一、Redis基本操作
1.连接redis
root@3f706a745e74:/data# redis-cli
127.0.0.1:6379>
2.查看所有数据
127.0.0.1:6379> keys *
1) "a"
#查看时注意不要轻易使用,如想查看数据,先查看数据量DBSIZE
127.0.0.1:6379> DBSIZE
(integer) 1
3.添加数据
127.0.0.1:6379> set k1 v1
OK
4.查看数据
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379> get k1
"v1"
5.删除数据
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379> del k1
(integer) 1
127.0.0.1:6379> keys *
(empty array)
#根据value选择非阻塞删除仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
127.0.0.1:6379> UNLINK ke
(integer) 1
6.修改数据
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k1 v11111
OK
127.0.0.1:6379> get k1
"v11111"
7.追加数据
127.0.0.1:6379> APPEND k1 ggg
(integer) 9
127.0.0.1:6379> get k1
"v11111ggg"
8.切换库
#1.切换库[1-15]
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> SELECT 2
OK
127.0.0.1:6379[2]> SELECT 3
OK
127.0.0.1:6379[3]> SELECT 16
(error) ERR DB index is out of range
#2.清空当前库
127.0.0.1:6379> FLUSHDB
OK
#3.通杀全部库
127.0.0.1:6379> FLUSHALL
OK
二、密码的设置
1.配置文件配置密码
#1.修改配置文件
[root@db01 redis]# vim redis.conf
requirepass DataXgroup@9H
#2.使用密码连接
[root@db01 redis]# redis-cli -a DataXgroup@9H
#3.登陆后输入密码
[root@db01 redis]# redis-cli
127.0.0.1:6379> AUTH DataXgroup@9H
OK
127.0.0.1:6379> DBSIZE
(integer) 2018041
#4.redis连接后获取密码
127.0.0.1:6379[3]> CONFIG GET requirepass
1) "requirepass"
2) "DataXgroup@9H"
2.redis连接后修改密码
#1.修改redis密码为DataXgroup@9G
127.0.0.1:6379[3]> CONFIG SET requirepass DataXgroup@9G
OK
127.0.0.1:6379[3]> exit
#2.测试登录
root@3f706a745e74:/data# redis-cli
127.0.0.1:6379> DBSIZE
(error) NOAUTH Authentication required.
127.0.0.1:6379> AUTH DataXgroup@9H
(error) WRONGPASS invalid username-password pair or user is disabled.
127.0.0.1:6379> auth DataXgroup@9G
OK
三、Redis键(key)
1.查看当前库所有key
#1.查看当前库所有key
127.0.0.1:6379> keys *
1) "k1"
2) "ke"
#2.匹配键k1
127.0.0.1:6379> keys *k1
1) "k1"
2.判断key是否存在
#存在则返回1
127.0.0.1:6379> EXISTS k1
(integer) 1
127.0.0.1:6379> EXISTS ke
(integer) 1
#不存在则返回0
127.0.0.1:6379> EXISTS k2
(integer) 0
3.修改key的名字
127.0.0.1:6379> RENAME ke k100
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k100"
4.查看数据类型
127.0.0.1:6379> TYPE k100
string
5.设置生存时间
#以秒为单位
127.0.0.1:6379> set jh gg
OK
127.0.0.1:6379> EXPIRE jh 10
(integer) 1
#以毫秒为单位
127.0.0.1:6379> pexpire k100 10000
(integer) 1
6.查看生存时间
#正整数生存时间倒计时
127.0.0.1:6379> TTL k100
(integer) 1
#-1代表没有设置生存时间
127.0.0.1:6379> TTL k100
(integer) -1
#代表设置过生存时间已删除,已过期
127.0.0.1:6379> TTL k100
(integer) -2
#1.以秒为单位
ttl key
127.0.0.1:6379> ttl mysets
-1 # -1代表永不过期
#2.以毫秒为单位
Pttl key
127.0.0.1:6379> PTTL a
-1 # -1代表永不过期
7.取消生存时间
127.0.0.1:6379> set jh nnng
OK
127.0.0.1:6379> EXPIRE jh 200
(integer) 1
127.0.0.1:6379> ttl jh
(integer) 196
127.0.0.1:6379> PERSIST jh
(integer) 1
127.0.0.1:6379> ttl jh
(integer) -1
8. 随机返回一个key
127.0.0.1:6379> RANDOMKEY
myset_sdiff
127.0.0.1:6379> RANDOMKEY
new_myset
127.0.0.1:6379> RANDOMKEY
myset
