zval结构体
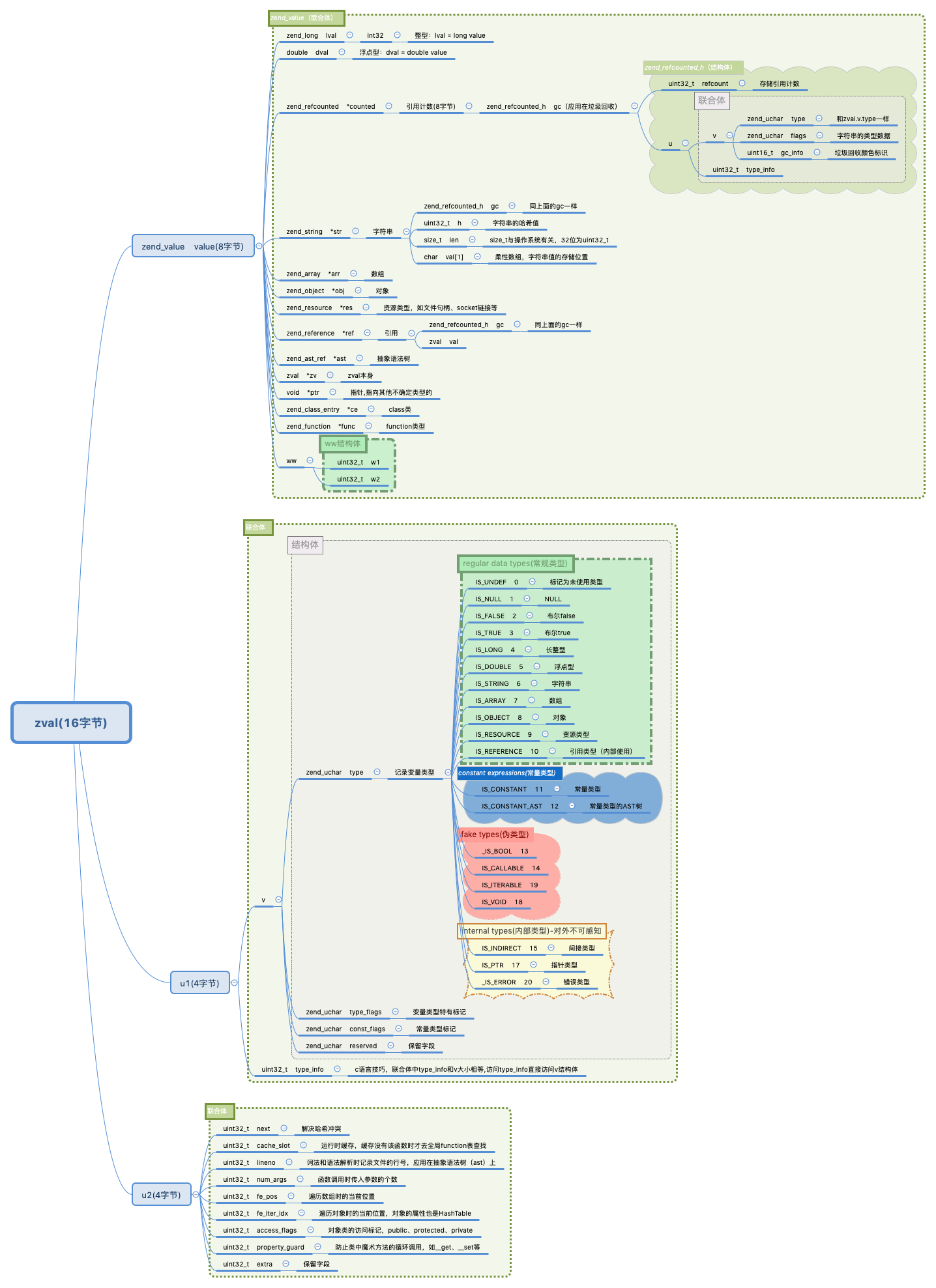
一。zval对比 (上图要右键新标签打开才能看清楚)
PHP的变量是由zval来存储的,PHP7之前的zval主要由value和type组成,后面增加了gc用来垃圾回收以及ref_gc来标志引用类型,共占了24字节,而在通过结构映射扩充zval来解决循环引用的问题,此时一个变量占了32字节,在扩充了zval之后,因为整型和浮点型不需要进行gc,所以整型和浮点型存在内存的浪费(存在有不需要的内存gc),而在开启zend内存池的情况下,一个变量的大小达到了48字节。
PHP7以后重构了zval,不仅解决了以前的问题,而且内存占用非常小。在PHP7以后,zval支持更丰富的类型,而且不再存储复杂的类型,复杂的类型数据都是通过指针来操作,所以使得zval存储了PHP中的一切,包括整型,字符串,数组,对象等,这些存储全部只占用16字节。
二。PHP是怎么知道zval存储了什么类型的变量
PHP是弱类型的语言,我们在编程时并不需要指明变量的类型,直接$a等于就行了,但是在底层不知道变量的类型是不行的,一个变量的类型就是意味着变量的大小,意味着需要向操作系统申请多少内存,如果不知道变量的大小就不知道需要申请多大的内存。PHP的变量类型是由zval.v.type来决定的,值存储在zval.value中,而在c和编程的中间,PHP帮我们进行了转换,这也是为什么PHP是用c语言来写的,却不适合用在cpu密集型的场合的最重要的原因之一。过度的向上抽象,使得编程人员不需要过多的关心语言方面,而只需要把时间放在业务上面。
三。整型和浮点型存储
对于整型和浮点型的存储,因为占用空间小,所以是直接存储的,直接创建两个zval (其他简单类型true/false/double/long/null等类似),然后在zval的value中来获取lval和dval。举例如下:
创建 int.php
进入gdb调试环境

