4.10 SpringCloud微服务技术栈
1. SpringCloud介绍
1.1 微服务架构
微服务架构的提出者:马丁福勒
http://martinfowler.com/articles/microservices.html
简而言之,微服务架构样式[1]是一种将单个应用程序开发为一组小服务的方法,每个小服务都在自己的进程中运行并与轻量级机制(通常是HTTP资源API)进行通信。这些服务围绕业务功能构建,并且可以由全自动部署机制独立部署。这些服务的集中管理几乎没有,它可以用不同的编程语言编写并使用不同的数据存储技术。
- 微服务架构只是一个样式,一个风格(部署标准,不是说非要遵循,就像restful风格一样)。
- 讲一个完整的项目,拆分成多个模块分别开发(可以根据功能拆,也可以根据其它)。
- 每一个模块都是单独的运行在自己的容器中。
- 每一个模块都是需要相互通讯的。Http,RPC,MQ。
- 每一个模块之间是没有依赖关系的,单独的部署。
- 可以使用多种语言去开发不同的模块。
- 使用MySQL数据库,Redis,ES去存储数据,也可以使用多个MySQL数据库。
总结:讲复杂臃肿的单体应用进行细粒度的划分,每个拆分出来的服务各自打包部署。
马丁福勒提出的这些只是一种微服务的设想,或者说是能力的介绍,具体的落地实现技术我们讲在下面学到。
1.2 SpringCloud介绍
可千万不要说SpringCloud是微服务啊,SpringCloud是微服务架构落地的一套技术栈。
SpringCloud中的大多数技术都是基于Netflix公司的技术进行二次研发(即包装再研发)。
如果你遇到什么问题,可以去SpringCloud中文社区网站搜索:http://springcloud.cn/
SpringCloud的中文网:http://springcloud.cc/,其实就是中文官网,我们在上面可以看到SpringCloud技术栈中有许多技术,但是我们最关心的是八大技术。
八大技术点:
- Eureka-服务的注册与发现
- Robbin-服务之间的负载均衡
- Feign-服务之间的通讯,以前用的是resttemplate
- Hystrix-服务的线程隔离以及断路器,可以实现服务降级
- Zuul-服务网关
- Stream-实现MQ的使用(我们以前也用过RabbitMQ,但是这里这个会更加简单)
- Config-动态配置,可以实现配置的动态化
- 8.Sleyth-服务追踪,可以看到哪个服务调用了哪个服务,用了多长时间等。
这里要百度搜索“resttemplate和Feign”查看其区别
https://www.jianshu.com/p/b64451435126
https://www.cnblogs.com/lushichao/p/12796408.html
深入学习HttpClient、RestTemplate和Feign的区别及相关知识
2. 服务的注册与发现-Eureka【重点】
2.1 引言
Eureka就是帮助我们维护所有服务的信息,以便服务之间的相互调用。

2.2 Eureka的快速入门
2.2.1 创建父工程
先创建一个Spring工程,gav坐标如下,然后什么依赖也不要导入;创建好后,先在pom.xml文件中引入SpringCloud的依赖,并修改版本为最新版本。如何查找这个依赖,在浏览器输入spring.io进入spring官网,点击projects中的springcloud,然后下翻可以看到SpringBoot和SpringCloud的对应版本,这里说明SpringCloud是依赖在SpringBoot的基础之上的,再下面有这个依赖声明。这里需要说明一下,dependencyManagement是控制依赖的版本,不导入依赖。这里加了之后,后面的springcloud就不需要声明版本了,都用最新的。这里是父工程,不需要其它依赖和插件,因此删除;此外由于是父工程,添加<packaging>pom</packaging>;再把新建项目中乌七八糟的文件删除了。留下的内容如下图。
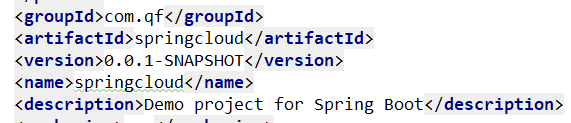
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.5.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.qf</groupId> <artifactId>springcloud</artifactId> <version>0.0.1-SNAPSHOT</version> <name>springcloud</name> <description>Demo project for Spring Boot</description> <packaging>pom</packaging> <properties> <java.version>1.8</java.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR8</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> </project>



2.2.2 创建EurekaServer
上面是创建父工程,并且在父工程中指定SpringCloud的版本,并且将packaging修改为pom。现在创建EurekaServer。在官网如何找到Eureka??先找到Netflix,因为Eureka输入Netflix,找到Learn,可以看到最新版本是2.2.5,然后点击Reference Doc打开文档。首先我们准备的是EurekaServer,因此Client就不看了。其实我们这里要清楚一件事,Eureka其实就是一个单独的SpringBoot工程。因此我要创建一个SpringBoot,并且把依赖引入进来。在父工程上右键新建一个Module,这里是创建一个Maven工程(为什么不是spring工程??),名称叫01-eureka。创建好后,我们这里的01-eureka工程也是SpringBoot工程,因为它继承了SpringCloud工程,而SpringCloud工程的父工程是SpringBoot。下面我们将SpringBoot工程需要的内容准备好。添加web依赖,添加启动类。这样一个SpringBoot工程就创建好了,是从Maven工程改过来的。下面再把Eureka的依赖加过来。这里不需要添加版本号,因为父工程中已经声明过了。即父工程中的DependencyManager。接下来需要在启动类上加一个注解@EnableEurekaServer即可;再接下来呢?需要什么配置文件??
![]()

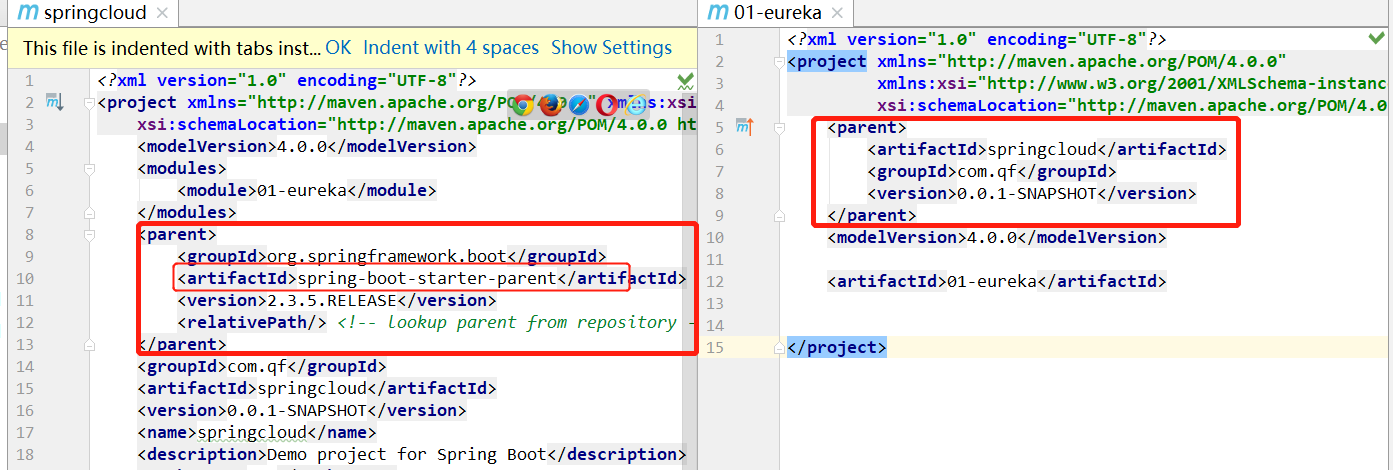

添加eureka依赖
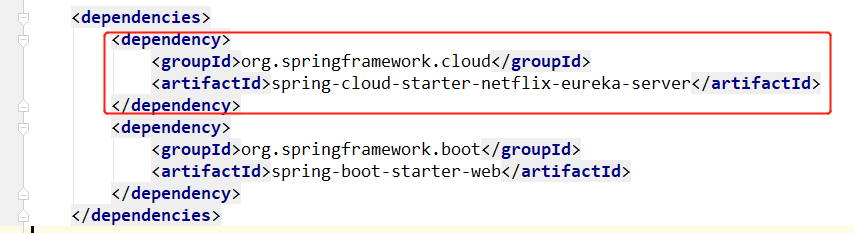
下面做什么呢?在启动类上加一个注解即可。
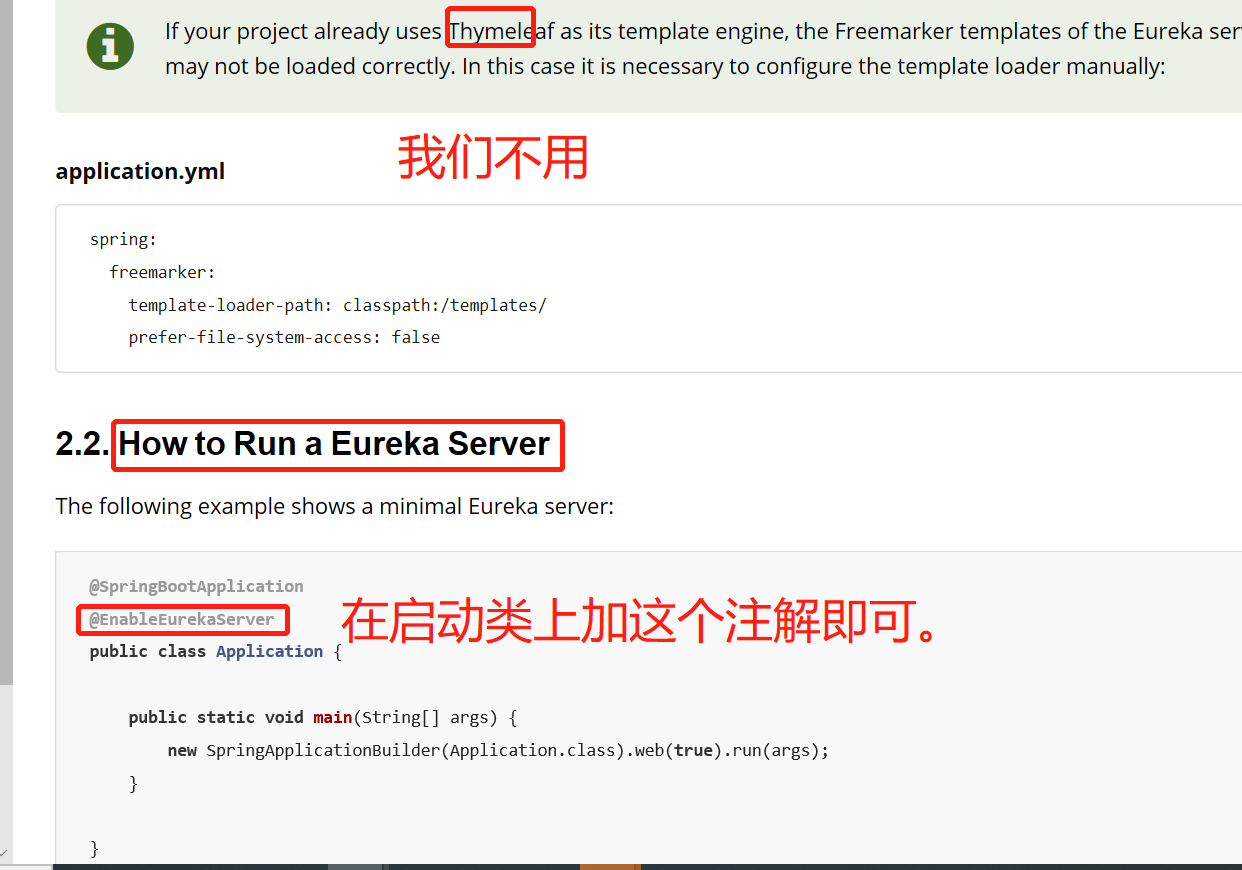

