

telegraf获取交换机端口状态已及端口状态报警设置
一. 方法1 32位与64位聚合
介绍: 即能获取64位端口进出口流量又能获取 32位端口状态
缺点: 不易于维护
32位与64位聚合:-------------------------------------------成功--------------------------------
[[inputs.snmp]]
agents = [
""
]
version = 2
community = ""
agent_host_tag = "ident"
fieldpass = ["ifHCInOctets","ifHCOutOctets","ifHighSpeed","ifOperStatus","ifAdminStatus"]
[[inputs.snmp.field]] #指标huawei交换机具体名称表头
name = "hostname"
oid = "SNMPv2-MIB::sysName.0"
is_tag = true #作为标签使用
[[inputs.snmp.table]] #针对要采集的对象:为进出口流量. 表内容
name = "interface" #任意命名指定采集对象的搜索前缀lable
inherit_tags = [ "hostname" ] #代理主机标签即要从顶级配置继承哪些标记并在输出中使用这些标记
oid = "IF-MIB::ifXTable" #需要采集的指标lable
[[inputs.snmp.table]] #针对要采集的对象:为进出口流量. 表内容
name = "interface" #任意命名指定采集对象的搜索前缀lable
inherit_tags = [ "hostname" ] #代理主机标签即要从顶级配置继承哪些标记并在输出中使用这些标记
oid = "IF-MIB::ifTable"
[[inputs.snmp.table.field]] #指标内容:端口作为标签使用 /“表头”
name = "ifDescr" #任意命名为:ifDeser
oid = "IF-MIB::ifName" #指标ID
is_tag = true #命名的此标签是否使用/是/否
[inputs.snmp.tags] #定义插件标签
addr =""
方法2 易于维护
介绍: 另外起一个iftable表加自动发现
单独获取端口状态
端口32位:-------------------------------------------成功案例
[[inputs.snmp]]
agents = [
#wuhanwugang
""
]
version = 2
community = ""
agent_host_tag = "ident"
fieldpass = ["ifOperStatus","ifAdminStatus","ifMtu"]
[[inputs.snmp.field]]
name = "hostname"
oid = "SNMPv2-MIB::sysName.0"
is_tag = true
[[inputs.snmp.table]]
name = "interface"
inherit_tags = [ "hostname" ]
oid = "IF-MIB::ifTable"
[[inputs.snmp.table.field]]
name = "ifDescr"
oid = "IF-MIB::ifDescr"
is_tag = true
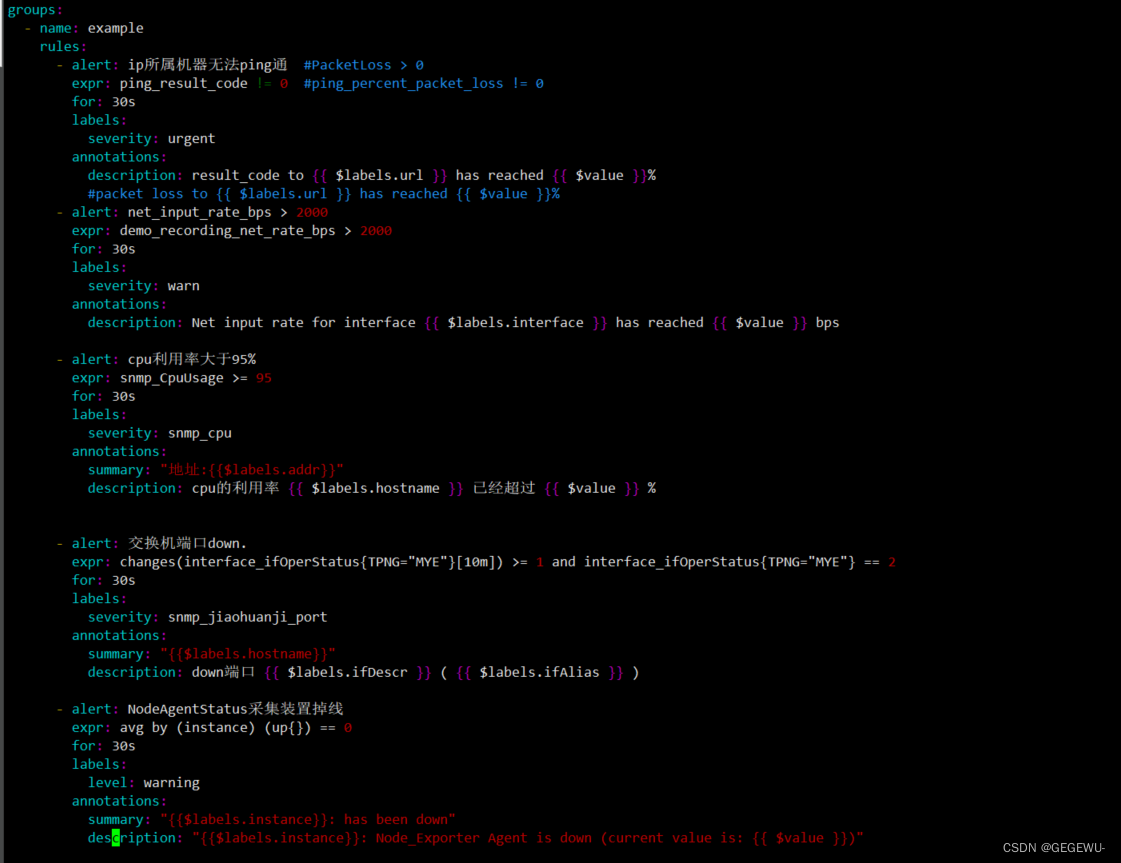
groups: - name: example rules: - alert: ip所属机器无法ping通 #PacketLoss > 0 expr: ping_result_code != 0 #ping_percent_packet_loss != 0 for: 30s labels: severity: urgent annotations: description: result_code to {{ $labels.url }} has reached {{ $value }}% #packet loss to {{ $labels.url }} has reached {{ $value }}% - alert: net_input_rate_bps > 2000 expr: demo_recording_net_rate_bps > 2000 for: 30s labels: severity: warn annotations: description: Net input rate for interface {{ $labels.interface }} has reached {{ $value }} bps - alert: cpu利用率大于95% expr: snmp_CpuUsage >= 95 for: 30s labels: severity: snmp_cpu annotations: summary: "地址:{{$labels.addr}}" description: cpu的利用率 {{ $labels.hostname }} 已经超过 {{ $value }} % - alert: 交换机端口down. expr: changes(interface_ifOperStatus{TPNG="MYE"}[10m]) >= 1 and interface_ifOperStatus{TPNG="MYE"} == 2 for: 30s labels: severity: snmp_jiaohuanji_port annotations: summary: "{{$labels.hostname}}" description: down端口 {{ $labels.ifDescr }} ( {{ $labels.ifAlias }} ) - alert: NodeAgentStatus采集装置掉线 expr: avg by (instance) (up{}) == 0 for: 30s labels: level: warning annotations: summary: "{{$labels.instance}}: has been down" description: "{{$labels.instance}}: Node_Exporter Agent is down (current value is: {{ $value }})"
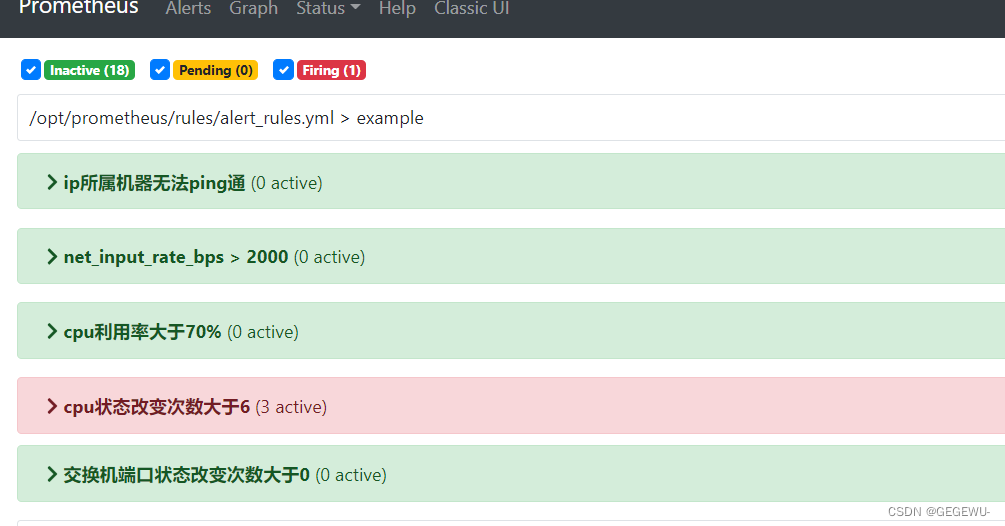
prometheus前端页面详情:
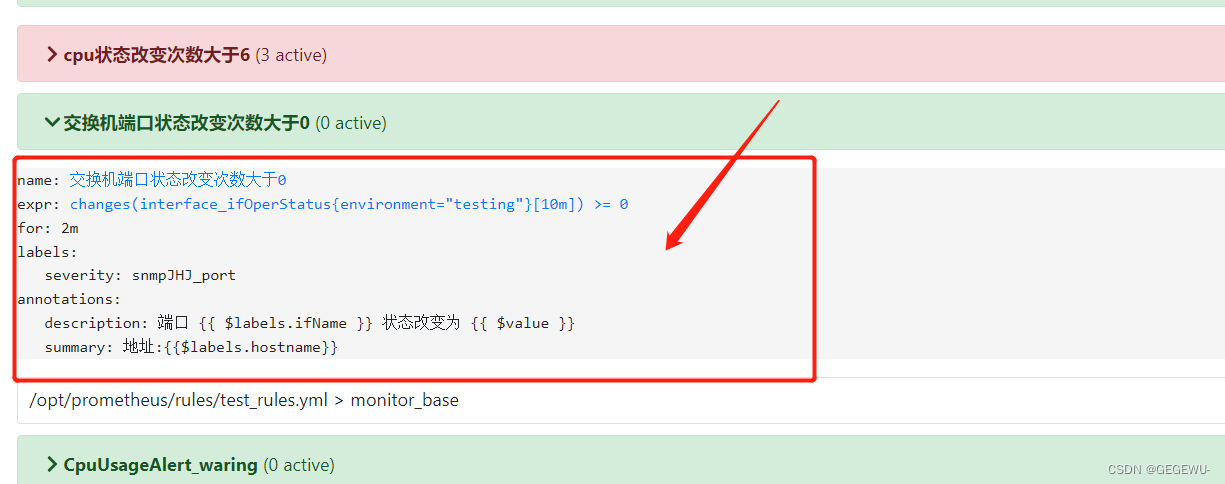
其他报警规则附带:
groups:
- name: monitor_base
rules:
- alert: CpuUsageAlert_waring
expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 60% (current value: {{ $value }})"
- alert: CpuUsageAlert_serious
#expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.85
expr: (100 - (avg by (instance) (irate(node_cpu_seconds_total{job=~".*",mode="idle"}[5m])) * 100)) > 85
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: MemUsageAlert_waring
expr: avg by(instance) ((1 - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes) * 100) > 70
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{$labels.instance}}: MEM usage is above 70% (current value is: {{ $value }})"
- alert: MemUsageAlert_serious
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{ $labels.instance }} MEM usage above 90% (current value: {{ $value }})"
- alert: DiskUsageAlert_warning
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }})"
- alert: DiskUsageAlert_serious
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 90% (current value is: {{ $value }})"