四、Redis数据结构之字符串(String)
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
1.命令行模式
进入命令行模式:
#a 输入密码
redis-cli -a password_value
#raw 避免中文显示乱码
redis-cli -a password_value --raw
2. 查看命令帮助
127.0.0.1:6379> help @string
APPEND key value
summary: Append a value to a key
since: 2.0.0
BITCOUNT key [start end]
summary: Count set bits in a string
since: 2.6.0
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
3.Exists
#查看key是否存在,返回true / false(0/1)
127.0.0.1:6379> EXISTS a
1
127.0.0.1:6379> EXISTS b
0
4.TTL
#查看数据过期时间
127.0.0.1:6379> ttl a
-1 # 永不过期
127.0.0.1:6379> ttl b
(integer) 2 # 过期时间还有2个单位
5.增加数据
增加数据的命令有以下几个:set,setex,psetex,setnx。
#1.常用命令
set key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]
1.*NX:当数据库中key不存在时,可以将key-value添加数据库
2.*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
3.*EX:key的超时秒数
4.*PX:key的超时毫秒数,与EX互斥
#2.使用set命令新增一个键值对及其EX,PX用法
--1.设置
127.0.0.1:6379> set name jh
OK
127.0.0.1:6379> get name
"jh"
--2.设置过期时间为秒
127.0.0.1:6379> set name jh ex 10
OK
127.0.0.1:6379> ttl name
(integer) 6
127.0.0.1:6379> ttl name
(integer) -2
--3.set 和 ex合并成setex
127.0.0.1:6379> SETEX name 10 jh
OK
127.0.0.1:6379> ttl name
(integer) 6
127.0.0.1:6379> ttl name
(integer) -2
--4.设置过期时间为毫秒
127.0.0.1:6379> set name jh px 10
OK
127.0.0.1:6379> ttl name
(integer) -2
--5.set 和 px 合并使用
127.0.0.1:6379> PSETEX name 100 jh
OK
127.0.0.1:6379> ttl name
(integer) -2
#3.使用set命令新增一个键值对及其NX,XX用法
Nx:当key不存在时创建,已存在则忽略。
Xx:当key存在则更新,不存在则忽略。
# nx
127.0.0.1:6379> set name jh nx
OK
127.0.0.1:6379> get name
"jh"
127.0.0.1:6379> set name jindada
OK
127.0.0.1:6379> get name
"jindada"
127.0.0.1:6379> set name jh nx
(nil)
127.0.0.1:6379> get name
"jindada"
# set 与 nx 合并使用
127.0.0.1:6379> SETNX name jh
(integer) 0
127.0.0.1:6379> get name
"jindada"
#4.批量增加
同时定义多个键值对,mset也可以和nx一起用。
mset key1 value1 [key2 value2...] #批量创建kv,已存在的会被更新
msetnx key1 value1 [key2 value2...] #批量创建kv,所有key不存在才会创建
127.0.0.1:6379> mset k1 a k2 b k3 c
OK
127.0.0.1:6379> MGET k1 k2 k3
1) "a"
2) "b"
3) "c"
6. 删除数据
DDL #删除数据
使用del命令删除数据,可批量可单个删除。
#格式
del key1 [key2 key3...]
#案例
127.0.0.1:6379> del k1 k2 k3
(integer) 3
127.0.0.1:6379> del name_xx
(integer) 1
127.0.0.1:6379> mget k1 k2 k3 name_xx name_nx
1) (nil)
2) (nil)
3) (nil)
4) (nil)
5) "wyk"
7.更改数据
#1.使用set命令修改数据
127.0.0.1:6379> get name
"jindada"
127.0.0.1:6379> set name jh
OK
127.0.0.1:6379> get name
"jh"
#2.使用getset命令修改数据
等同于get+set,执行此命令返回get的结果,然后将该key更新为新的value,下次再get的时候查到的就是新的value。
127.0.0.1:6379> GETSET name jindada
"jh"
127.0.0.1:6379> get name
"jindada"
#3.使用setrange按下标更新数据
对指定下标的字符串进行更新,下标从0开始算起。
127.0.0.1:6379> SETRANGE name 5 eidei
(integer) 10
127.0.0.1:6379> get name
"jindaeidei"
8.查找数据
#1.查看所有的key
查看所有的Key,在数据量大的Redis中慎用,容易卡死。
127.0.0.1:6379> KEYS *
1) "k1"
2) "name"
3) "k2"
4) "k3"
#2.根据key获取数据
使用get获得指定key的value。
127.0.0.1:6379> get name
"jindaeidei"
#3.批量获得指定keys的values
mget key1 [key2 key3...]
