技术名称通解 --- 数据仓库
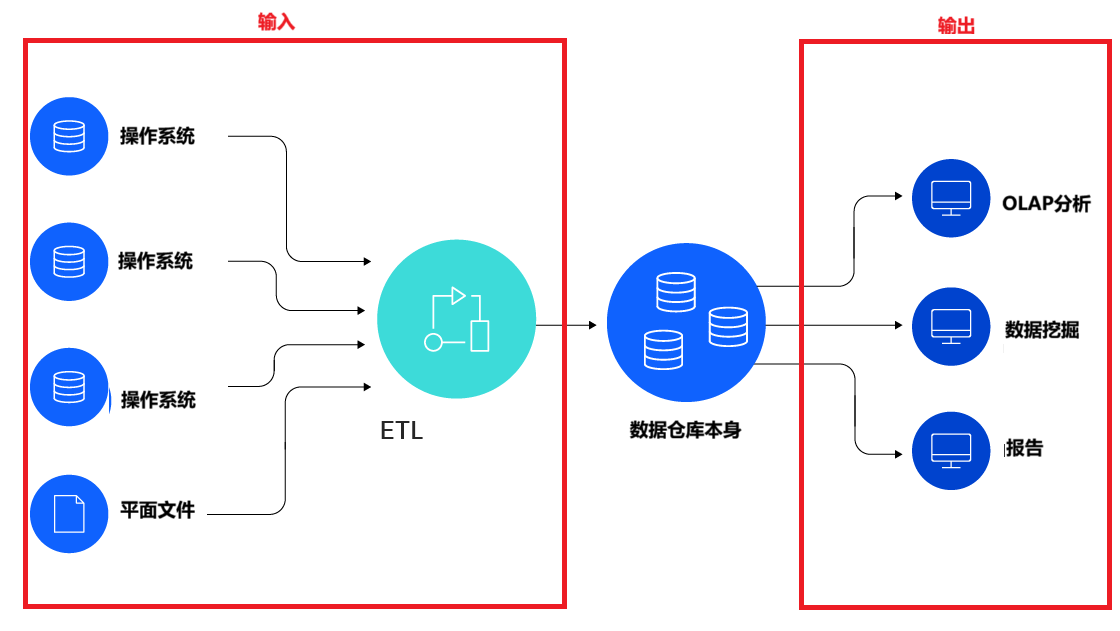
数据仓库或企业数据仓库 (EDW) 是一种系统,需要通过ETL(抽取、转换、加载)过程从多个数据源(包括RDBMS、ERP、CRM等)提取数据,汇聚到一个统一的数据存储中,从而为数据分析、数据挖掘、人工智能 (AI) 和机器学习提供支持。通过数据仓库系统,组织能以标准数据库无法企及的方式对大量数据(TB 级和 PB 级)运行强大的分析。数据仓库早期在本地大型机上运行,现在趋势是云端或专用设备。
一般而言,数据仓库具有三层架构,具体则为:
-
底层:数据仓库服务器(通常为关系数据库系统)+ ETL接入工具
-
中间层:中间层由 OLAP(在线分析处理)服务器组成,它可实现快速查询。此层可使用三种类型的 OLAP 模型,即 ROLAP、MOLAP 和 HOLAP。所用 OLAP 模型的类型取决于现有数据库系统的类型。
-
顶层:顶级由某种前端用户界面或报告工具来呈现,它允许最终用户对其业务数据进行临时数据分析。
-
ROLAP(关系型OLAP):基于传统的关系型数据库,数据以表的形式存储。ROLAP通过SQL查询对这些表进行分析,适合处理大规模数据,但查询速度相对较慢。
-
MOLAP(多维OLAP):使用专门的多维数据存储,把数据预先处理并存储成多维“数据立方体”,这样查询速度更快,适合频繁的多维分析。但由于数据需要预先计算,数据量大时存储需求高。
-
HOLAP(混合OLAP):结合了ROLAP和MOLAP的优点。HOLAP可以根据需要在关系型数据库和多维数据存储之间切换,既能处理大数据,又能在某些情况下加快查询速度。
有些人有疑问,为什么有关系型数据库,我们还要数据仓库,因为关系型数据库具有某些天然缺陷,数据仓库是为了弥补这些缺陷而出现的。
MySQL 的局限性:
-
缺乏高级数据分析和建模功能:
MySQL 缺少诸如机器学习模型训练、时间序列分析、复杂统计计算等高级数据分析功能。这些任务通常需要专门的工具或语言,如 Python、R 或专门的数据分析平台。 -
性能瓶颈:
对于超大规模数据集或复杂的分析查询,MySQL 的性能可能不如专门的分析数据库(如 ClickHouse、Greenplum)或大数据处理框架(如 Apache Spark)。 -
数据可视化能力有限:
MySQL 没有内置的数据可视化功能,需要配合 BI 工具(如 Tableau、Power BI)或编程语言(如 Python 的 Matplotlib、Seaborn 等)来实现数据的图形化呈现。 -
不擅长处理非结构化数据:
MySQL 主要用于处理结构化的表格数据,对于非结构化数据(如文本、图像、音频)的分析支持较弱。
数据仓库中的架构是指在数据库或数据仓库中组织数据的方式。架构结构主要有两种类型:星型架构和雪花型架构,
星型架构:此架构由一个事实数据表组成,而该事实数据表可联接到多个非规范化维度表。此架构被视为最简单且最常见的一种架构,而其用户在查询时可享受到更快的速度。维度表非规范化: 维度表通常包含丰富的描述性数据,以避免复杂的表连接。例如,一个产品维度表可能包含产品名称、类别、品牌、尺寸等多种属性,而这些数据在规范化的数据库中可能会被拆分成多个相关的表。
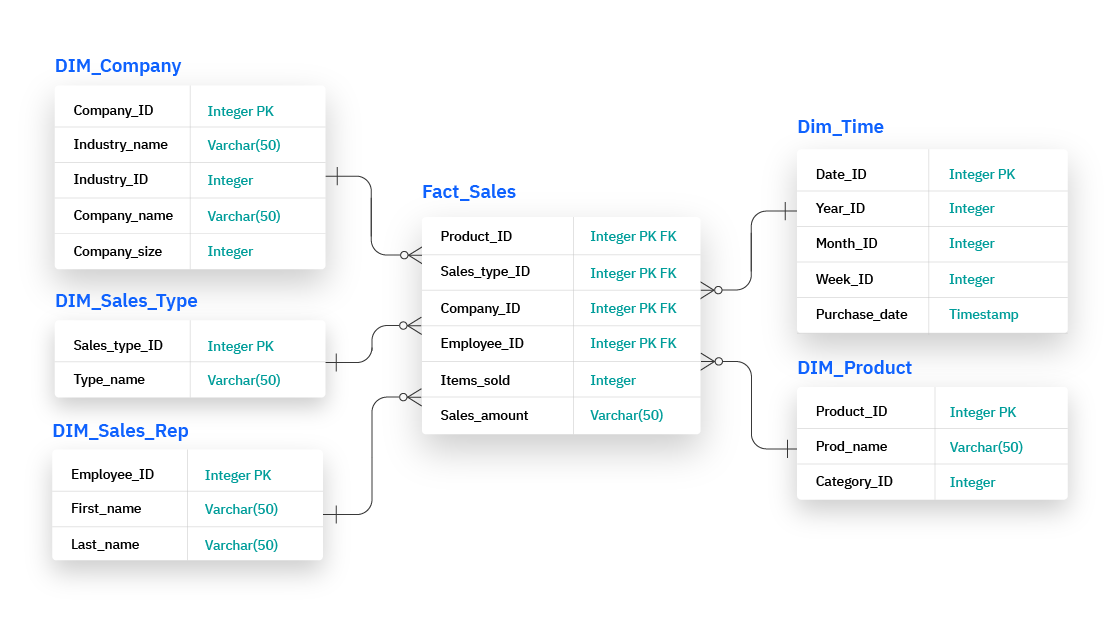
这张图展示了一个数据仓库中的星型模型结构,它由一个事实表和多个维度表组成。以下是各个表的详细解释:
-
Fact_Sales (事实表:销售)
- Product_ID (Integer PK FK): 产品的唯一标识符,外键。
- Sales_type_ID (Integer PK FK): 销售类型的唯一标识符,外键。
- Company_ID (Integer PK FK): 公司唯一标识符,外键。
- Employee_ID (Integer PK FK): 员工唯一标识符,外键。
- Items_sold (Integer): 销售的商品数量。
- Sales_amount (Varchar(50)): 销售金额。
-
DIM_Company (维度表:公司)
- Company_ID (Integer PK): 公司唯一标识符,主键。
- Industry_name (Varchar(50)): 行业名称。
- Industry_ID (Integer): 行业标识符。
- Company_name (Varchar(50)): 公司名称。
- Company_size (Integer): 公司规模。
-
DIM_Sales_Type (维度表:销售类型)
- Sales_type_ID (Integer PK): 销售类型的唯一标识符,主键。
- Type_name (Varchar(50)): 销售类型名称。
-
DIM_Sales_Rep (维度表:销售代表)
- Employee_ID (Integer PK): 员工唯一标识符,主键。
- First_name (Varchar(50)): 员工的名字。
- Last_name (Varchar(50)): 员工的姓氏。
-
Dim_Time (维度表:时间)
- Date_ID (Integer PK): 日期唯一标识符,主键。
