
KALI LINUX 工具大全之信息收集数字取证 --- Xplico (解释)
流量析构工具
所谓流量析构就是将流量中包含的应用层数据提取出来,比如一张图片通过http传输该工具就可以直接提取成为一张图片而不关心流量的具体细节。
官方网站:https://www.xplico.org/
在线版本:http://demo.xplico.org/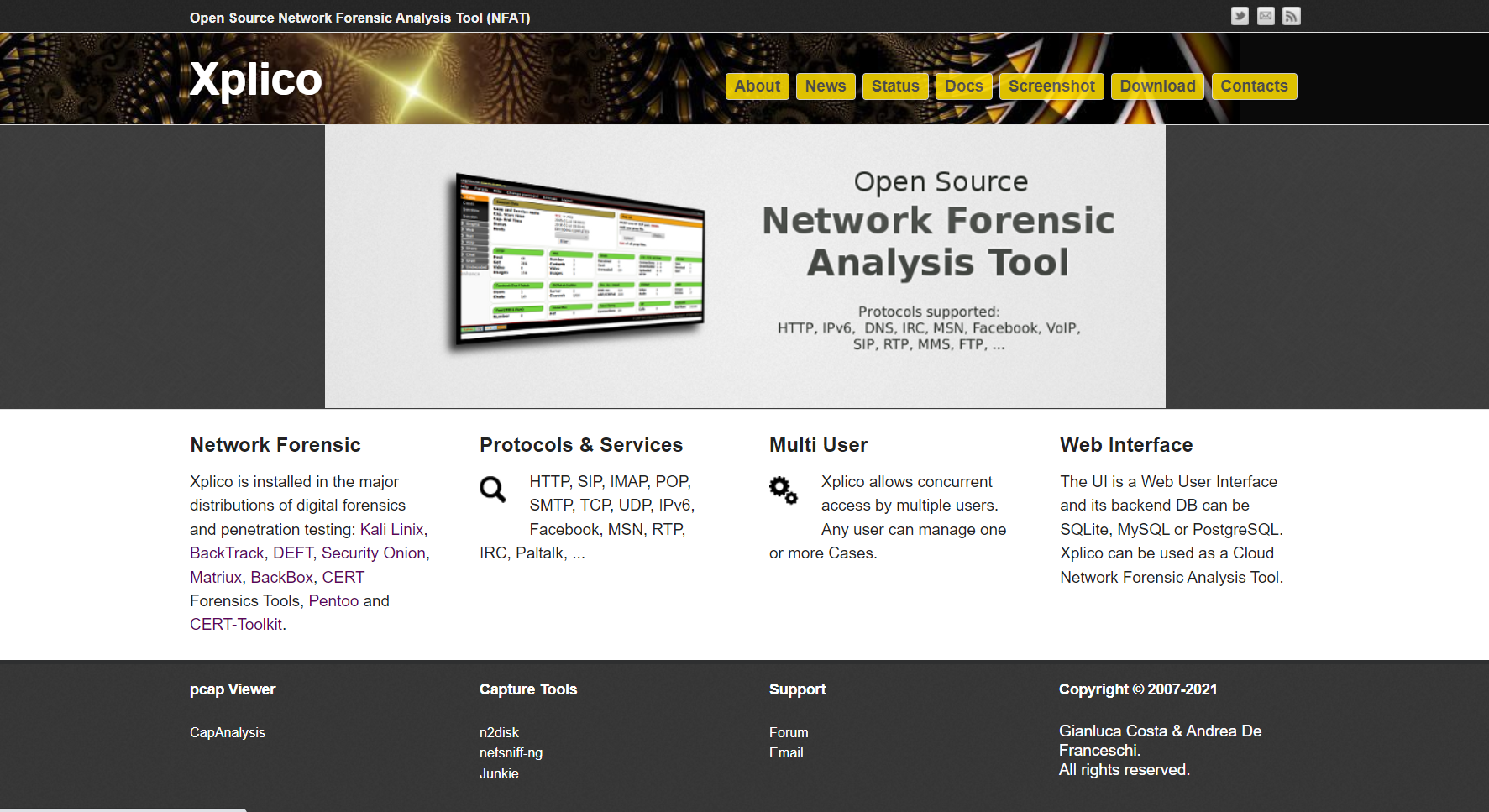
快速上手
---离线上传pcap文件提取图片等数据
1.开启xplico
kali 2021.4系统默认没有安装先用kali方源在线安装一下(所谓官方源就是理解为手机小米应用商店类似)
sudo apt install xplico
sudo service apache2 start
sudo service xplico start
打开浏览器 输入ip:9876 发现报错暂时没办法解决,但是并不是一点办法没有,xplico官方网站还提供有预装xplico的系统镜像文件,下载下来
https://sourceforge.net/projects/xplico/files/VirtualBox%20images/
下载最新1.2版本的,因为是国外网站需要魔法上网技术,获取下载链接使用百度网盘离线下载的方式,或者用英国的袋里点袋里下载,直接下载只有几kb速度。
解压后用你virtualbox新建虚拟机加载虚拟镜像文件vdi即可,这里就不详细讲了。
打开虚拟机系统,登录时候会连接twitter所以会卡住,需改注释一下网页代码,位置在
\opt\xplico\system\xi3\app\View\Layouts\default.ctp
或者
