MySQL为什么使用B+树索引
MySQL为什么使用B+树索引
索引
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样
索引的常见类型
- BTREE 索引
- Hash 索引
- FULL-TEXT 全文索引
- RTREE 空间索引
MySQL为什么使用B+树索引
-
二叉树为什么不可行?
对数据的加速检索,首先想到的就是二叉树,二叉树的查找时间复杂度可以达到O(log2(n))。下面看一下二叉树的存储结构
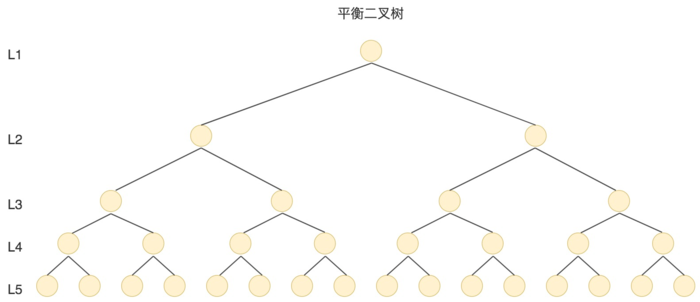
二叉树是一种二分查找树,有很好的查找性能,相当于二分查找。 但是当N比较大的时候,树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差。 而且二叉树最坏的情况会退化成链表。如果依次插入5、22、23、34、77、89、91如下: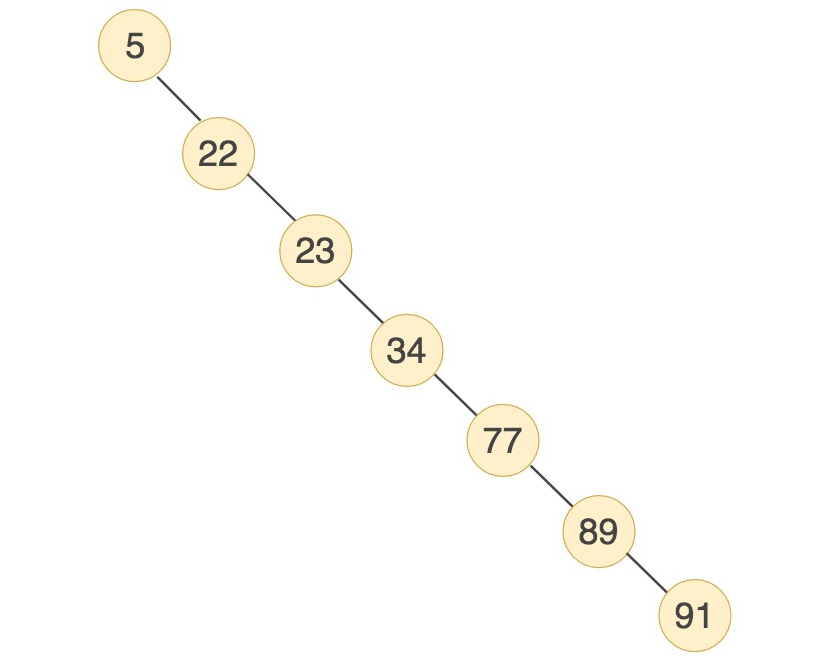
-
平衡二叉树为什么不可行?
为了解决二叉树存在线性链表的问题,会想到用平衡二叉查找树来解决。
平衡二叉查找树定义为:节点的子节点高度差不能超过1,通过左旋、右旋的方式来保证二叉树的平衡。
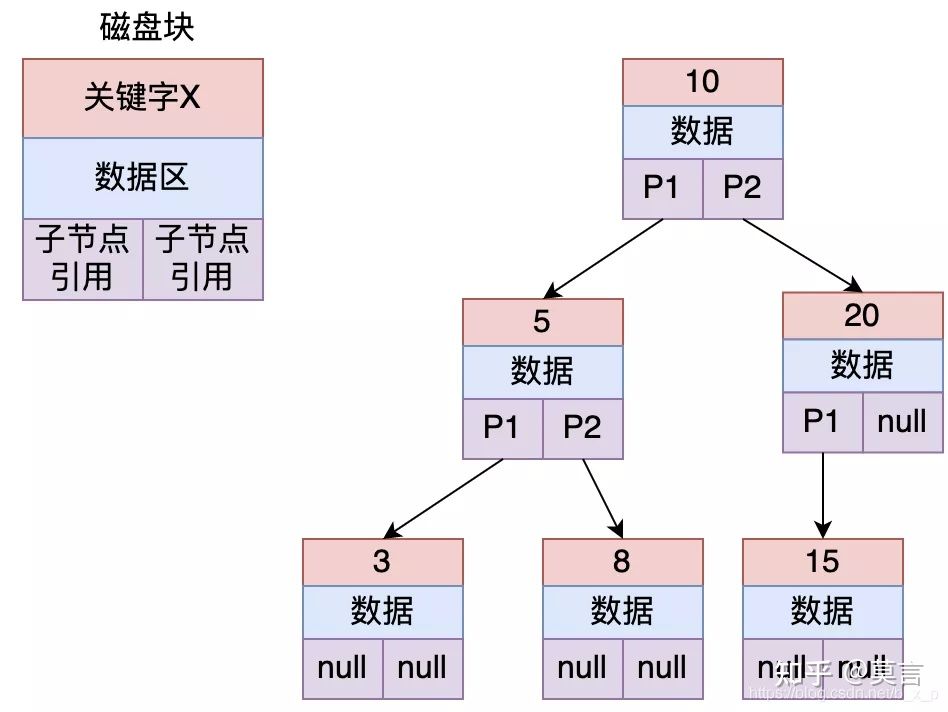
到这里,平衡二叉树解决了存在线性链表的问题,数据查询的效率也还可以,基本能达到O(log2(n)), 那为什么mysql不选择平衡二叉树作为索引存储结构?