- Year_ID (Integer): 年份标识符。
- Month_ID (Integer): 月份标识符。
- Week_ID (Integer): 周标识符。
- Purchase_date (Timestamp): 购买日期时间戳。
-
DIM_Product (维度表:产品)
- Product_ID (Integer PK): 产品的唯一标识符,主键。
- Prod_name (Varchar(50)): 产品名称。
- Category_ID (Integer): 产品类别标识符。
整体概述: 这个模型展示了一个数据仓库中的数据如何通过事实表和多个维度表进行组织。事实表(Fact_Sales)存储了核心业务事件的数据,而维度表提供了相关的详细信息。通过这种结构,可以进行多维数据分析和报表生成。
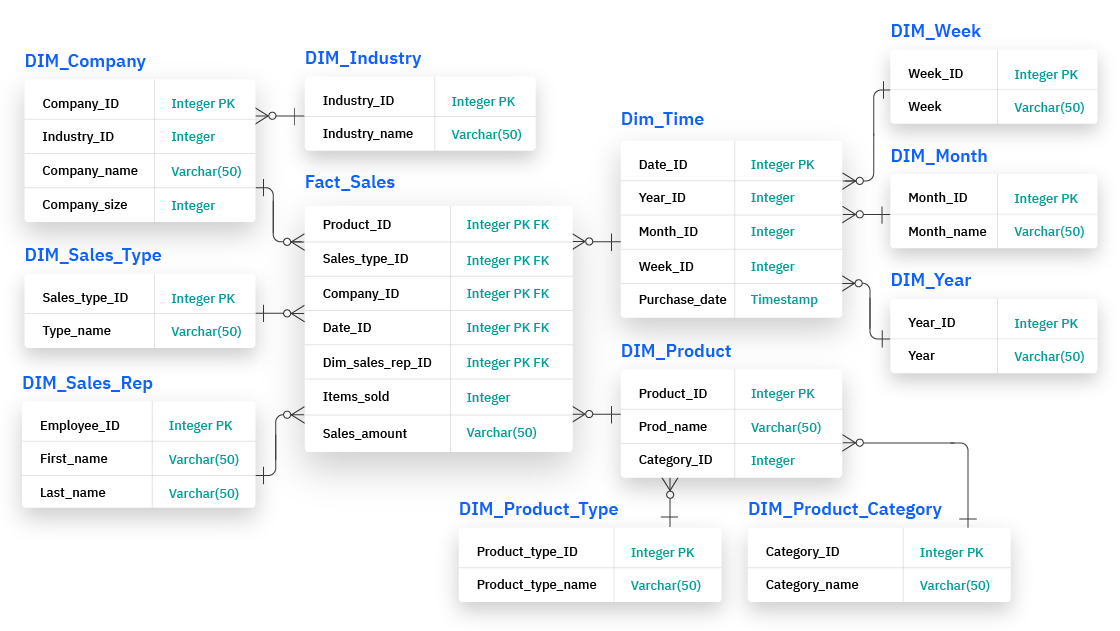
雪花型架构:雪花型架构是数据仓库中的另一种组织结构,但其采用度较低。在此架构中,事实数据表会连接到多个规范化的维度表,而这些维度表均有子表。雪花型架构的用户可享受到较低水平的数据冗余性,但这会以查询性能作为代价。
- 数据库 是用于日常操作的记录系统,重视数据的更新和一致性。
- 数据仓库 是用于商业分析的存储系统,重视数据的整理和查询性能。
- 数据湖 是数据的“大水池”,允许存储各种原始数据,以备未来使用。
- 数据市场 是数据的“交易场所”,专注于数据的交换、销售和购买。
它与关系型数据库最大的区别是
- 数据仓库:用于联机分析处理(OLAP),侧重于对大量历史数据的复杂分析和决策支持。主要应用场景包括数据挖掘、趋势分析、报表生成等。
- RDBMS:用于联机事务处理(OLTP),侧重于实时、高频的事务处理,如插入、更新、删除数据,适用于日常的业务操作。
数据仓库可以是关系型的,但与常见的关系型数据库相比,数据仓库在设计和优化上有不同的侧重点。数据仓库常常使用关系型数据库管理系统(RDBMS)的概念和技术,但其架构、存储方式和查询优化方式与传统的关系型数据库有所区别。
关系型数据仓库是一种基于关系模型的仓库系统,数据仍然以表格形式组织,并支持SQL查询,但经过优化以处理大规模数据和复杂查询操作。
常见的数据仓库实现
以下是一些具体的数据仓库实现,其中包括传统的关系型和现代的云原生实现:
1. Amazon Redshift
类型:云端数据仓库服务
特点:基于列式存储,支持SQL查询,专门为大规模数据处理和复杂查询优化。可以水平扩展,支持PB级数据。
用途:用于大型企业数据分析,支持并行处理和大规模聚合操作。
