
深入理解 DB-GPT
DB-GPT 项目介绍
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。
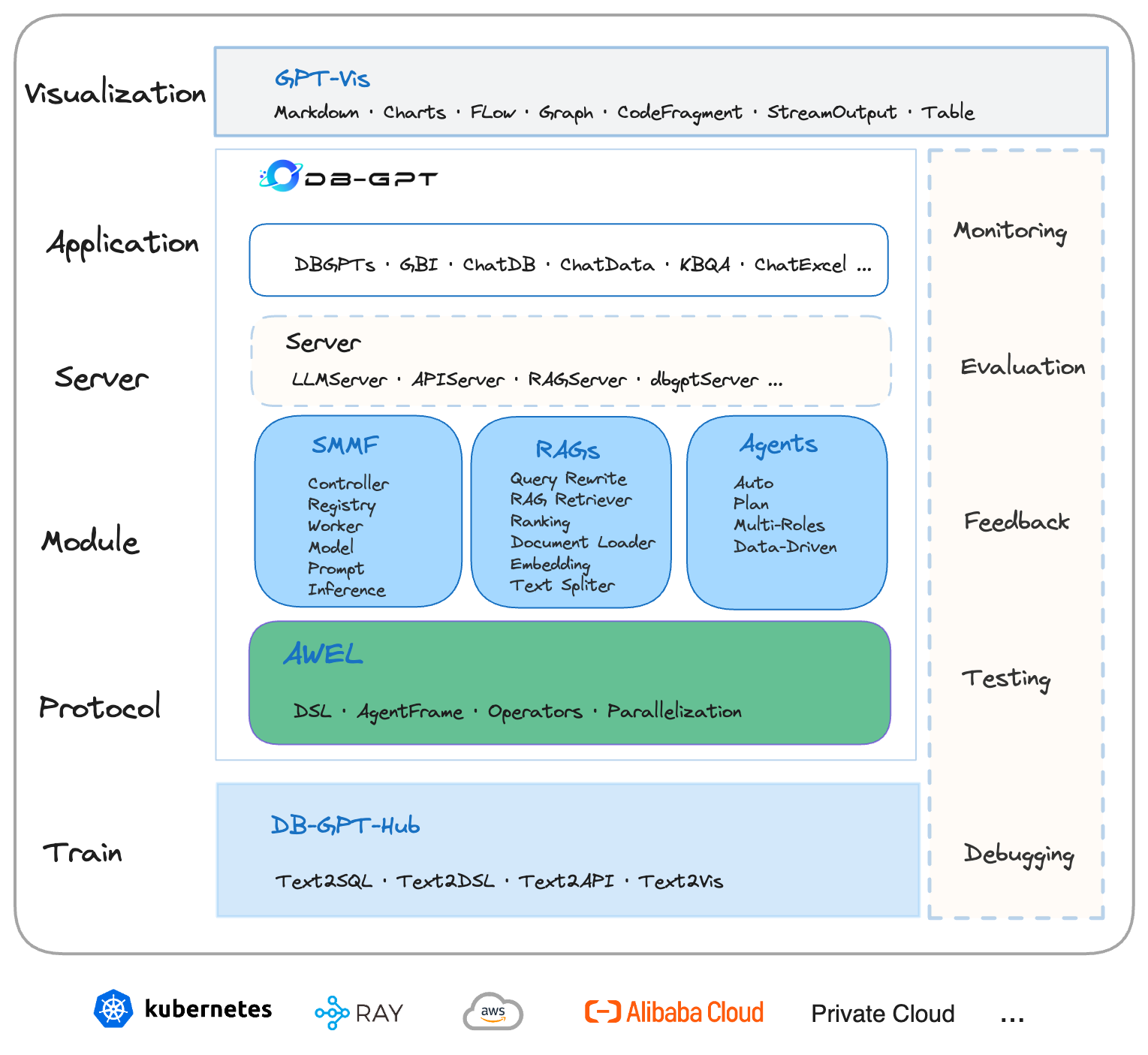
Train(训练层): DB-GPT-Hub 旨在增强文本转 SQL 中的模型性能 项目地址
Protocol(协议层): 通过标准协议编排自己智能的工作流。
Module(模块层):
- SMMF 服务化多模型管理框架,云原生的那一套微服务的架构,应用服务通过微服务的方式去服务,在大模型领域中,把模型进行了服务化,调用模型就相当于调用服务一样,通过服务的方式使用各种各样的模型。
- RAGS 有了大模型这个超级大佬,那我们去管理私域知识,通过私域知识构建我们 Agents 工作时上下文。
- Agents 具体要做一些事情,通过这个 Agents 去实现的。
Server(服务层): 真正和客户端去交互,去工作的,去连接的接口层。
Application(应用层): 像 ChatDB、ChatData 等都是基于 Server 层进行实现的。
Visualization(可视层): 实际生产环境中可以服用,让大模型通过标准协议进行反馈。
提供整体效果的微调。
关键特性
一、私域问答&数据处理&RAG(Retrieval-Augmented Generation)
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
二、多数据源&GBI(Generative Business Intelligence)
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
三、多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。