- 搜索效率不足。一般来说,在树结构中,数据所处的深度,决定了搜索时的IO次数(MySql中将每个节点大小设置为一页大小,一次IO读取一页 / 一个节点)。如上图中搜索id = 8的数据,需要进行3次IO。当数据量到达几百万的时候,树的高度就会很恐怖。
- 查询不不稳定。如果查询的数据落在根节点,只需要一次IO,如果是叶子节点或者是支节点,会需要多次IO才可以。
- 存储的数据内容太少。没有很好利用操作系统和磁盘数据交换特性,也没有利用好磁盘IO的预读能力。因为操作系统和磁盘之间一次数据交换是以页为单位的,一页大小为 4K,即每次IO操作系统会将4K数据加载进内存。但是,在二叉树每个节点的结构只保存一个关键字,一个数据区,两个子节点的引用,并不能够填满4K的内容。
-
B树
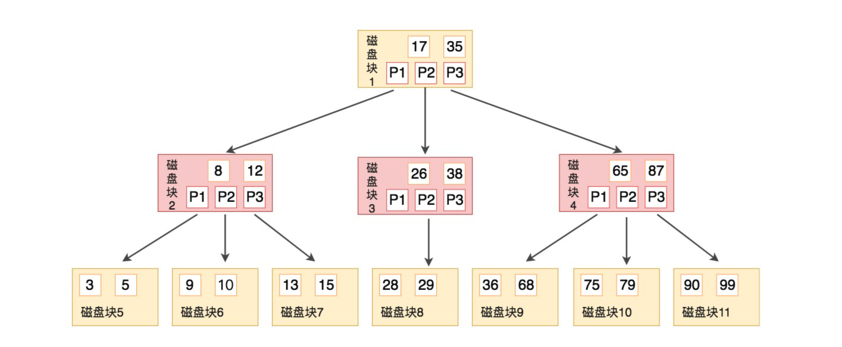
B树简单地说就是多叉树,每个叶子会存储数据,和指向下一个节点的指针。
例如要查找9,步骤如下
我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
B树很好的解决了平衡二叉树中的问题:
B Tree 能够很好的利用操作系统和磁盘的交互特性, MySQL为了很好的利用磁盘的预读能力,将页大小设置为16K,一次IO将一个节点(16K)内容加载进内存。假设使用BigInt(8字节)作为索引,每个关键字的数据区也是8字节,不考虑其他的情况下上图能存16 * 1000 / (8 + 8) = 1000个关键字。对于二叉树来说,三层高度只能存7个节点,而对于这种一个节点可以存1000个关键字的B树来说,三层高度能够搜索的关键字个数远大于二叉树。
- B+树

B+树是B树的改进,简单地说是:只有叶子节点才存数据,非叶子节点是存储的指针;所有叶子节点构成一个有序链表
例如要查找关键字16,步骤如下
与根节点的关键字 (1,18,35) 进行比较,16 在 1 和 18 之间,得到指针 P1(指向磁盘块 2)
找到磁盘块 2,关键字为(1,8,14),因为 16 大于 14,所以得到指针 P3(指向磁盘块 7)
找到磁盘块 7,关键字为(14,16,17),然后我们找到了关键字 16,所以可以找到关键字 16 所对应的数据。
B+树的优点:
1. 扫表、区间查询效率更高,B树使用中序遍历才能完成查询范围的查找
2. B+树每次都必须查询到叶子节点才能找到数据,而B树查询的数据可能不在叶子节点,也可能在,这样就会造成查询的效率的不稳定
3. B+树查询效率更高,因为B+树矮更胖,高度小,查询产生的I/O最少。
为什么B+树更加矮胖
B+ 树更加适应磁盘的特性,相比 B 树减少了 I/O 读写的次数。由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
平衡二叉树 & B+树 不同节点量级对应树高比较
| 数量级(单位/万) | AVL Tree 高度 | BTree 高度(N = 1200) |
|---|---|---|
| 100 | 20 | 2 |
| 1000 | 24 | 3 |
| 10,000 | 27 | 3 |
说明:以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200。
为什么减少I/O次数?