在 echo 所在的行打断点,当然也可以在入口main函数打断点
(gdb) b ZEND_ECHO_SPEC_CV_HANDLER
运行 int.php
(gdb) r int.php
在第一个echo中断,输入 n 往下一步直到获取变量的值

打印一下变量是一个指针

打印指针指向的值,这里面就是一个zval

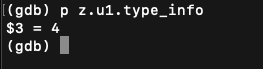
获取变量的类型为4,看图得知为长整型
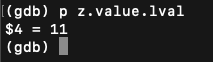
得知变量类型后,打印value下的长整型的值即为变量存储的值
输入 c 继续执行到下一个 echo 断点
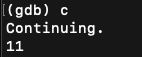
输入 n 一步一步重复上面的步骤

打印变量类型为浮点型
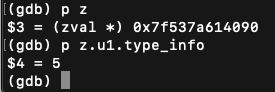
查看变量存储的值
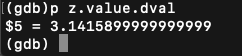
可见整型和浮点是直接存储而不是指向另一块内存,他们是各自独立一块自己的内存空间来直接存储的。
接着看一下 代码最后的 unset($a)
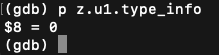
变量的类型是未使用类型,此时并没有真正的释放内存,而是需要时才覆盖或者删除。
四。复杂类型存储
复杂类型(字符串,数组,对象等)的存储占用空间比较大,所以是共享同一块内存,即同一个zval,在进行某些操作时才会单独分开,比如写时复制等。
五。引用类型
说到引用类型,就要区别一下传值和传址,引用类型为传址
传值时,两个变量的地址是不一样的,所以改变一个变量的值时,另一个不会改变。
传址时,两个变量的地址是一样的,所以改变一个变量的值时,另一个也会一起改变。
现在来实战一下,以及哪个问题和我们的预期是不一样的
1. 首先赋值$a
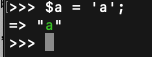
2. 接着赋值$b,此时改变$b的值,$a是不会改变的,因为两个变量的地址是不一样的,即两个zval,这里不再演示
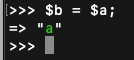
3. 接着用地址赋值$c
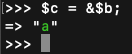
4. 接着改变$c的值,我们知道$b也会改变,因为用的是同一个地址,即同一个zval。
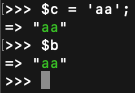
5. 现在来把$c给删除掉,此时我们的预期$b也会变成空。
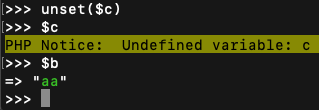
但是结果$b却还存在,这和我们的预期是不一样的
问题主要在于,在 $c=&$b时,= 两边的变量类型变成了引用类型
1. 创建调试代码,调试步骤可看上面
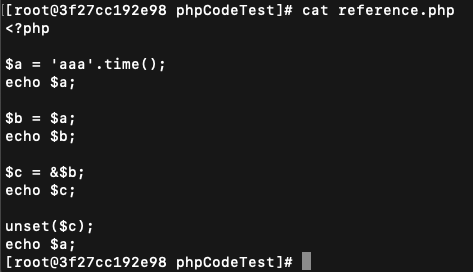
2. 首先查看$a的地址为 0x7f1d67c14080 ,类型为6,即字符串(对照上面的图)

