

presto 原理架构
0、简介
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 Hive 的 10 倍以上。Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品,单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto 的目标是在可期望的响应时间内返回查询结果,Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。
1、架构
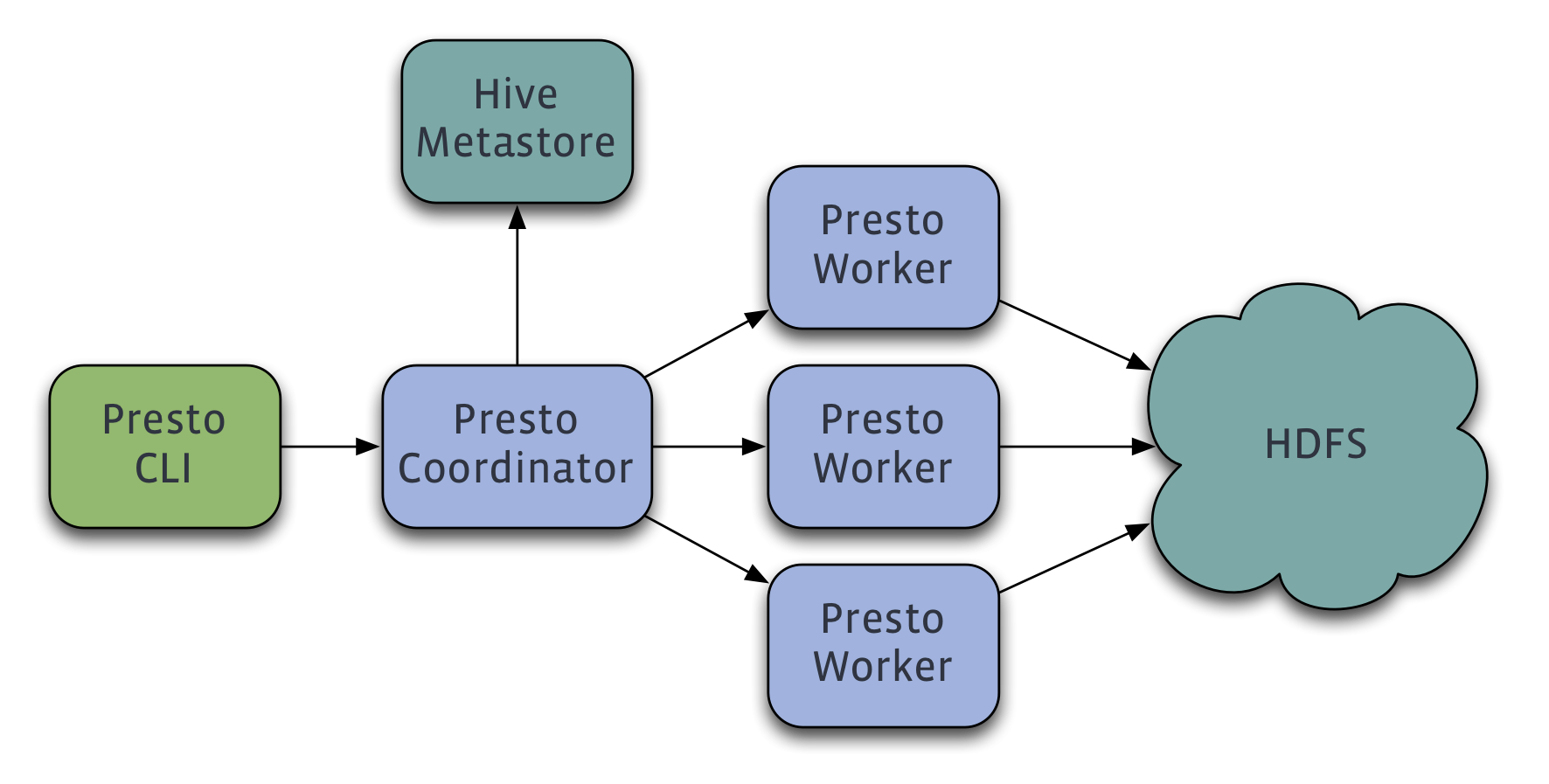
Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- 一个Discovery Server节点
- 通常内嵌于Coordinator节点中
- 多个Worker节点
- 负责实际执行查询任务,负责与HDFS交互读取数据
Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息。
更形象架构图如下:

2、低延迟原理
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- GC控制
3、执行过程
提交查询
用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行。
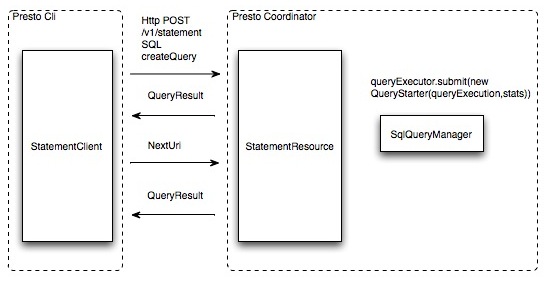
SQL编译过程
Presto与Hive一样,使用Antlr编写SQL语法,语法规则定义在Statement.g和StatementBuilder.g两个文件中。 如下图中所示从SQL编译为最终的物理执行计划大概分为5部,最终生成在每个Worker节点上运行的LocalExecutionPlan,这里不详细介绍SQL解析为逻辑执行计划的过程,通过一个SQL语句来理解查询计划生成之后的计算过程。

样例SQL:
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
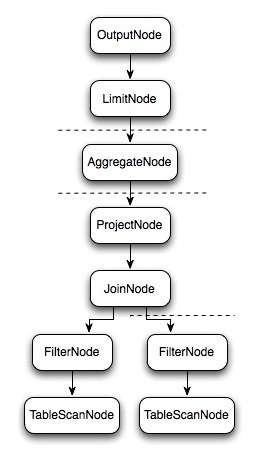
上面的SQL语句生成的逻辑执行计划Plan如上图所示。那么Presto是如何对上面的逻辑执行计划进行拆分以较高的并行度去执行完这个计划呢,我们来看看物理执行计划。
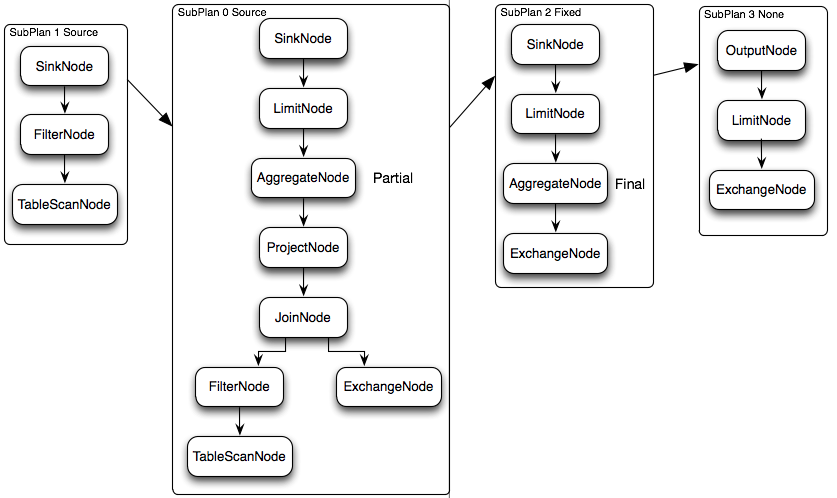
物理执行计划
逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行。
SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性。
- PlanDistribution表示一个查询Stage的分发方式,逻辑执行计划图中的4个SubPlan共有3种不同的PlanDistribution方式:Source表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行;Fixed表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8);None表示这个SubPlan只分配到一个节点进行执行。在下面的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据。
