python爬取抖音短视频
好久也没写过博客了,距离上一写的博文到现在也过去了四年。这段时间Urumqi yq突然爆发,单位暂时也不让回。一个人宅着没事就刷刷抖音看看短视频,作为一位有故事的男人【狗头】,抖音推荐的视频还是挺符合个人口味的,于是就萌生了把这些好看的视频全部保存的想法。之前喜欢用一些免费的公众号小程序去下载无水印的视频,可是没过多久这些小程序不是失效就是需要变相付费下载,最为一名资深白嫖党【狗头】岂是能忍的,然后就各种查资料,一顿操作猛如虎后,也没有什么简便方法。还是自己写程序把,可是自从工作以来最多就用用office三件套,编程都荒废了,用python写个hello world都会把单词拼错【汗】,没关系我们可以学,大不了从头再来,个人自学、在B站上学、面向github编程学。以下省略千余字学习过程。
PS:本人也是编程新手写作此文纯当个人学习记录,代码只是满足个人需求,以下内容若有不严谨之处希望各位看官老爷们不吝啬赐教。
好了不废话了开始进入正题
- 获得抖音首页推荐视频信息然后下载视频(无水印)
- 获取某抖主发布的全部视频信息然后下载视频(无水印)
- 获取自己或他人喜欢视频的信息然后下载视频(无水印)
- windows环境下搭建好python编程环境,本人使用python3.8.3版本
- 好用的编辑器如pycharm、vscode等
- 安卓模拟器、或者实体机也行
- 抖音app本人使用抖音极速版(v10.8.0)
- https抓包工具charles(可以不用)、 mitmproxy [详情]
- 假设你已经在pc端和模拟器上配置好charles和mitmproxy证书,确保已经可以正常
抓取http及https数据包 - 一颗不厌其烦的心
mitmproxy is a free and open source interactive HTTPS proxy.
安装:pip install mitmproxy
安装后有3个命令行工具:mitmproxy, mitmdump, mitmweb
本文只使用mitmdump查看流量数据(请求与响应)、执行自定义脚本
在配置好mitmproxy之后,在控制台上输入mitmdump并在模拟器上打开抖音app,mitmdump会出现手机上的所有请求。经过一番分析实践,查找资料发现有如下三个api接口,分别请求用户发布的视频信息、
请求首页推荐视频信息,请求用户喜欢的视频的信息。
post_api = 'https://aweme-lq.snssdk.com/aweme/v1/aweme/post/......' feed_api = 'https://aweme-lq.snssdk.com/aweme/v2/feed/......' favo_api = 'https://aweme-lq.snssdk.com/aweme/v1/aweme/favorite/......'
然后这三个请求对应的response里面就是我们需要的内容,通过分析response我们发现post、favo
返回是json格式的数据包。feed返回的是protobuf的数据包。所以我们只需要在自定义的mitmproxy
脚本中根据app所以请求中的关键字获取相对应的response数据包即可。
通过分析获取到的数据包、然后问题出现了:json格式的数据包python很方便操作,主要是如何解析protobuf的数据包。
然后又经过一番各种Google,结果发现:protobuf 有一套自己的语法。不了解 Protobuf 协议语法和用法的话也无法反解数据。也就是说在没有那个抖音自定义的( .proto 文件)情况下,基本上是无法逆序列化解析。经过一番资料查找各种踩坑之后,借助工具,使用google提供的的protoc编译工具,这个工具提供反解析参数。这样就能获取protobuf数据包的大致信息。
protoc –decode_raw < douyin_feed.bin > 1.txt
我们可以对比解析前和解析后的数据对比。
解析前

解析后
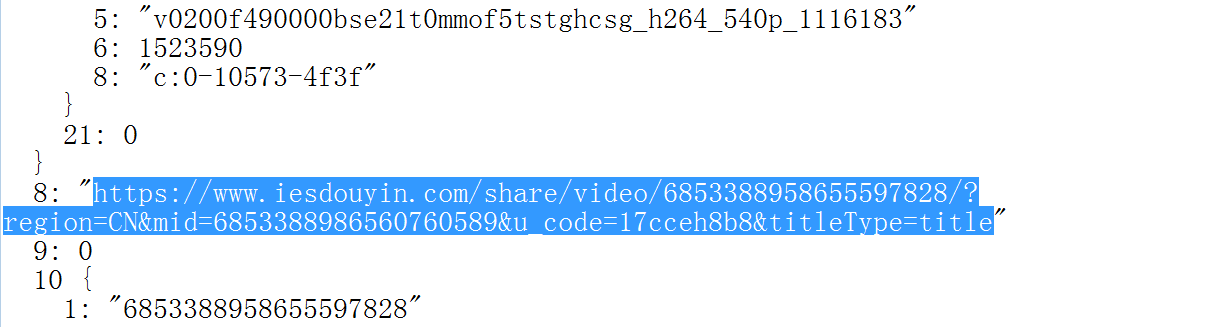
诸如此类的url地址。我们大致可以确定这很可能就是视频的分享地址,通过一番实践论证后果真如此,
那么,我们直接请求这些分享地址,在浏览器中打开按F12打开开发者模式,观察里面的ajax异步请求
的数据包,复制视频play_addr,再打开后发现播放的视频仍然是有水印的。然后又经过一番查找资料,
无果。好吧在网上找了个某第三方抖音分享视频下载网站,简单分析了它的接口,照着网站js加密参数 。后来偶然间发现了一篇帖子(不好意思
那部分自己也能正常获取请求结果,返回视频无水印下载地址
实在是想不起了。。。)大致意思是把里面链接playwm改成play,用手机端UA就能获得无水印地址了,试了一下果真如此。

经过上面的分析之后,我们开始码代码把。
然后问题出现了,由于mitmdump只是加载我们的脚本程序,如果把所有的代码都堆在脚本程序里
会造成脚本运行缓慢阻塞网络请求,开始想在脚本里写个多线程去执行耗时操作,然后就被教育了。
好吧那么把我们需要的信息写入数据库中,然后再写个程序读取数据库然后再去下载视频总没问题吧。
然后经过一番实践发现,获取的视频链接都有时效性,过段时间就会失效。那么就没有什么办法一遍
浏览视频,一边下载视频吗?答案是肯定的,后来想到用socket套接字在两个程序中进行通信。
用我们的脚本程序A获取视频信息用套接字发送到视频下载程序B,然后在程序B中开个线程用于接收
套接字信息,再开几个线程下载视频,程序B中不同线程之间用Queue()队列实现生产消费模式。
ok,主体框架搭好了,我们开始吧。talk is cheap show me the code…
"""
===================================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/8/ 0004 下午 12:03
FileName :mitmproxy_douyin_get_url_scripts.py
====================================================
"""
import mitmproxy.http
import json
import time
import struct
from socket import *
post_api = 'https://aweme-lq.snssdk.com/aweme/v1/aweme/post/'
feed_api = 'https://aweme-lq.snssdk.com/aweme/v2/feed/'
favo_api = 'https://aweme-lq.snssdk.com/aweme/v1/aweme/favorite/'
def send_data_to_server(header_dict, type):
'''
:param header_dict 获取到的数据包字典
:param type 原视频类型,feed,post,favo
与服务端通信发送数据,使用自定义协议
每次调用就创建一个套接字,用完就关闭
'''
tcp_client_socket = None
host = '127.0.0.1'
port = 9527
address = (host, port)
try:
tcp_client_socket = socket(AF_INET, SOCK_STREAM)
tcp_client_socket.connect(address)
if type == 'post' or type == 'favo':
json_data = json.dumps(header_dict)
json_bytes = json_data.encode('utf-8')
tcp_client_socket.send(struct.pack('i', len(json_bytes)))
tcp_client_socket.send(json_bytes)
#print(header_dict)
elif type == 'feed':
#先发送协议头用struct打包,包含要发送的数据大小