下面就是配置文件,写好之后就可以运行起来了。
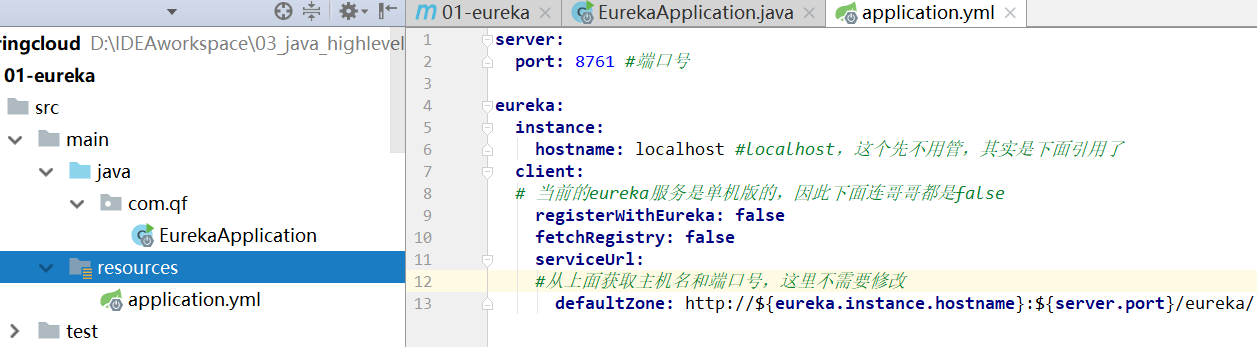
测试界面:
创建EurekaServer总结:
1.创建一个SpringBoot父工程,并且在父工程中指定SpringCloud的版本,并且将packaging修改为pom;
2.创建eureka的sserver,创建SpringBoot工程,并且导入依赖(两个依赖web和eureka),在启动类上添加注解(enableeurekaserve),编写yml配置文件(端口号,地址,集群等)。
2.2.3 创建EurekaClient
创建EurekaClient,并将其注册到EurekaService中
1.创建Maven工程,修改为SpringBoot(其实这里就是加入了web依赖)
创建maven工程,名字是02-customer,添加web依赖变为SpringBoot工程。再创建启动类。

2.导入依赖(上面是eurekaserve的依赖,这次是eurekaclient依赖)

3.在启动类上添加注解(上面是@enableeurekaservice,这里是@enableeurekaclient)
图略
4.编写配置文件(让client可以找到刚刚编写的serve),那我们怎么找到eureka-client-service-url的配置信息呢?点击service-url进去,再次点击serviceURL,找到该字段,然后下翻找到赋值信息。


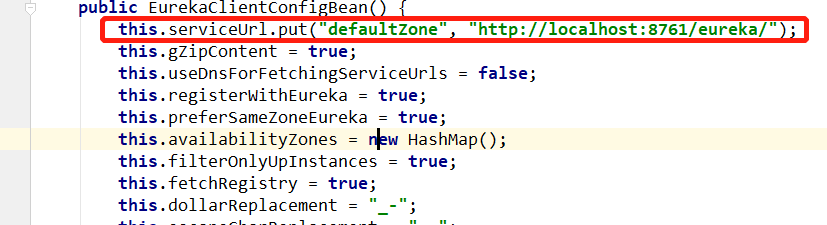
此时可以启动并测试:在eureka的地址上看到这个client已经注册进去了。

创建EurekaClient步骤总结:
创建Maven工程,修改为SpringBoot;
导入依赖;
在启动类上添加注解(其实2.x之后的版本不写这个enableeurekaclient也是可以的,但还是写上吧);
编写配置文件(指定eureka服务端地址,指定当前服务的名称)
2.2.4 测试Eureka
这里是为了测试调用服务时,是否可以在eureka中找到地址,因此这里先把搜索模块构建出来。
创建03-searchMaven工程;添加依赖,一个是web(为了修改为SpringBoot工程),一个是eureka-client;创造启动类,并添加client注解;添加配置文件(eureka的地址+服务名称),还有这里记得修改端口号,因为8080已经被占用了。然后启动并查看。



客户模块不需要知道服务的地址,只需要知道服务的名称就可以访问到,即可以从Eureka中拿到。
使用EurekaClient的对象去获取信息(通过服务名称获得信息,包括地址等)
@Autowired
private EurekaClient eurekaClient
正常RestTemplate调用即可。
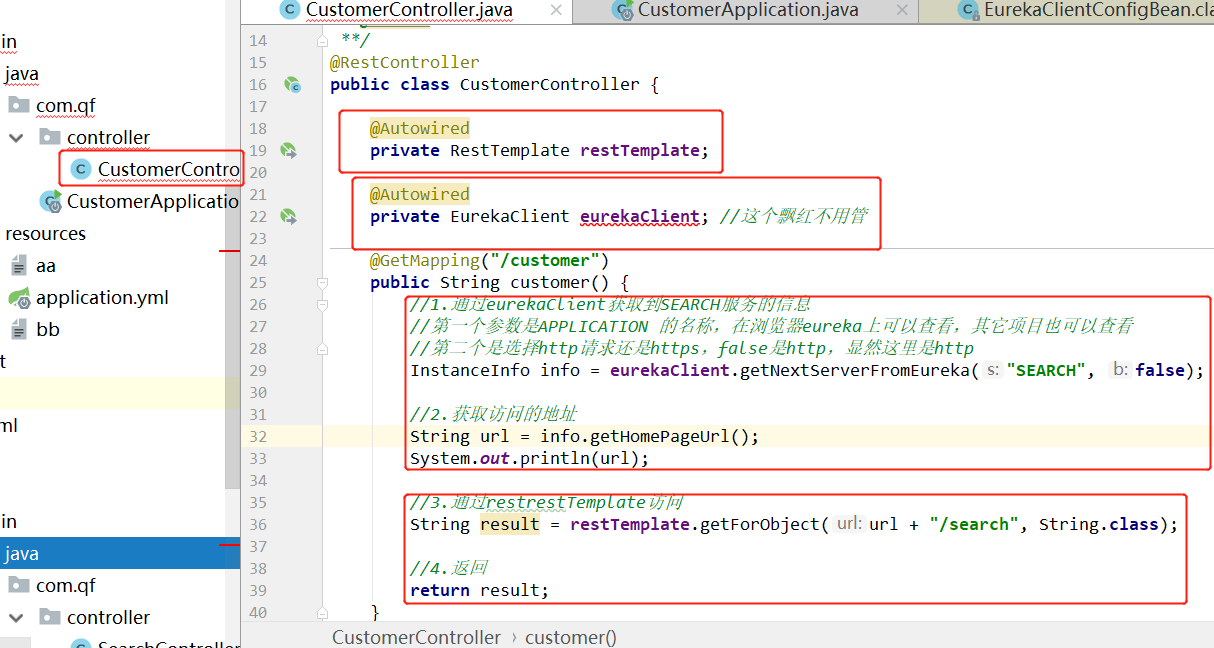
这里需要说一下,restTemplate需要手动new对象并返回,这里为了方便,就在启动类里面创建了,如下:

这里是Search模块创建的controller
package com.qf.controller; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class SearchController { @GetMapping("/search") public String search() { return "search"; } }
下面是运行结果:(此外可以在控制台看到SEARCH服务的地址,只是我显示的有点问题,不知道为什么,按道理应该是localhost:8080/)

2.3 Eureka的安全性
现在我们的Eureka只要有ip和端口号就能登录,谁都可以,不是非常安全,因此我们要加个安全校验,也就是说要登录才能访问。
在官网中可以看到:

实现Eureka认证
1、导入依赖,其实就是Spring-security的依赖。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency>
2、编写配置类,为了这个 Spring-security只是对访问eureka路径有效。即只对其进行CSRF安全认证。(创建配置类,放在config目录下)
创建配置类,加入注解@EnableWebSecurity,继承WebSecurityConfigureAdapter,重写configure方法,注意不要重写错了,然后忽略路径。