\opt\xplico\xi\app\View\Layouts\default.ctp
或者
直接搜索文件 sudo find / -name default.ctp
将下面
<script src="https://platform.twitter.com/widgets.js" type="text/javascript"></script>
改为
<!-- <script src="https://platform.twitter.com/widgets.js" type="text/javascript"></script> -->
开启xplico,在菜单中找到xplico start点击即可开启
2.分析pcap文件
打开浏览器 输入ip:9876
输入内置用户名:密码 xplico:xplico ,语音必需是英文
点击左侧新建案例,选择pcap,输入案例名称, 点击创建,点击新创建的案例名称进入
点击左侧新建会话,输入会话名称, 点击创建,点击新创建的会话名称进入
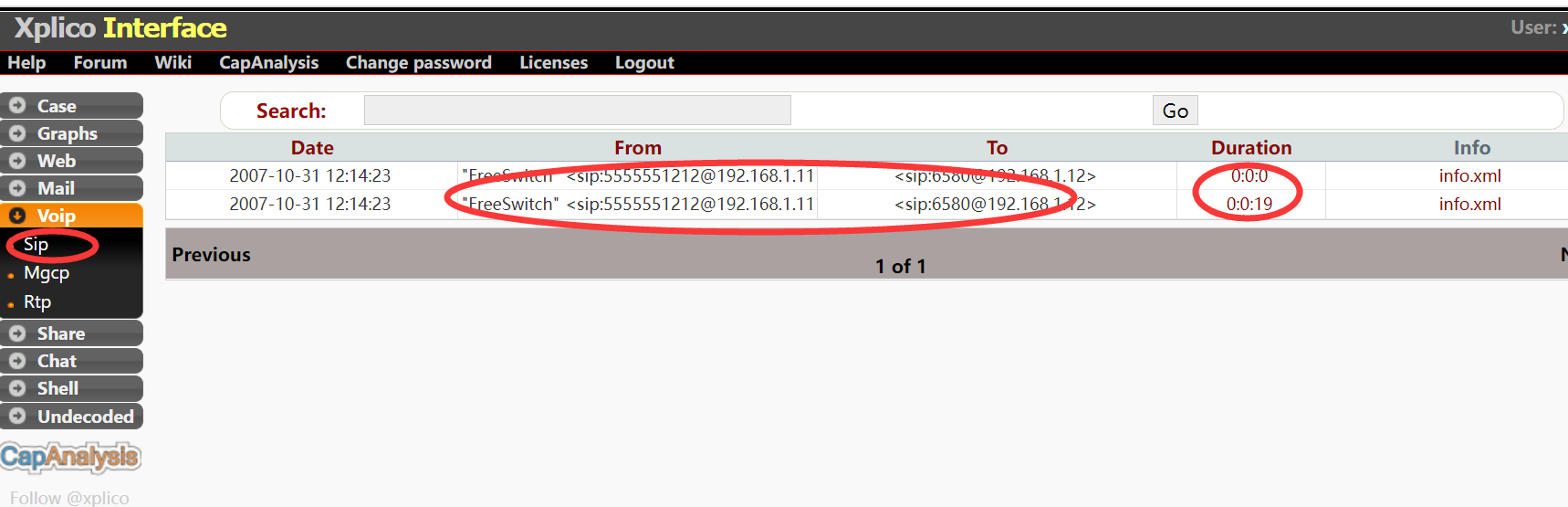
如下图所示,绿色表示的内容都可以在左侧找到对应关系
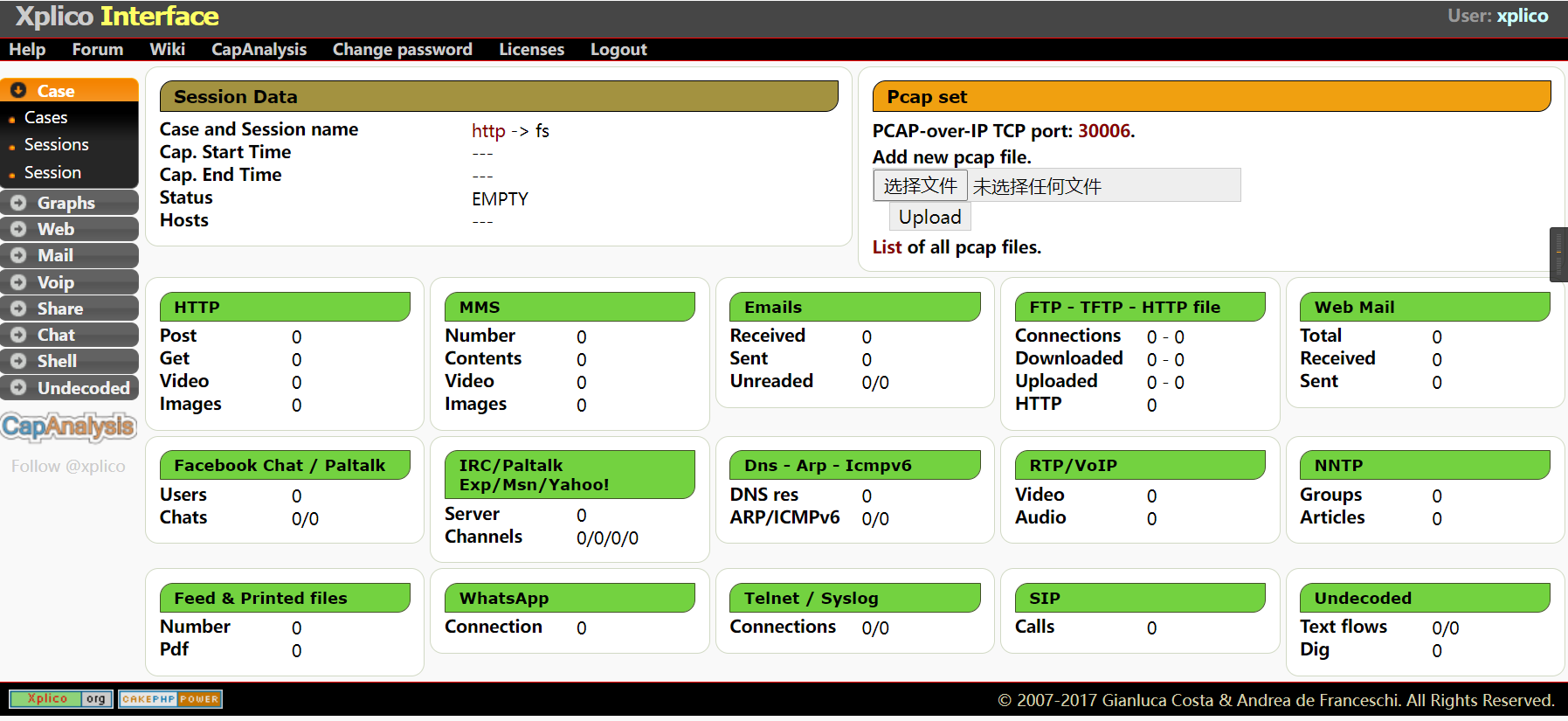
每次要分析pcap文件都要先创建案例和会话,才能导入文件
上传一个pcap文件(样本在这里 ://wiki.xplico.org/doku.php?id=pcap:pcap),上传之后等待解码一小会
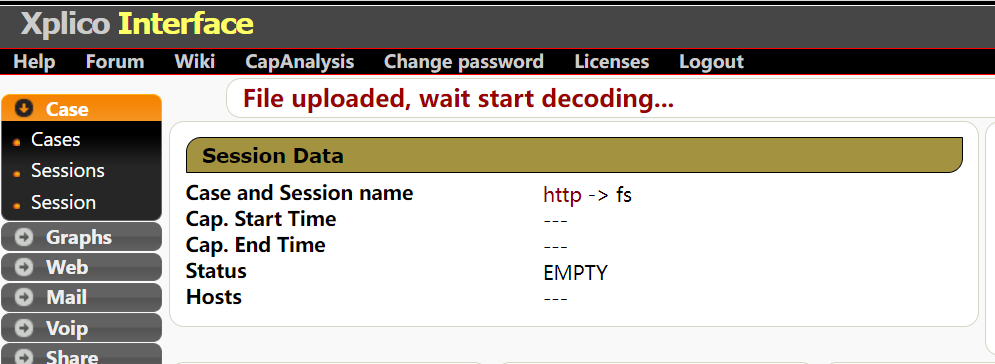
下图提示就是完成了
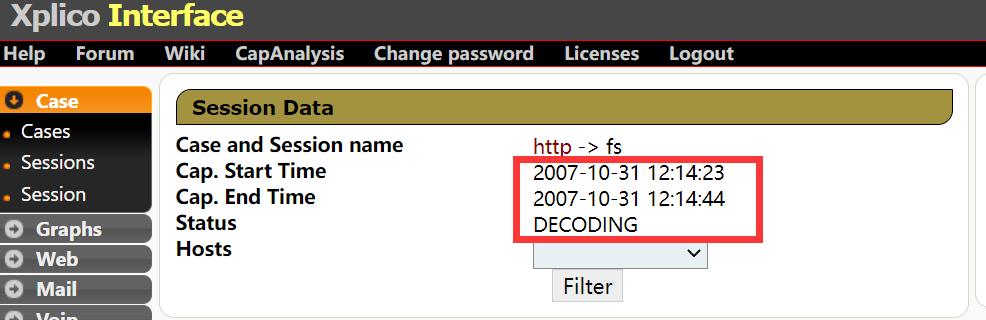
解码后会看见sip有两条内容