data_len = header_dict['size']
byte_arr = header_dict['content']
new_dict = {
'type': 'feed',
'size': data_len
}
json_data = json.dumps(new_dict)
json_bytes = json_data.encode('utf-8')
tcp_client_socket.send(struct.pack('i', len(json_bytes)))
tcp_client_socket.send(json_bytes)
chunk_size = 1024
start = 0
end = 1 * chunk_size
#print('new_dict...........................:', new_dict)
#发送protubuf数据,每次发送1024个字节
while True:
if data_len // chunk_size > 0:
read_bytes = byte_arr[start : end]
start = end
end += chunk_size
data_len -= chunk_size
tcp_client_socket.send(read_bytes)
#print(read_bytes)
else:
read_bytes = byte_arr[start : ]
tcp_client_socket.send(read_bytes)
break
except:
pass
if tcp_client_socket:
tcp_client_socket.close()
def get_local_time(create_time):
'''
:param create_time 原视频的发布时间,linux时间戳
:return: 返回年月日格式的日期
'''
time_local = time.localtime(int(create_time))
pub_date = time.strftime("%Y-%m-%d", time_local)
return pub_date
def response(flow: mitmproxy.http.HTTPFlow):
if flow.request.url.startswith(post_api) or flow.request.url.startswith(favo_api):
if flow.response.status_code == 200:
url_json = json.loads(flow.response.text)
if url_json and url_json['aweme_list']:
for aweme_list in url_json['aweme_list']:
aweme_id = aweme_list['aweme_id']
create_time = aweme_list['create_time']
create_time = get_local_time(create_time)
type = 'post' if flow.request.url.startswith(post_api) else 'favo'
header_dict = {
'type': type,
'aweme_id_create_time': aweme_id + '_' + create_time,
'nickname': aweme_list['author']['nickname'],
'play_url': aweme_list['video']['play_addr']['url_list'][0]
}
send_data_to_server(header_dict, type)
elif flow.request.url.startswith(feed_api):
if flow.response.status_code == 200:
procbuf = flow.response.content
feed_dict = {
'type': "feed",
'content': procbuf,
'size': len(procbuf)
}
#print('procbuf len................', len(procbuf))
send_data_to_server(feed_dict, 'feed')
addons = {
response()
}
4.2 辅助程序
"""
===================================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/8/ 0004 下午
FileName :parase_data.py
====================================================
"""
import os
import re
import json
import time
import requests
import random
import hashlib
from lxml import etree
import math
from decimal import Decimal
import warnings
warnings.filterwarnings('ignore')
'''
class Get_real_play_addr(object):
def __init__(self):
self.request_url = 'http://3g.gljlw.com/diy/ttxs_dy2.php?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
def parase_play_addr(self, url):
paly_url = ''
r = str(random.random())[2:]
s = hashlib.md5((url + '@&^' + r).encode()).hexdigest()
params = { 'url': url, 'r': r, 's': s }
try:
response = requests.get(url = self.request_url, headers = self.headers, params = params)
if response.status_code == 200:
content = response.content.decode('utf-8')
html = etree.HTML(content)
paly_url = html.xpath('//source/@src')[0]
if paly_url:
return paly_url
except:
print("network error cannot parase play_addr...")
return None
'''
# 打开protobuf文件,用正则表达式匹配出所有的分享链接地址
class Get_url_from_protobuf(object):
def __init__(self):
self.pat = r'(?<=\")https://www.iesdouyin.com/share/video/.*(?=\")'
self.command = r' --decode_raw <'
def get_url(self, exe_path, file_path):
try:
fp = os.popen(exe_path + self.command + file_path)
if fp:
src = fp.read()
fp.close()
url_list = re.findall(self.pat, src)
url_list = set(url_list)
return url_list
except:
print('decode protobuf failed...')
return None
def get_local_time(create_time):
