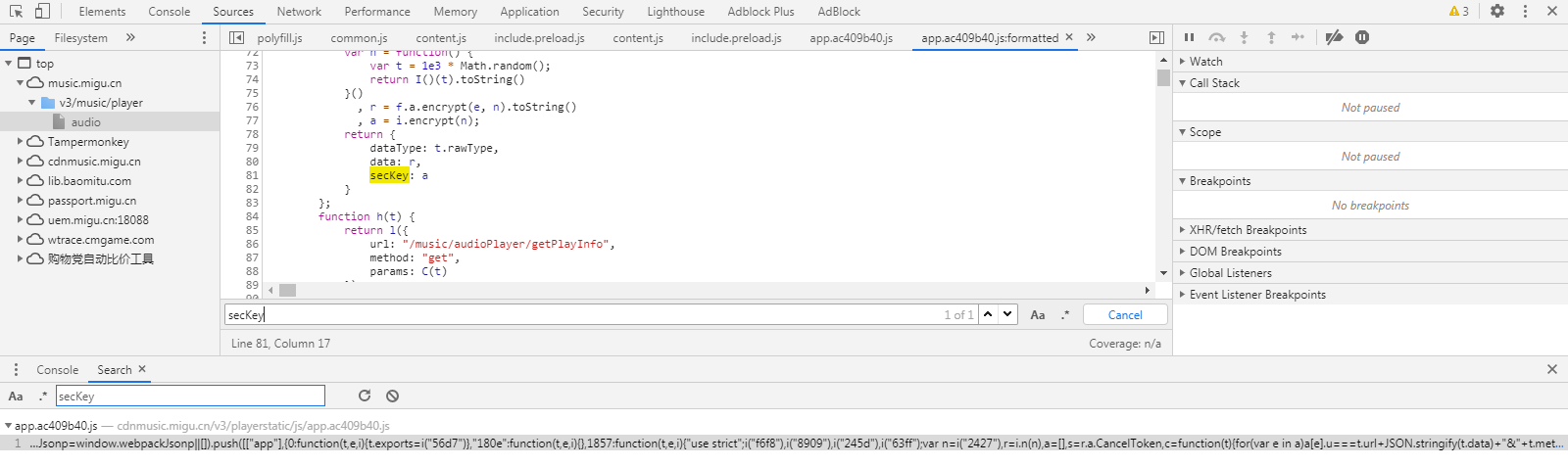
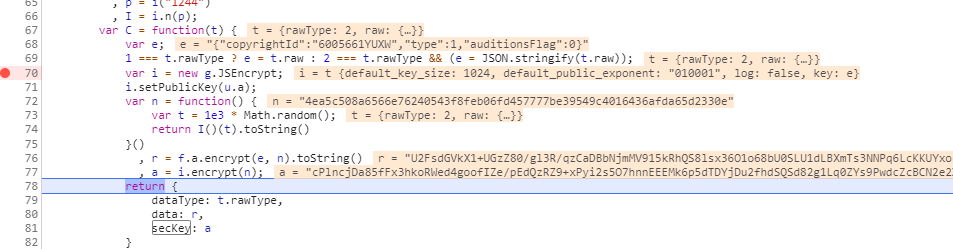
打个断点进行单步调试,变量e即为被加密的数据,经多番测试,其中copyrightId即歌曲的版权id;
type为音乐的音质类型,无损SQ type == 3,高质量HQ type == 2,普通音质 type == 1
auditionsFlag默认为0;变量n为固定值;变量 r、a即为我们提交的加密参数。
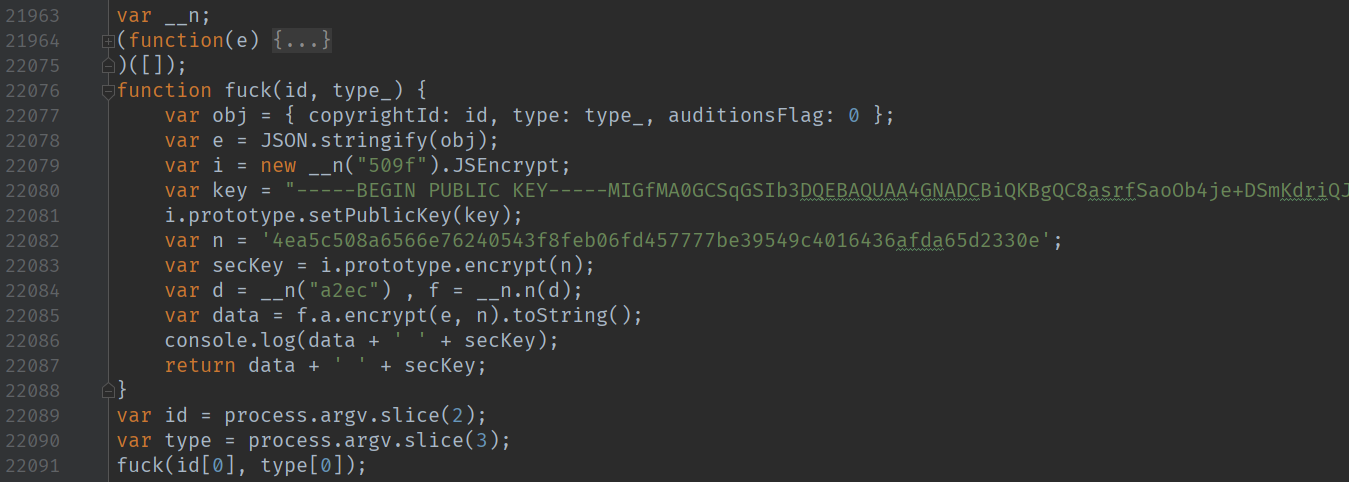
好了基本上分析完了,此处省略抠js代码过程。
三、具体实现
"""
===================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/8/25 0020 上午 12:08
FileName :migu_music.py
===================================
"""
import os
import requests
import warnings
from lxml import etree
from enum import Enum
from queue import Queue
import threading
warnings.filterwarnings('ignore')
class MusicType(Enum):
Normal = 1
HQ = 2
SQ = 3
class MiguMusic(object):
def __init__(self):
self.req_url = 'https://music.migu.cn/v3/api/music/audioPlayer/getPlayInfo?'
