
【论文阅读笔记】VerifyNet Secure and Verifiable Federated Learning
【论文阅读笔记】 VerifyNet: Secure and Verifiable Federated Learning
摘要:
本文主要针对于两个问题:1)如何保护用户上传到云服务器的信息(eg.梯度信息)2)如何保证服务器正确的聚合了用户上传的信息。提出了一种可验证的联邦学习方案,第一次将可验证引入到联邦学习中,第一次提出了双盲化的方法保护了用户上传的梯度信息。本文提出的方法是构建在离散对数的困难问题上的。
关键字:隐私保护,深度学习,可验证联邦学习,云计算
引言:
联邦学习中需要解决的两个关键问题是:1)保护用户上传梯度 2)数据的完整性(其中尤为重要的是服务器返回的结果是否正确);
数据完整行是联邦学习经常被忽略的一个点,不进行数据完整性的校验会导致更多的隐私信息泄露,例如,常见的白盒攻击可以通过给用户特定的结果来诱导用户泄露更多的隐私信息。
现阶段对可验证的研究非常少,大多基于额外的硬件组件,此外我们还需要考虑用户的掉线情况。
本文,我们提出了一种可验证联邦学习,称为VerifyNet,使用全同态哈希和伪随机计算来提供可验证的联邦学习,使用密钥分享协议来解决用户掉线问题,本文主要贡献如下:
- 基于全同态哈希和伪随机生成技术实现了聚合结果的可验证性
- 提出了一种双盲化的方法解决用户掉线问题
- 给出了完整的安全性证明,和大量的实验分析方案可行新
问题描述:
A.联邦学习:常见的机器学习分为中心式的机器学习和联邦式机器学习
B.系统框图:
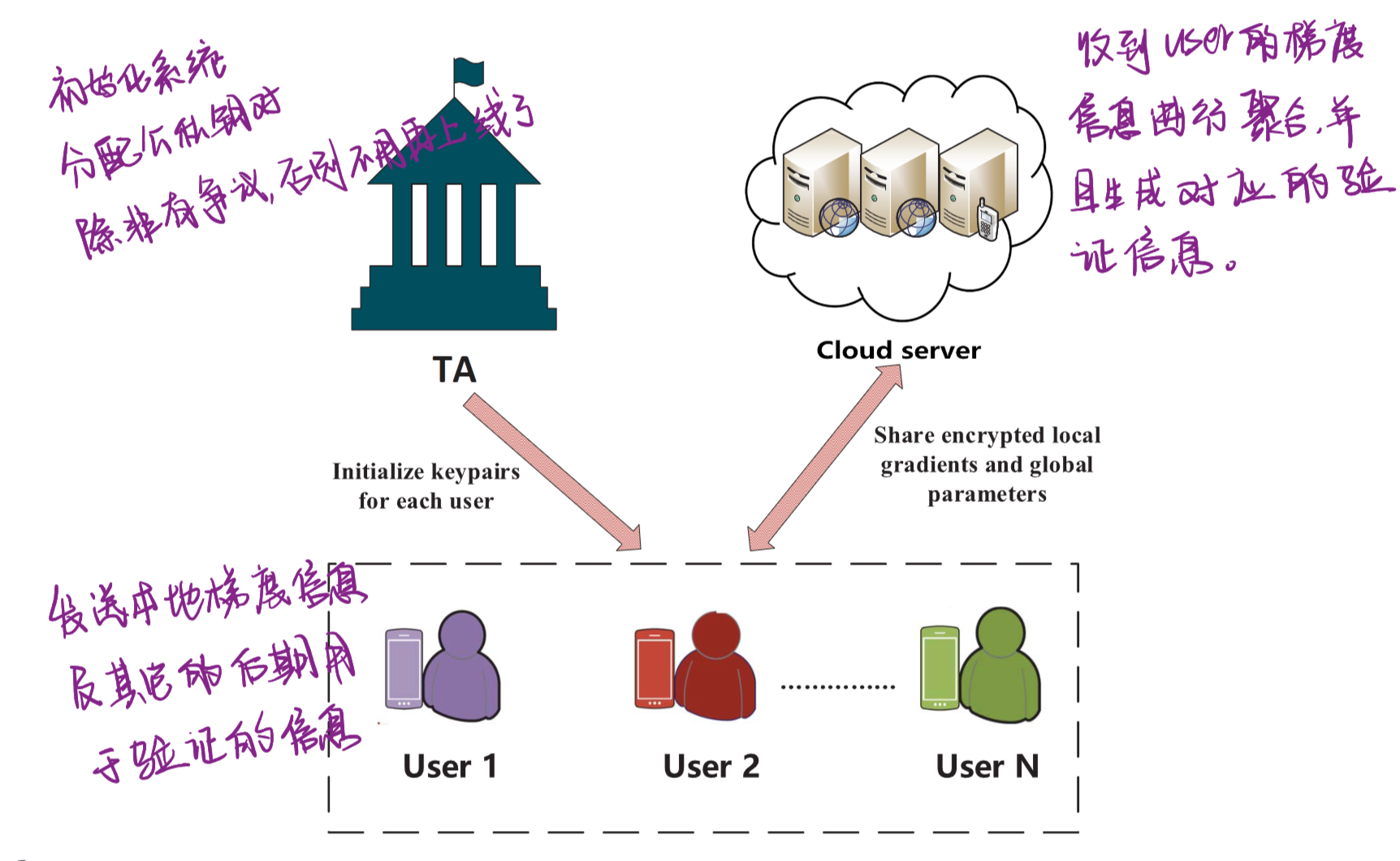
C. 威胁模型和设计目标
本文中我们认为TA是完全可信的,云服务器和用户都是诚实但好奇的,他们可能存在合谋的情况来获得特定用户的隐私信息。此外,云服务器可以试图构建一个假的proof或返回一个错误的聚合结果来诱导用户接受这个信息。
预备知识
技术引进
在联邦学习中,我们在进行模型的训练过程中,需要注意三点内容:用户上传的梯度必须经过加密,否则敌手会轻易的得到用户的隐私数据;服务器返回的结果必须能够被用户所检验,这是保证用户权益的重要内容;我们要考虑用户的掉线情况,保证掉线的用户不会对聚合结果产生影响。
A.单盲化保护用户的梯度信息:
用户在上传自己的梯度数据时,通过下面的式子进行加密:
其中的 \({{r_{n,m}}}\)是用户\(n\)与用户\(m\)通过密钥协商确定的共同密钥,云服务器拿到信息后可以通过聚合得到如下的结果:
我们发现用户上传时添加的密钥\(r_{n,m}\)在进行求和的时候被消除了,这就是单盲化保护用户的隐私方案,但是它不仅仅造成了大量的通信开销,并且不能在用户掉线的时候提供一个有效的帮助,最重要的验证也无法得到实现,所以我们提出了一种双盲化的方案。
B. 双盲化保护用户的梯度信息
在这里我们先改良 \({{r_{n,m}}}\)的计算,我们通过\(s_{n, m} \leftarrow \mathbf{K A .agree } \left(N_n^{S K}, N_m^{P K}\right)\)来代替之前由两个用户通过密钥协商确定的密钥,原式子则变成了
其中的 \({{\bf{PRG}}\left( {{s_{n,m}}} \right)}\)是通过\(s_{n, m}\)作为种子,利用伪随机生成器生成的随机数。为了解决用户的掉线问题,我们需要考虑到用户离线应如何将用户加入的随机数进行剔除,因此我们采用秘密分享协议,将用户的私钥 \({N_n^{SK}}\)通过秘密分享的形式进行一个分享。
这样一旦用户无法及时的上传自己的信息,服务器可以请求其他用户提交该用户的分享值,解密得到相应的 \({{s_{n,m}}}\),进而踢出相关的数据。
然而依然存在一种情况,用户有可能只是网络不太好,并不能及时的上传自己的信息,而是延后的提交信息,但此时服务器已经请求了用户的私钥分享值,就会导致该“迟到的用户”提交的梯度信息被解锁得到原始数据。
为了解决这个问题,我们采用二次盲化的手段,具体公式如下:
其中的 \({{\beta _n}}\)是由用户\(n\)自行生成的数据,其也通过秘密分享的手段分享给其他的用户,因此在云服务器只需要请求掉线的用户的\({{s_{n,m}}}\)的份额,以及在线用户 \({{\beta _n}}\)的份额即可完成聚合的任务。
尽管如此,双盲化协议主要是为了保护用户上传的梯度信息以及解决用户掉线的问题,但是仍然没有完成验证的目标,于是我们又提出了下面的方案。
提出的框架
正确性证明:
算法协议如下图所示:

基本框架/算法

相关工作
A.深度学习的隐私保护
针对深度学习的梯度保护策略,我们有许多方案,常见的有:差分隐私,安全多方计算以及密码学原语[11,18,19]。以差分隐私为基础的梯度保护策略都被证实是不安全的[14],在GAN网络下是亦被攻破的。在[11]文章中,使用了安全多方计算来保护用户的梯度,但是其没有考虑到用户离线的问题。
B.可验证的深度学习
云服务器可能会返回错误的聚合结果欺骗用户,在[16]中,使用了交互式证明系统来验证服务器的聚合结果。在[17]中,则是使用了一些可信任的硬件来帮助我们验证正确性。这些研究都是基于硬件或者只使用于部分的可验证环境中。
[11] K. Bonawitz et al., “Practical secure aggregation for privacy-preserving machine learning,” in Proc. ACM CCS, 2017, pp. 1175–1191.
[14] B. Hitaj, G. Ateniese, and F. Perez-Cruz, “Deep models under the GAN: Information leakage from collaborative deep learning,” in Proc. ACM CCS, 2017, pp. 603–618.
[16] Z. Ghodsi, T. Gu, and S. Garg, “SafetyNets: Verifiable execution of deep neural networks on an untrusted cloud,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 4672–4681.
[17] F. Tramèr and D. Boneh, “Slalom: Fast, verifiable and private execution of neural networks in trusted hardware,” Jun. 2018, arXiv:1806.03287. [Online]. Available: https://arxiv.org/abs/1806.03287
[18] R. Shokri and V. Shmatikov, “Privacy-preserving deep learning,” in Proc. ACM CCS, 2015, pp. 1310–1321.
[19] L. T. Phong, Y. Aono, T. Hayashi, L. Wang, and S. Moriai, “Privacypreserving deep learning via additively homomorphic encryption,” IEEE Trans. Inf. Forensics Security, vol. 13, no. 5, pp. 1333–1345, May 2018.
结论
在本文中,我们提出了VerifyNet,它支持向每个用户验证服务器的计算结果。此外,VerifyNet支持用户在训练过程中退出。安全性分析表明,在诚实但好奇的安全设置下,我们的VerifyNet具有很高的安全性。此外,在真实数据上进行的实验也证明了我们提出的方案的实际性能。作为未来研究工作的一部分,我们将重点关注降低整个协议的通信开销。
提出的问题
- 这种验证方案需要在用户本地进行大量的计算和额外的通信开销,如何在跨设备的联邦学习上应用这一功能称为非常复杂的一项工程,依然需要更加轻量级的方法来实现。
该文原文来自:https://gabaili.top/
转载请注明出处,感谢~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号