time_local = time.localtime(int(create_time))
pub_date = time.strftime("%Y-%m-%d", time_local)
return pub_date
# 获取分享视频的下载地址
def Get_real_play_addr_by_web(aweme_id):
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; ZTE BA520 Build/MRA58K; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/55.0.2883.77 Mobile Safari/537.36'
}
api_url = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + aweme_id
response = requests.get(url = api_url, headers = headers, verify = False)
if response.status_code == 200:
response_json = response.json()
play_addr = response_json['item_list'][0]['video']['play_addr']['url_list'][0]
create_time = response_json['item_list'][0]['create_time']
create_time = get_local_time(create_time)
play_addr = play_addr.replace('playwm', 'play', 1)
# 返回下载地址和视频的发布时间
return (play_addr, create_time)
return None, None
def Get_file_size(e: int) -> str:
if e <= 0:
return ''
t = ["B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB"]
n = math.floor(math.log2(e) / math.log2(1024))
return str(Decimal(e / math.pow(1024, n)).quantize(Decimal("0.00"))) + t[n]
#'https://www.iesdouyin.com/share/video/6854870744690625805/?region=CN&mid=6854870758414781191'
#print(Get_real_play_addr_by_web("6854870744690625805"))
4.3 下载程序
"""
===================================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/8/ 0004 下午
FileName :douyin_video_downloads.py
====================================================
"""
import requests
import json
import os
import time
import sys
import threading
import struct
from queue import Queue
from socket import *
from parase_data import Get_url_from_protobuf
from parase_data import Get_real_play_addr_by_web
from parase_data import Get_file_size
import warnings
warnings.filterwarnings("ignore")
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; ZTE BA520 Build/MRA58K; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/55.0.2883.77 Mobile Safari/537.36'
}
que = Queue()
lock = threading.Lock()
chunk_size = 1024
#下载线程
def Download(path, index):
while True:
global que
if que.empty():
print("No.{} thread is waiting for data...".format(index))
data = que.get()
dir_name = data['type']
file_name = data['aweme_id_create_time']
dir_path = ''
if dir_name == 'feed':
play_url, create_time = Get_real_play_addr_by_web(data['aweme_id_create_time'])
if (not play_url) or (not create_time):
continue
file_name = file_name + '_' + create_time
dir_path = os.path.join(path, dir_name)
else:
dir_path = os.path.join(path, dir_name, data['nickname'])
play_url = data['play_url']
global lock
with lock:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
file_path = os.path.join(dir_path, file_name + '.mp4')
read_size = 0
with lock:
if os.path.exists(file_path):
continue
try:
response = requests.get(url = play_url, headers = headers, verify = False)
if response.status_code == 200:
#print(response.headers)
total_szie = int(response.headers['Content-Length'])
print("NO.{} thread is downloading... {} filesize:{}".format(index, data['aweme_id_create_time'] + '.mp4', Get_file_size(total_szie)))
t_1 = time.time()
with open(file_path, "wb") as fp:
for data in response.iter_content(chunk_size = chunk_size):
if data:
fp.write(data)
read_size += chunk_size
#print('No.{} threading is downloading: {} ...: {}%'.format(index, file_path, str(round(read_size / total_szie * 100, 2))))
print("No.{} thread finshed! total cost: {}s".format(index, str(round(time.time() - t_1, 2))))
time.sleep(0.2)
else:
print("cannot conneted with the servers...")