- OutputPartitioning属性只有两个值HASH和NONE,表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle。在下面的执行计划中只有SubPlan0的OutputPartitioning=HASH,所以SubPlan2接收到的数据是按照rank字段Partition后的数据。
完全基于内存的并行计算
查询的并行执行流程
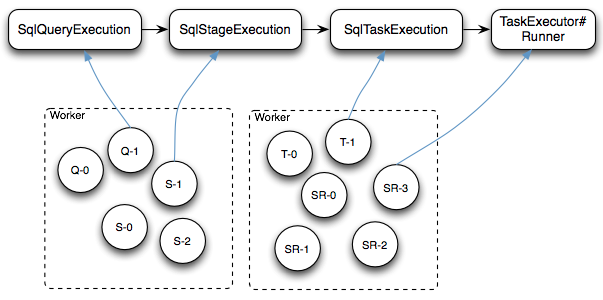
Presto SQL的执行流程如下图所示
- Cli通过HTTP协议提交SQL查询之后,查询请求封装成一个SqlQueryExecution对象交给Coordinator的SqlQueryManager#queryExecutor线程池去执行
- 每个SqlQueryExecution线程(图中Q-X线程)启动后对查询请求的SQL进行语法解析和优化并最终生成多个Stage的SqlStageExecution任务,每个SqlStageExecution任务仍然交给同样的线程池去执行
- 每个SqlStageExecution线程(图中S-X线程)启动后每个Stage的任务按PlanDistribution属性构造一个或者多个RemoteTask通过HTTP协议分配给远端的Worker节点执行
- Worker节点接收到RemoteTask请求之后,启动一个SqlTaskExecution线程(图中T-X线程)将这个任务的每个Split包装成一个PrioritizedSplitRunner任务(图中SR-X)交给Worker节点的TaskExecutor#executor线程池去执行
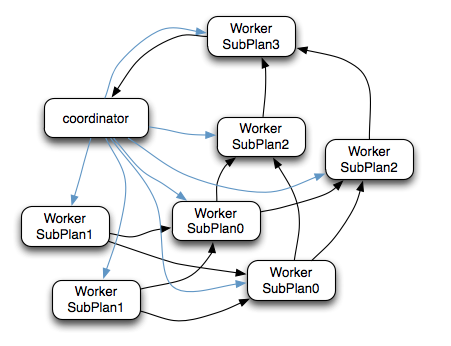
上面的执行计划实际执行效果如下图所示。
- Coordinator通过HTTP协议调用Worker节点的 /v1/task 接口将执行计划分配给所有Worker节点(图中蓝色箭头)
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join操作和Partial Aggr操作
- SubPlan1的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
源数据的并行读取
在上面的执行计划中SubPlan1和SubPlan0都是Source节点,其实它们读取HDFS文件数据的方式就是调用的HDFS InputSplit API,然后每个InputSplit分配一个Worker节点去执行,每个Worker节点分配的InputSplit数目上限是参数可配置的,Config中的query.max-pending-splits-per-node参数配置,默认是100。
分布式的Hash聚合