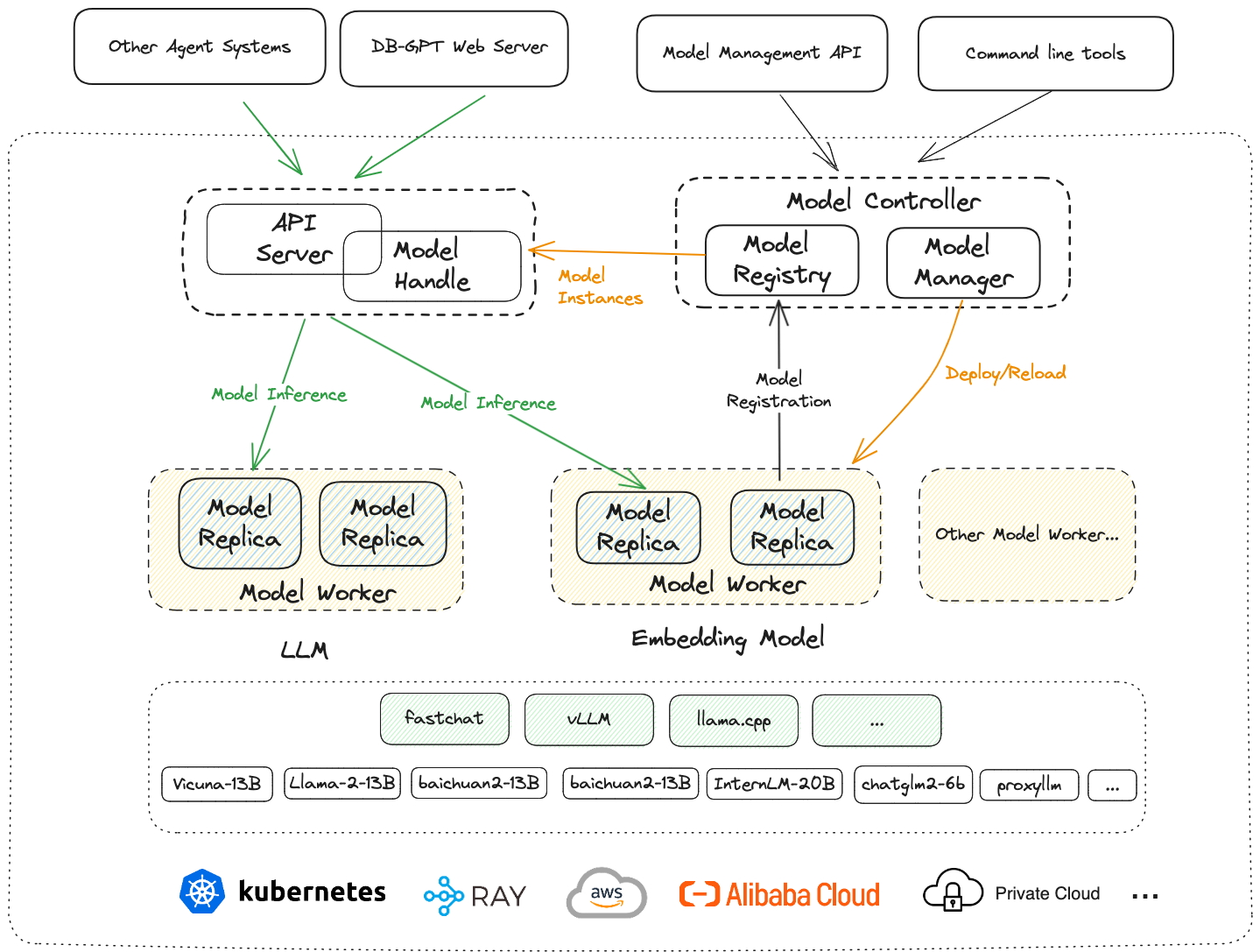
四、自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。
什么是 CVP 架构
- C 是以 ChatGPT 为代表的大语言模型,现在表现最好的通用 LLM 是 GPT-4,两者都是属于 OpenAI 公司的产品,但是 GPT-4 的价格是 ChatGPT-3.5 的 20 倍。本地 LLM 表现比较好的是百川智能在近期发布的
Batchuan2-13B-Chat[现在可能是glm4-9b-chat2024-07-08 16:05:39 星期一]。我们建议,在知识库问答场景,如果不涉及隐私数据,可调用 ChatGPT-3.5,涉及隐私数据时,可基于DB-GPT本地部署Baichuan2-13B-Chat来做推理。 - V 是(Vector Database)向量数据库的缩写。区别于传统的数据库,向量数据库专门存储和管理向量数据,通常采用基于向量索引的存储方式,将向量数据映射到高维空间中,并在这个空间中构建索引结构,以支持高效的相似度查询。
- P 即 Prompt,但是这里的 Prompt 不单指 LLM 的提示词,更广义地表示提示工程和产品交互部分。Prompt 包括 zero-shot、one-shot 跟 few-shot 三类,一般情况下,few-shot 的效果要明显好于前两者。针对于 P,实质上需要它的逻辑推理能力,而不是它的知识储量。
为什么要用 CVP 架构
企业借助 LLM 能力提升生产力是目前 LLM 落地的一个重要方向。围绕这个方向的探索大致分为两大流派:传统流派将垂域内容、私域内容补充到数据集里,微调甚至重训 LLM,希望模型具有端到端的能力,即单模型架;新兴流派则引入了向量数据库为 LLM 提供长期记忆,采用通用 LLM 集成领域知识库的方案来提供服务,即 CVP 架构。
