

MySQL 索引优化指南
原理

b+ 树,记住这棵树!索引所有优化都围绕这棵树展开(hash索引除外)
优点
-
索引大大减小了服务器需要扫描的数据量
-
索引可以帮助服务器避免排序和临时表
-
索引可以将随机IO变成顺序IO
-
索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组。在MySQL5.1和更新的版本中,InnoDB可以在服务器端过滤掉行后就释放锁,但在早期的MySQL版本中,InnoDB直到事务提交时才会解锁。对不需要的元组的加锁,会增加锁的开销,降低并发性。 InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组数。但是只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即索引达不到过滤的目的),MySQL服务器只能对InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了。如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。
-
关于InnoDB、索引和锁:InnoDB在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
缺点
-
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
-
建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
-
如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
-
对于非常小的表,大部分情况下简单的全表扫描更高效;
类型
存储方式:
聚族索引:同一个数据结构中保存了索引与数据(如InnoDB的主键索引,适合多行检索)
非聚族索引:非聚族索引,也称二级索引(适合单行检索)
索引类型:
普通索引:最基本的索引,没有任何限制,是我们大多数情况下使用到的索引。
唯一索引:与普通索引类型,不同的是唯一索引的列值必须唯一,但允许为空值。
主键索引:不允许值为空的唯一索引。
组合索引:将几个列作为一条索引进行检索,使用最左匹配原则。
全文索引:全文索引(FULLTEXT)仅可以适用于MyISAM引擎的数据表;作用于CHAR、VARCHAR、TEXT数据类型的列。(很少使用,业界基本用 ES)
使用
原则:
-
最左前缀匹配原则:
-
索引选择性:公式是 COUNT(DISTINCT col) / COUNT(*),表示字段不重复的比率,比率越大扫描的记录数就越少,性能越佳
-
索引尽可能短:B+树数据结构决定,过长降低性能;
-
索引列不能参与计算:B+树数据结构决定,如有函数处理索引将会实效;
注意点:
-
索引覆盖(一个索引包含(或者说是覆盖)需要查询的所有字段)可减少回表操作提高查询速度;
-
查询条件可以乱序,MySQL的查询优化器会优化成索引可以识别的模式;
-
尽可能的扩展索引,不要新建立索引;(索引太多影响写速度)
-
索引不会包含有NULL值的列:只要列中包含有NULL值,都将不会被包含在索引中,组合索引中只要有一列有NULL值,那么这一列对于此条组合索引就是无效的;
-
单个多列组合索引和多个单列索引的检索查询效果不同,MySQL查询只使用一个索引,如果WHERE子句中已经使用了索引的话,那么ORDER BY中的列是不会使用索引;
- 联合索引实效情况:
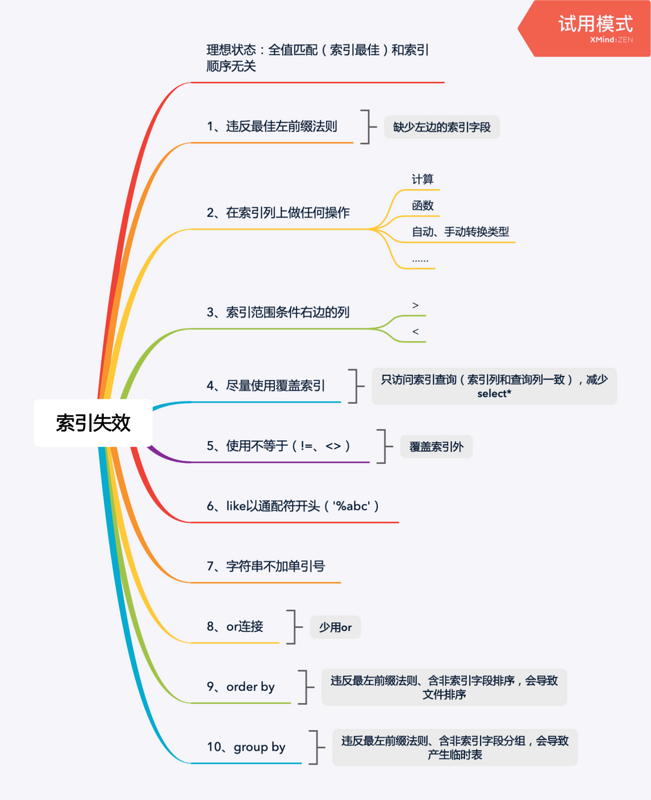
调优步骤:
-
查看运行效果,是否真的很慢,主要设置SQL_NO_CACHE;
-
WHERE条件单表查询,锁定最小返回记录表。这句话的意思是,把查询语句的WHERE都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高;
-
EXPLAIN查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询);
-
ORDER BY LIMIT 形式的SQL语句,让排序的表优先查;
-
了解业务的使用场景;
-
加索引时,参照建立索引的几大原则;
-
观察结果,不符合预期,则重新从1开始分析;
进阶
磁盘IO与预读
数据结构选择:b+树、b树、红黑树对比
InnoDB/MyISAM 索引对比
Explain详解
参考
《高性能MySQL》第3版
https://blog.csdn.net/mysteryhaohao/article/details/51719871
https://zhuanlan.zhihu.com/p/29118331
https://www.infoq.cn/article/OJKWYykjoyc2YGB0Sj2c