except:
print("downloading %s failed... network error please try againg"%play_url)
#que.put(data)
# 服务端用于接收mitm脚本发送的数据
def run(exe_path, file_path):
PORT = 9527
HOST = ''
address = (HOST, PORT)
tcp_server_socket = socket(AF_INET, SOCK_STREAM)
tcp_server_socket.bind(address)
print("the server is lunching, listeing the port {}...".format(address[1]))
tcp_server_socket.listen(5)
while True:
try:
client_socket, client_address = tcp_server_socket.accept()
print('the client{} linked:{}'.format(client_address, time.asctime(time.localtime(time.time()))))
data = client_socket.recv(4)
header_size = struct.unpack('i', data)[0]
header_bytes = client_socket.recv(header_size)
header_json = json.loads(header_bytes.decode('utf-8'))
if header_json['type'] == 'post' or header_json['type'] == 'favo':
que.put(header_json)
else:
chunk_size = 1024
read_size = 0
total_size = header_json['size']
with open(file_path, 'wb') as fp:
while read_size < total_size:
data = client_socket.recv(chunk_size)
if data:
fp.write(data)
read_size += len(data)
probuf = Get_url_from_protobuf()
url_list = probuf.get_url(exe_path, file_path)
for url in url_list:
try:
feed_dict = {
'type': 'feed',
'feed_url': url,
'aweme_id_create_time': url[38: 57] #只是视频的id,并没有发布时间
}
que.put(feed_dict)
except:
continue
client_socket.close()
except:
tcp_server_socket.close()
print("never run here...")
if __name__ == "__main__":
dir_path = sys.argv[1]
if dir_path.endswith('/'):
dir_path += '/'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
#dir_path = r'C:\Users\Administrator\Desktop\pytho_src\douyin\videos'
thread_list = []
for i in range(4):
if i == 0:
thread_list.append(threading.Thread(target = run, args = (r'.\protobuf\protoc.exe', r'.\probuf.bin', )))
else:
thread_list.append(threading.Thread(target = Download, args = (dir_path , i + 1, )))
thread_list[i].setDaemon = True
[i.start() for i in thread_list]
[i.join() for i in thread_list]