重写该方法

3、编写配置文件(指定好登录时需要的用户名和密码)

重启并测试看是否这次登录eureka是否需要用户名和密码。
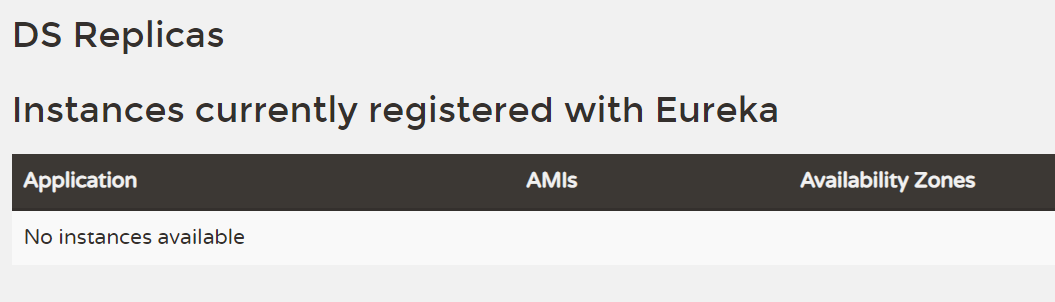
此时用用户名和密码登录后,发现没有服务,并且看其它两个注册的client中的任意一个,发现这里被拒绝,不能访问任何服务,这是自然的,你eureka登录都需要密码,注册自然也是需要的。
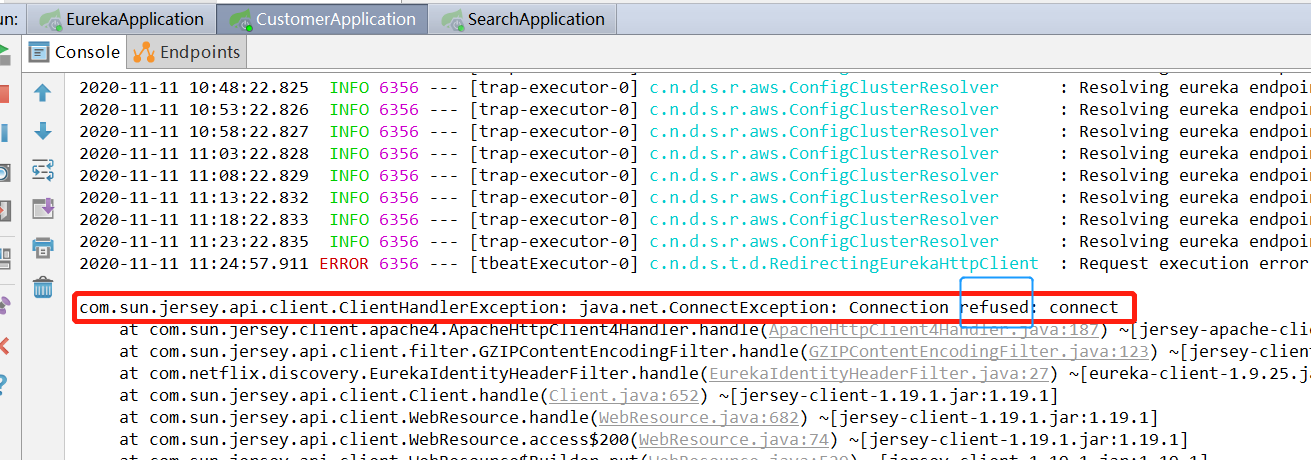
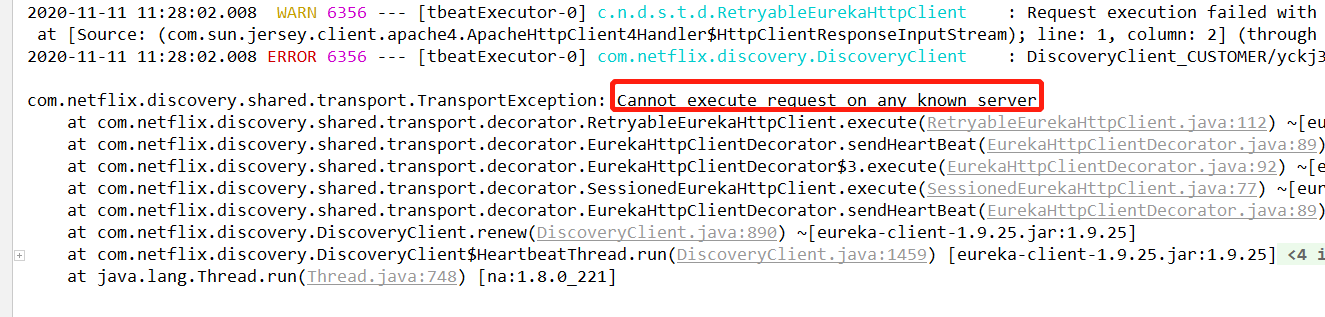
4、其它服务想注册到Eureka上需要添加用户名和密码。两个客户端都如此操作一下。

这次再次刷新,发现两个client都注册到seurity-service上面了。
2.4 Eureka的高可用
如果我的程序正在运行,突然Eureka宕机了(毕竟是一个SpringBoot工程,如果其当即,其它服务调用就找不到地址)。如果宕机会有两种情况。
- 如果调用方访问过一次被调用方了,Eureka的宕机不会影响到功能(因为访问一次后,调用方会保存被调用方的地址,就不需要走Eureka去拿地址了)。
- 如果调用方没有访问过被调用方,Eureka的宕机就会造成当前功能不可用(因为此时自己没有地址,找Eureka,它宕机了)。
针对上面的两种情况,都可以测试下。测试图略。我的第二种情况验证失败,因为要清理缓存,但是我不会。
想要达到高可用,其实非常简单。第一就是准备堕胎Eureka服务(其实就是再创建一个模块,用于Eureka服务);第二是每个Client都注册到所有Eureka服务上(这里其实就是再次注册到新的上面即可);第三是两台Eureka服务相互通信,保存数据一致。
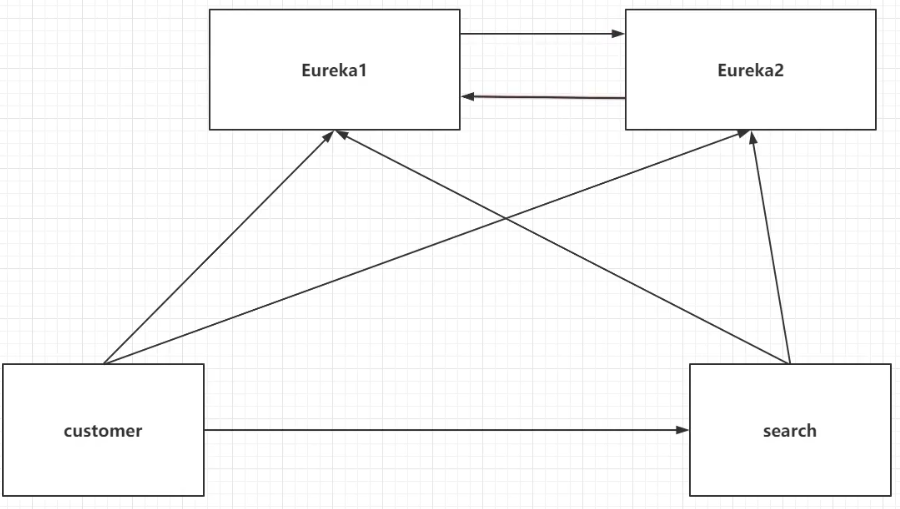
搭建Eureka高可用步骤:
1、准备多台Eureka,这里就不再创建,直接复制,复制步骤如下
右键01-eureka,找到show in Explore,打开后,复制一份并修改名字为04-eureka

打开04-eureka,删除两个文件。

打开pom文件,将aitifactId修改为04-eureka
此时打开IDEA,里面就自动有了04-eureka,下面在父工程的pom文件中将该子模块添加进来。

下面打开04-eureka的配置文件,修改端口号为8762,因为8761已经被占用了,是01-eureka模块的。
然后启动这两个eureka服务,先保证浏览器可以访问到。
2、让服务注册到多台Eureka,这一步非常简单,只需要修改下配置文件即可。在02-customer和03-search中都这么操作。然后启动这两个client,看看两台eureka中是否有这两个client的注册。

此时我们发现一台Eureka上有信息,另一台上没有,这是为什么呢?因为在注册时,他们会选择一台进行注册,而另一台就不注册了。要想两台都注册,就需要靠第三步了。
3、让多台Eureka之间相互通讯(这里的修改也是非常简单的,只需要在两台服务上修改配置文件即可)

重启,即可测试,并看到两台服务上都注册了客户端。这里看着UNKNOWN不爽,可以修改应用名称(01和04的名称这里要一样,不知道不一样是不是可以)