相比于单模型架构,CVP 架构在可扩展性、实时性和成本三个维度都有明显优势。
- 传统流派需要将垂域、私域内容更新到模型参数中,需要微调 LLM,需要花费大量的计算资源,同时需要专业的同学去完成这个工作,但是结果不稳定,有可能花费数周都无法微调出一个令人满意的模型,甚至是负优化。这个过程也被形象地比喻为“炼丹”!
- 新兴流派引入了向量库位 LLM 补充一个外部记忆体,存储垂域、私域的知识。不需要微调 LLM,只需要将实时知识添加到向量库中即可完成知识的更新,而非微调 LLM。
在 AI 问答助手产品的落地中发现,即使 CVP 架构依赖于本地部署的 Baichuan2-13B-Chat,七问答效果也可以显著超过 GPT-4 的单模型架构。当然这套架构的和核心是垂域、私域知识库的构建,知识库的质量直接决定了 CVP 架构的问答效果。
假如连续问大模型五六个问题,五六个问题之前的问题,它已经不记得了,是大模型只有一个短期记忆,这跟它允许的最大上下文 token 值是分不开的[这也是后续月之暗面、智谱清言相继发布超长上下文大模型的原因 2024-07-08 16:36:54 星期一]。
AI 问答助手流程
Question + Prompt + ChunkN(top_k) => LLM
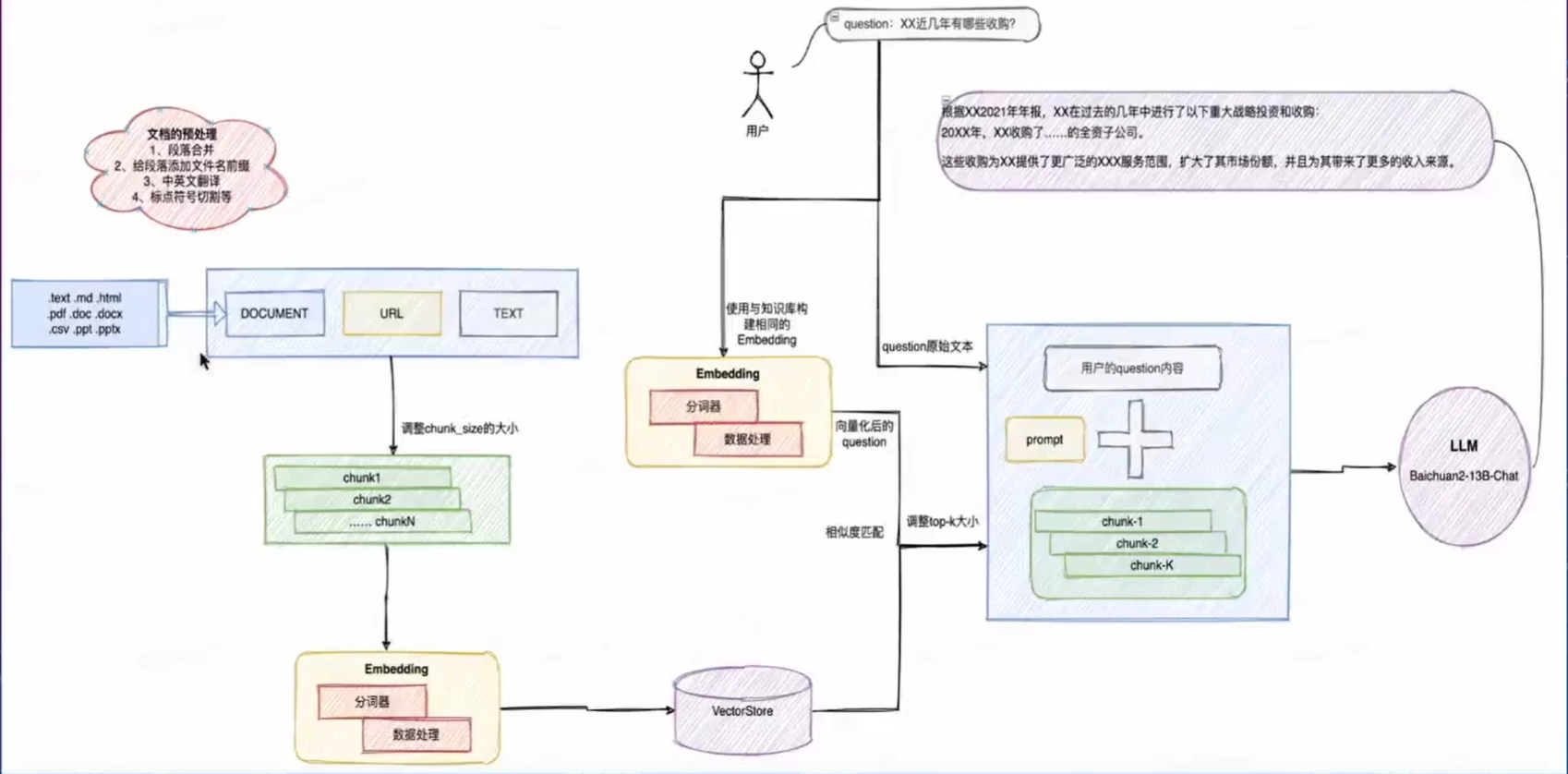
PS: 以上流程需要做到拆到每一部分来看,为后续体系化地做调优做准备。
文档预处理阶段
即在文档上传知识库之前做的文档预处理工作。预处理工作的准则是,能系统化的步骤则系统化,不能系统化的步骤按照 SOP 人工处理之后,需要达到入知识库的标准。不满足标准的文档不允许入库。文档预处理阶段核心要考量的点:
- 文档语言统一:在构建知识库时发现,有的文档是中英结合的,例如,同一行中左边是中文(简体)、右边是英文,这种需要删掉英文,只保留中文(简体);如果是中文(繁体),则需要转成中文(简体);如果文档是英文,则需要转成中文(简体)。
- 文档格式统一:我们测试发现,相比于
.pdf格式,.docx格式的效果更好,推荐使用该格式,需要将.pdf格式转换为.docx格式。 - 文档命名规整:文档名应控制在
10字左右,使用简洁明了的词语活短语来命名文档,避免使用无意义的数字、符号或缩写。
【good case】20221220-中央经济工作会议解读
【bad case】20221220-英大证券-英大证券宏观评论(2022年第36期总第120期):2022年中央经济工作会议解读,基建投资大概率是2023年扩大内需的助理,1-4季度GDP当季同比大概率总体上行 - 文档内容规整:
- 一/二级标题规整:标题名应控制在
5字左右且需要有含义,使用简洁明了的词语或短语来命名文档,避免使用无意义的数字、符号或者缩写。

- 段落合并:合并段落的阈值需要根据文档切割的
chunk_size大小来调整[默认 100 字]。文档、标题的重命名都是服务于段落内容标记。如果一个知识库非常大的话,包含上千个文档,就会非常容易出现召回准确性下降的问题。
- 一/二级标题规整:标题名应控制在
- 段落打标加权:将合并后的新段落打标加权,打标的格式为
文档名 + 一级标题 + 二级标题。
文档的切割阶段
chunk_size参数控制每个切割块的字符长度,简单的调整可直接调整该参数的大小,取决于chunk_size能否抓到主要中心含义,如果chunk_size太小,会把一个完整的东西给切成了好几段,导致了他每一个chunk的内容都不全,如果chunk_size太大,会把两到三个段落,同时切分到同一个chunk当中,导致一些细节问题处理不好。