# #run(r'.\protobuf\protoc.exe', r'.\probuf.bin')
# print("finish!")
五、使用方法

5.2 下载程序用法

六、运行效果
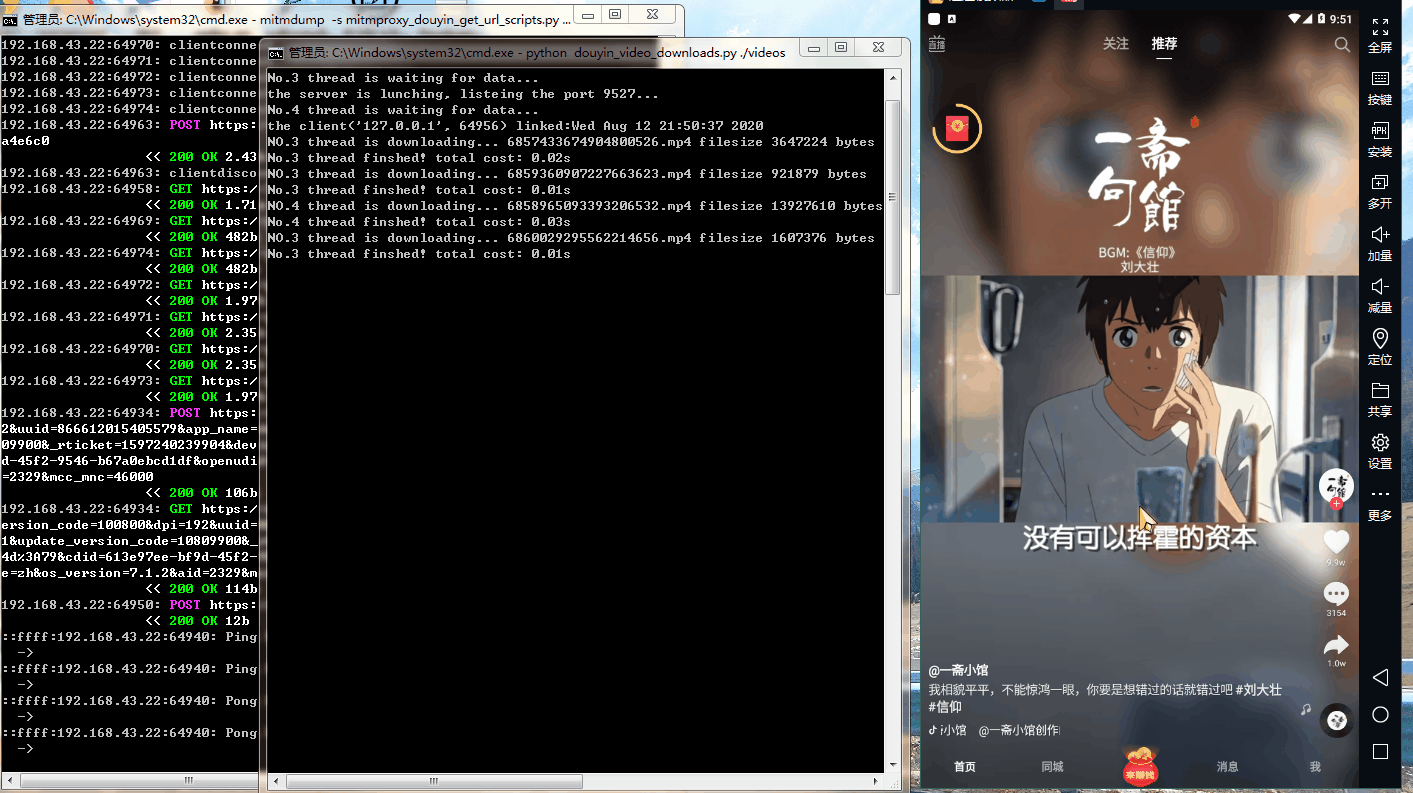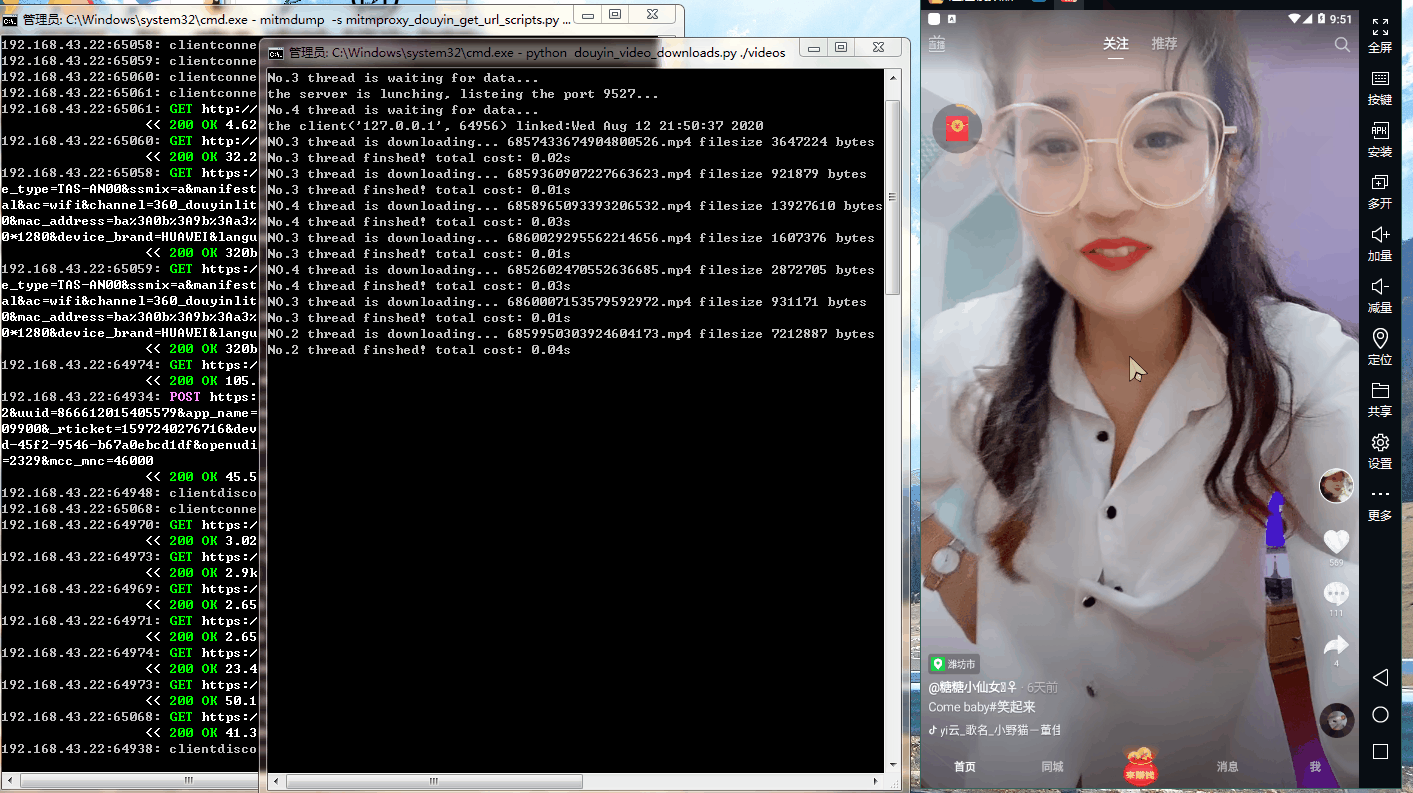