127.0.0.1:6379> mget k1 k2 k3
1) "a"
2) "b"
3) "c"
#4.从字符串的指定开始结束下标截取字符串
getrange key start end
127.0.0.1:6379> GETRANGE name 0 4
"jinda"
9.计数
#1.指定key递增
对指定的key的value加1,递增步长默认1,如果key不存在,其初始值为0,在incr之后其值为1,如果value的值不能转为整型,如hello,该操作将执行失败并返回相应的错误信息。
127.0.0.1:6379> INCR num
1
127.0.0.1:6379> INCR num
2
#2.指定key递减
对指定的key的value减1,递减步长默认1,如果key不存在,其初始值为0,在decr之后其值为-1,如果value的值不能转为整型,如hello,该操作将执行失败并返回相应的错误信息。
127.0.0.1:6379> DECR num
1
127.0.0.1:6379> DECR num
0
#3.递增指定长度
对指定的key的value加指定的步长,递增步长可指定,如果key不存在,其初始值为0,在incrby之后其值为步长,如果value的值不能转为整型,如hello,该操作将执行失败并返回相应的错误信息。
$步长increment为整数,当为负数时效果等于递减
incrby key increment
#4.递减指定长度
对指定的key的value减指定的步长,递减步长可指定,如果key不存在,其初始值为0,在decrby之后其值为步长的负数,如果value的值不能转为整型,如hello,该操作将执行失败并返回相应的错误信息。
$步长increment为整数,当为负数时效果等于递増
decrby key increment
redis> SET count 100
OK
redis> DECRBY count 20
(integer) 80
10.追加
#在字符串最后面追加子串
append key value
# 对不存在的 key 执行 APPEND
## 确保 myphone 不存在
redis> EXISTS myphone
(integer) 0
# 对不存在的 key 进行 APPEND ,等同于 SET myphone "nokia"
## 字符长度
redis> APPEND myphone "nokia"
(integer) 5
# 对已存在的字符串进行 APPEND
## 长度从 5 个字符增加到 12 个字符
redis> APPEND myphone " - 1110"
(integer) 12
redis> GET myphone
"nokia - 1110"
11.长度
#返回字符的长度
strlen key
12.数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.
![]()
如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
五、Redis数据结构之列表(List)
单键多值
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
![]()
1.查看命令帮助
help @list
BLPOP key [key ...] timeout
summary: Remove and get the first element in a list, or block until one is available
since: 2.0.0
BRPOP key [key ...] timeout
summary: Remove and get the last element in a list, or block until one is available
since: 2.0.0
2.从左边插入元素
从左边插入元素,从左边依次追加进栈,先进后出,后进先出
LPUSH key element [element ...]
127.0.0.1:6379> LPUSH mylist jh 18
2
127.0.0.1:6379> LPUSH mylist shanghai
3
127.0.0.1:6379> LRANGE mylist 0 -1
1) "shanghai"
3) "18"
4) "jh"
3.从右边插入元素
从右边插入元素,从右边依次追加进队列,先进先出,后进后出。
RPUSH key element [element ...]
127.0.0.1:6379> RPUSH mylist python
(integer) 4
127.0.0.1:6379> RPUSH mylist linux
(integer) 5
127.0.0.1:6379> LRANGE mylist 0 -1
1) "shanghai"
3) "18"
4) "jh"
5) "python"
6) "linux"
4. list存在时才会从左边依次追加元素
#与sting类型中的nx类似,只有当list存在时才会从左边依次追加元素。
LPUSHX key element [element ...]