可以在左侧列表查看详细情况,点击duration可以看到具体的数据内容
详细介绍
Xplico 是拉丁文explico,英语是explain,译为解释
Xplico的目标是从互联网流量中提取包含的应用程序数据。例如,Xplico从pcap文件中提取每个电子邮件(POP,IMAP和SMTP协议),所有HTTP内容,每个VoIP呼叫(SIP,MGCP,H323),FTP,TFTP等。支持的协议和服务,HTTP, SIP, IMAP, POP, SMTP, TCP, UDP, IPv6, Facebook, MSN, RTP, IRC, Paltalk, ...
Xplico 允许多个用户同时访问。任何用户都可以管理一个或多个案例。UI 是一个 Web 用户界面,其后端数据库可以是 SQLite、MySQL 或 PostgreSQL。Xplico 可用作云网络取证分析工具。
Xplico 安装在数字取证和渗透测试的主要发行版中:Kali Linix、BackTrack、DEFT、Security Onion、Matriux、BackBox、CERT Forensics Tools、Pentoo和CERT-Toolkit。
Xplico并不是网络协议分析工具,而是开源网络取证分析工具 (NFAT)。所谓协议分析工具是指wireshark等工具对流量进行注释,网络取证工具则是提取流量的有效数据。比如pcap文件中有http流量,该工具可以提取出html页面、媒体等等有效数据。一直以来,大多数人都是使用wireshark进行流量分析、取证等,流量分析当然是wireshark更好,至于流量取证,其实更适合用xplico。
功能就两种离线流量取证和在线流量取证,离线使用文件pcap的已经介绍过,在线就是在创建案例是选择实时采集就这么点功能。还有一种用法就是ettercap开启arp欺骗抓取目标流量分析
优点:
开源免费,Xplico 是在GNU 通用公共许可证下发布的。
支持web管理
模块化。每个 Xplico 组件都是模块化的。输入接口、协议解码器(Dissector)和输出接口(dispatcher)都是模块;
缺点:
兼容性差,软件经常运行出错。
协议支持少且只能分析部分数据
功能单一,不能像wireshark直接导出对象不方便
web管理操作逻辑太复杂不直观,比如必需先创建案例和会话才能开始分析,分析结果必需点击左侧一个一个查看不方便,应该是分析出什么展示什么才直观
自动分析太慢,同时导入多个pcap文件要等很长时间
软件界面简陋,软件长期无人维护
帮助文档不全且陈旧,有些命令失效了
评分:想法不错但是用起来效果不好,总体评价一颗星
来源:http://sourceforge.net/projects/xplico/files/Xplico%20versions
https://github.com/xplico
Xplico主页 | Kali Xplico回购
- 作者:Gianluca Costa & Andrea De Franceschi.(还有一个项目 CapAnalysis
) - 许可证:GPLv2
xplico – Network Forensic Analysis Tool (NFAT)
什么是case案例,可以理解为项目
什么是会话,可以理解为项目流程
xplico v1.2.1
Internet Traffic Decoder (NFAT).
See http://www.xplico.org for more information.
Copyright 2007-2017 Gianluca Costa & Andrea de Franceschi and contributors.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
This product includes GeoLite data created by MaxMind, available from http://www.maxmind.com/.
usage: xplico [-v] [-c <config_file>] [-h] [-s] [-g] [-l] [-i <prot>] -m <capute_module>
-v 版本
-c 配置文件
-h 帮助
-i info of protocol 'prot'
-g 显示协议树图
-l 打印所有日志在屏幕上
-s 每秒打印解码状态
-m capture type module
NOTE: parameters MUST respect this order!
xplico Usage Example
Use the rltm module (-m rltm) and analyze traffic on interface eth0 (-i eth0):
xplico v1.0.1
Internet Traffic Decoder (NFAT).
See http://www.xplico.org for more information.
Copyright 2007-2012 Gianluca Costa & Andrea de Franceschi and contributors.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
This product includes GeoLite data created by MaxMind, available from http://www.maxmind.com/.
Configuration file (/opt/xplico/cfg/xplico_cli.cfg) found!
GeoLiteCity.dat found!
pcapf: running: 0/0, subflow:0/0, tot pkt:1
pol: running: 0/0, subflow:0/0, tot pkt:0
eth: running: 0/0, subflow:0/0, tot pkt:1
pppoe: running: 0/0, subflow:0/0, tot pkt:0
ppp: running: 0/0, subflow:0/0, tot pkt:0
ip: running: 0/0, subflow:0/0, tot pkt:0
Xplico 官方存储库下载
如果您使用的是32 位或64位 Ubuntu 11.04 ↔ 16.10,那么您可以使用我们的官方存储库:
sudo bash -c 'echo "deb http://repo.xplico.org/ $(lsb_release -s -c) main" >> /etc/apt/sources.list' #添加xplico官方源 sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 791C25CE #导入官方服务器证书 sudo apt-get update sudo apt-get install xplico
或者来自 SourceForge第三方存储库下载
要想轻松安装Xplico,你只需从终端执行这个脚本(感谢Claus Valca)
Ubuntu 12.04 32位
sudo apt-get update
sudo apt-get install -y gdebi sed #安装环境
wget downloads.sourceforge.net/project/xplico/Xplico%20versions/version%201.0.0/xplico_1.0.0-ubuntu_12.04_i386.deb #从sf网站下载软件安装包
sudo gdebi -n xplico* #安装
sudo find /etc/php5/apache2/php.ini -exec sed -i.bak 's/post_max_size = 8M/post_max_size = 800M/g; s/upload_max_filesize = 2M/upload_max_filesize = 400M/g' {} \; #修改apache配置文件
sudo service apache2 restart
sudo service xplico restart
firefox localhost:9876
Ubuntu 12.04 64位
把上面32位的下载文件名改为
xplico_1.0.0-ubuntu_12.04_amd64.deb 即可
Ubuntu 11.04 and 11.10 32位
sudo apt-get update && sudo apt-get install -y gdebi sed && wget downloads.sourceforge.net/project/xplico/Xplico%20versions/version%201.0.0/xplico_1.0.0_i386.deb && sudo gdebi -n xplico* && sudo find /etc/php5/apache2/php.ini -exec sed -i.bak 's/post_max_size = 8M/post_max_size = 800M/g; s/upload_max_filesize = 2M/upload_max_filesize = 400M/g' {} \; && sudo service apache2 restart && sudo service xplico restart && firefox localhost:9876
Ubuntu 11.04 and 11.10 64位
把上面32位的下载文件名改为
xplico_1.0.0_amd64.deb
从 0.6.2 版开始,有一个新工具可以帮助从命令行创建新案例和/或新会话。此工具与 SQLite 和 MySQL DB(lite 和ximysql调度程序和 XI)兼容。工具路径为/opt/xplico/script/session_mng.pyc,使用非常简单。
新案例
要使用名为“April”的会话创建一个名为“AP home”的新案例,命令是:
/opt/xplico/script/session_mng.pyc -n "AP home" "April"
上面不行执行下面的命令
/opt/xplico/script/session_mng.pyc -n "AP home" "April"
输出为您提供案例 ID(添加新会话所必需的)以及复制/上传此新会话的 pcap 文件的路径。示例输出:
案例 ID:1 将 pcap 文件放在这里:/opt/xplico/pol_1/sol_1/new
新会话
要在 ID 为 1 的情况下再添加名为“May”的新会话,命令是:
/opt/xplico/script/session_mng.pyc -a 1 "May"
上面不行执行下面的命令
/opt/xplico/script/session_mng.py -a 1 "May"
同样,输出结果会给你一个路径,让你为这个新的会话复制/上传你的 pcap 文件。
配置文件
如果您开发了一个新的协议解析器并为您的解析器定义了一个新的PEI,那么您可以在 session_mng.pyc 配置文件中添加您自己的协议目录输出(由调度程序和 XI 使用)。这个文件是/opt/xplico/cfg/sol_subdir.cfg(来自源代码:system/script/sol_subdir.cfg)。sol_subdir.cfg 示例:
# 这个文件的每一行都是 session (sol) 目录中的一个目录名。 # 注释必须以'#'开头,作为这一行!
# Every line of this file is the name of a direcory in session (sol) directory. # A comment must start with '#', as this line! http mail ftp ipp pjl mms gea tftp dns nntp fbwchat telnet webmail httpfile grbtcp grbudp rtp sip irc paltalk_exp paltalk msn webmsn
PCAP2WAV - RTP2WAV
安装步骤
-