一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间
传统的硬盘盘结构是像下面这个样子的,它有一个或多个盘片,用于存储数据。中间有一个主轴,所有的盘片都绕着这个主轴转动。一个组合臂上面有多个磁头臂,每个磁头臂上面都有一个磁头,负责读写数据。
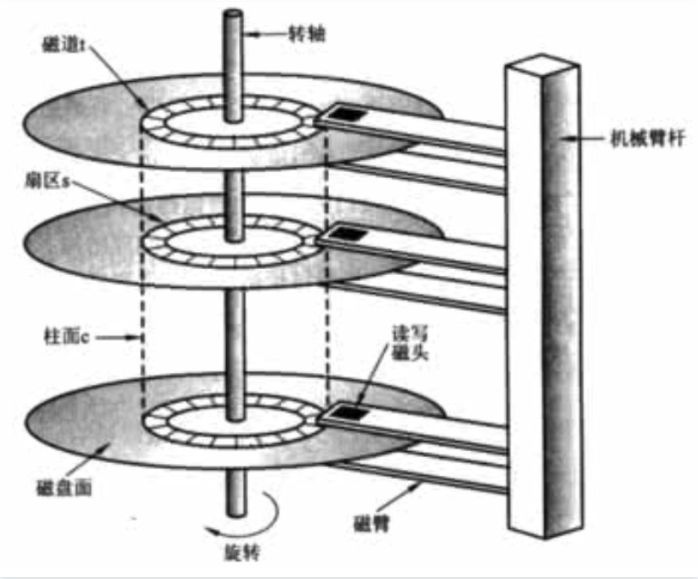
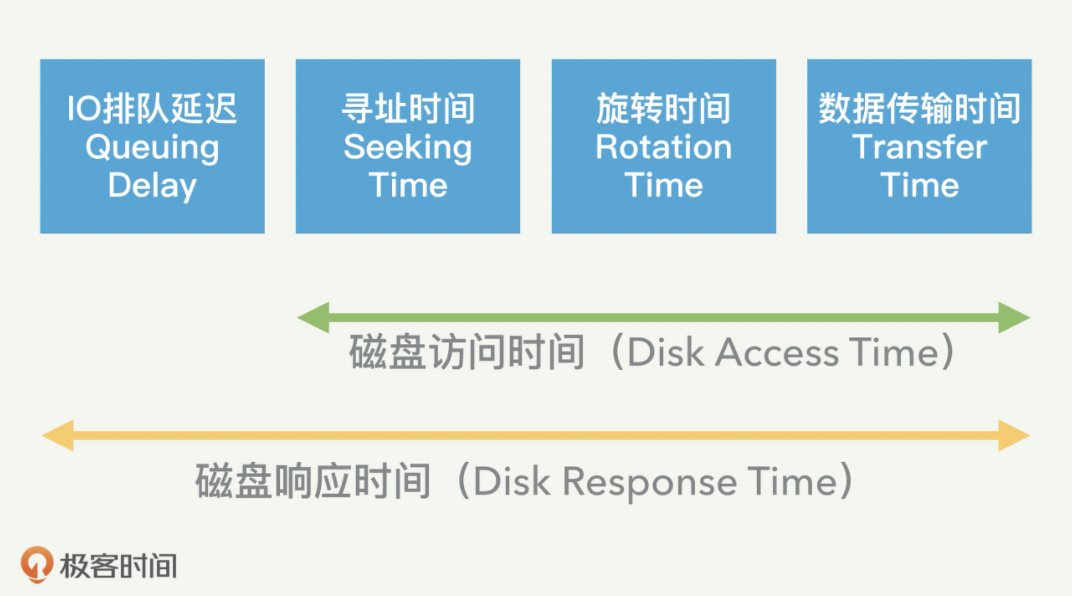
读写文件耗费的时间主要分为两部分:
1 让磁头定位到指定位置的时间(寻道时间)
2 磁头从盘片上读出数据的时间(传输时间)
也就是说,磁盘I/O 慢的原因在于读写数据时触发的寻道时间和传输时间
MySQL InnoDB存储结构
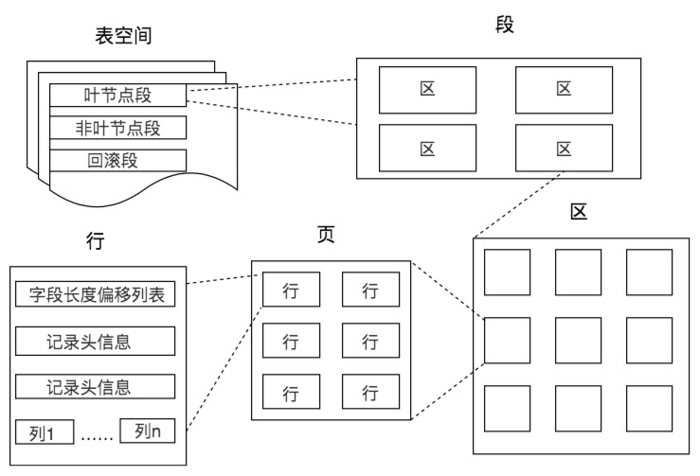
InnoDB引擎下所有数据都被逻辑地存放在一个空间中 ,即表空间 ( tablespace ) 。表空间又由段 ( segment ) 、区 ( extent ) 、页 ( page ) 组成
-
表空间
- 默认情况下,只有一个表空间ibdata1,所有数据存放在这个空间内
-
segment 段