127.0.0.1:6379> LPUSHX mylist Shanghai7
(integer) 6
127.0.0.1:6379> LRANGE mylist 0 -1
1) "Shanghai7"
2) "shanghai"
3) "18"
4) "jh"
5) "python"
6) "linux"
127.0.0.1:6379> LPUSHX testlist Shanghai0
(integer) 0
127.0.0.1:6379> LRANGE testlist
(error) ERR wrong number of arguments for 'lrange' command
5.当list存在时才会从右边依次追加元素
#与lpushx类似,只有当list存在时才会从右边依次追加元素。
RPUSHX key element [element ...]
127.0.0.1:6379> RPUSH testlist jh
(integer) 1
127.0.0.1:6379> LRANGE testlist 0 -1
1) "jh"
127.0.0.1:6379> RPUSHX testlist 18
(integer) 2
127.0.0.1:6379> LRANGE testlist 0 -1
1) "jh"
2) "18"
6. 从list中指定的元素的前/后 插入一个新元素
LINSERT key BEFORE|AFTER pivot element
127.0.0.1:6379> LRANGE testlist 0 -1
1) "jh"
2) "18"
# 在某个KEY之前插入某个值
127.0.0.1:6379> LINSERT mylist before 18 179
127.0.0.1:6379> LRANGE mylist 0 -1
Shanghai上海1718alvin上海市linuxpythonQingPu
# 在某个值后面添加一个值
127.0.0.1:6379> LINSERT mylist after 18 1610
127.0.0.1:6379> LRANGE mylist 0 -1
Shanghai上海171816alvin上海市linuxpythonQingPu
127.0.0.1:6379>
7.删除数据
#1.从列表左侧开始移除LREM key count element
127.0.0.1:6379> 127.0.0.1:6379> LINSERT mylist after 18 1614
(integer) 8
127.0.0.1:6379> LINSERT mylist after 18 1615
(integer) 9
127.0.0.1:6379> LINSERT mylist after 18 1616
(integer) 10
127.0.0.1:6379> LRANGE mylist 0 -1
1) "Shanghai7"
2) "shanghai"
4) "18"
5) "1616"
6) "1615"
7) "1614"
8) "jh"
9) "python"
10) "linux
127.0.0.1:6379> LREM mylist 2 1614
127.0.0.1:6379> LRANGE mylist 0 -1
1) "Shanghai7"
2) "shanghai"
3) "18"
4) "1616"
5) "1615"
6) "jh"
7) "python"
8) "linux"
8. 修改数据
#1.修改元素内容
LSET key index element
127.0.0.1:6379> LRANGE mylist 0 -1
1) "Shanghai7"
2) "shanghai"
3) "18"
4) "1616"
5) "1615"
6) "jh"
7) "python"
8) "linux"
127.0.0.1:6379> LSET mylist 2 19
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "Shanghai7"
2) "shanghai"
3) "19"
4) "1616"
5) "1615"
6) "jh"
7) "python"
8) "linux"
#2.截取为从下标start到下标stop闭区间的列表
将原列表截取为从下标start到下标stop闭区间的列表,即原列表变为一个第start+1个到第stop+1个元素的列表。
LTRIM key start stop
127.0.0.1:6379> LTRIM mylist 2 8
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "19"
2) "1616"
3) "1615"
4) "jh"
5) "python"
6) "linux"
9. 查询数据
#1.查看列表中元素的个数
LLEN key
127.0.0.1:6379> LLEN mylist
(integer) 6
#2.根据起止下标查询列表元素
LRANGE key start stop
127.0.0.1:6379> lrange mylist 0 -1 #表示查看全部元素
1) "19"
2) "1616"
3) "1615"
4) "jh"
5) "python"
6) "linux"
127.0.0.1:6379> lrange mylist -1 -1 #表示查看最右边的元素
1) "linux"
#3.根据指定的index下标查看列表中的元素
LINDEX key index
127.0.0.1:6379> LINDEX mylist 3
"jh"
#4.从左边消费列表中的元素
从左边消费列表中的元素,消费完之后从列表中删除。
LPOP key
127.0.0.1:6379> LRANGE mylist 0 -1
1) "19"
2) "1616"
3) "1615"
4) "jh"
5) "python"
6) "linux"
127.0.0.1:6379> LPOP mylist
"19"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "1616"
2) "1615"
3) "jh"