搭建Eureka高可用步骤总结
1、准备堕胎Eureka:次啊用复制的方式,删除iml和target文件,并且修改pom.xml中的项目名称,再给父工程添加一个module。
2、让服务注册到堕胎Eureka(其实就是在每个客户端修改pom文件,在defaultZone后面用逗号隔开多台服务地址)。如果只到这里,会发现只有一个有信息,其它没有。
3、让多台Eureka之间相互通讯(修改每个服务端pom文件,)两个地方该为true,defaultZone改为另外一台Eureka的地址。
2.5 Eureka的细节
1、EurekaClient启动时,会将自己的信息注册到Eurekaserver上,EurekaServer就会存储上EurekaClient的注册信息。
2、当EurekaClient调用服务时,本地没有注册信息的缓存时,去EurekaService中去获取注册信息。
3、EurekaClient会通过心跳的方式和REurekaServer进行连接。(默认30sEurekaClient会发送一次心跳请求,告诉服务端,该Client还活着,如果查过了90s还没有发送心跳inxi的话,EurekaServer就认为你宕机了,将当前EurekaClient从注册信息表中移除)。这个时间是可以修改的,是在客户端修改的,但是一般我们不修改。
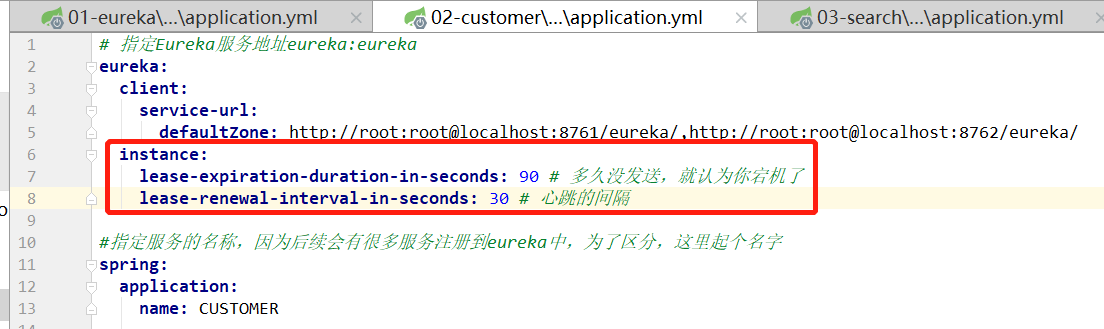
4、EurekaClient会每隔30s去EurekaServer中去更新本地的注册表(其实就是第一次访问后缓存在本地的信息,保持信息一致),这个时间也是可以改的,但我们一般不改。
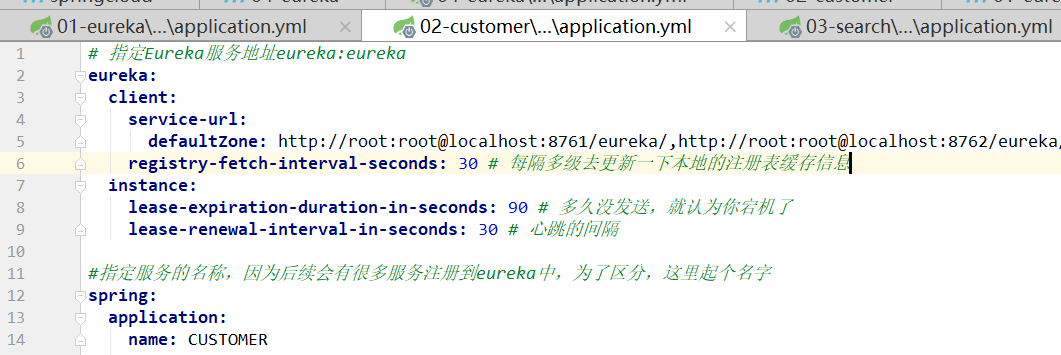
5、Eureka的自我保护机制(默认是开启的,我们不用管,就是浏览器端的那一行红字),统计15分支内,如果一个服务的心跳发送比例低于85%,EurekaServer就会开启自我保护机制。
- 不会从EurekaServer中移除长时间没有收到心跳的服务(即使你宕机了,Eureka依然认为你活着)。
- EurekaServer还是可以正常提供服务的。
- 网络比较稳定时,EurekaServer才会开始将自己的信息被其他节点同步过去。(这是什么意思??)

6、CAP定理,C:一致性,A:可用性,P:分区容错性,这三个特性在分布式环境下,只能满足2个,日且分区容错性在分布式环境下,时必须要满足的,只能在AC之间进行权衡。
如果选择CP,保证了一致性,可能会造成你系统在一定时间内时不可用的,如果你同步数据的时间比较长,造成的损失大。
Eureka就是一个AP的效果,高可用的集群,Eureka集群时务中心,Eureka即便宕机几个也不会影响系统的使用,不需要重新的去推举一个master,也会导致一定时间内数据时不一致的(需要给他时间保持数据同步)。
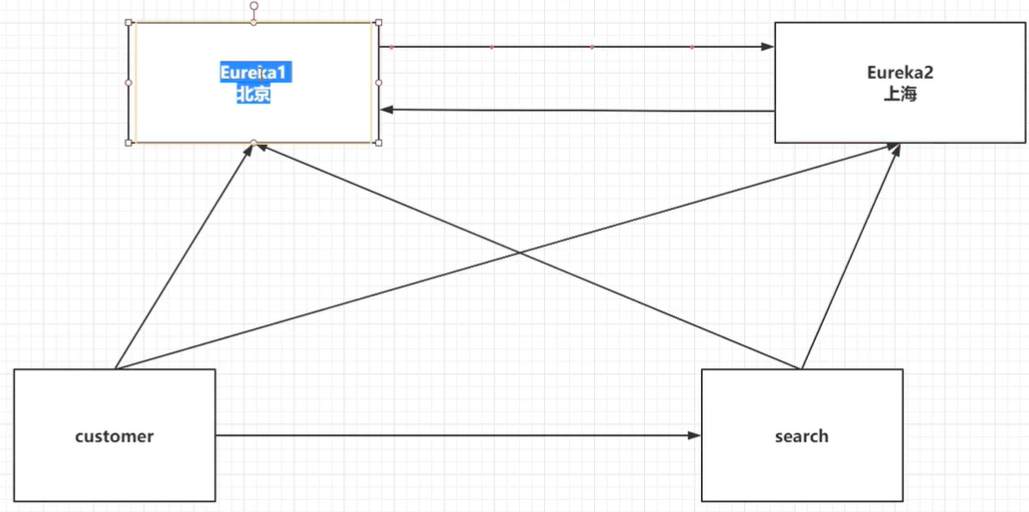
分布式中,比如我们一台eureka是在北京,一台是在上海,那么我们是无法解决网络卡顿问题的,所以就一定要保证分区容错性。
3. 服务间的负载均衡-Robbin
3.1 引言
Robbin是帮助我们实现服务和服务负载均衡(如果搜索模块压力过大,搭建了集群,即多个模块,这些模块都注册到了Eureka上,当Customer想要访问搜索模块的时候该访问谁呢??总要有个选择的机制,这就是Robbin),Robbin输入客户端负载均衡。
客户端负载均衡:customer客户模块,将2个Search模块信息全部拉取到本地的缓存(在第一次访问之后,就把从Eureka获得的信息缓存到了本地),在customer中自己做一个负载均衡的策略(决定选谁的方式),选中某一个服务。
服务端负载均衡:在注册中心,直接根据你指定的负载均衡策略,帮你选中一个指定的服务信息,并返回。(我猜想这种注册中心的话,是不会把信息缓存到本地的,每次都要到注册中心来找地址)。Dubbo就是服务端负载均衡。

这里你想,由于Robbin是客户端负载均衡,即只需要在客户端(CUSTOMER)模块添加依赖,注解,修改访问方式就可。
3.2 Robbin的快速入门
1、启动两个search模块。这里非常简单,不再像以前一样复制。具体操作是:打开Edit Configurations...,


2、在customer中导入robbin依赖,这里依然不需要引入版本号。(在官网中查看还是在netfli中,因为他属于Eureka中的内容)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-ribbon</artifactId> </dependency>

3、配置整合RestTemplate和Robbin,因为RestTemplate是模块与模块之间访问的,而Robbin是决定访问方式的,因此要相互整合一下。非常简单,在注入RestTemplate的类上加上@LoadBalanced注解即可。
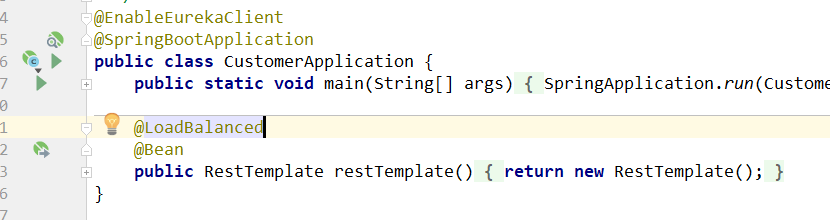
4、在customer中访问search,这里就更加简单了,在没有添加robbin时,用RestTemplate去访问另一个模块,首先要从注入的Eureka客户端对象中得到服务信息,再从服务信息对象中得到服务地址,然后再访问(配合服务地址和/search)。但是在加入Robbin后,可以直接用restTemplate访问,即省除了上面的两步。
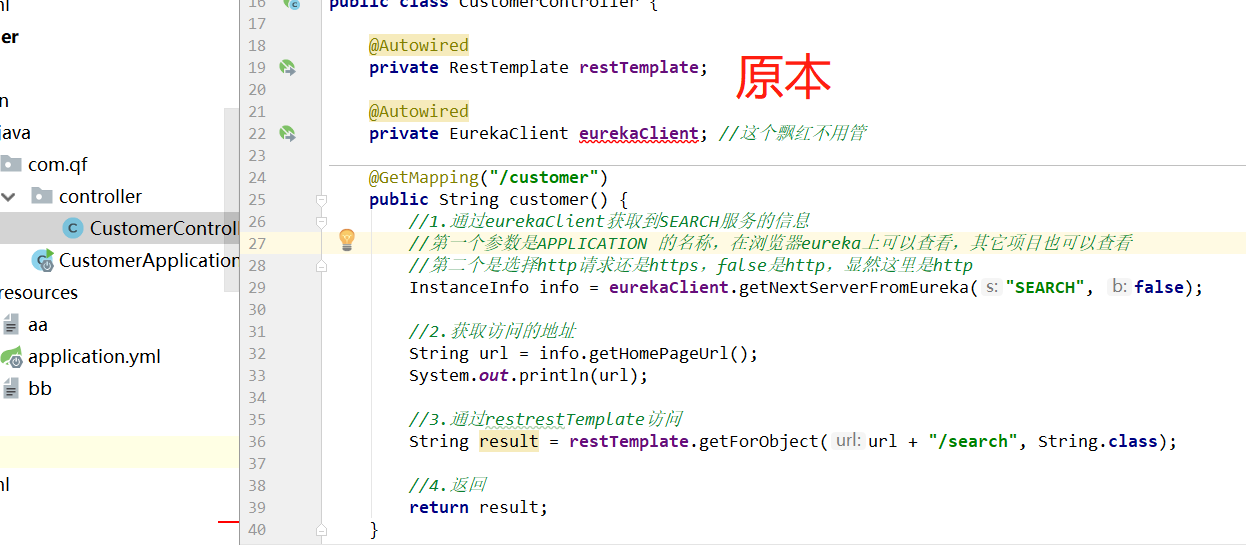

