哈希表散列表(zend_array)数组
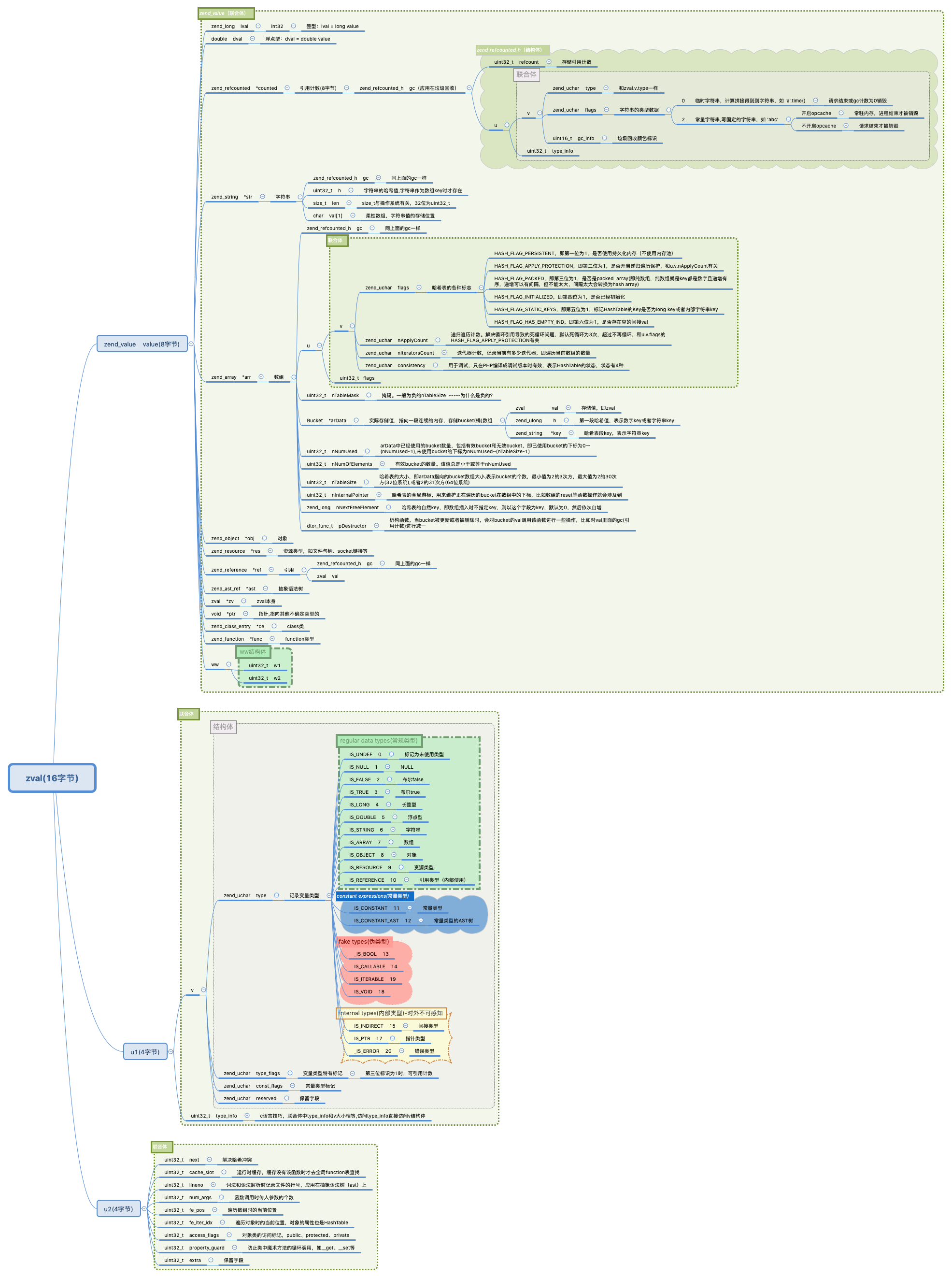
一。哈希表,也称散列表
如下图所示
key:键,通过它可以快速检索到对应的value。一般是数字或字符串。
value:值,目标数据。可以是复杂的数据结构。
slot: 槽,就是平时所说的哈希表的单元,全部就是哈希表的表长
bucket: 桶, 对应槽下存储的值,可以是复杂类型
哈希函数: key 通过哈希函数得到slot,比如 key%表长 = slot, 就会得到对应的槽
哈希冲突: key 通过哈希函数得到slot是同一个,就叫作哈希冲突。一般采用链地址法和开放地址法解决冲突
具体可以百度来看
二。PHP中的哈希表
PHP在上面的哈希上做了如下改变:
增加了hash1函数(hash2和上面的哈希函数效果一样,把数字映射到槽中)。hash1将key映射为h值,hash2将h值映射为slot的索引值。
bucket里面增加h字段。
bucket里面的key字段作为字符串key,不再表示数字key。
这么做主要有两个原因:
因为哈希的key可能是数字也可能是字符串,所以用h代表数字的键,用key代表字符串的键,如果键是字符串,那么通过hash1得到数字键,然后和上面的哈希一样,把h(数字键)映射到槽中。如果键是数字,hash1啥都不做,h值就是键值,然后和上面的哈希一样,把h(数字键)映射到槽中。
加快了比较和查找,在比较查找中,先比较h值,h值相等再比较长度和内容,但经过了hash1得到的h值九成以上是不相等的,这就能通过h快速的比较出结果,而不用对长度和内容进行比较,加快了速度。

三。PHP7的哈希表(看最顶层图的zend_array,即数组)
PHP7还是使用链地址法解决冲突。不过采用的链表是一种逻辑上的链表,所有bucket不再通过指针维护上下游关系,如下图所示
槽和桶放在了数组里面,-1到-n对应上面所说的slot(槽),右边的0到n-1就对应槽中挂载的桶了,这么做最大的效果就是:
数组是随机存取的(即直接访问),通过数组下标直接获取值,不像一般的哈希一样通过链表来顺序访问,这里增加了至少一半的效率
这里也很直观的能看到为什么PHP数组是有序的(即插入和遍历出来的结果一样),因为插入时在有效bucket中插入,即0,1,到n-1,而遍历时也是直接这么从头读出来的。PHP数组的设计要满足这两个条件:1. 是字典,即键值对 2. 是有序 。 现在这两个条件都已经满足了

到了这里其实还有些疑问:
1. 上面数组的设计是怎么映射槽的,槽又是怎么关联桶,桶和桶又怎么关联的?
解决了这个也就解决了索引数组为啥是负的,掩码为啥是负的?即 value.arr.nTableMask(看最上面的图)