4) "python"
5) "linux"
#5.从右边消费列表中的元素
从右边消费列表中的元素,消费完之后从列表中删除。
RPOP key
127.0.0.1:6379> LRANGE mylist 0 -1
1) "1616"
2) "1615"
3) "jh"
4) "python"
5) "linux"
127.0.0.1:6379> RPOP mylist
"linux"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "1616"
2) "1615"
3) "jh"
4) "python"
#6.消费列表最右边的元素并返回
消费列表A的最右边的元素返回,然后追加到列表B的最左边。
RPOPLPUSH source destination
RPOPLPUSH List_A List_B
127.0.0.1:6379> LRANGE mylist 0 -1
1) "1616"
2) "1615"
3) "jh"
4) "python"
127.0.0.1:6379> RPOPLPUSH mylist mylist
"python"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "python"
2) "1616"
3) "1615"
4) "jh"
#7.从列表中左侧查询元素
从列表中左侧查询元素,返回列表的key和左侧第一个元素,若所有查询的列表中都没有元素,则会阻塞等待至设置的timeout秒之后返回空,若在这期间,这些列表新增了元素,则会立刻消费并返回该元素。
BLPOP key [key ...] timeout
127.0.0.1:6379> BLPOP mylist 10
1) "mylist"
2) "1616"
127.0.0.1:6379> BLPOP mylist 10
1) "mylist"
2) "1615"
127.0.0.1:6379> BLPOP mylist 10
1) "mylist"
2) "jh"
10.数据结构
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。
![]()
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
六、Redis数据结构之无序集合(Set)
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变。集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
1. 查看帮助命令
#使用Redis命令手册查看
127.0.0.1:6379> help @set
2.增加数据
#1.给集合内新增成员,若集合不存在则创建集合并新增成员。
SADD key member [member ...]
#2.示例
127.0.0.1:6379> SADD myset 1
(integer) 1
127.0.0.1:6379> SADD myset 2
(integer) 1
127.0.0.1:6379> SADD myset 3
(integer) 1
127.0.0.1:6379> SADD myset 4
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "1"
2) "2"
3) "3"
4) "4"
3. 删除数据
#1.从集合中删除指定的成员,返回删除的个数。
SREM key member [member ...]
#2.示例
127.0.0.1:6379> SREM myset 2 4
(integer) 2
127.0.0.1:6379> SMEMBERS myset
1) "1"
2) "3"
4. 修改数据
#1.移动数据
SMOVE source destination member
#2.示例
127.0.0.1:6379> SADD myset1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> SADD myset2 one two three
(integer) 3
127.0.0.1:6379> SMOVE myset1 myset2 4
(integer) 1
127.0.0.1:6379> SMEMBERS myset1
1) "1"
2) "2"
3) "3"
4) "5"
127.0.0.1:6379> SMEMBERS myset2
1) "three"
2) "two"
3) "4"
4) "one"
5.查看数据
#1.查看集合中所有的成员
SMEMBERS key
127.0.0.1:6379> SMEMBERS myset1
1) "1"
2) "2"
3) "3"
4) "5"
#2.返回集合中成员的个数
SCARD key
127.0.0.1:6379> SCARD myset1
(integer) 4
#3.从集合中随机返回指定个数的成员
SRANDMEMBER key [count]
127.0.0.1:6379> SRANDMEMBER myset1 2
1) "3"
2) "2"
127.0.0.1:6379> SRANDMEMBER myset1 2
1) "5"
2) "3"
#4.判断对象是否是集合中的成员,1表示true,0表示false
SISMEMBER key member
127.0.0.1:6379> SISMEMBER myset1 6
(integer) 0
127.0.0.1:6379> SISMEMBER myset1 2
(integer) 1
#5.随机返回一个成员,从集合中随机弹出一个成员,返回该成员并从集合中删除该成员。
SPOP key
127.0.0.1:6379> SPOP myset2
"one"
127.0.0.1:6379> SPOP myset2
"two"
127.0.0.1:6379> SPOP myset2
"three"
127.0.0.1:6379> SMEMBERS myset2
1) "4"
6.交集
#1.取多个集合的交集,返回这些集合中共同拥有的成员。
SINTER key [key ...]