现在可以测试一下,是否可以访问,以及访问的时候是不是轮询状态(Robbin默认的访问策略),即访问到不同的search模块端口号。此时只需要重启客户端customer即可,因为只是修改了它。

3.3 Robbin配置负载均衡策略
负载均衡策略:在下方的注解配置的IRule接口(是负载均衡策略总接口)按ctrl+alt+B可以查看实现类
- RoundRobbinRule:轮询策略(默认,无需配置)
- RandomRule:随机策略
- WeightedResponseTimeRule:默认会采用轮询的策略(统计每个服务相应的时间),后续会根据服务的相应时间,自动给你分配权重(时间长的少分配)。
- BestAvailableRule:根据被调用方并发数量最小的去分配(你这个服务器请求最少,我就把请求发送给你)。
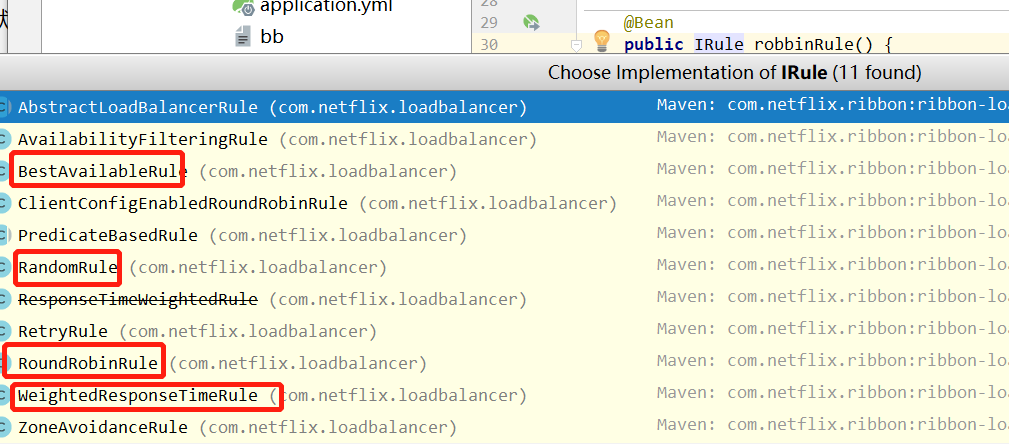
配置轮询策略有两种方式:注解和配置文件(推荐)
采用注解的形式(这个就像RestTemplate一样,在Spring容器中注入一个负载均衡的对象,然后Robbin就会根据这个对象来决定访问)
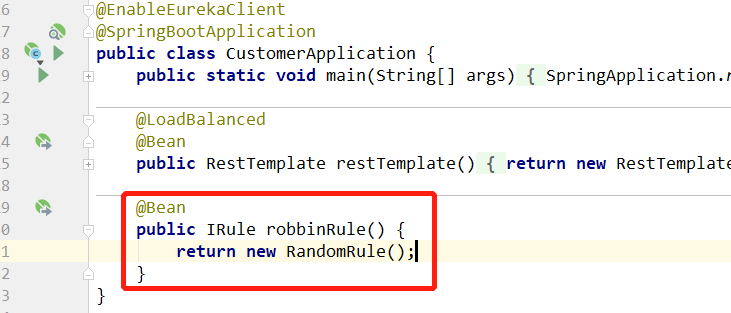
此时再次访问就是随机的(只需要重启customer客户端即可,因为只修改它)
配置文件去指定负载均衡的策略(更推荐,为什么推荐不清楚),此时要把上面Spring容器中注入的策略注释掉。


此时去测,依然是轮询的方式,因为权重方式漠然开始是轮询。
其实无论是权重还是并发数,这两种我们测的时候都很难看到区别。因为我们就是本地调用,基本上没有时间等差别。
4. 服务间的调用-Feign【重点】
4.1 引言
Feign可以帮助我们实现面向接口编程,就直接调用其他的服务,简化开发。(直接用@autowired,简化了restTemplate访问(地址+返回值的方式),其实就是Fein封装了restTemplate,这就回到了以前Spring项目时的情况,更加方便)
我觉得要想好好理解Feign的优势和作用,首先要经常用restTemplate调用服务,再常用Feign调用,这样就能理解两者的区别了。就这道这里为什么要用Feign代替restTemplate了。可以搜索Feign与restTemplate的区别。另外这个博客要看。
https://www.jianshu.com/p/b64451435126
4.2 Feign的快速入门
使用Feign非常非常简单,当然使用restTemplate也非常简单。我们先回顾下restTemplate的使用。
如果除下测试,其实就两步:第一步,在Spring容器中通过注解bean的方式注入;第二步:拿到该实例,即可使用(如获得,服务信息,得到url,访问)。
Feign的使用步骤除下测试,是三步:第一步:导入依赖,第二步:添加一个注解EnableFeignClients(和Eureka一样,在启动类上添加);第三步:创建一个接口,并且和Search模块做映射;当然你也可以说还有第四步,就是使用;第五步是测试。
1、导入Feign的依赖,版本号依然不用(同样,这里是在customer模块添加,因为其访问了search模块),在官网怎么找,在SoringCloud的最后一个组件中,是OpenFeign(以前是Feign,在2.x之后变为OpenFeign)

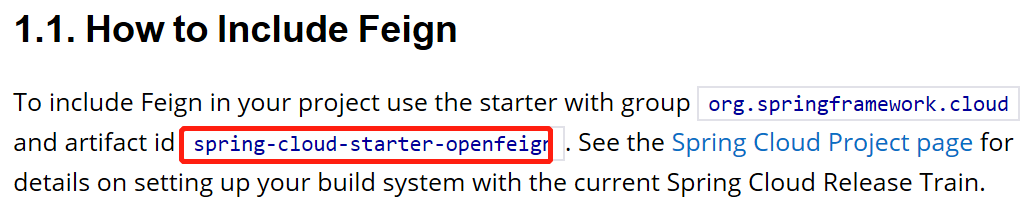
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
2、添加一个注解(和Eureka一样,在启动类上添加)
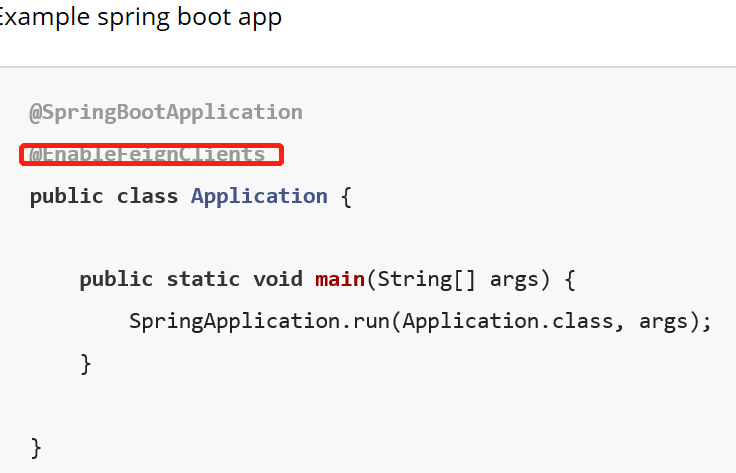
3、创建一个接口,并且和Search模块做映射。