此外还可调整文档切割的方法,目前使用的是zh_core_web_sm。
EMBEDDING阶段
评估指标:一般采用 Top5 的召回准确率和 Top10 的召回准确率。
目前对于中文文档而言,bge-large-zh(智源开源)[目前是使用的是text2vec 2024-07-08 17:33:49 星期一] Embedding引擎效果是最好的。
Top 召回准确率:TopN 条 chunk 包含了答案和问题数/总的问题数。
向量库
向量库对比:

选择建议:探索性应用可选择Chroma,使用方便,极为轻量;企业落地应用选择Milvus,分布式架构,可扩展性强,社区活跃。
召回Top_k
K 的选择:文旦那个内容足够丰富时(文档>10),调大该值,文档内容比较少时,调小该值。
PS: K * chunk_size不得超过 LLM 允许的最大输入 tokens。还需要考虑 Prompt、Question 等因素的影响。
Prompt
知识库问答场景下的prompt工程相对比较简单,不同知识库固化一个当前知识库通用的prompt。
LLM
对于中文知识库问答来说,目前表现最好的开源 LLM 是Baichuan2-13B-Chat[现在应该是 glm-4-9b-chat 2024-07-08 17:50:18 星期一],上面提到,在 CVP 架构中,我们不需要太强的 LLM,就可以有很好的效果,以Baichuan2-13B-Chat作为本地 LLM,在 AI 文档助手场景中,可以获得85%以上的准确率。
知识库构建理论
在构建 AI 问答知识库时,最开始我们将所有的文档都放到了一个知识库中,包括宏观政策、经济和行业调研分析的文档,但是发现效果并不好,研究badcase发现,用户问宏观政策环境问题时,会召回财报中讲述宏观政策环境对企业经营的影响。用户问某个企业的经营状况时,又会召回很多宏观政策经济的内容,知识互相糅杂,导致不准确。