上面的执行计划在SubPlan0中会进行一次Partial的聚合计算,计算每个Worker节点读取的部分数据的部分聚合结果,然后SubPlan0的输出会按照group by字段的Hash值分配不同的计算节点,最后SubPlan3合并所有结果并输出
流水线
数据模型
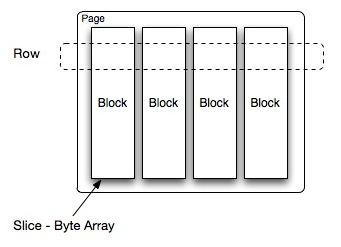
Presto中处理的最小数据单元是一个Page对象,Page对象的数据结构如下图所示。一个Page对象包含多个Block对象,每个Block对象是一个字节数组,存储一个字段的若干行。多个Block横切的一行是真实的一行数据。一个Page最大1MB,最多16*1024行数据。
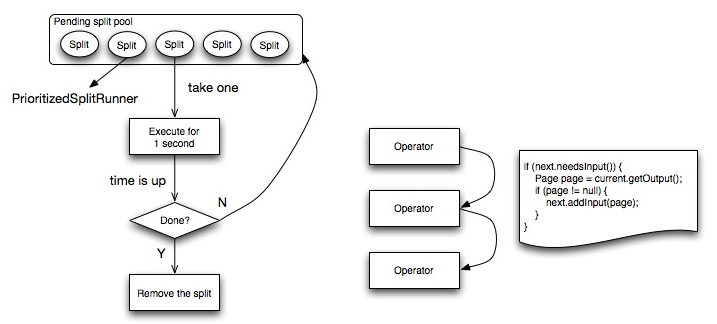
节点内部流水线计算
下图是一个Worker节点内部的计算流程图,左侧是任务的执行流程图。
Worker节点将最细粒度的任务封装成一个PrioritizedSplitRunner对象,放入pending split优先级队列中。每个
Worker节点启动一定数目的线程进行计算,线程数task.shard.max-threads=availableProcessors() * 4,在config中配置。
每个空闲的线程从队列中取出一个PrioritizedSplitRunner对象执行,如果执行完成一个周期,超过最大执行时间1秒钟,判断任务是否执行完成,如果完成,从allSplits队列中删除,如果没有,则放回pendingSplits队列中。
每个任务的执行流程如下图右侧,依次遍历所有Operator,尝试从上一个Operator取一个Page对象,如果取得的Page不为空,交给下一个Operator执行。
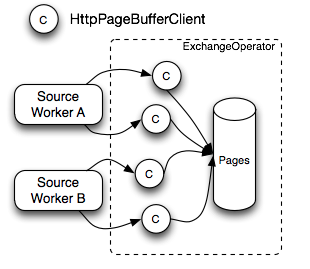
节点间流水线计算
下图是ExchangeOperator的执行流程图,ExchangeOperator为每一个Split启动一个HttpPageBufferClient对象,主动向上一个Stage的Worker节点拉数据,数据的最小单位也是一个Page对象,取到数据后放入Pages队列中
本地化计算
Presto在选择Source任务计算节点的时候,对于每一个Split,按下面的策略选择一些minCandidates
- 优先选择与Split同一个Host的Worker节点
- 如果节点不够优先选择与Split同一个Rack的Worker节点
- 如果节点还不够随机选择其他Rack的节点
对于所有Candidate节点,选择assignedSplits最少的节点。
动态编译执行计划
Presto会将执行计划中的ScanFilterAndProjectOperator和FilterAndProjectOperator动态编译为Byte Code,并交给JIT去编译为native代码。Presto也使用了Google Guava提供的LoadingCache缓存生成的Byte Code。


上面的两段代码片段中,第一段为没有动态编译前的代码,第二段代码为动态编译生成的Byte Code反编译之后还原的优化代 码,我们看到这里采用了循环展开的优化方法。
循环展开最常用来降低循环开销,为具有多个功能单元的处理器提供指令级并行。也有利于指令流水线的调度。
引用
https://prestodb.io/overview.html