127.0.0.1:6379> sadd myseta 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd mysetb 4 5 6 7 8
(integer) 5
127.0.0.1:6379> sadd mysetc 5 6 7 8 9
(integer) 5
127.0.0.1:6379> SINTER myseta mysetb mysetc
1) "5"
#2.将多个集合的交集的结果保存为一个新的集合destination,返回新集合的成员个数。
SINTERSTORE destination key [key ...]
127.0.0.1:6379> SINTERSTORE mysetc mysetb myseta
(integer) 2
127.0.0.1:6379> SMEMBERS mysetc
1) "4"
2) "5"
7. 并集
#1.取多个集合的并集,相同的成员会被去重。
SUNION key [key ...]
127.0.0.1:6379> SMEMBERS mysetb
1) "4"
2) "5"
3) "6"
4) "7"
5) "8"
127.0.0.1:6379> SMEMBERS myseta
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> SUNION myseta mysetb
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
#2.将多个集合的并集的结果保存为一个新的集合
SUNIONSTORE destination key [key ...]
127.0.0.1:6379> SUNIONSTORE mysetc myseta mysetb
(integer) 8
127.0.0.1:6379> SMEMBERS mysetc
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
8. 差集
#1.取多个集合的差集,以最左边的为主集合,返回左集合中有而其他集合没有的成员。
127.0.0.1:6379> SDIFF myseta mysetb
1) "1"
2) "2"
3) "3"
9. 将多个集合的差集的结果保存为一个新的集合
#将多个集合的差集的结果保存为一个新的集合 ,返回新集合的成员个数 。
SDIFFSTORE destination key [key ...]
127.0.0.1:6379> SDIFFSTORE mysetc myseta mysetb
(integer) 3
127.0.0.1:6379> SMEMBERS mysetc
1) "1"
2) "2"
3) "3"
10.数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
七、Redis数据结构之哈希(Hash)
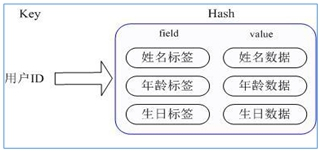
Redis hash 是一个键值对集合。
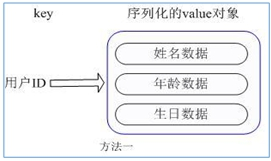
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似于python中的dict和java中的map集合。用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下2种存储方式:
![]()
每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大。
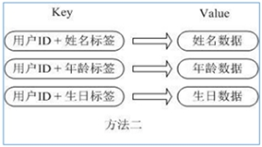
![]()
用户ID数据冗余
![]()
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
1.查看命令帮助
not connected> help @hash
HDEL key field [field ...]
summary: Delete one or more hash fields
since: 2.0.0
HEXISTS key field
summary: Determine if a hash field exists
since: 2.0.0
2. 设置hash类型的单个field或一次性设置多个field
HSET key field value [field value ...]
127.0.0.1:6379> hset csdn id 1 name jh company 上海
(integer) 3
3.查看hash类型的key中指定的field是否存在
hexists key field
127.0.0.1:6379> HEXISTS csdn name
1
127.0.0.1:6379> HEXISTS csdn company
1
4.只有value中不存在的field才会被创建
HSETNX key field value
5. 删除数据
#使用hdel命令删除hash类型的value中的fields,可批量可单个删除
HDEL key field1 [field2 ...]
127.0.0.1:6379> HDEL csdn name
1
127.0.0.1:6379> HEXISTS csdn name
0
6.更改数据
#对hash类型中相同的field进行set操作会更新该field的值
HSET key field value [field value ...]
127.0.0.1:6379> HSET csdn name jindada
0
7.查找数据
#1.使用hget获取指定hash类型的field对应的值
HGET key field
127.0.0.1:6379> Hget csdn name
jindada
#2.使用hmget获取指定hash类型的多个field对应的值
HMGET key field [field ...]