从源代码目录启动脚本 pcap2wav_tgz.sh
-
从 /下 和具有root 用户解压 pcap2wav.tgz :
cd /; sudo tar xzvf pcap2wav.tgz
为 web 根目录 /opt/pcap2wav/www 配置 Apache
NameVirtualHost *:9878
<VirtualHost *:9878>
ServerAdmin info@xplico.org
DocumentRoot /opt/pcap2wav/www
<Directory "/opt/pcap2wav/www">
Options All
AllowOverride All
Order allow,deny
allow from all
</Directory>
ErrorLog /var/log/apache2/pcap2wav_error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel warn
CustomLog /var/log/apache2/pcap2wav_access.log combined
</VirtualHost>
在文件/etc/apache2/ports.conf的结尾处添加这一行 Listen 9878 (Add ar the end of the file /etc/apache2/ports.conf the line Listen 9878)
启动脚本 /opt/pcap2wav/pcap2wavd.sh :
sudo /opt/pcap2wav/pcap2wavd.sh
现在可以访问pcap2wav( http://localhost:9878 )的网页了。
Xplico DB 升级(仅适用于 1.0.0 或更高版本)
如果你使用Xplico Ubuntu软件包,请不要使用本指南。
在安装新版本的Xplico之前,你必须保存所有的数据和SQLite(MySQL)数据库。
sudo mkdir /opt/xplico_bck sudo mv /opt/xplico/pol_* /opt/xplico_bck sudo mv /opt/xplico/xplico.db /opt/xplico_bck
现在您可以安装新版本,并且在安装结束时您必须运行以下命令:
sudo mv /opt/xplico/xplico.db /opt/xplico/xplico_new.db sudo mv /opt/xplico_bck/* /opt/xplico/ cd /opt/xplico/script/db/sqlite sudo ./create_xplico_db.sh sudo / opt/xplico/script/db/sqlite/upgrade_db.py sudo rm -f /opt/xplico/xplico_new.db sudo rm -rf /opt/xplico/xi/app/tmp/cache/models/* sudo rm -rf / opt/xplico/xi/app/tmp/cache/views/*
源代码
Xplico 使用其他项目的源代码、库、数据库和应用程序,其中一些在 Xplico 代码中,但其他没有,因此要构建具有所有功能的 Xplico(系统),必须下载(编译/安装)这些软件:
如果您想要连接的地理和时间可视化(GeoIP C API和 GeoLite City),或者如果您想要重建使用网络打印机(GhostPCL)打印的文档,或者如果您想要基于 RTP 解码 VoIP(videosnarf),则可选软件是必需的.
依赖关系
Xplico 代码依赖于这些库:
-
Pcap 库:libpcap
-
SQLite 库:libsqlite3
-
Zlib:zlib1g-dev
Xplico 还取决于这些应用程序:
构建它
在本节4) 中,我们描述了编译和安装(如果需要)Xplico 的步骤。某些步骤是可选的,取决于您决定使用的功能。
-
首先解压压缩包:
tar -xzvf xplico-xxxx.tgz -
编译 nDPI 库。从解压 xplico 的 SAME 目录中:
svn co https://svn.ntop.org/svn/ntop/trunk/nDPI cd nDPI ./configure --with-pic 制作
无需安装 nDPI。
-
在 Xplico 分发目录中运行make。希望您不会遇到任何问题。
-
运行make 后,您将看到 xplico 二进制文件和模块目录。
-
如果您希望(不是必需的)解码网络打印机作业,请确保您有 Ghostpcl。编译 Ghostpcl 无需安装。将“ pcl6 ”应用程序复制到 Xplico 主目录中(在 xplico 二进制文件的同一目录中)。
-
如果您想解码 RTP、SIP、MEGACO、H323、MGCP... VoIP 音频编解码器,请确保您有 Videosnarf-0.63。将“videosnarf”复制到 Xplico 主目录(在 xplico 二进制文件的同一目录中)。
-
运行“ ./xplico ”并确保一切正常。请注意,您必须具有 root 权限才能捕获实时数据!
-
如果您使用 Xplico 接口,则运行以下命令:
进行安装
从源代码安装 Xplico Interface (XI)
Xplico Interface 是用 PHP 开发的,它基于CakePHP框架。该接口可以使用或SQLite数据库或MySQL数据库,目前仅SQLite dispatcher在Xplico解码器中完成并测试。
MySQL 数据库调度程序和 MySQL 的 XI 配置文件可以在这里获得。
源代码
安装
按照此处给出的说明自动进行安装。
所有 PHP 代码和 XI 的根源代码都可以在 /opt/xplico/xi 目录中找到。
您必须更改这两个目录的访问权限:
-
/选择/xplico/xi
-
/选择/xplico/cfg
Apache 用户必须具有对 /opt/xplico/cfg 的读写访问权限
阿帕奇配置
Apache 配置的示例文件可以在/opt/xplico/cfg/apache_xi 中找到
。配置文件的主要特点是:
-
根目录:/opt/xplico/xi
-
要允许 PHP 代码正确运行,必须在 Apache Web 服务器中启用:
-
php5
-
php5-sqlite
-
改写
-
-
为简单起见(但不安全)从 Apache 配置文件更改:
-
“选项…… ”到“选项全部”
-
“ AllowOverride .... ” 到 “ AllowOverride All “
-
为了能够上传大型 pcap 文件,您必须更改php.ini文件中的post_max_size和upload_max_filesize值:
-
post_max_size = 100M
-
upload_max_filesize = 100M
浏览器
在 Firefox 中启用代理。代理IP是您安装Xplico的机器的IP,端口为80或9876(Apache端口在配置文件中定义)。查看 Xplico 接口的 URL 是:http://IP:port。如果您使用机器名称而不是 IP ,则您可能不会在 Web 界面中输入。
默认用户
在默认的用户名和密码是:
-
用户名:xplico
-
密码:xplico
在默认的管理员用户名和密码是:
-
用户名:admin
-
密码:xplico
要为 Xplico 创建 .deb 包,请按照以下说明操作:
1º) 下载源代码
#wget http://developer.berlios.de/project/showfiles.php?group_id=8919
(选择即 xplico-0.5.4.tgz 或更高版本)
2º) 解压
# tar xvfz xplico-0.5.4.tgz # cd xplico
3º) 安装这些工具
# apt-get install devscripts build-essential dpkg-dev dh-make debhelper fakeroot
4º) 如果您需要更改版本号,请按照现有语法编辑此文件。
# nano debian/changelog
5º) 创建包
# dpkg-buildpackage -rfakeroot
6º) 检查包装是否有任何错误:
# lintian ../xplico-0.5.4.deb
如果您有任何问题,可以使用Xplico 的论坛
使用 Xplico
控制台模式
我们这里只描述控制台模式模式,如果你使用 Web 界面,那么你必须看到Web 界面页面。
控制台模式下的 Xplico 允许您解码单个 pcap 文件、pcap 文件目录或从以太网接口(eth0、eth1 等)实时解码。
要选择输入类型,您必须使用“ -m ”选项。“ -m ”选项允许您加载特定的 xplico 捕获接口(捕获模块)。
可能的捕获接口是“ pcap ”和“ rltm ”。如果您运行“ ./xplico -h -m pcap ”,您将获得使用 pcap 接口的帮助,显然“ ./xplico -h -m rltm ” 可以帮助您使用实时接口。在控制台模式下,xplico 提取的所有文件默认放置在“xdecode”目录中。每个源IP和协议都有一个特定的目录,在这个目录中你可以找到解码数据。
例如,如果 IP 为 192.168.1.123 的 PC 发送了一封电子邮件,而 IP 为 192.168.1.159 的 PC 访问了站点www.iserm.com 和www.xplico.org,那么 xdecode 目录树是这样的:
解码/ |-192.168.1.123/ | `-电子邮件/ | |-in/ | `-出/ | `-192.168.1.159/ `-http/ |-www.isrm.com `-www.xplico.org
使用示例
-
如果你必须解码 test.pcap,你必须启动这个命令:
./xplico -m pcap -f test.pcap在解码结束时,您的文件位于 xdecode/<ip>/http、xdecode/<ip>/mail、xdecode/<ip>/ftp、……而 kml 文件(谷歌地球)位于 xdecode/
-
如果你必须解码一个目录“/tmp/test”,里面有很多 pcap 文件,你必须启动这个命令:
./xplico -m pcap -d /tmp/test在解码结束时,您的文件位于 xdecode/<ip>/http、xdecode/<ip>/mail、xdecode/<ip>/ftp、……而 kml 文件(谷歌地球)位于 xdecode/
-
如果您必须实时解码 eth0,则命令是:
./xplico -m rltm -i eth0打破收购:^C。在解码结束时(解码是实时的),您的文件位于 xdecode/<ip>/http、xdecode/<ip>/mail、xdecode/<ip>/ftp 和 kml 文件(Google Earth)中在 xdecode/
Xplico 有很多解码模块,这些模块在modules 目录下,要启用或禁用一个模块你必须修改xplico.cfg文件(默认在./config/ 目录)。
Google Earth 的 GeoMap 文件 (kml) 每 30 秒更新一次。
解剖图
命令:
./xplico -g
为您提供解剖器之间的关系图,显然仅适用于启用的解剖器。
解剖信息
命令:
./xplico -i <协议>
为您提供名为协议的解剖器的所有信息。
Xplico 接口
使用此界面可以创建新案例,引入新的捕获文件,查看解码器提取的所有数据。
首先我们必须登录: 默认用户是xplico,密码是xplico。
默认用户是xplico,密码是xplico。
用户管理员:admin → xplico
案子
此时我们要创建一个新的案例。在 Xplico 中,这种情况与监听点(网络中的捕获点)重合,这是因为 Xplico 系统(解码管理器、解码器、操纵器等)试图将提取的数据关联到:
-
模拟浏览器缓存
-
重建P2P文件(多日下载)
-
重建使用类似DownThemAll工具下载的文件
-
… 等等
对于每种情况,我们必须定义:
-
一个名字(唯一更好)
-
数据来源,或者是来自文件还是来自网络接口
-
可选的外部参考。这个外部参考可以帮助您找到这个新案例的存储库。

