

http://www.pythonchallenge.com/ 网站题解
在知乎中无意发现了这个网站,做了几题发现挺有趣的,这里记录下自己的解题思路,顺便对比下答案中的思路
网页:http://www.pythonchallenge.com/
目前只做了几题,解题的方法就是根据页面上给的提示(文字或图片),然后得出一个字符串xxx,http://www.pythonchallenge.com/pc/def/xxx.html 就是下一题的url。下面统一用一个字符串代表xxx这个答案。
网站的参考答案中给出的答案是更pythonic的。
第1题:
http://www.pythonchallenge.com/pc/def/0.html

算是让你熟悉规则的题,告诉你怎么到下一关。
因为与python有关,以为结果串 2**38,后面再试下发现是这个计算的结果。
所以答案是 274877906944。
第2题:
http://www.pythonchallenge.com/pc/def/map.html

这是一题规则题,根据图中的提示:K->M、O->Q、E->G 可以发现其规律就是字母表对应的后移两位,即 'abcdefghijklmnopqrstuvwxyz' -> 'cdefghijklmnopqrstuvwxyzab'。
找到规律后,就用此规律转化下面红紫色的语句:
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
代码:
s="""g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."""
source='abcdefghijklmnopqrstuvwxyz'target='cdefghijklmnopqrstuvwxyzab'
tran_dict=dict(zip(source, target))
result=''
for _s in s:
result += tran_dict.get(_s, _s)
print result
转换后结果为:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
按这规则转化url里的字符串:
map -> ocr
答案为 orcr。
过关后可以看得到参考答案,这里只提一下它的做法:
1、使用ord、chr(字符与ASCII码数值间转换)
2、使用string.maketrans和translate
table = string.maketrans('abcdefghijklmnopqrstuvwxyz','cdefghijklmnopqrstuvwxyzab')
’text to be translated'.translate(table)
第3题:
http://www.pythonchallenge.com/pc/def/ocr.html

这题让我蒙了一阵子,不知道突破点在哪,可能是英文太差一直没反应过来,后面注意到 the page source,于是就打开了网页源码
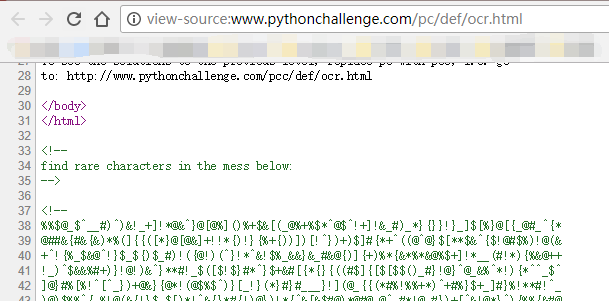
发现突破口是在这,找出下面一大串字符中 rare 字符,便是统计这大串字符的各字符出现个数。
我的代码:
s="""%%$@_$^__#)^)&!_+]!*@&^}@...""" //这串不打出来了
d={}
l=[]
for _s in ss:
if _s not in d:
d[_s] = 0
l.append(_s)
d[_s] += 1
print d
print l
然后看打印
>>> print d
{'\n': 1220, '!': 6079, '#': 6115, '%': 6104, '$': 6046, '&': 6043, ')': 6186, '(': 6154, '+': 6066, '*': 6034, '@': 6157, '[': 6108, ']': 6152, '_': 6112, '^': 6030, 'a': 1, 'e': 1, 'i': 1, 'l': 1, 'q': 1, 'u': 1, 't': 1, 'y': 1, '{': 6046, '}': 6105}
>>> print l
['\n', '%', '$', '@', '_', '^', '#', ')', '&', '!', '+', ']', '*', '}', '[', '(', '{', 'e', 'q', 'u', 'a', 'l', 'i', 't', 'y']
可见应该要找出现个数为1的,按出现顺序输出
答案为:equality
参考答案:
1、使用字符串的 count 函数,可以计算出字符串中某字符的出现个数
第4题:
http://www.pythonchallenge.com/pc/def/equality.html
持续更新中。。。