127.0.0.1:6379> hmget csdn name company
jindada
上海
#3.使用hgetall获得指定hash类型对象的全部field和对应的value值
HGETALL key
127.0.0.1:6379> HGETALL csdn
id
1
company
上海
name
jindada
#4.使用hkeys获得指定hash类型对象的全部field
HKEYS key
127.0.0.1:6379> HKEYS csdn
id
company
name
#5.使用hvals获得指定hash类型对象的全部field的values值
HVALS key
127.0.0.1:6379> HVALS csdn
1
上海
jindada
8. 计数
#1.hincrby可以对hash对象的指定的field的value做递增操作
与string类型中的incrby类似,hincrby可以对hash对象的指定的field的value做递增操作,increment必须是整数(hash类型中没有hdecrby方法,当increment为负数时为递减操作),value必须是integer类型,否则会报对应的错误。
HINCRBY key field increment
ps:filed对应的value必须是integer类型,increment必须是整数,可以为负
127.0.0.1:6379> HINCRBY csdn id 10
11
#2.hincrbyfloat可以对hash对象的指定的field的value做递增操作
与string类型中的incrbyfloat类似,hincrbyfloat可以对hash对象的指定的field的value做递增操作,increment可以是整数或浮点数(hash类型中没有hdecrbyfloat方法,当increment为负数时为递减操作),value必须是数字类型,否则会报对应的错误。
HINCRBYFLOAT key field increment
ps:filed对应的value必须是数字类型,increment可以是整数或浮点,可以为负
127.0.0.1:6379> HINCRBYFLOAT csdn id 10.9
21.9
9. 长度
#1.hlen返回hash类型中field的数量
HLEN key
127.0.0.1:6379> HLEN csdn
3
#2.hstrlen返回hash类型中指定filed对应的value的字符长度
HSTRLEN key field
127.0.0.1:6379> HSTRLEN csdn id
4
127.0.0.1:6379> HSTRLEN csdn company
6
10.过期
#我们可以看到hash类型没有hsetex hpsetex一类的方法,想对hash对象做过期策略可以使用全局函数expire。
expire key seconds
127.0.0.1:6379> EXPIRE csdn 1000
1
127.0.0.1:6379> ttl csdn
993
11.数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
八、Redis数据结构之有序集合Zset(sorted set)
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
1.查看命令帮助
127.0.0.1:6379> help @sorted_set
2.增加数据
#1.往有序集合中新增成员,需要指定该成员的分数,分数可以是整形或浮点型,当分数相同时候,索引下标按照字典排序。
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]
#2.示例
127.0.0.1:6379> ZADD myzset 1 jh
1
127.0.0.1:6379> ZADD myzset 2 shanghai 3 beijing
2
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
shanghai
beijing
3.查询数据
#1.获取有序集合的成员数
ZCARD key
127.0.0.1:6379> ZCARD myzset
3
#2.获取指定分数区间内的成员数
从有序集合内获取指定分数区间内的成员数。
ZCOUNT key min max
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
shanghai
beijing
127.0.0.1:6379> ZCOUNT myzset 1 2
2
#3.字典排序
根据字典排序返回min ,max之间的数据量.
ZLEXCOUNT key min max
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
shanghai
beijing
127.0.0.1:6379> ZLEXCOUNT myzset [sh [zzz
0
#4.获取成员的分数值
返回有序集中,成员的分数值,不存在的成员返回空。
ZSCORE key member
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
shanghai
beijing
127.0.0.1:6379> ZSCORE myzset shanghai
2
#5.迭代有序集合中的元素(包括元素成员和元素分值)
127.0.0.1:6379> ZSCAN myzset 0 match "sh*"
0
shanghai
2
127.0.0.1:6379> ZSCAN myzset 0 match "j*"
0
jh
1
5.删除数据
#1.移除指定的成员
ZREM key member [member ...]
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
shanghai
beijing
127.0.0.1:6379> ZREM myzset shanghai
1
127.0.0.1:6379> ZRANGE myzset 0 -1
jh
beijing
6.数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构:
1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
7.跳跃表(跳表)
1、简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
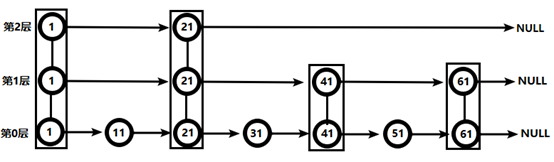
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表
要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
![]()
(2) 跳跃表
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号