在这一点上,我们有一个所有创建的案例的列表。

会议
一个案例由一个或多个会话组成,然后选择我们在会话页面中输入的案例。在Xplico每个会话 包含在一个特定的时间间隔中取得的数据,每个会话的时间间隔必须是不相交的和的每个陈述时间会话必须大于或等于比上的结束时间会话。
要在案例中创建新会话,我们必须单击“ New sol ”按钮。会话仅由名称定义:会话名称

如前所述,每个案例都可以有多个session。

捕获文件
选择会话,我们将进入为此会话解码的数据的摘要页面。

在每个会话中,我们可以引入一个或多个捕获文件。这可以用“ Pcap set ”形式制作。

单击“列表”,我们将获得输入的数据列表。
在“会话数据”中,我们报告案例名称和会话,输入数据的开始和结束时间。

在“会话数据”中还可以选择源主机,查看该主机的数据。
实时捕捉
如果您已经创建了一个“ Live Capture Case ”,那么您可以从XI 的Session页面中选择网络接口并开始/停止采集。

电子邮件
电子邮件页面显示所有已发送和已接收电子邮件的列表
 和:
和:
-
发货时间
-
主题
-
发送方
-
接收者,即使作为密件抄送发送
-
电子邮件的大小(随附)
搜索表单允许我们按主题、收件人和发件人查找电子邮件。
选择一封您看到的电子邮件,即使它是 html 格式并包含附加文件。

对于每封电子邮件,我们可以获得仅包含它的流的 PCAP。为此,我们必须将鼠标指向信息行并单击pcap链接。

网络
进入 Web 菜单,我们可以查看会话的所有 HTTP 内容。我们可以选择或搜索内容。

单击链接将打开一个新页面(分离的),其中使用 Xplico System 将重建该页面的完整 url,包含在解码的 pcap 中。Xplico System 模拟浏览器的原始缓存,当然如果 pcap(在所有会话的情况下)包含模拟缓存的数据。
当且仅当在 Firefox 中启用代理并且它指向运行 Xplico System 的服务器时,一切才能正常工作。
此外,对于每个内容,我们可以通过单击方法链接来检查请求头、响应头和正文。
可以仅在传输内容的流内部实现 pcap。

如果内容是视频(flv 格式),我们可以直接看到视频,点击 url。

图片
要获得 HTTP 协议传输的所有图像的概览,我们可以访问菜单图像。

打印机
在此页面中,我们可以查看使用“打印机命令语言”的网络打印机打印的所有文档的列表。每个文档都转换为 pdf 格式。
FTP 和 TFTP
FTP和TFTP 的页面类似。
在主页面中,我们可以看到所有连接到 ftp/tftp 服务器的列表,以及相应的下载和上传的文件数量。

对于每个服务器,点击链接,我们可以看到服务器信息、用户名、密码、命令、下载的文件和上传的文件。

对于每个文件,您可以拥有相应的 pcap 文件,该文件仅包含文件的数据包。

您还可以检查与服务器交换的所有命令。

域名系统
该DNS页面显示所有DNS没有错误响应,列出规范名称,如果它存在,响应的第一个IP。同样,您可以进行研究或托管或 IP。

从主DNS页面中的链接图表可以用图表表示DNS响应的统计数据,或查看 50 个最受欢迎的主机的图表。

最受欢迎的主持人。

彩信
如果 MMS 消息(多媒体消息服务)通过 HTTP 协议传输,则 Xplico 解码器可以将 MMS 消息分解为其内容,即文本、视频和图像。
彩信主页报告已解码的彩信列表,

点击链接我们可以看到消息的内容。

如果您有二进制(原始)形式的彩信,那么您可以使用mmsdec工具对其进行解码。
NNTP
地理地图
在会话解码期间,Xplico 会生成一个 KML 文件,该文件与 Google Earth 一起使用,允许您拥有由 Xplico 解码的连接的时间和地理地图。

PCAP-over-IP
从 Xplico 1.0.0 开始,我们添加了PCAP-over-IP 功能。
从 Xplico 接口,您可以查看启用了 PCAP-over-IP 的端口号。

