【爬虫】进一步提取图片url,下载图片
import requests
from lxml import etree
url="https://pic.netbian.com/4kdongman/"
domain="https://pic.netbian.com/"
data=requests.get(url)
#print(data.text)
et=etree.HTML(data.text)
res=et.xpath("//div[@class='slist']/ul/li/a/@href")
#print(res)
image=[]
for i in res:
img_addr=domain+i
img_data=requests.get(img_addr)
#print(img_data.text)
#print(domain+i)
new_et=etree.HTML(img_data.text)
result=new_et.xpath("//div[@class='photo-pic']/a/img/@src")
result=domain+''.join(result) #将列表转成字符串,然后加上域名
image.append(result) #将图片地址存起来
print(result)
#下载图片
for url in image:
imge_res=requests.get(url) #对图片发送url请求
image_con=imge_res.content #拿到图片的字节数据
name=url.split("/")[-1] #获取图片名字
with open(f"E:\爬虫\picture\{name}",'wb') as f:
f.write(image_con)
这里下载图片是用字节读取的方式,下面的两个for循环是对上一次得到的提取到的页面源代码进行正则匹配,找到真正图片的url
上次得到的html是这样子,还得查看页面源代码,找到真正图片url
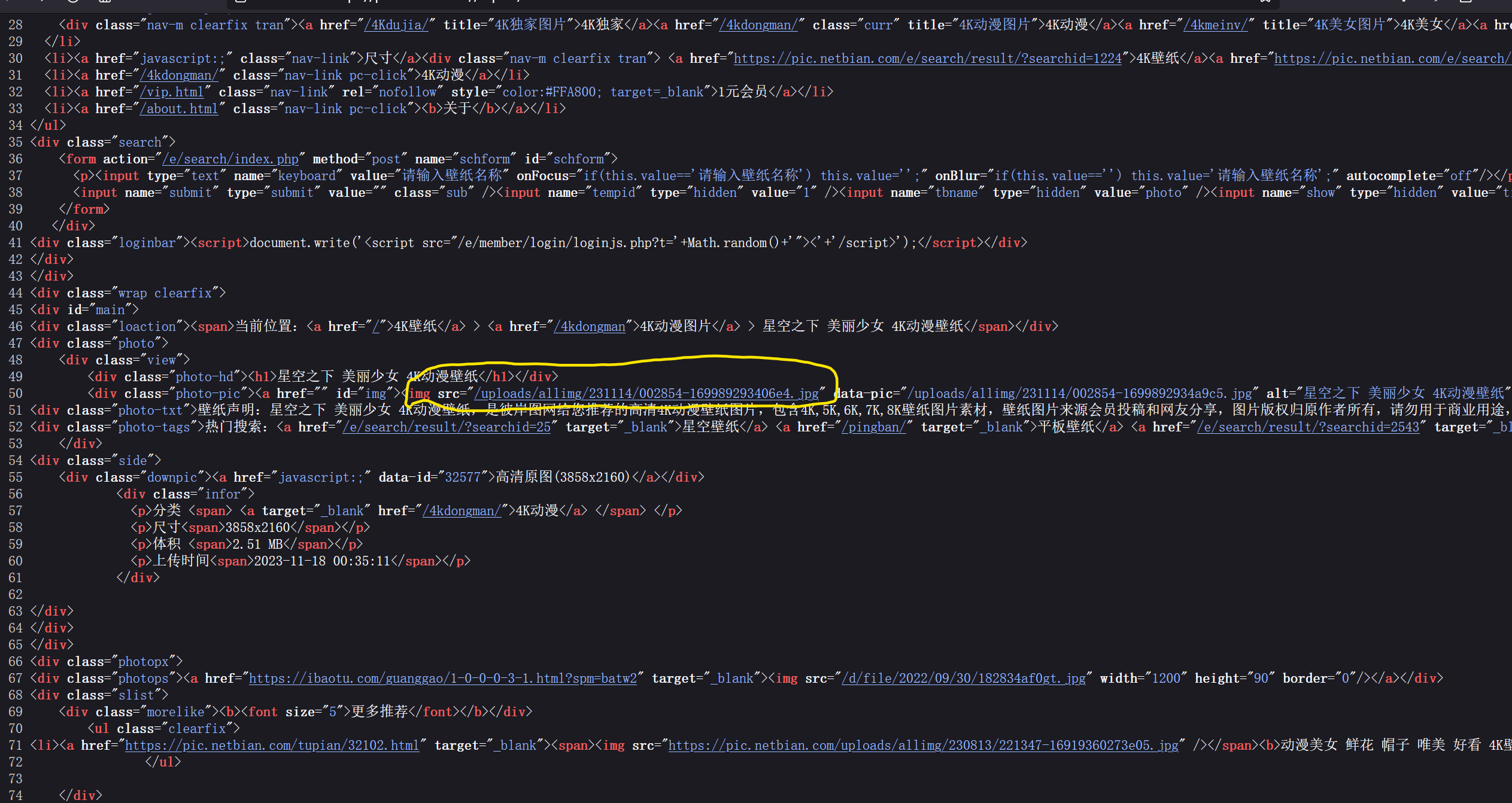
然后用xpath提取,再用字节写入成文件就行,加上for循环,就可以爬取该网站所有图片
import requests
from lxml import etree
for idex in range(129):
url=f"https://pic.netbian.com/4kdongman/index_{idex}.html"
domain="https://pic.netbian.com/"
data=requests.get(url)
#print(data.text)
et=etree.HTML(data.text)
res=et.xpath("//div[@class='slist']/ul/li/a/@href")
#print(res)
image=[]
for i in res:
img_addr=domain+i
img_data=requests.get(img_addr)
#print(img_data.text)
#print(domain+i)
new_et=etree.HTML(img_data.text)
result=new_et.xpath("//div[@class='photo-pic']/a/img/@src")
result=domain+''.join(result) #将列表转成字符串,然后加上域名
image.append(result) #将图片地址存起来
print(result)
#下载图片
for url in image:
imge_res=requests.get(url) #对图片发送url请求
image_con=imge_res.content #拿到图片的字节数据
name=url.split("/")[-1] #获取图片名字
with open(f"E:\爬虫\picture\{name}",'wb') as f:
f.write(image_con)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号