- 数据段:B+ tree的叶子节点
- 索引段:B+ tree的非叶子节点
-
extend 区
- 每个区的大小为1M,页大小为16KB,即一个区一共有64个连续的页(区的大小不可调节,页可以)
-
Page 页
- InnoDB磁盘管理的最小单位
-
row 行
- 对应数据表里一条条记录
在数据库中, 不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说存储空间的基本单位是页。
一个页就是一棵树B+树的节点,数据库I/O操作的最小单位是页,与数据库相关的内容都会存储在页的结构里。
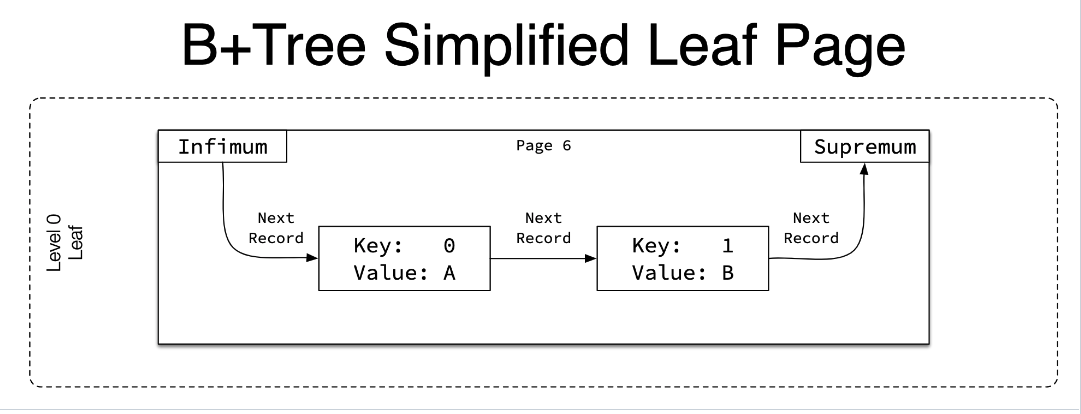
B+Tree Structure
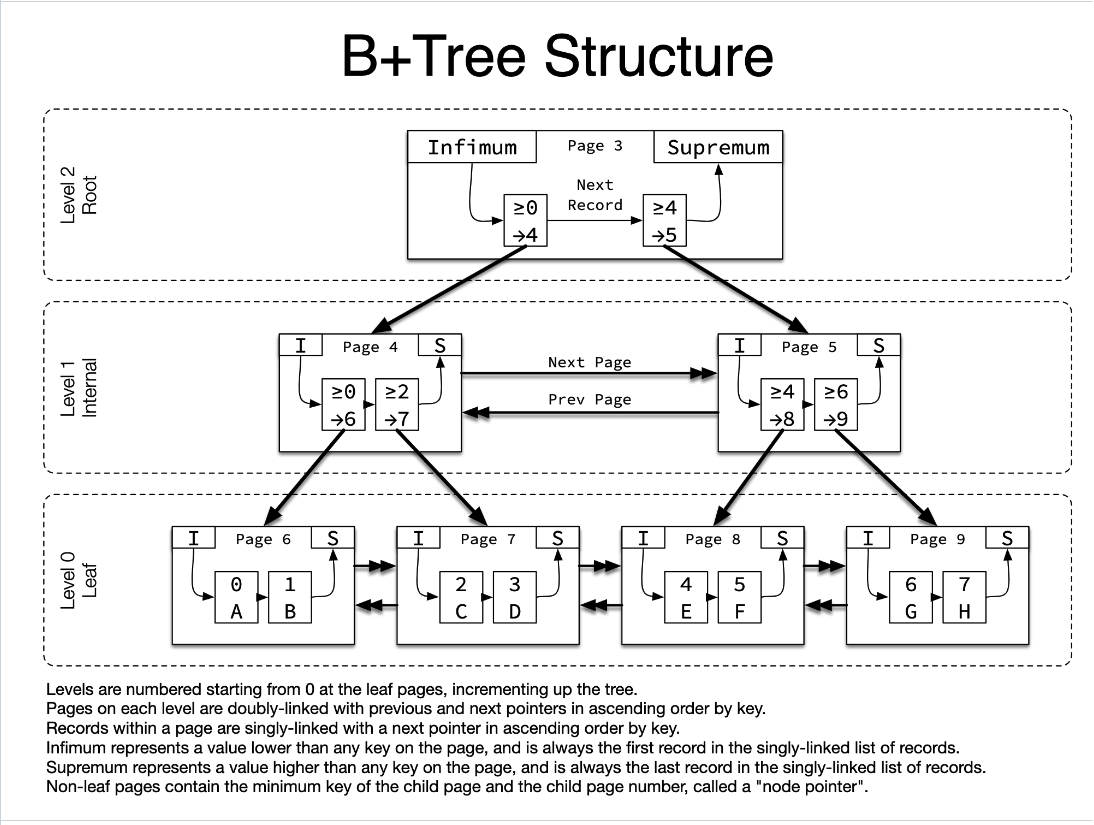
1. 叶子节点作为树的第0层节点,向上递增
2. 每一层页节点之间都通过双向链表连接
3. 叶节点内部数据都是单向连接的
4. infimum 是下界,supremum 是上界
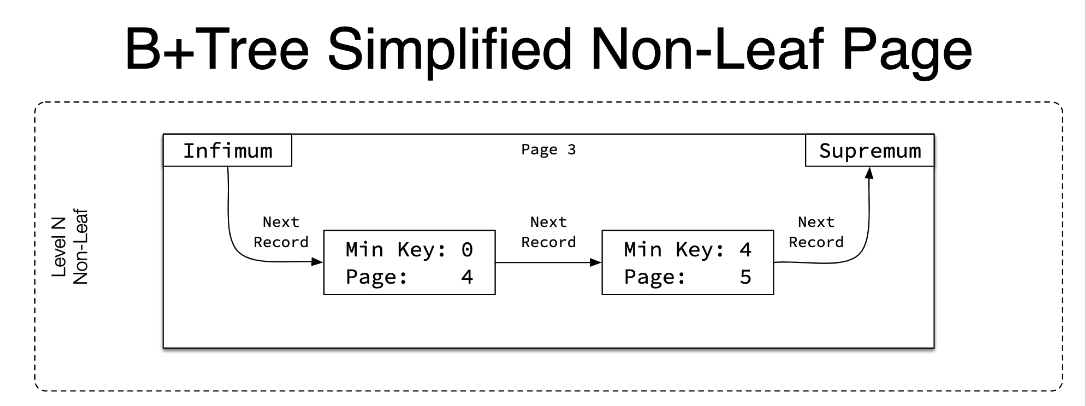
5. 非叶节点中的数据包含子节点的最小 key 和页号
叶子节点:
非叶子节点:
根节点结构内容:
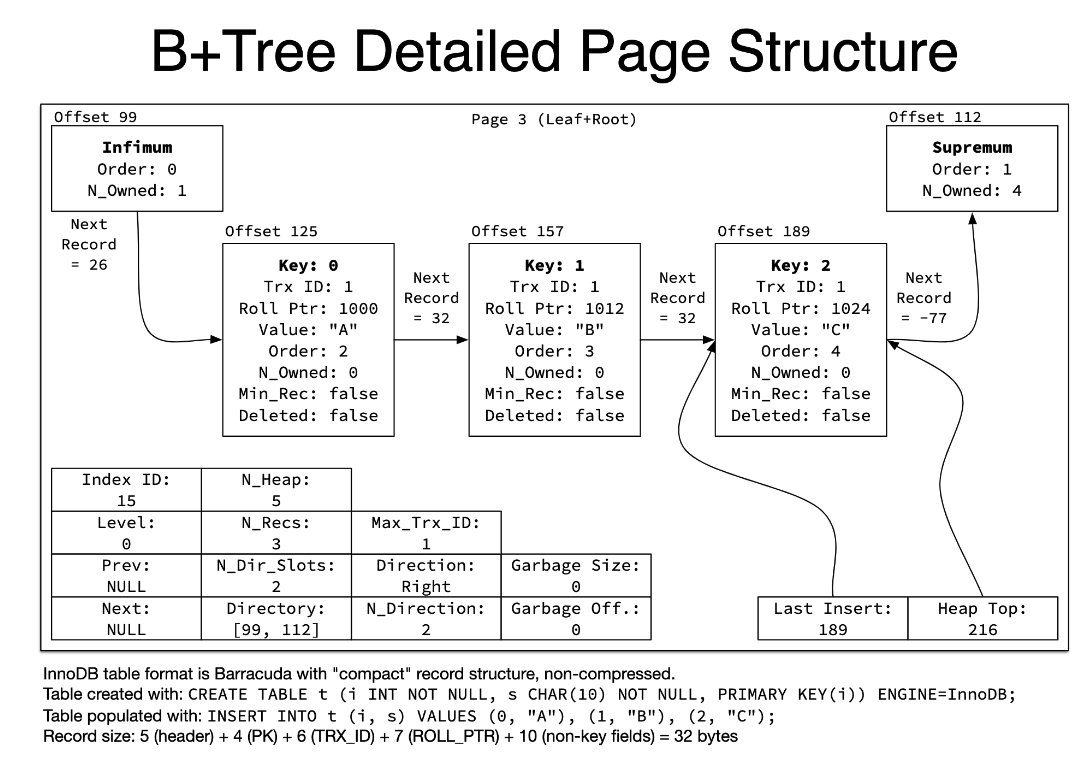
Index ID:当前页属于哪个索引ID。
N_Heap:堆中的记录数(包含上界、下界、删除记录)。
LEVEL:当前页在索引树中的位置,0x00代表叶节点。
N_RECS:该页中记录的数量。
MAX_TRX_ID:修改当前页的最大事务ID。
N_DIR_SLOTS:在Page Directory(页目录)中的Slot(槽)数
DIRECTION:最后插入的方向。可能的取值为PAGE_LEFT(0x01),PAGE_RIGHT(0x02),PAGE_SAME_REC(0x03),PAGE_SAME_PAGE(0x04),PAGE_NO_DIRECTION(0x05)。
N_DIRECTION:一个方向连续插入记录的数量。
PAGE_GARBAGE:已删除记录的字节数,即行记录结构中,delete flag为1的记录大小的总数。
PAGE_LAST_INSERT:最后插入记录的位置。
Heap_TOP:堆中第一个记录的指针。
数据查找
由于页目录中记录的主键是有顺序的,所以可以通过二分法进行查找,通过二分法在页目录找到对应的槽,再遍历整个组中的记录
页中数据存储结构:
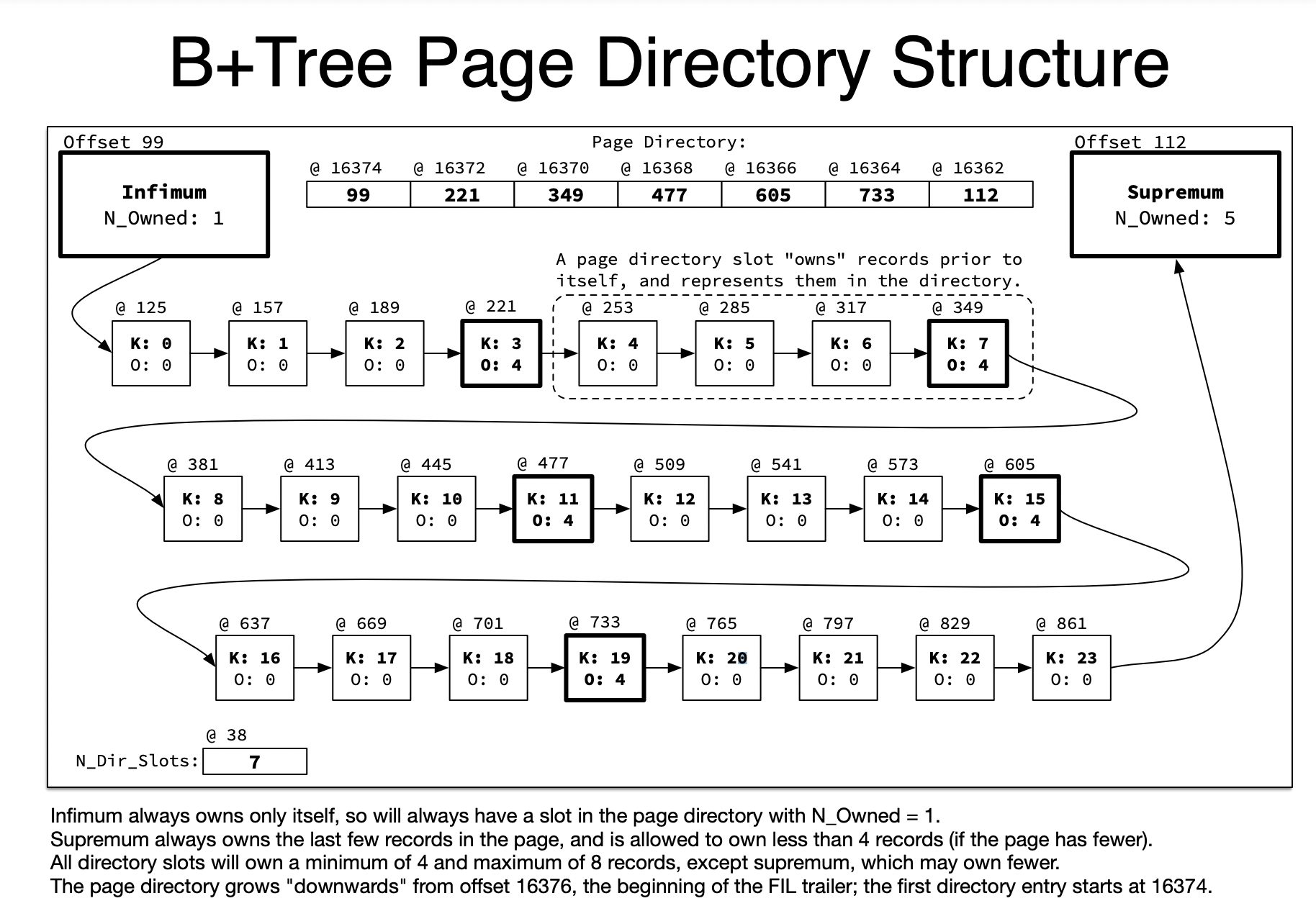
InnoDB会将一个页中的所有记录划分成若干个组,每组4-8个记录。将每个组最后一个记录相对于第一个记录的地址偏移量(可以定位到真实数据记录)提取出来存放在页中一个叫做Page Directory的数组中,数组中的元素就是这些地址偏移量,也称为槽(slot)。
联合索引
创建表
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
`contry` varchar(20) NOT NULL DEFAULT '',
`age` int(11) NOT NULL,
`gender` tinyint(4) NOT NULL,
PRIMARY KEY (`id`),
KEY idx_age_contry_name(`age`, `contry`, `name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
构建联合索引,联合索引会将N个字段组合成一个元素,形成一棵B+树,大致如下
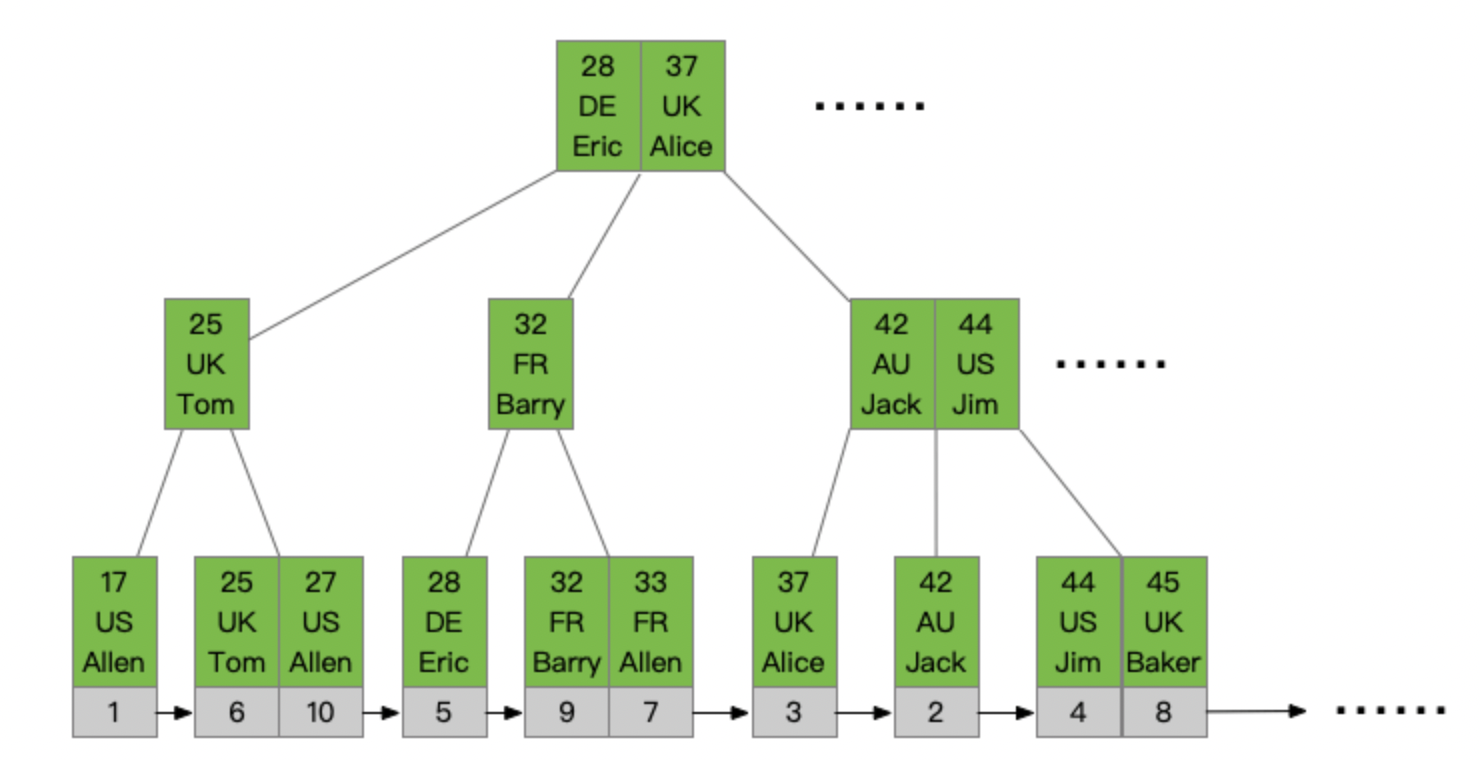
