
Raft笔记
Raft
分布式系统可以容错,在一部分server挂掉的时候仍然正常工作,而难点在于如何处理挂掉的server保存的数据不一致问题
novel features
- Log 只从 leader 流向 server
- Leader selection 包含在心跳检测中,使用randomized timer
- Membership changes 用一种新算法,使前后集群的主体在转换时是重叠的
replicated state machine
基于replicated log
每个Server的log都以相同的顺序存储着相同的command,因此每个server的输出是相同的
高理解度的设计
方法:
- 问题分解:leader election, log replication, safety, and membership changes 将这些问题分解开,成子问题
- 简化状态空间:减少状态数量,增加机制上的限制(
砍掉意义不大的功能)
分解一致性问题
将一致性问题分解为三个子问题
- Leader election
- Log replication
- Safety
Raft basic
Server states:
- leader
- follower
- candidate
leader处理所有的客户端请求
term
Raft 将时间分为若干个任意长度的 term
每个term的开头都是一次election
若election的结果是平票,则这个term结束,没有leader,稍后会有一个新的term
机制
term 在 Raft 中扮演了逻辑时钟的角色,这让server察觉到谁是过时的leader
每个server存储一个term number
-
如果发现自己的term number比别人小,则更新
-
如果leader或candidate发现自己的term过时了,他会立马变成follower
-
如果server收到了过时的request,则拒绝掉
RPC
- **RequestVote RPC **: election
- AppendEntries RPC : heartbeat (no log) & replicate log entries
如果一段时间没有收到响应,会重试RPC
所有RPC的发起都是并行的
Leader election
利用heartbeat发起election
每个Server一开始都是follower
leader会向所有follower发heartbeat,若follower一段时间没收到heartbeat,称为election timeout,则认为没有可用leader,于是发起election