- alert: NodeFileDescriptorUsage
expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} File Descriptor usage high"
description: "{{$labels.instance}}: File Descriptor usage is above 60% (current value is: {{ $value }})"
- alert: NodeLoad15
expr: avg by (instance) (node_load15{}) > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Load15 usage high"
description: "{{$labels.instance}}: Load15 is above 80 (current value is: {{ $value }})"
- alert: NodeAgentStatus
expr: avg by (instance) (up{}) == 0
for: 2m
labels:
level: warning
annotations:
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: Node_Exporter Agent is down (current value is: {{ $value }})"
- alert: NodeProcsBlocked
expr: avg by (instance) (node_procs_blocked{}) > 10
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Process Blocked usage high"
description: "{{$labels.instance}}: Node Blocked Procs detected! above 10 (current value is: {{ $value }})"
- alert: NetworkTransmitRate
#expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Transmit Rate usage high"
description: "{{$labels.instance}}: Node Transmit Rate (Upload) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: NetworkReceiveRate
#expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Receive Rate usage high"
description: "{{$labels.instance}}: Node Receive Rate (Download) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: DiskReadRate
expr: avg by (instance) (floor(irate(node_disk_read_bytes_total{}[2m]) / 1024 )) > 200
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Read Rate usage high"
description: "{{$labels.instance}}: Node Disk Read Rate is above 200KB/s (current value is: {{ $value }}KB/s)"
- alert: DiskWriteRate
expr: avg by (instance) (floor(irate(node_disk_written_bytes_total{}[2m]) / 1024 / 1024 )) > 20
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Write Rate usage high"
description: "{{$labels.instance}}: Node Disk Write Rate is above 20MB/s (current value is: {{ $value }}MB/s)"