self.serach_api = 'https://music.migu.cn/v3/api/search/suggest?'
self.headers = {
'referer': 'https://music.migu.cn/v3/music/player/audio',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36',
}
self.headers_song = {
'Host': 'freetyst.nf.migu.cn',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
self.params = {
'dataType': 2,
'data': None,
'secKey': None
}
self.que = Queue()
self.song_list = []
def get_music_download_url(self, song_id, type = 3):
'''
获取歌曲下载链接
:param song_id: 歌曲copyrightId
:param type: 默认下载无损格式的音频
:return:
'''
try:
secKey = os.popen('Node fuck.js ' + f'{song_id} {type}').read().split(' ')
except:
print('error cannot create secKey')
return None
self.params['data'] = secKey[0]
self.params['secKey'] = secKey[1]
try:
response = requests.get(url = self.req_url, headers = self.headers, params = self.params, verify = False)
print(response.text)
if response.status_code == 200:
url = 'http:' + response.json()['data']['playUrl']
return url
except:
print('network error please try again...')
return None
def get_singer_or_music_id(self, keyword, type):
'''
获取歌手id或者歌曲id
:param keyword:
:param type: type == 1 keyword为歌手id,反之为歌曲id
:return:
'''
param = { 'keyword': keyword }
headers = {
'referer': 'https://music.migu.cn/v3?keyword=',
'Host': 'music.migu.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
try:
response = requests.get(url = self.serach_api, headers = headers, params =param, verify = False)
data = response.json()
return data['data']['singers'][0]['id'] if type == 1 else data['data']['songs'][0]['copyrightId']
except:
return None
def get_song_list(self, keyword, page = 1, type = 1):
'''
获取歌手主页歌曲信息
eg: https://music.migu.cn/v3/music/artist/559/song
:param keyword: 歌手名称或歌曲名称
:param page: 歌手主页,页码
:param type: type == 1,keyword为歌手名称、type == 2, keyword为歌曲名称
:return: None
'''
id = self.get_singer_or_music_id(keyword, type)
if not id or type == 2:
if id:
self.song_list.append([id, keyword, MusicType['SQ'].value])
return None
songs_api = 'https://music.migu.cn/v3/music/artist/{id}/song?page={page}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
url = songs_api.format(
id = id, page = page
)
try:
#歌手主页,获取歌曲:id、名称、音质
response = requests.get(url = url, headers = headers, verify = False)
html = etree.HTML(response.text)
ids = html.xpath('//div[@class="song-name J_SongName"]/a/@href')
titles = html.xpath('//div[@class="song-name J_SongName"]/a/@title')
types = html.xpath('//div[@class="song-name J_SongName"]/i/text()')
for _id, tit, typ in zip(ids, titles, types):
try:
__typ = MusicType[typ.upper()].value
except:
__typ = MusicType['Normal'].value
finally:
self.song_list.append([_id.split('/')[-1], tit, __typ])
#print(_id, tit, typ)
except Exception as err:
print(err)
def download_thread(self, path):
'''
下载线程
:param path: 下载保存的路径
:return:
'''
while not self.que.empty():
__d = self.que.get()
try:
resp = requests.get(url = __d[0], headers = self.headers_song, stream = True)
if resp.status_code == 200:
print(f'start downloading {__d[1]}')
file_path = os.path.join(path, f'{__d[1]}.flac')
with open(file_path, 'wb') as wf:
for data in resp.iter_content(1024):
if data:
wf.write(data)
print(f'the file {__d[1]} download complished...')
except:
print('download network error...')
def run(self, keyword, page = 1, type = 1):
'''
程序入口
:param keyword: 歌手名称或歌曲名称
:param page: 默认下载歌手主页第一页的所有歌曲
:param type: type == 1,keyword为歌手名称、type == 2, keyword为歌曲名称
:return:
'''
self.get_song_list(keyword, page, type)
if not self.song_list:
print('song list empty...')
return
for i in self.song_list:
if i and i[0]:
self.que.put((self.get_music_download_url(i[0], i[2]), i[1]))
# keyword为歌手,创建歌手文件夹,否则保存路径为当前目录下的music文件夹
path = os.path.join(os.getcwd(), keyword if type == 1 else 'music')
if not os.path.exists(path):
os.makedirs(path)
thread_list = []
for i in range(3):
t = threading.Thread(target = self.download_thread, args = (path, ))
t.setDaemon(True)
thread_list.append(t)
t.start()
[_.join() for _ in thread_list]
if __name__ == '__main__':
d = MiguMusic()
#d.run('许巍') #用歌手名下载
d.run('曾经的你', 1, 2)
由于js代码较长约莫2w余行,此处就不上传了,如果有需要的小伙伴评论区留言或者私信我也行。
以上代码仅供交流学习之用,切勿用作其它用途。
部分js代码:

By: GadyPu 博客地址:http://www.cnblogs.com/GadyPu/ 转载请说明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号