election过程
一个follower增加他的term,转换成candidate,给自己投票,给每个server发 RequestVote RPC
他保持candidate的状态直到三种情况:
- 他获胜
- 另一个candidate获胜
- 一段时间过后仍无胜者
candidate获胜条件:他获得了多数票
一旦赢得election,他将给其他server发heartbeat,通知他们新leader的存在并阻止新election的发起
在投票过程中,candidate也可以收来自于自称leader的AppendEntries RPC,如果发送者的term >= candidate,则自己变为follower。否则拒绝此RPC
避免split vote
randomized election timeouts : election timeout 是随机选取的
Vote 策略
- 不投 candidate term < 自己term的
- 不投 log 没自己新的
- 如果此 term 已经投过票了,则不投了(votedFor存投的candidateId)
- 其他情况,投
Up-to-date: comparing the index and term of the last entries in the logs
Log replication
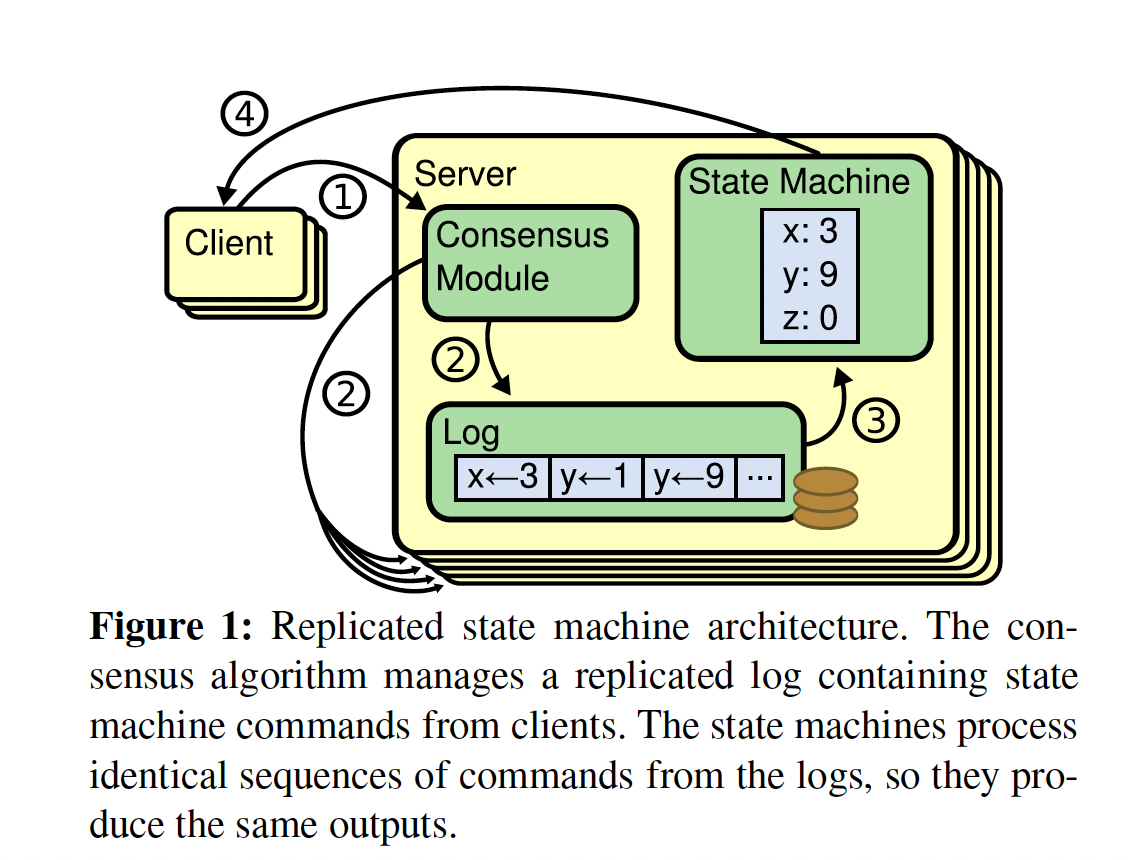
- Leader收到client命令
- 写自己的log,new entry
- 给follower发AppendEntries RPC,复制此entry到 log
- 确保一致性同步后,leader执行此entry (最终会被所有server的状态机执行),并返回response给client
- 如果某个follower崩溃或运行慢,leader会无限重试AppendEntries RPC
Log

Log 三要素
- Log index
- Term: 方块上面的数字
- Command
commited: 一个entry被大多数server复制到了log
累积确认: 一个entry是commited,那么之前所有entry都是commited
apply: 一旦follower确认一个entry是commited,他将在自己的状态机执行此entry
Log Matching Property

- 两个处在不同 log 的 entry 拥有相同的index和term,那么他们就是相同的