3. 接着查看$a的值为aaa1577371164,引用计数refcount的值为1 ,@13是查看的长度为13

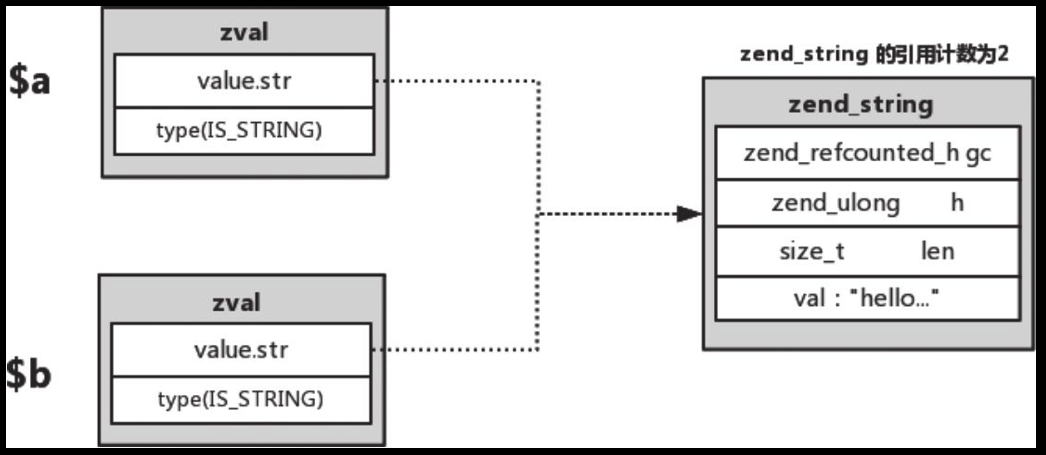
4. 接着查看$b的地址为0x7f1d67c14090,$a和$b的地址不一样,且相差一个zval的大小, $a 和 $b存储字符串的地址都是0x7f1d67c5e8c0 ,共用这一块内存,复杂类型都是这么共用一块内存的

5. 此时$a和$b指向的值的引用计数变为了2

6. 在$c = &$b后,看一下$c,地址为0x7f1d67c140a0,类型为10,即引用类型(看上面的图对照)

7. 现在看一下$b已经由字符串类型变成了引用类型,而$b和$c的值指向的都是同一块内存 0x7f1d67c01118

8. 现在看一下这地址的值,类型为引用类型,引用计数为2,值的地址为0x7f1d67c5e8c0 ,这个地址和前面$a的值所指向的地址是一样的,也就是说$a,$b,$c的值是存储在同一块内存中的

9. 接着再看一下这个地址存储值的值,和前面所看到的值是一样的,即真正存储的值是不变的,此时$a直接指向这个地址,而$b和$c指向了引用的地址,再由这个引用指向这个存储值的地址。