首先解决怎么映射到slot的,h 通过 hash2 的到 slot ,举个简单的例子,比如哈希表的长度为 8 ,得到的 h 值 为10 ,10%8=2 就会映射到第二个slot , 用数组来存储后原理也一样(这里设计得非常巧妙), 用 h 值 和表长按位或,同样取 8 和 10,此时 8 要变成 -8 存储在计算机里,存储的补码(计算机存储数都是补码,主要为了解决符号位和加减法等原因)为 11111111 11111111 11111111 11111000 (32位系统),这里可以算一下它的原码,反码=补码-1 =
11111111 11111111 11111111 11110111 得到反码,原码=反码取反(第一位符号位不取反) = 10000000 00000000 00000000 00001000 ,算一下这个二进制就是 -8, 存储在计算机里就是补码 000 (忽略前面的所有1),而 任何整数和 这个值 按位或后 恰好满足 [-n,-1] 的取值范围,比如现在举例的 -8 ,即
000 -8 001 -7 010 -6 011 -5 100 -4 101 -3 110 -2 111 -1
这里就刚好是[-8,-1]的取值范围,再用刚才的例子,把 10 和 -8 按位或之后得 -2
11111111 11111111 11111111 11111000 = -8 0111.........................110110 = 10 1111...........................1110 = -2
-2 就是第二个slot ,是不是很神奇,然后slot里的值存储bucket的索引,剩下的和图中所示一样。
2. 既然是找到slot后,再通过slot找到第一个bucket,接着再找第二个bucket,那么它和链表的方式是一样的,链表的方式也是这样子,找到slot后,由链表的指针找到第一个bucket,然后再通过下一个指针找第二个bucket,都是一样的啊,效率提现在哪里?
这个问题我一开始就产生了,刚开始百思不解,书中也没有明确的说明这个原因,既然作者这么设计,必有他的道理,效率也必定提升了,只是我没有想到在哪方面提升了,后来仔细一想,既然原理还是一样的,那就是体现在查找的方式上,具体体现在这个地方:
用最简单的例子说明,对于指针 a* 指向bucket , 要得到 bucket 的值 , cpu 通过寄存器访问内存得到变量 a 的值,然后返回给cpu ,这里称为一次内存的访问,也就是两次指令的操作,因为变量a的值是一个地址,cpu 拿到值后再次像第一次一样寻址得到bucket的值,这里进行了两次的内存访问。而通过上面设计的数组来操作的话,只需要拿到数组的头地址进行寻址,然后通过内存的偏移(数组的索引进行偏移)得到值,返回给cpu,这里只进行了一次内存的访问,减少了一次内存访问,效率就体现在这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号