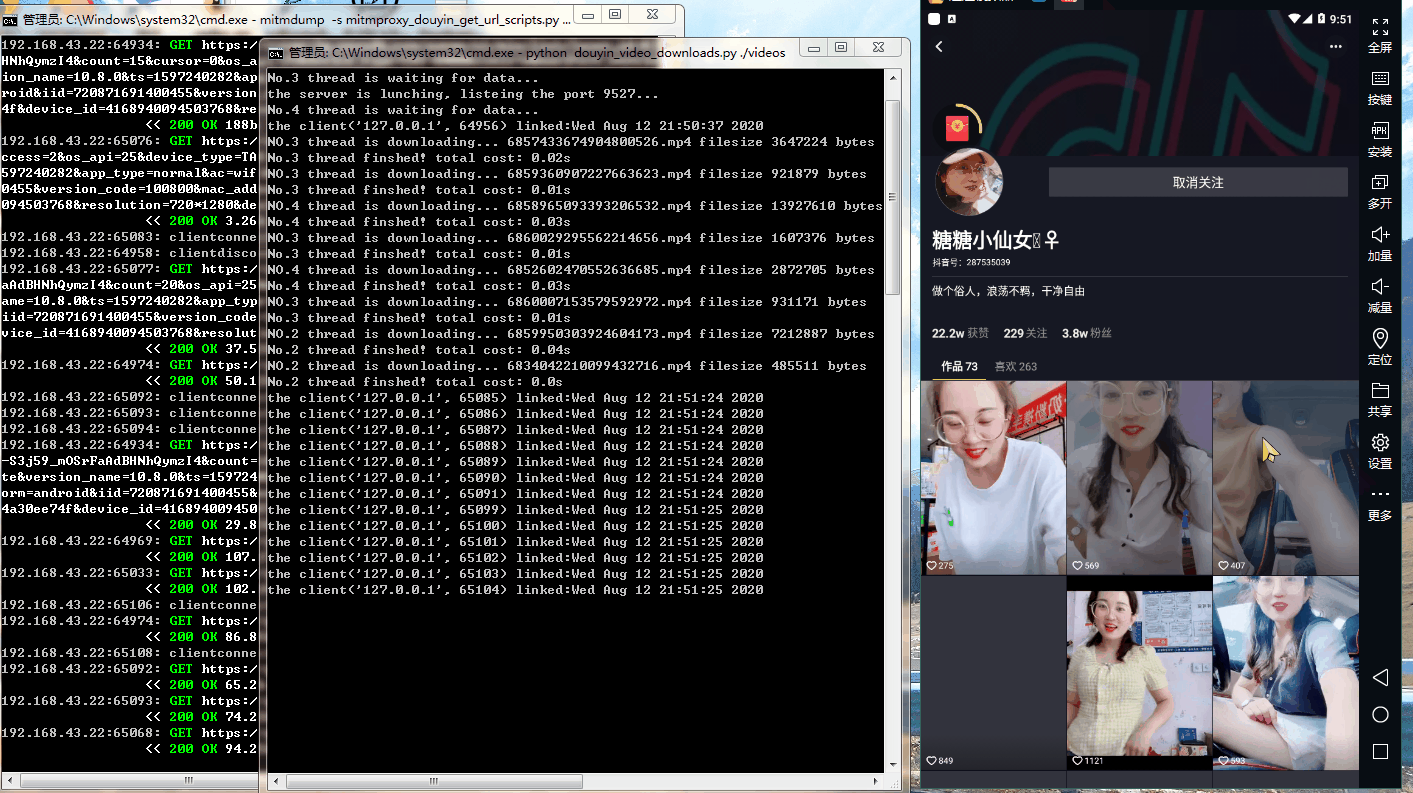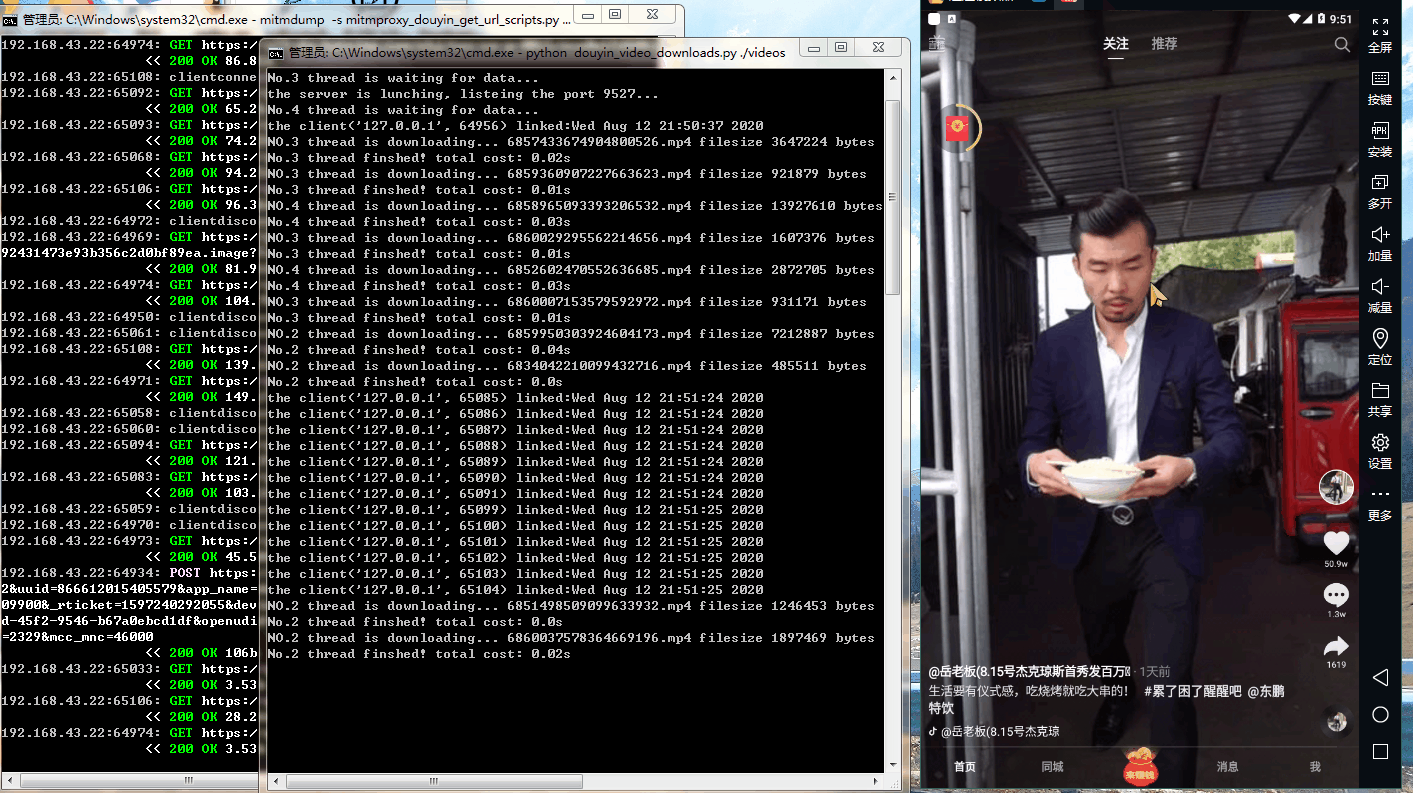
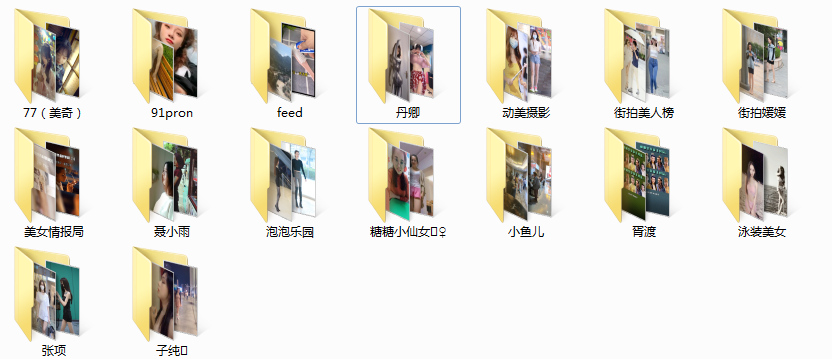
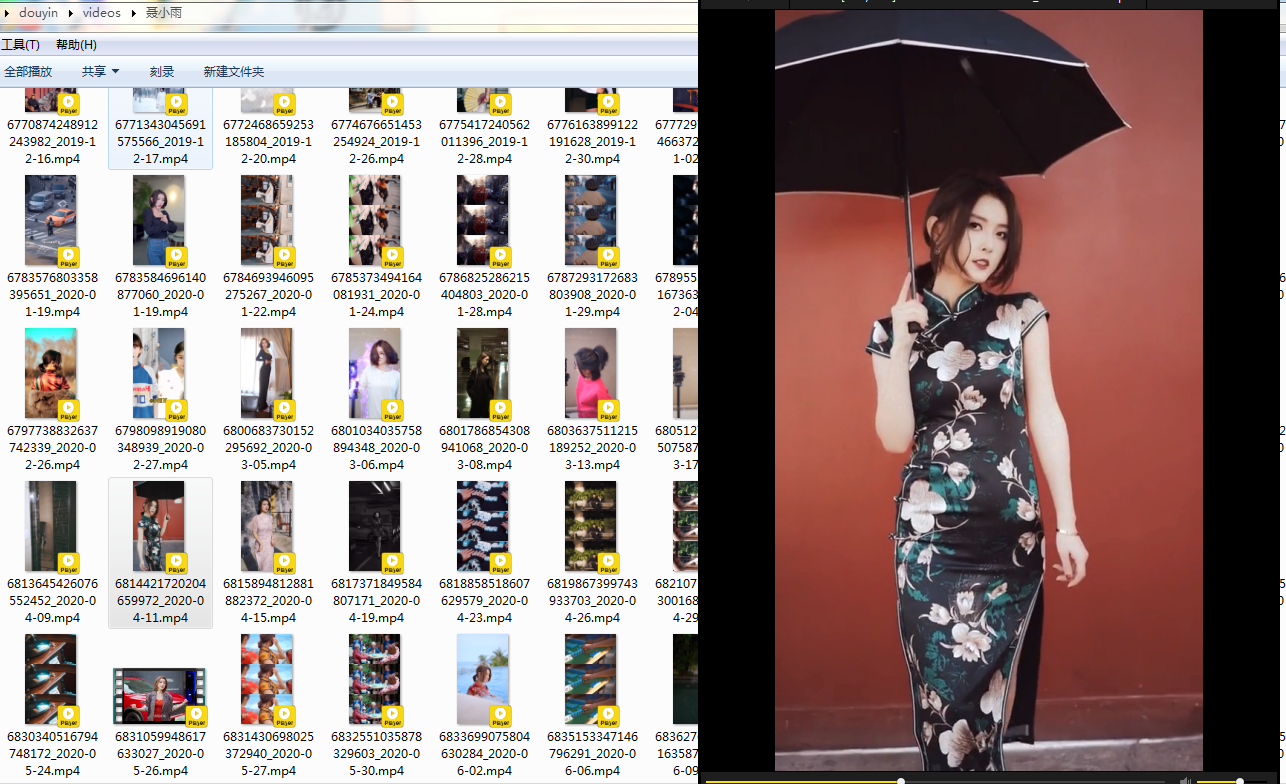
七、参考链接
1、https://blog.csdn.net/doctor_who2004/article/details/105718889
2、https://www.jianshu.com/p/af381ef134e2
3、https://blog.csdn.net/mp624183768/article/details/80956368
八、下一步计划
差不多就这么多,之前还打算用Appiun实现自动滑动,可又要下一大堆软件,自己的小电脑跑个模拟器已经不堪重负想想还是算了吧。受条件所限,自己的手机上没有进行测试(不然躺床上刷视频pc端程序挂后台运行,手机端浏览的视频基本上都能下载),只是在模拟器上运行,然后就没然后了。
大家有啥疑问的欢迎在评论区留言。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号