如果 Xplico 服务器的 IP 为192.168.0.195,则传输文件my_file.pcap的命令是:
cat my_file.pcap | nc 192.168.0.195 30001
配置文件
Xplico 的配置文件定义了:
-
要使用的解剖器
-
每个解剖器的日志级别
-
放置所有临时文件的目录
-
日志文件的名称
-
要使用的调度程序
-
与机械手的联系
配置文件的默认路径位置为:
-
./配置
-
/选择/xplico/cfg
在控制台模式下(从 shell),我们可以使用-c选项从命令行选择配置文件:
./xplico -c <my_config_file> -m pcap -f example.pcap
配置文件由四部分组成:
-
解剖器定义
-
调度员定义
-
机械手连接定义
-
通用定义
解剖器定义
在 Xplico 中,所有解剖器(所有模块)必须位于同一目录中。该目录由MODULES_DIR参数定义。
MODULES_DIR=/opt/xplico/bin/modules
解剖器由MODULE参数 定义
MODULE=dis_ip.so
并且解剖器的日志级别由LOG参数定义,该参数应在解剖器定义的同一行上。
MODULE=dis_ip.so LOG=FEWITDS
LOG 参数的每个字母启用特定的日志级别。
调度员定义
调度程序是 Xplico 的组件,用于组织数据、将数据插入数据库和适当的位置/路径。
使用 Xplico,您可以创建各种类型的调度程序以满足您的需求。
目前的调度员是:
-
none (disp_none.so):这是一个非常简单的调度器(调度器的一个例子),它不组织提取的数据(数据留在临时目录中)
-
lite (disp_lite.so):这个调度器使用SQLite作为DB,用于资源较少的Live CD。
-
cli (disp_cli.so):这个调度器将重建的数据组织在目录 xdecode 中,按照 IP 和协议类型进行组织: xdecode/<ip>/http, xdecode/<ip>/mail, xdecode/<ip>/ftp, ...
-
ximysql (disp_ximysql.so):这个调度器使用MySQL作为DB,用于大量数据。
调度程序由 DISPATCH 参数定义
调度=disp_none.so
并且调度器的日志级别由LOG参数定义,应该在调度器定义的同一行
DISPATCH=disp_none.so LOG=FEWITDS
LOG 参数的每个字母启用特定的日志级别。
配置文件中只能定义一个调度程序。
机械手连接定义
Xplico System 中的操纵器(聚合器、转码器、相关性)是组织和关联从解码器中提取的数据的应用程序。
可能有多个同时活动的操纵器。
操纵器的例子是:
-
http
-
http 快速下载(例如管理 DownThemAll)
-
饲料阅读器
-
网络 DAV
-
中小企业
-
点对点
Xplico(解码器)通过插座连接到操纵器。
一个机械手连接由同一行中的三个参数 AGGREG、AGHOST 和 AGPORT 定义
AGGREG=http AGHOST=127.0.0.1 AGPORT=23456
AGGREG定义了操纵器协议类型,AGHOST定义了操纵器运行的IP地址,AGPORT定义了操纵器的监听端口。
通用定义
通过 DISPATCH_PARALLEL 我们可以选择调度器的细化方式。实际上我们可以选择是否运行在调度器执行的并行处理中。选择取决于我们如何设计调度程序。和
DISPATCH_PARALLEL=1
计算是并行执行的,
DISPATCH_PARALLEL=0
计算是连续进行的。
使用 CAPTURE_LOG 参数,我们可以定义捕获模块的日志级别。
CAPTURE_LOG=FEWITDS
使用CORE_LOG我们可以定义Xplico的主要代码的日志级别(所有部分/代码没有模块)
CORE_LOG=FEWITDS
使用 LOG_DIR_PATH 和 LOG_BASE_NAME 参数,我们可以定义日志文件的路径和基本名称
LOG_DIR_PATH=tmp/ LOG_BASE_NAME=xplico
最后 TMP_DIR_PATH 定义了创建临时文件的目录路径
TMP_DIR_PATH=tmp/xplico
日志级别
Xplico 有七个日志级别。日志级别用字母表示,表示我们可以启用相应级别的日志的字母。
| 信 | 日志级别 |
|---|---|
| F | 致命的 |
| 乙 | 错误 |
| 宽 | 警告 |
| 一世 | 信息 |
| 吨 | 痕迹 |
| D | 调试 |
| 秒 | 启动/统计 |
如果出现Fatal、Error 或Warning情况,Xplico 会生成一行日志(如果级别已启用)和一个 XML 文件(日志行标识此 xml 文件)。使用此 XML 文件和 xml2pcap.php 脚本,我们可以隔离生成日志的事件。要使用的命令是:
/opt/xplico/script/xml2pcap.php xml_file.xmlisolate.pcap
使用这个命令,我们有可能让 PCAP 只包含导致问题的数据(流)。很容易猜测,这有助于我们调试和开发解剖器。
示例文件
配置文件的一个例子是:
#------------ xplico 的配置文件 #---------- 模块参数 #------ 模块目录路径 MODULES_DIR=/opt/xplico/bin/modules #------ 模块名称和日志掩码 #---- 面具类型: #---- F -> 致命 #---- E -> 错误 #---- w -> 警告 #---- 我 -> 信息 #---- T -> 跟踪 #---- D -> 调试 #---- S -> 启动/统计 #-- 示例:MODULE=dis_gian LOG=FEWITS MODULE=dis_pcapf.so LOG=FEWITDS MODULE=dis_pol.so LOG=FEWITDS MODULE=dis_lis.so LOG=FEWITDS MODULE=dis_eth.so LOG=FEWITDS MODULE=dis_ppp.so LOG=FEWITDS MODULE=dis_ip.so LOG=FEWITDS MODULE=dis_ipv6.so LOG=FEWITDS MODULE=dis_tcp.so LOG=FEWITDS #MODULE=dis_tcp_soft.so LOG=FEWITDS MODULE=dis_udp.so LOG=FEWITDS MODULE=dis_http.so LOG=FEWITDS MODULE=dis_pop.so LOG=FEWITDS MODULE=dis_imap.so LOG=FEWITDS MODULE=dis_smtp.so LOG=FEWITDS MODULE=dis_httpfd.so LOG=FEWITDS MODULE=dis_sip.so LOG=FEWITDS MODULE=dis_rtp.so LOG=FEWITDS MODULE=dis_sdp.so LOG=FEWITDS #MODULE=dis_l2tp.so LOG=FEWITDS #MODULE=dis_vlan.so LOG=FEWITDS MODULE=dis_ftp.so LOG=FEWITDS MODULE=dis_dns.so LOG=FEWITDS MODULE=dis_icmp.so LOG=FEWITDS MODULE=dis_nntp.so LOG=FEWITDS MODULE=dis_irc.so LOG=FEWITDS MODULE=dis_ipp.so LOG=FEWITDS MODULE=dis_pjl.so LOG=FEWITDS MODULE=dis_mms.so LOG=FEWITDS MODULE=dis_sll.so LOG=FEWITDS MODULE=dis_tcp_grb.so LOG=FEWITDS MODULE=dis_udp_grb.so LOG=FEWITDS #-----------调度模块 #------ 模块名称 #DISPATCH=disp_xsystem.so LOG=FEWITDS #DISPATCH=disp_lite.so LOG=FEWITDS DISPATCH=disp_none.so LOG=FEWITDS #DISPATCH=disp_embedded.so LOG=FEWITDS # - - 旗帜。如果 0 模块 'DISPATCH' 只从一个线程调用, #---- 否则 (1) 解剖器的任何线程调用 'DISPATCH' 函数模块 concorentialy DISPATCH_PARALLEL=1 #------ 聚合器连接 #AGGREG=http AGHOST=127.0.0.1 AGPORT=23456 # - - - - - 日志 #---- 捕获掩码 CAPTURE_LOG=FEWITDS #----核心面具 CORE_LOG=FEWITDS #---- 日志目录和名称库 LOG_DIR_PATH=tmp/ LOG_BASE_NAME=xplico #---------- TMP目录路径 TMP_DIR_PATH=tmp/xplico
如何解码大量数据
从 0.6.2 版本开始,有一个名为session_mng.pyc的新脚本,以方便管理,对于旧版本,请阅读以下内容。
如果您有GB或 TB 的数据要解码,那么步骤如下(显然是在安装 Xplico 和 XI 之后):
须藤须 cd /opt/xplico rm -rf pol_* rm xplico.db cd /opt/xplico/script/db/sqlite2 ./create_xplico_db.sh
使用 XI 仅创建一个案例,在此案例中仅创建一个会话。现在运行 DEMA(解码管理器):
/opt/xplico/script/sqlite_demo.sh
此时将所有 pcap 文件(随时甚至每天)复制到此目录中(文件名必须按捕获时间的字母顺序排列):
/opt/xplico/pol_1/sol_1/new/
使用 DB sqlite 解码很慢。在 CLI 中,您的速度最高,但提取的数据更难以阅读和查看。
XI 和现场捕捉
如果您使用的是 0.5.3(或更新)版本的 Xplico,那么您可以在从 XI 创建“案例”时选择实时捕获。
对于旧版本的 Xplico,要在实时捕获中使用 XI,您可以按照以下步骤操作:
-
删除 /opt/xplico/xplico.db
-
删除所有 /opt/xplico/pol
-
执行:
cd /opt/xplico/script/db/sqlite2 ./create_xplico_db.sh
-
with XI 只创建一个案例
-
在这种情况下,只创建一个聆听会话 (sol)
此时,如果您进入/opt/xplico/script您可以找到脚本rt_demo.sh。编辑此文件,在 tcpdump 命令中更改网络接口,并在运行脚本后(以 root 用户身份)。记住:不要运行 sqlite_demo.sh
禁用校验和验证
从 Xplico 0.6.0 开始,您可以通过管理员页面禁用校验和验证和来自 XI 的单个解剖器。
对于 0.6.0 之前的 Xplico 要禁用所有校验和验证,需要使用配置文件“xplico_cli_nc.cfg”。IE:
cp /opt/xplico/cfg/xplico_cli.cfg /opt/xplico/cfg/xplico_cli.CHECKSUM_ACTIVATED.cfg cp /opt/xplico/cfg/xplico_install_lite.cfg /opt/xplico/cfg/xplico_install_lite.CHECKSUM_ACTIVATED.cfg cp /opt/xplico/cfg/xplico_cli_nc.cfg /opt/xplico/cfg/xplico_cli.cfg cp /opt/xplico/cfg/xplico_install_lite_nc.cfg /opt/xplico/cfg/xplico_install_lite.cfg
解码环回接口
只需禁用校验和验证。
获取从解码流量创建的文件列表
对于第三个应用程序,了解 Xplico 在解码文件夹中创建了哪些文件可能很有用。
文件 /opt/xplico/lastdata.txt 将每隔几秒写入一次。您的应用程序可以将其移动到另一个文件夹并处理其中包含的路径,并且 Xplico 将从那一刻起使用新路径再次创建该文件(Xplico 将路径附加到该文件,因此很容易进行自动处理,并且文件不会显着增长)。要为每个解决方案获取一个“lastdata.txt”(案例中的会话:在其“pol_xy”文件夹中),请更改
XS_ONE_FILE_PATHS=1
编译前在“dispatch/lite/lite.h”。
版本 0.6.0
在此版本中,每个调度员都有一个模块来启用此功能
命令行模式
从文件 /opt/xplico/cfg/xplico_cli.cfg(和 /opt/xplico/cfg/xplico_cli_nc.cfg)更改行
DISPATCH=disp_cli.so LOG=FEWITDS
到
DISPATCH=disp_cli_list.so LOG=FEWITDS
XI模式
通过 XI 的配置页面。
版本 0.5.8 到 0.5.4
要激活此功能,您必须使用以下命令编译项目:
使 CLI_LIST=1
版本 0.5.3
在 0.5.3 版本中,它仅适用于 xplico_cli:# xplico -m [rltm/pcap] -[i eth0/f file.pcap]
分析样本
https://wiki.xplico.org/doku.php?id=pcap:pcap
XI Cookie 劫持
此示例说明如何在Windows Live 中使用XI Cookie 劫持工具。
Windows Live 和 Hotmail
Xplico 使用网络数据,因此显然您必须运行捕获 Windows Live(或 Hotmail)用户的网络流量。

上面的截图是原用户的Live网页。现在您有了用户网络数据的 pcap 文件。将此 pcap 与 Xplico 一起使用:

从左侧菜单“Web→Site”:

使用搜索找到“mail.live.com”:

启用代理以指向 Xplico 服务器(代理:localhost:9876):

单击 cookie 链接:

将打开一个新窗口。禁用代理:

点击链接:

所以:

即使原始用户已断开连接(注销),也是如此。
架构和模块文档
1º) Xplico 的嗅探器是使用 pcap 的新嗅探器还是您使用的是 tshark 或 tcpdump?
Xplico 是从头开始编写的,它不使用 tshark 或 tcpdump。而不是天生的嗅探器。使用实时模式毫无意义。
2º) 有没有办法同时保存解码的流量和 PCAP 格式?
没有直接。在 Xplico 中,数据包不能被复制并发送到两个单独的解剖器(结构约束)。对于实时解码,模块是 rltm ( -m rltm ),但可能会丢失数据包,因为它可能是单个数据包的 Xplico 平均处理时间大于每秒平均数据包数。无论如何,另一种解决方案是使用另一个嗅探器并仅使用 Xplico 进行解码:
mkfifo p.cpap
tcpdump -s0 -A -w b.cpap -i eth0 -p &
tail -f b.cpap > p.cpap
./xplico -m pcap -f p.cpap
3º) xplico 不支持的协议(今天)的流量怎么样?即telnet,有什么办法也可以节省这种流量吗?
所有流(数据包)都到达两个解析器:tcp_grb.c 和 udp_grb.c。在这两个解剖器中,数据(数据包)被丢弃。但是,如果您在 #define GRB_FILE 1 中更改定义:#define GRB_FILE 0,则数据将保存到 pcap 文件(每个流一个文件)。
4ª) 是否有任何创建协议解码器的方法或示例?
此时:没有。取决于您想要执行的协议。在 Xplico 中,解剖器分为两种不同的类型。第一种:
-
数据包解析器(例如:IP、TCP、UDP、ETH、PPP 等)
-
流解剖器(例如:HTTP、POP 等)
第二种:
-
节点流解析器(即:解析器“识别流”)
-
或不
TCP 是数据包解析器和节点流解析器。IP 是数据包解析器,但不是节点流解析器。HTTP 是流解析器,但不是节点流解析器。
通常应用协议的解析器是流解析器而不是节点流解析器。最好的例子是TFTP的源代码. 这是一个需要多个流的协议(数据来自不同的元组)。许多解剖器(叶解剖器)定义了 PEI(信息协议元素)。您可以使用以下命令查看所有解剖器上的 PEI:./xplico -i http ./xplico -i pop ... 每个 PEI 都被传送到 Dispatcher(模块调度程序)。cli 的调度程序什么也不做。XI 的调度程序填充 sqlite 数据库。在实践中,Pei 是将数据(提取)标准化。每个人都可以轻松开发他们的 Dispatcher,而无需了解或修改协议解析器。并非所有解剖器都有 PEI,但所有解剖器都有协议栈信息 (./xplico -i http),用于在解剖器和另一个之间创建依赖关系(启发式与否)。./xplico -g(查看依赖)
5ª) 我在剖析捕获时遇到问题,我该如何调试它?
Xplico 生成名为 war_*.xml 或 error_*.xml 的日志文件,如果您使用命令(系统/脚本),此 xml 文件对于调试非常有用:./xml2pcap.php <xml_file> <output_file> (tshark is necessary)
您可以仅使用 pcap 文件(<output_file>)获得生成日志 (<xml_file> ) 的流(数据)。每个XML文件都有一个索引(文件名的第一个数字,即war_x或err_x_中的x),每个索引对应日志文件(xplico_y_m_d.log)中的一行,该行索引在括号中。示例: 当且仅当模块(解剖器)中有日志时,这使得调试(xml2pcap.php)变得容易。xml file: warn_1_1253080327.xml → index 1
log file: warning line (xml is a warning): 07:52:07 [http]{20}-WARNING: (1) Packets lost in body response
6ª) 为什么pcap文件上传失败?
您可以上传的文件大小取决于 PHP-Apache 的设置。在文件 php.ini (Ubuntu: /etc/php5/apache2/php.ini) 中有两个值决定了文件的最大大小:
-
post_max_size
-
上传最大文件大小
要上传 100M 字节的文件,设置必须是:
-
post_max_size = 100M
-
upload_max_filesize = 100M
在某些 Linux 发行版中,如 Backtract4,您必须执行“chmod -R 777 /tmp”更改权限。
7ª) 创建新案例时,我收到一条“请更正下面的错误”。
检查 /opt/xplico 权限。“chmod -R 777 /opt/xplico”永远不会失败。
8ª) Xplico 已经连接到projects.xplico.org,这是做什么用的??
不要恐慌。在旧版本中,向外部服务器 ( http://projects.xplico.org/version/xplico_0.5.png )请求新版本的 Web 界面图像提示。Xplico 不会向任何服务器发送任何信息。Xplico 是 GNU,您可以在编译之前检查代码。在较新的版本中,此图像已被删除。
9ª) 为什么Xplico 登录时出现空白页面?
对于遇到此问题的任何人,请确保安装 php5-sqlite 包。
10ª) 为什么 Xplico 这么慢?
Xplico 使用 SQLite 作为数据库,如果有很多内容要插入数据库,则速度会下降。一个解决方案是禁用ARP协议,另一个解决方案是使用MySQL作为DB。
11ª) 为什么 session_mng.pyc 给我一个错误?
session_mng.pyc 是一个 Python3 脚本,它使用 httplib2 python 库,如果没有安装这个库 session_mng.py 会报错。要解决此问题,您必须安装 httplib2。如果您的 Linux 发行版没有为您提供 python3-httplib2 包,那么您可以执行此步骤。
12ª) 如何使用主机名而不是 IP 地址访问 Xplico?
Xplico 已嵌入(在其 PHP 代码中)一个 Http 代理,该代理用于显示网页,例如模拟用户的原始缓存。默认情况下,十一url必须为一个IP地址(维基:http://wiki.xplico.org/doku.php?id=interface#browser),唯一的例外是URL的http://demo.xplico .org(出于显而易见的原因)。如果您使用名称(而不是 ip)作为 url,那么 XI 会给您一个空白页,因为 XI 在解码数据中搜索您的 url。
要更改此行为,您必须修改 PHP 代码:
-
文件/opt/xplico/xi/cake/dispatcher.php
-
将 demo.xplico.org 替换为您的主机名(在 url 中使用)
Xplico 系统架构
Xplico System 由四个宏组件组成:
各组件之间的关系如图所示。