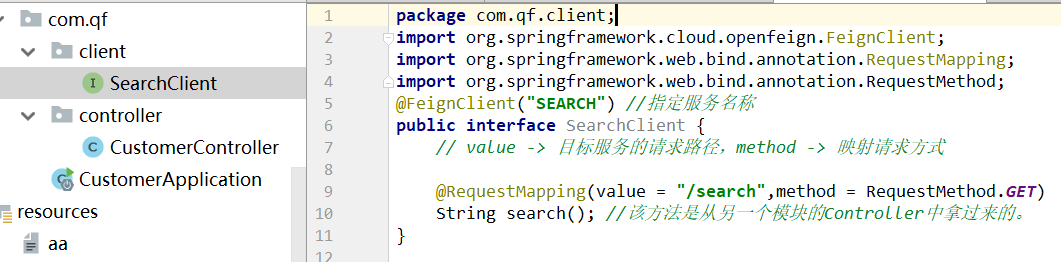
既然Feign和RestTemplate实现的作用一致,那么之前我们要给RestTemplate整合Eureka和Robbin,这里自然也要给Feign整合Eureka和Robbin。之前只是在Spring容器注入RestTemplate实例的Bean上加上@LoadBalanced注解(地址自己写的)算是整合了Robbin,这里是在接口上用@FeignClient指定服务名称,这个算是整合了Eureka,那Robbin不整合吗?可能是不需要(就是不需要,想要修改,就直接修改配置文件负载均衡策略就可)。
4、测试使用(其实就是customer模块的controller中注入接口即可调用方法),这里再次访问其他模块就更加简单,只需要在Controller中注入这个接口,并调用其中的方法即可。
4.3 Feign的传递参数方式
之前的我们时没有传递任何参数的
1、传递参数注意事项
- 如果你传递的参数,比较复杂时,默认会采用POST的请求方式(即使你的method声明了GET也会用POST)。
- 传递单个参数时,推荐使用@PathVariable,如果传递的单个参数比较多,这里也可以采用@RequestParam,这两个注解都不能省略value属性。
- 传递对象信息时,统一采用json的方式,添加@RequestBody(没有value属性)
- Client接口必须采用@RequestMapping(不支持GetMapping等)
下面就声明几个接口去测试一下。
2、在search模块下准备三个接口(分别用@PathVariable、@RequestParam和json的方式去接收@RequestBody)
回到searh模块下,准备三个接口,为了传递对象,这里声明一个对象出来,为了方便操作,在pom文件中添加lombok依赖。
package com.qf.controller;
import com.qf.entity.Customer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class SearchController {
@Value("${server.port}")
private String port;
@GetMapping("/search")
public String search() {
return "search:" + port;
}
//单独调用没问题
//连接:http://localhost:8081/search/2
//接收单个单个参数
@GetMapping("/search/{id}") //@PathVariable这个注解是为了从地址中获取id参数用的
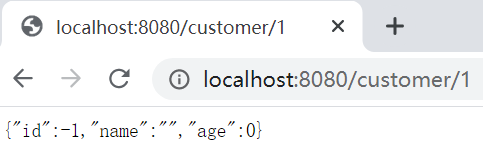
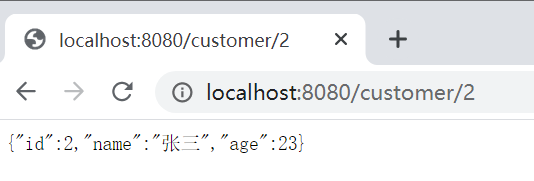
public Customer findById(@PathVariable Integer id) {
return new Customer(id,"张三",23);
}
//单独调用没问题
//接收多个单个参数 如果我们访问时少加一个参数,会报400的错,因为我们的RequestParam没有指定required=false
//错误访问:http://localhost:8081/getCustomer?id=1
@GetMapping("/getCustomer")
public Customer getCustomer(@RequestParam Integer id, @RequestParam String name) {
return new Customer(id,name,23);
}
//单独调用没问题
//连接:http://localhost:8081/save?id=2&name=xiaoming&age=12
//接收单个多个参数,即单个对象
//而到这边后,由于我的请求参数过于复杂,是一个对象,我们用get接收,是不行的,要改为postmapping,但是接口处不用改,还是get,它会自动用post
@PostMapping("/save") //会自动转换为POST请求,即使你写的是GET 现在访问会出现405
public Customer save(@RequestBody Customer customer) { //这里的@RequestBody不加也是可以的,建议加上
return customer;
}
}
package com.qf.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @NoArgsConstructor @AllArgsConstructor public class Customer { private Integer id; private String name; private Integer age; }
3、封装customer模块下的Controller
由于此时customer的controller和Search模块的controller很像,先把那边的copy过来。然后在这个基础上修改。
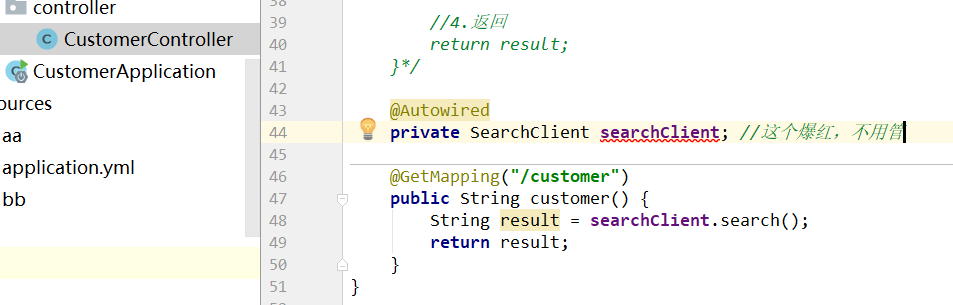
package com.qf.controller; import com.netflix.appinfo.InstanceInfo; import com.netflix.discovery.EurekaClient; import com.qf.client.SearchClient; import com.qf.entity.Customer; import org.apache.naming.factory.ResourceLinkFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; /** * @author YCKJ-GaoJT * @create 2020-11-11 10:22 **/ @RestController public class CustomerController { /*@Autowired private RestTemplate restTemplate; @Autowired private EurekaClient eurekaClient; //这个飘红不用管 @GetMapping("/customer") public String customer() { //1.通过eurekaClient获取到SEARCH服务的信息 //第一个参数是APPLICATION 的名称,在浏览器eureka上可以查看,其它项目也可以查看 //第二个是选择http请求还是https,false是http,显然这里是http InstanceInfo info = eurekaClient.getNextServerFromEureka("SEARCH", false); //2.