后续拆成3个知识库,效果有了明显改善,研究 badcase 发现,用户对于宏观政策库、经济库的问题,往往需要结合宏观政策和经济材料才能完美回答,研究材料发现确实如此,宏观政策中夹带经济,经济中夹带宏观政策,所以最后建了两个库:宏观库和行业库。效果达到了最优,问答准确率达到了92%。
在尝试划分知识库的时候,发现知识库构建遇到的问题,答案基本都能在数仓建模中找到,上述案例其实是数仓建模分主题域的理论:域内高内聚,域间低耦合。推广到知识库的分知识库理论为:库内高内聚,库间低耦合。即划分到一个知识库里的文档以及所有的知识,要尽量保证这所有的文档内容都是有比较强的相似度的,不同的库与库之间尽量不要有重叠或者相似文档的部分。
效果对比
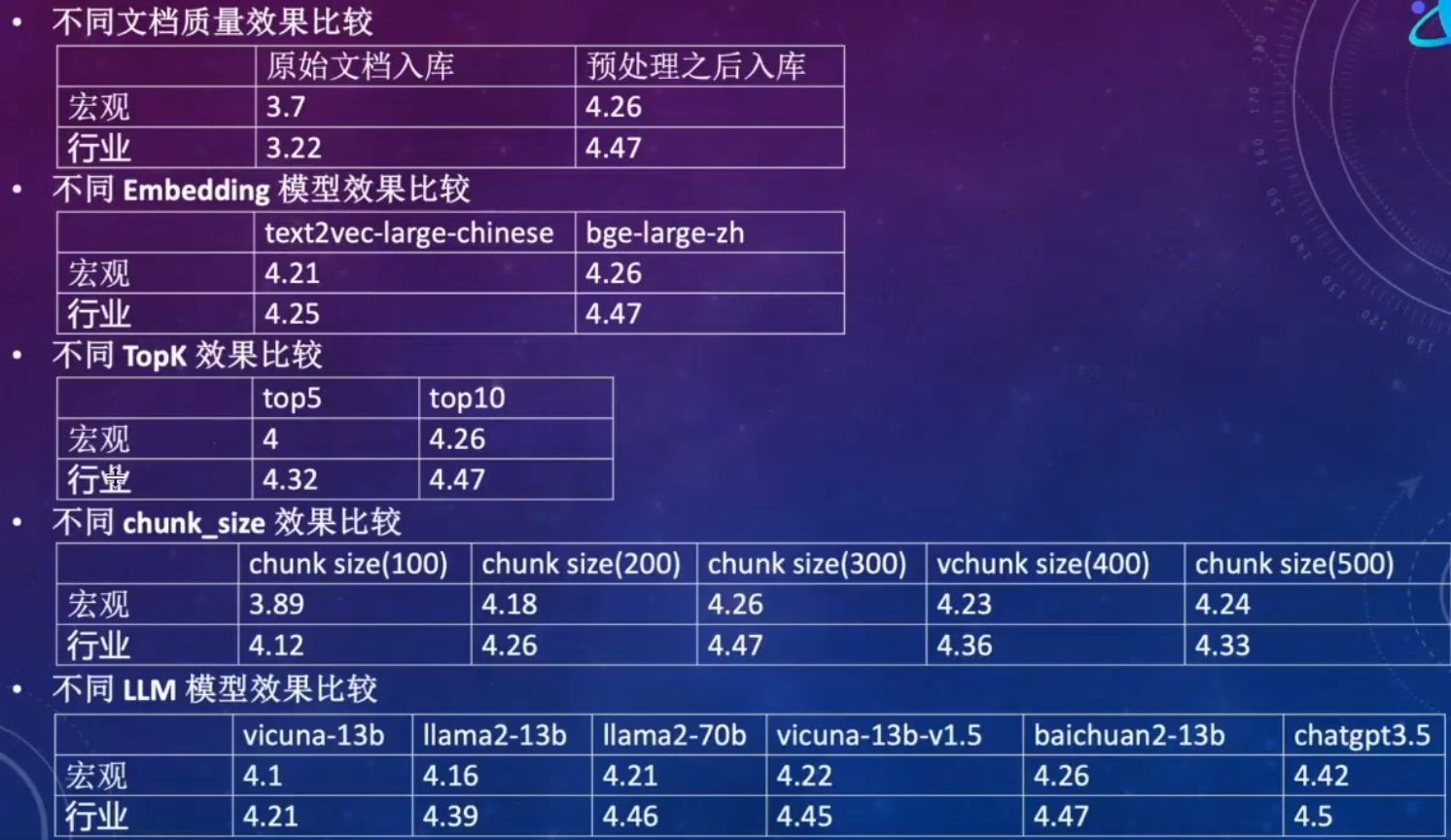
评分标准
针对宏观知识库和行业知识库选择80个问题作为测试集,测试评分标准如下:
PS: 人工打分,比较主观,需要专业人员参与。

未来的挑战与思路
- 超大文档集下,三级标题打标的必要性,过量的打标内容对真实信息熵的扰乱程度。
对于超大文档集,是需要三级标题,甚至四级标题进行打标,但是打标的质量需要特别关注:打标应言简意赅,精简打标的内容,如果无法再打标的内容上间精简,则需要相应地增大chunk_size的大小,以此控制打标部分的占比不应超过 chunk 的 10%,放在打的表覆盖真实的信息内容。 - 文档中的表格和图片上的指标识别
采用ORC的方式来将文档中的图片抽离出来,单独处理。经过测试常规ORC识别还达不到落地应用的效果,所以我们要求在图片加必要的文字说明,特别是对于包含指标值的图片,需要人工将其解决成文字。 - 推理框架升级,推理提速
目前DB-GPT使用的是FastChat作为推理框架,推理速度和并发均有很大的提升空间,在Q4可以将其融合到DB-GPT工程里。