还有其他应用程序和脚本可以由四个组件互换使用。
通过调试的流程图
在低级别准确查看 Xplico 中发生的事情可能会很有用,以了解它的运作方式。为了演示,我们将看到当 Xplico 处理来自http://wiki.xplico.org/doku.php?id=pcap:pcap (0.5.5)的示例 PCAP 时会发生什么。
在 main() 函数中,调用 CapInit() 初始化将要使用的捕获模块,然后调用 CapMain() 执行捕获。当调用 CapInit() 时,它会设置一个指向合适的捕获模块的函数指针,然后从 CapMain() 调用这个函数指针。在这种情况下,函数指针是从 cap_pcap.so 文件加载的,因此从 CapMain() 内部调用 CaptMain() 函数指针,它实际上是在调用 capt_dissectors/pcap/pcap.c:CaptDisMain()。
一旦控制到达 PCAP 捕获模块,将调用 pcap_loop,每个数据包将由 PcapDissector() 处理。ProtDissec() 有一个 while 循环,它为传入数据包的协议层次结构中的每个数据包找到并执行适当的数据包解析器。
解码管理器
德马有以下职责:
-
组织输入数据
-
设置解码器和操纵器的配置、历史文件
-
启动解码器和操纵器
-
控制解码器和操纵器的执行
介绍
Xplico 读入流量数据(捕获模块),根据协议(解析器模块)从这些数据中解析信息,然后将信息分派到所需的输出目的地(调度器模块)。
解码器的每个部分都是一个插件,然后是一个模块。在 Xplico(解码器)中,我们区分了三种类型的模块:
-
捕获模块:这些模块允许(理论上)连接到任何类型的数据采集系统;
-
Dissector 模块:这些模块是协议解码器,它们依次分为不同的类别;
-
Dispatcher 模块:这些模块允许(理论上)连接到任何类型的数据存储系统(目录/文件、SQLite、Oracle、MySQL、PostgreSQL、带有套接字连接的系统存储,……想象空间)。这一切都可以轻松完成,无需修改协议解剖器(解剖器模块);
捕捉模块
捕获模块位于源代码树的capt_dissectors顶级目录中。该PCAP捕获模块接口PCAP流量文件。该rltm(可能代表了“实时”)从捕获的实时网络接口的流量数据了(eth0,为wlan0,EN1等)
解剖模块
这些模块从流量中提取特定于协议的信息,可以在dissectors顶级目录中找到。它们被划分为每个支持的协议(eth、ip、tcp 等)的子目录。
FTP解析器
目前,FTP PEI.cmd 组件指向存储FTP会话明文的文件名。如果想要提取对话的FTP命令和响应(从调度程序内部),建议使用两个选项。第一个(也是最简单的)是解析给定的文件名并以这种方式获取信息。第二个选项是修改解剖器以将此信息作为 PEI 组件包含在内。
TCP解剖器
为了避免流之间同步的重大问题(例如,FTP的命令和数据通道),建议您使用名为 tcp_soft 的 TCP 解析器。我们为两种不同的需求开发了两个独立的 TCP 解剖器。两者都向更高的解析器(FTP、POP、SMTP)提供相同的数据,但具有不同的时间限制(在不同的流之间)。我们的“应用”解剖器(TCP 上的解剖器)旨在与两个 TCP 解剖器一起正常工作。
调度模块
Dispatcher 模块将数据导出到目的地,可以是数据库(SQLite、Postgres 等)、一组目录和文件、网络套接字,或者您想要的任何其他地方。这些可以在dispatch顶级目录中找到。
要创建自己的调度程序,您需要实现位于xplico-src/dispatch/dispatch.h的接口。具体来说,您需要实现 3 个函数:DispInit()、DispEnd()、DispInsPei()。DispInit() 通常用于设置特定于您的调度员打算使用的协议的 ID 号,以及设置您的调度员可能需要的任何其他内容(套接字、数据库连接等) - 我相信每个调度员只调用一次此函数. DispInsPei() 被多次调用,每次都会传递一个指向协议元素信息 (PEI) 对象的指针(见下文)。调用 DispEnd() 来清理您需要清理的任何内容(关闭文件/套接字句柄、数据库连接等)
如果您正在创建自己的调度程序并发现无法从协议的 PEI 组件中导出所需的协议信息,则有必要修改相应的解剖器,以便包含/构建所需的信息。
提示:为了按捕获/解码时间输出数据,请查看 pei.time 和 pei.time_cap 。
协议元素信息
PEI 数据结构的定义可以在xplico-src/dispatch/include/pei.h 找到。PEI 包含元数据和 PEI 组件列表。该工具支持的每个协议都有一个解析器,可以从流量数据中解码协议信息,然后将该信息编码为特定于协议的 PEI 格式。给定协议的 PEI 格式由 DissecRegist() 函数中的相应解剖器模块定义,可以从命令行使用 -i 选项查看。例如,FTP PEI 定义在xplico-src/dissectors/ftp/ftp.c:DissecRegist(). 目前,PEI 组件的值可以是字符串(通过解剖器填充 PeiCompAddStingBuff())或文件(通过解剖器填充 PeiCompAddFile())。解剖器模块负责从原始数据包数据构建 PEI,然后将这些 PEI 提供给调度模块(通过调用它们的 DispInsPei() 函数)进行输出。
并非所有解剖器都会生成 PEI;此类解析器的示例是 TCP、IP、UDP 和以太网。
机械手
操纵器允许在派发 PEI 之前对它们进行一些操纵。它们在捕获解析器→协议解析器→调度器链中的作用可以在这里描述:
--------->机械手 (1) |--------->机械手(2) | ... |--------->机械手(n) 捕获解析器 -> 协议解析器 ---(PEI)---->| (或者) --------->调度员
操纵器可以从原始输入 PEI 生成新的 PEI;然后可以将这些生成的 PEI 提供给调度员。
---(PEI)---->操纵器---(PEI)---->调度器
打开浏览器 输入ip:9876 出现下面报错
该报错存在了很久了,是因为该软件太长时间没有更新导致与依赖软件存在兼容性问题,是软件自身问题不是kali的问题,
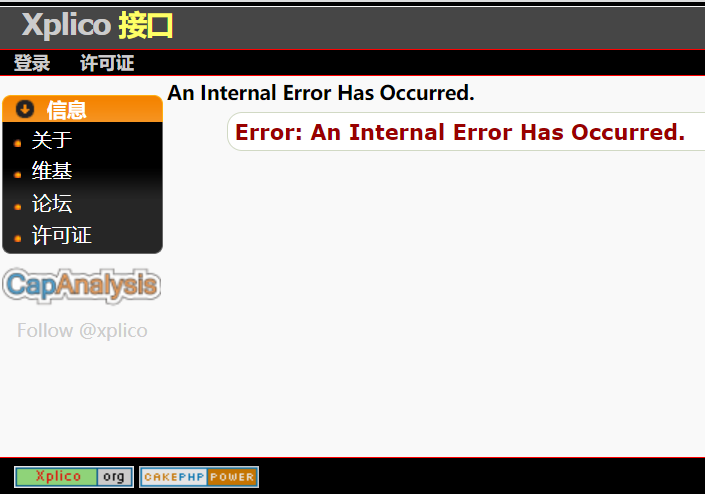
首先我们检查以下内容
数据库是否存在
数据库用户名密码是否正确
是否创建了表
都没问题,进行分析发现是依赖的cakephp抛出的错误,修改配置文件查看详细信息
sudo nano /opt/xplico/xi/app/Config/core.php
将Configure::write('debug', 0);
改为 Configure::write('debug', 2);
刷新页面,看见下面提示
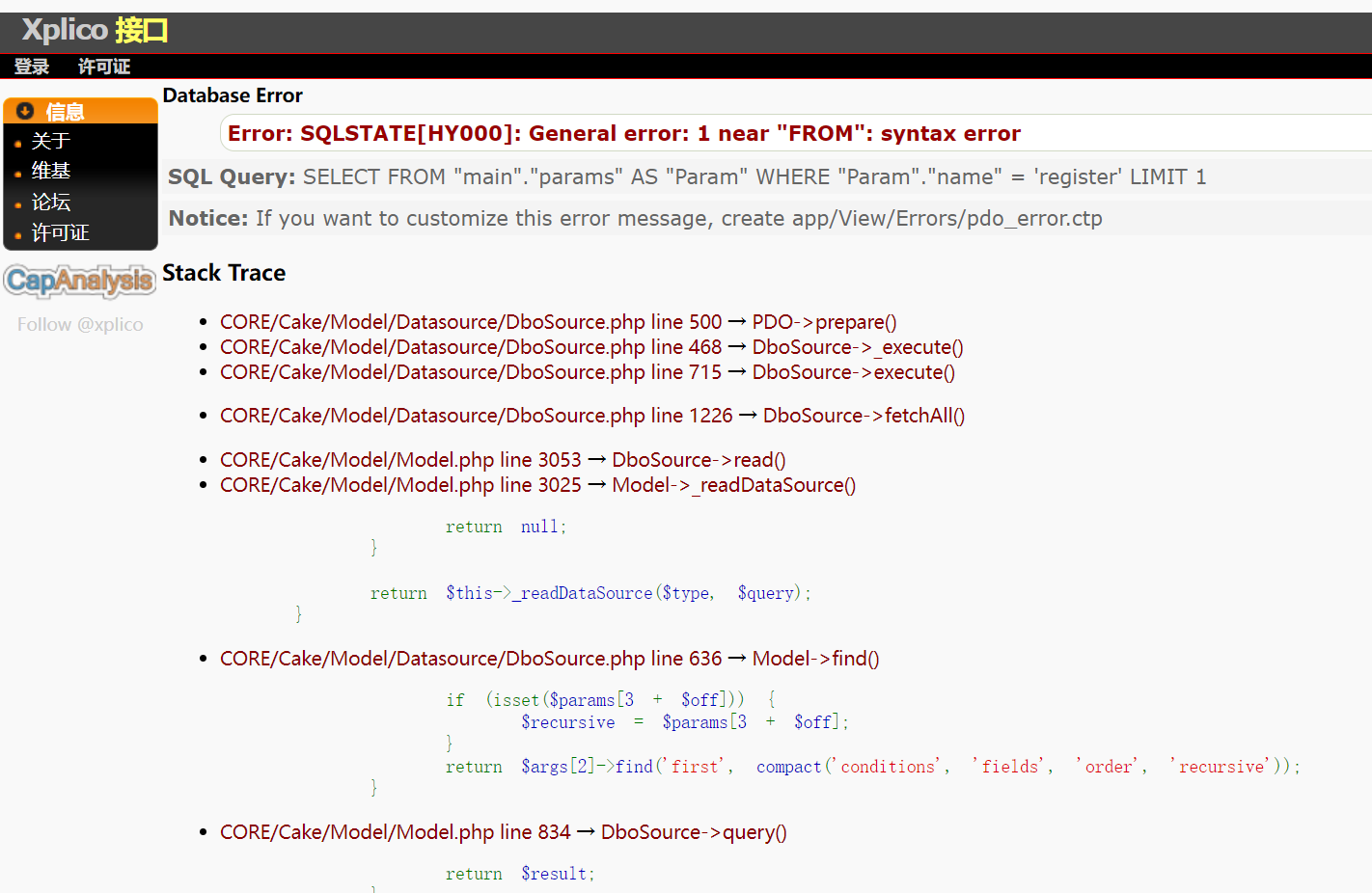
进一步分析发现是php操作sql数据库是发生语法错误。select 后面没有参数直接跟随from
之后我查找了一堆代码没有找到问题出现的地方所以不了了之了。


{kind=link}