获取访问的地址 String url = info.getHomePageUrl(); System.out.println(url); //3.通过restrestTemplate访问 String result = restTemplate.getForObject("http://SEARCH/search", String.class); //4.返回 return result; }*/ @Autowired private SearchClient searchClient; //这个爆红,不用管 @GetMapping("/customer") public String customer() { String result = searchClient.search(); return result; } //接收单个单个参数 @GetMapping("/customer/{id}") //@PathVariable这个注解是为了从地址中获取id参数用的 Customer findById(@PathVariable Integer id) { return searchClient.findById(id); } //接收多个单个参数 @GetMapping("/getCustomer") public Customer getCustomer(@RequestParam Integer id, @RequestParam String name) { return searchClient.getCustomer(id,name); } //上面两个测试都是没有问题的,但这个测试报来500的错误 //http://localhost:8080/save?id=1&name=xx&age=11 //这里少写参数是没有问题的,会默认是null //这个报错的原因是什么?? //首先浏览器访问的请求发送到这里,是没有问题的,然后就是走接口,通过Feign访问serach模块。 //接收单个多个参数,即单个对象 @GetMapping("/save") //现在访问会出现500错误 public Customer save(Customer customer) { //return searchClient.save(customer); return customer; } }
4、再封装Client接口
这里也是将这三个复制过来,进行修改。这里需要特别说明的是,FeignClient中是不支持GetMapping和PostMapping的,我们要用RequestMapping,并声明method。
这里的接口不需要声明public关键字(接口不用声明是显然的)。
package com.qf.client; import com.qf.entity.Customer; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.ResponseBody; @FeignClient("SEARCH") //指定服务名称 public interface SearchClient { // value -> 目标服务的请求路径,method -> 映射请求方式 //value是轮径,和另一个模块的一样 @RequestMapping(value = "/search", method = RequestMethod.GET) String search(); //该方法是从另一个模块的Controller中拿过来的。 //接收单个单个参数 @RequestMapping(value = "/search/{id}", method = RequestMethod.GET) //@PathVariable这个注解是为了从地址中获取id参数用的 Customer findById(@PathVariable(value = "id") Integer id); //接收多个单个参数 @RequestMapping(value = "/getCustomer", method = RequestMethod.GET) Customer getCustomer(@RequestParam(value = "id") Integer id, @RequestParam(value = "name") String name); //接收单个多个参数,即单个对象 //虽然这里用GET也可以,还是会走post请求,但是还是建议改为post,非常建议改成POST,虽然get不会错 @RequestMapping(value = "/save", method = RequestMethod.GET) //会自动转换为POST请求,即使你写的是GET 现在访问会出现405 public Customer save(@RequestBody Customer customer); }
下面就是测试,把两个search模块启动,再启动customer模块。先步通过customer模块直接访问search模块测试,再通过customer模块测试。
4.4 Feign的Fallback
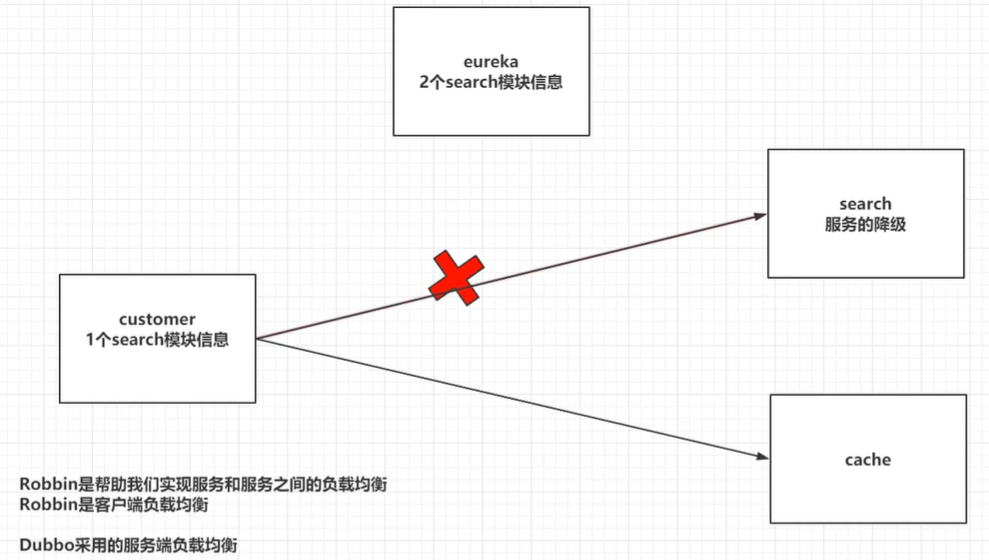
这里customer模块去访问search模块,如果访问成功则访问cache模块。但是如果访问search模块失败,怎么办?那就不能访问cache模块了。此时呢?我想即使访问search失败,我依然要访问cache模块,该怎么办?这里就是服务降级,如果访问search模块失败,你给我一个错误的数据,失败的数据,然后我可以继续访问cache模块。而不是直接报错。
Fallback可以帮助我们在使用Feign去调用另外一个服务时,如果出现了问题,走服务降级,返回一个错误数据,避免功能因为一个服务出现问题,全部失效。步骤如下:
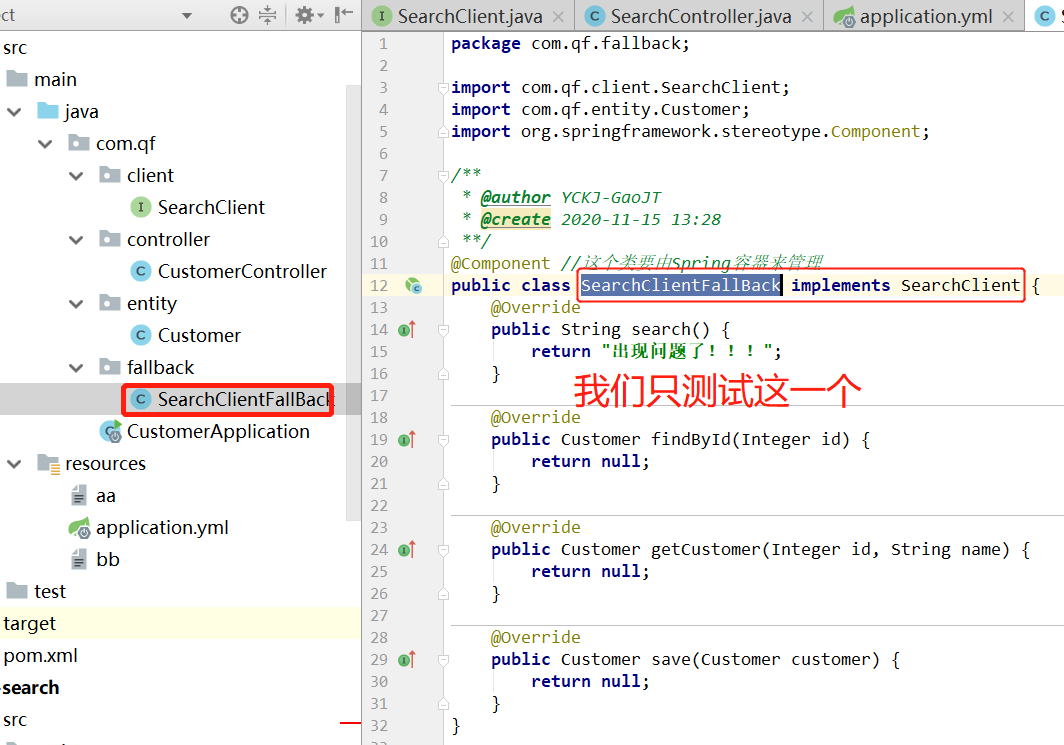
1、创建一个POJO类,实现Client接口。(这个类实现了接口中的所有方法,针对每一个方法,如果出现了错误该怎么办,即出现问题时,你要返回的错误数据)。
这里重写了之后,我们只测试这一个方法,因此就第一个方法search里面return了。
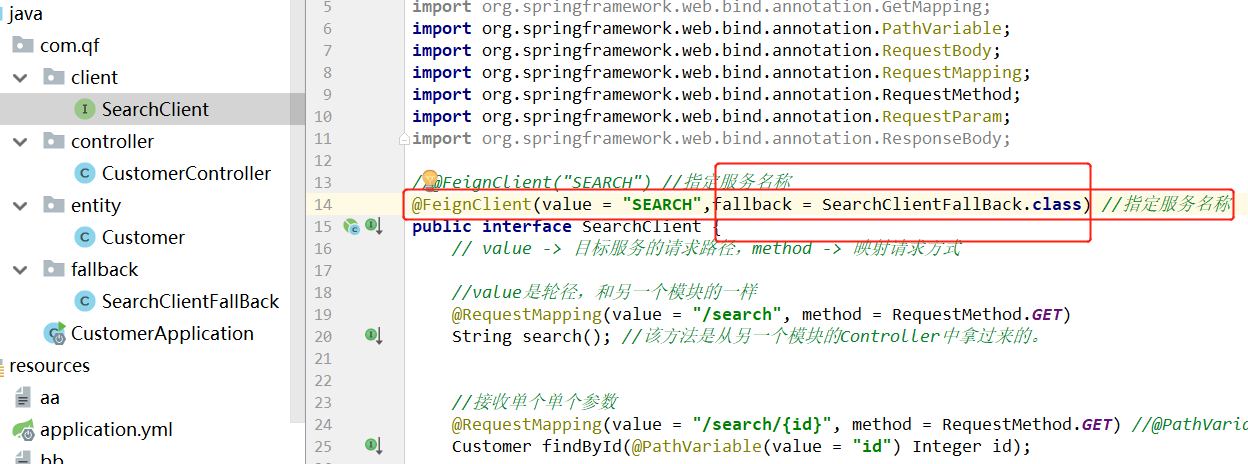
2、修改Client接口中的注解,添加一个属性(把我们刚刚添加的POJO类给指定上) 。
3、添加一个配置文件(在yml中)。
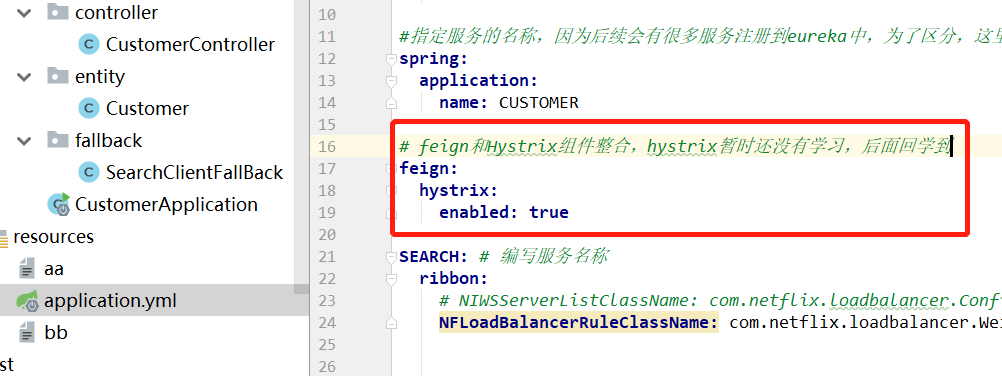
下面就是测试了,重启customer和search模块,然后在浏览器端输入地址,访问客户端的customer地址,此时会通过feign调用search(调用哪个模块不一定,因为Robbin)。此时访问search模块下的search方法时(注意,这里为了出现错误,我们对其代码进行了修改,如下),然后自然是不能访问成功的,但是这时候,依然进入了回调方法,页面显示“出现问题了!!!“。
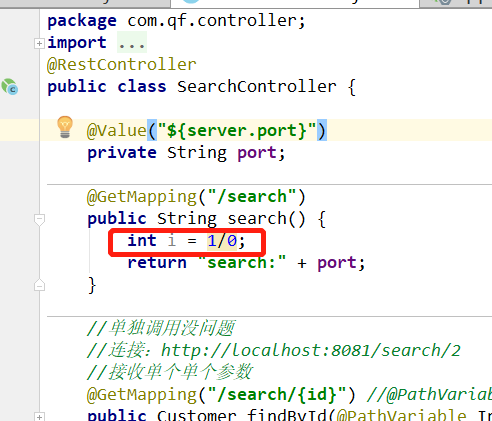
此时打开customer控制台: 没有任何报错。