2. Google BigQuery
类型:完全托管的云端数据仓库
特点:支持SQL查询,基于列式存储,并通过Dremel技术进行查询优化,支持大规模数据的快速查询和分析。
用途:用于实时分析和大规模的数据查询与分析,尤其适合数据量非常大的场景。
3. Snowflake
类型:云原生数据仓库
特点:支持独立的计算和存储分离,基于列式存储,能够支持各种工作负载下的高效查询,且可以在多云环境中部署。
用途:适合各种规模的数据分析任务,尤其适合复杂查询和大数据分析。
4. Microsoft Azure Synapse Analytics(原 SQL Data Warehouse)
类型:基于云的企业级数据仓库
特点:结合了大数据和数据仓库功能,支持SQL和大数据查询,具有强大的可扩展性。
用途:适用于需要结合OLTP和OLAP的复杂应用场景,支持数据湖与数据仓库的集成分析。
5. Oracle Exadata
类型:企业级数据仓库解决方案
特点:硬件和软件高度集成,专门为高性能数据仓库操作而设计,支持SQL查询和并行处理。
用途:适用于大型企业的核心数据分析应用,特别是在对高性能有严格要求的场景。
6. Teradata
类型:企业级数据仓库解决方案
特点:支持大规模并行处理,优化了对大量数据的复杂查询处理能力,适用于PB级的数据量。
用途:主要用于企业的战略性分析,支持高性能的数据查询与管理。
7. Greenplum
类型:开源并行数据仓库
特点:基于PostgreSQL,支持大规模并行处理,适用于大数据量下的查询和分析操作,具有高水平的扩展性。
用途:适合需要在本地或云端进行大规模数据分析的场景。
8. IBM Db2 Warehouse
类型:企业级云数据仓库解决方案
特点:支持云端或本地部署,提供列式存储和压缩技术,以优化大数据分析工作负载。
用途:用于企业级的大规模数据分析应用,适合复杂的SQL查询与分析。
9. ClickHouse
类型:开源列式数据库
特点:专为大规模数据分析设计,支持高速的聚合查询,并对时间序列数据和日志数据有良好的优化。
用途:特别适合实时分析、日志和监控数据的处理。
总结
数据仓库可以是关系型的,并且基于关系数据库的技术进行实现,但为了优化分析和查询,大多数现代数据仓库会采用列式存储和并行处理等技术。常见的数据仓库实现包括云原生的解决方案(如Amazon Redshift、Google BigQuery)以及传统的企业级数据仓库(如Oracle Exadata、Teradata)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号