- 两个处在不同 log 的 entry 拥有相同的index和term,那么他之前的所有entry都是相同的
确保上述第二条生效的措施:
AppendEntries RPC 中包含了leader的 prevLogIndex & prevLogTerm,如果follower没找到此prevEntry,则返回失败,拒绝新entry。因此,只要follower返回成功,通过归纳法,则之前的entry都和leader是一致的
Leader Crash
Lead crash的时候,log会不一致。老leader可能还没有commit entry就crash了
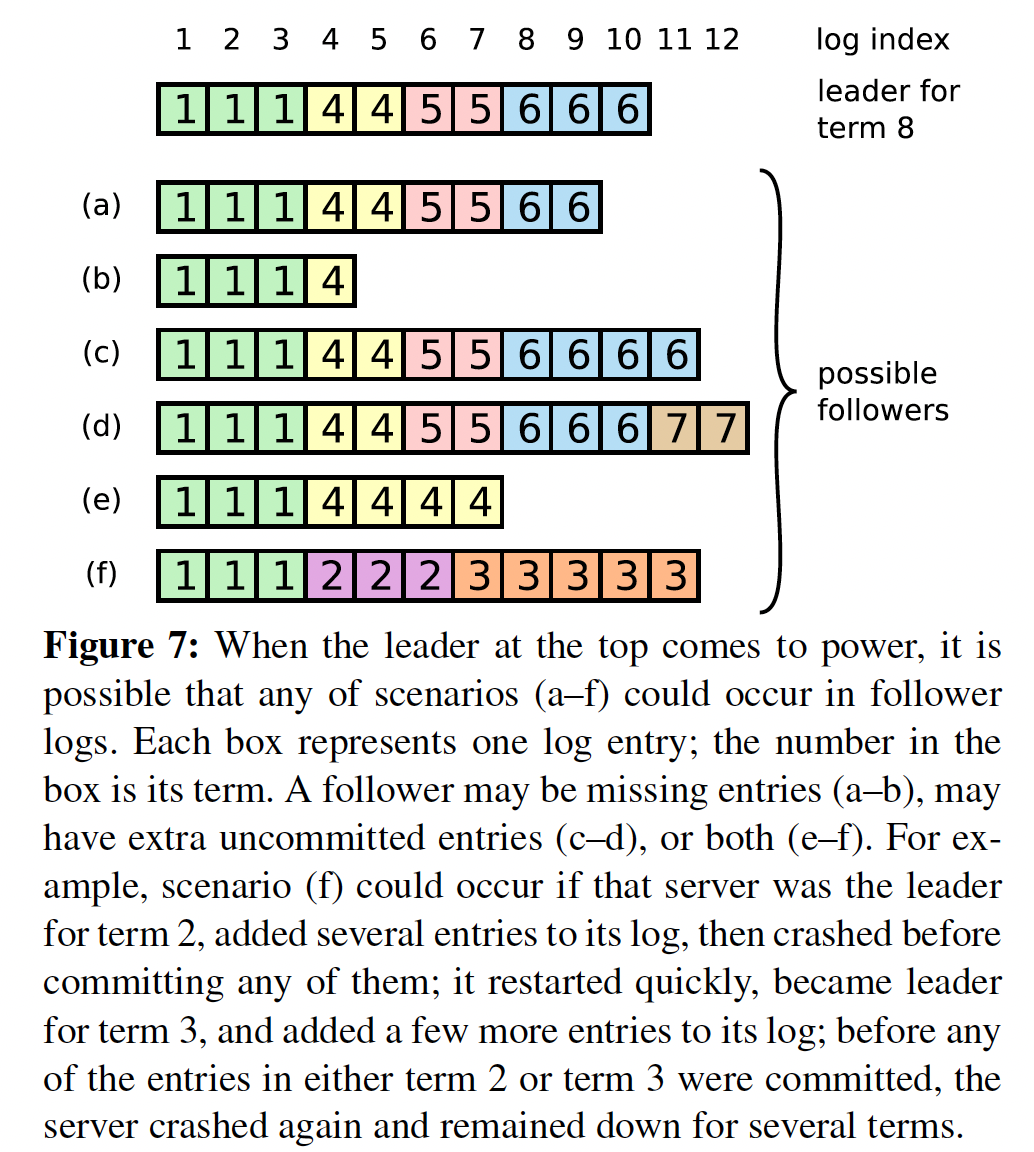
处理不一致 consistency check
consistency check 是通过 AppendEntries RPC 执行的
策略: leader 让 follower 强制复制 leader 的 log,如果有冲突,follower的 log 会被覆盖
过程:
- leader找到与follower一致的最近点
- 删除后面的所有follower log
- leader将后面的所有leader log 发给 follower
leader会维护每个follower的nextIndex,用于发AppendEntries RPC时给他们
当leader刚当上时,nextIndex = 自己最后一个entry index + 1
consistency check失败后,leader会递减自己的nextIndex,然后重试AppendEntries RPC直到成功,一旦成功,follower就复制了后面的log,达到一致。
可优化为:follower返回冲突index的数量,leader直接减去,达到一致的index,这样只用重试一次
Follower and candidate crashes
如果这两种crash发生了,那么发给他们的RequestVote & AppendEntries RPCs 会失败,Raft会无限重试RPC直到成功。
Raft RPC 是幂等的,如果新entry到了,而follower已经有此entry了,则会忽略这些entry
Timing and availability
MTBF: 一个server平均发生两次故障的间隔时间
实现心得
- 计时器到时触发时,可新开一个线程执行逻辑,而不应暂停计时同步处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号