10. 接着往下走unset($c),查看一下$c的类型已经变成了0(对照上图),即未使用的类型,此时$c不再被使用而且随时会被覆盖,但$b和$c所指向的引用地址并没有变化,只是把$c的类型变成了不再被使用

11. 此时查看$b的值和之前是没有变化的,依然是指向上面提到的引用地址

12. 接着查看引用地址有了什么变化,只是引用计数减少了1,由原来的2变成了1,依然指向了存储值的地址

13. 所以得出结论,当使用“&”操作时,会创建一种新的中间结构体zend_reference,这个结构体会指向真正的zend_string结构体,所以zend_string结构体的引用计数不变,同时zend_reference结构体的引用计数变为2,因为$c和$b此时的类型都会变为zend_reference。这样的好处是原始的zend_string在内存中始终只有一份,删除操作也不会影响到其他的值,只会使自身标志为未使用和使中间的引用类型的引用计数减一,如PHP 7底层设计与源码实现这书中的图所示
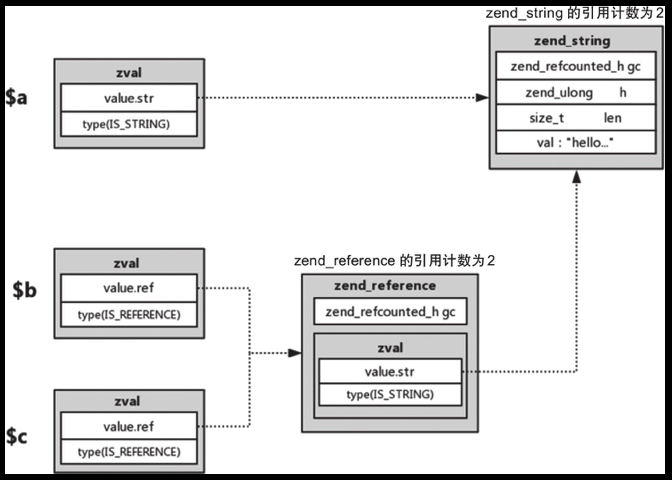
14. 如果在unset之前改变$c的值,$b的值也会改变,$a的值不会改变,这里涉及到写时复制,复制出了另一个zval来存储值。
六。需要解决的疑问
1. 联合体中为什么需要多加一个没有标识作用的字段?比如 value.u1.type_info 中的type_info以及垃圾回收中的gc.u.type_info等
value.u1.type_info 标明了答案,主要是联合体中是共用内存的,直接访问type_info就能访问u,而不需要通过u复杂的访问。
2. 字符串里为什么用柔性数组char val[1],而不是用指针 chat *val ?
数组是连续的一块内存,访问时只需要一次访存,即获取头地址,然后偏移就行了,用指针需要两次访存,即先获取到指针保存的值,是个地址,再到这个地址去拿值。柔性数组不占用内存,指针会占用。
C语言中结构体的最后一个元素可以是大小未知的数组,即柔性数组,用来存储不确定长度的数据。
3. 字符串的柔性数组char val[1]中,为什么不是val[]或者val[0],而偏偏是val[1] ?
主要是为了兼容不同c编译器,c99以前只支持val[1]这种(这些不重要)
4. 字符串的长度可以直接计算出来,为什么还需要个len字段来记录字符串的长度?
一方面是因为二进制安全,可查看 https://www.cnblogs.com/GH-123/p/12159126.html
另一方面是记录了长度之后,同样的字符串不需要重复的计算,不记录的话同个字符串每次都要重复计算
5. 已经有了value.u1.type作为变量的类型判断了,垃圾回收的gc为什么还要冗余的多出gc.u.v.type来再次判断变量的类型?
两个type保存的地址是同一个(可以gdb调试查看),可以看成是个别名,这样可以快速得到值。
七。参考
https://www.amazon.cn/dp/B07D8QSGD9?_encoding=UTF8&psc=1
https://coding.imooc.com/class/312.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号