查询过程中,会先根据第一列的条件进行查询,查询到满足的值之后,再根据第二列的查询条件继续定位,依次类推。
联合索引的一些特性如下:
-
最左匹配
联合索引的一个特性是最左匹配,也就是当一个查询中,有多个查询条件时候(sql编写顺序无所谓),查询条件需要精确匹配联合索引的左边连续几个列,此时联合索引便可以被用到(用到联合索引的部分列),例如:
age=15 and contry='US' and name='Eric':是一个全匹配age=15 and contry='US':是一个最左匹配,也能用上联合索引,但是只能用上联合索引的age和contry两列age=15:也是一个最左匹配,也能用上联合索引,但是只能用上联合索引的age列contry='US' and name='Eric':并没有从联合索引的最左列开始匹配,因此无法用上索引age=15 and name='Eric':只能用上age部分的索引,因为缺少了中间字段
最左匹配特性的由来:
我们知道B+树的构造过程中,需要对比插入元素和树中节点的比较结果,来确定元素的插入位置。联合索引生成的B+树中,会优先以第一列的比较结果来定位,第一列值相等的时候,会继续使用第二列的比较结果,依次类推,因此一定要第一列的精确查询条件,才能定位到某些子树,然后才能在子树基础上,继续使用第二列的查询条件,一次类推下去,从而形成一个最左匹配的规则。
-
覆盖索引
在使用非聚集索引查询时,一般会检索两遍数据,不过也会有例外。 当我们要查询的列本身就在索引树中,就不会进行二次查询,也就是覆盖索引。例如
select age, name from `user` where age = 10; -
范围查询
当联合索引遇到范围查询条件之后,后面的列便无法使用索引,例如:
age>15 and contry='US' and name='Eric':能使用age列的索引,但是无法使用完整的联合索引
在B+树数据结构中进行范围查询,可以先查询到最小/最大值,然后通过叶子节点上的链表指针,按照顺序遍历叶子节点,即可得到范围查询结果,因此当联合索引中的某一列使用了范围查询之后,可以认为是B+树已经深入到最底层的叶子节点做范围查询了,无法再在非叶子节点中根据后续列的查询条件进行检索。
Mysql索引优化建议
- 尽量采用自增ID作主键
- 不要建立太多索引
- 严禁左模糊查询(like '%xxx')
- 利用覆盖索引避免回表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号