而打开search(其中一个报错):

上面这样做就会有个问题,调用方(customer模块)无法知道具体的错误信息是什么。
此时我们可以通过FallBackFactory的方式去实现这个功能。
1、而FallBackFactory是基于Fallback的(因此上面的三步还是要写的)。只需要稍微修改一下即可。
2、再创建一个POJO类,实现FallBackFactory<Client>,泛型要指定Client类,这里就是SearchClient。其同样需要Spring容器来管理。

这个类我这里讲解一下:其作用其实就是将Search模块的错误信息拿过来,在customer模块中打印一下:其需要Spring容器管理,因此有Component注解;其要实现FallbackFactory接口,泛型是SearchClient;重写的方法的返回值就是SearchClientFallBack,因此要注入,这是固定固定;最后方法体中要打印错误信息,方法形参已经拿到了对象,打印即可。
3、修改client接口中的属性。(之前用fallback,现在用fallbackfactory)

SearchClient接口中此时的FeignClient注解属性不再需要fallback,需要的是fallbackFactory。
下面就是测试,重启customer即可测试,此时发现customer(调用方)控制台也出现了错误信息。此时这个错误信息就非常清晰,可以知道具体位置。
feign.FeignException$InternalServerError: [500] during [GET] to [http://SEARCH/search] [SearchClient#search()]: [{"timestamp":"2020-11-15T06:04:48.697+00:00","status":500,"error":"Internal Server Error","message":"","path":"/search"}]
5. 服务的隔离及断路器-Hystrix
5.1 引言
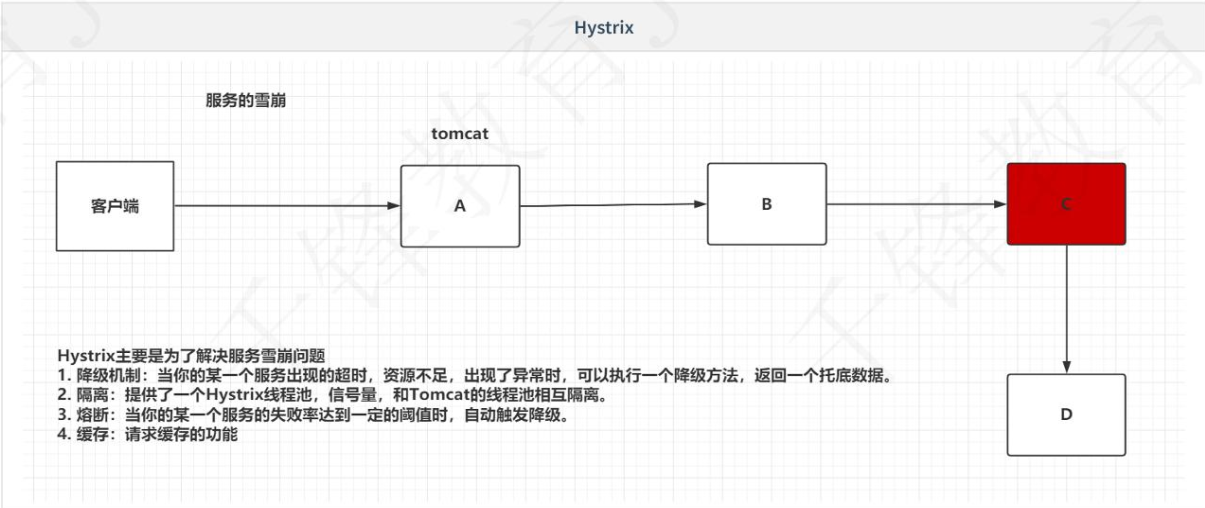
当客户端访问A模块的时候,A模块想要给客户端返回数据,它需要调用B模块,B模块想要给A模块数据,需要调用C模块,C需要调用D。如果此时C模块宕机了,那么整个就出现了问题,我们称之为服务的雪崩。
Hystrix主要是为了解决服务雪崩问题:(其提供了四个重要的机制)
1.降级 机制:当你的某一服务出现了超时,资源不足,出现了异常时,可以执行一个降级方法,返回一个拖地数据。(我们前面Feign中的fallback其实就是服务降级,其就是Feign和Hystrix的整合,当出现错误,给你返回一个字符串提示)。有人会说,那我用try-catch就可以完成这样的功能了。其实Hystrix还提供了其他三个功能。
2.隔离:提供了一个Hystrix线程池,信号量,和Tomcat的线程池相互隔离。(Tomcati里面的线程池时有一定数量的,当模块调用或访问时,就会用一个线程来处理该调用,但是时会用完的,如果用完了,就不能处理业务,就出现了问题。如果用Hystrix,则访问时走Tomcat线程池,处理业务时走Hystrix线程池)。其实没有听懂。
3.熔断:当你的某一个服务的失败率达到一定的阈值时,自动出发降级。(比如这个C模块访问10次,9次都有问题,那么Hystrix就有理由相信你有问题,触发熔断机制,下次再访问时,B模块就不访问你了,Hystrix自动用服务降级,即1功能,返回你降级后的提示数据,这样避免频繁访问一个有问题的模块。)
4.缓存:请求缓存的功能,其实用户请求,或者我们处理很多业务的时候,很多访问都是一样的,如果有了缓存,当Hystrix发现请求一样时,就把缓存数据给你,就不再走一次模块访问了。
注:服务降级我们已经用过Feign的fallback了,不过它还有其他的实现方式。
5.2 降级机制实现
上面我们已经学过Feign的fallback了。现在再学Hystrix关于降级机制的实现。
1、导入依赖(Hystrix的)
在官网中,其还是在Netflix中。我们要在customer模块中添加(调用方),这里还是不需要版本。

<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
2、添加一个注解(就像Eureka和Feign一样)
同Eureka和Feign,为了让当前功能可以使用Hystrix,我们在启动类上添加一个注解。

3、针对某一个接口去编写它的降级方法(这里的接口说的不是interface,而是controller),这里降级方法中的@PathVariable是可以不要的。

其实这里我就有点疑惑了,我上面写的是这些信息添加在调用方(当然我自己理解的,然后被调用发出现错误,我理解的是search,则被调用方或有个降级方法,即这个降级方法是在被调用方的。)这里竟然错误和降级方法都是在调用方,可能我理解的有点问题吧。
上面错误后,我们希望访问customer/id地址后,返回的是一个new的对象,而不是给我报错(500异常)。
4、在接口上添加注解(这里的接口说的不是interface,而是controller)
到了后面这个注解里面我们会添加很多属性。
@HystrixCommand(fallbackMethod = "findByIdFallBack") //指定错误时走哪个方法。
5、测试一下(当出现问题时,会走这个降级方法,从而返回一个托底数据)
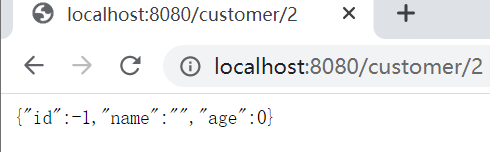
这个降级是成功了,但是Customer模块竟然没有报错。
5.3 线程隔离
如果使用Tomcat的线程池去接收用户的请求,使用当前线程去执行其他服务的功能,如果某一个服务出现了故障,导致tomcat的线程大量的堆积(最终不断请求,线程池耗尽),导致Tomcat无法处理其他业务功能。对于这种情况,Hystrix提供了两种方式:
1、Hystrix的线程池(默认),接收用户请求采用tomcat的线程池,执行业务代码,调用其他服务时,采用Hystrix的线程池。我们举例说明这样的好处,比如客户端i请求A模块中的一个功能,然后嗲用到后面的C模块失败了,按道理这样时间长就会线程池耗尽。但是呢?向后调用C模块,我们现在用Hystrix来处理,就和Tomcat线程池无关了。此时如果客户端要访问A模块中的其他功能,还是可以访问的。
2、信号量,使用的还是Tomcat线程池,帮助我们去管理Tomcat的线程池。比如:如果没有线程了,就让请求排队等待。

现在我们在这两个客户端controller中的两个访问中分别打印线程名字,并在浏览器中访问,结果是:
hystrix-CustomerController-1(添加了HystrixCommand注解后默认使用Hystrix线程池,当然我们也可以修改默认)
http-nio-8080-exec-3(这个是Tomcat线程池中的线程)
下面的方法customer/id的访问默认使用的是hystrix线程池。
下面我们说一下如何配置Hystrix线程池和信号量。
1、Hystrix的线程池的配置(访问A)(具体的配置name属性需要去查看HystrixCommandProperties类)
找到GitHub官网,下翻找到维基百科进去。其实也是在Github中,右侧栏目看到Configuration,这里就放着Hystrix的全部配置。可以找到下面的所有配置。


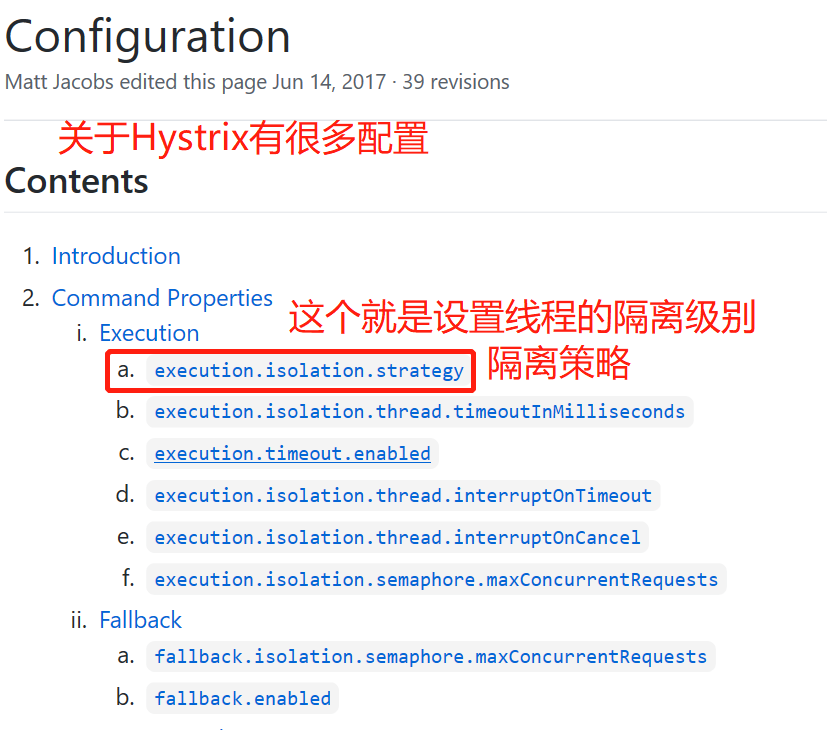
1.线程隔离策略:name=hystrix.command.default.execution.isolation.strategy,value=THREAD,SEMAPHORE。(value只用这两个结果,一个是线程池(默认),一个是信号量,当然在这里是配置线程池,自然选择THREAD)。
2.指定超时时间(这个只有线程池有,信号量没有):name=hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds,value=1000(默认是1000ms)。是说用Hystrix线程池调用时,多长时间返回讲解方法结果。比如如果用Hystrix线程池访问,超过1s还没有给结果,则返回降级结果。
3、是否开启超时时间配置:name=hystrix.command.default.execution.timeout.enabled,value=true;这是默认值,时说上面的超时时间配置是否生效。
4、超时之后是否中断线程:name=hystrix.command.default.execution.isolation.thread.interruptOnTimeout,value=true(这也是默认值);这个是true是很正常的,因为超时了,就没有必要再向下执行了。
5、取消任务后是否中断线程:name=hystrix.command.default.execution.isolation.thread.interruptOnCancel,value=false(默认值);这是指,我们发送请求,然后又取消(中断)了,不想发送了,取消任务了。那么此时线程受否终端,false的意思是不中断,即使你取消了,我依然会执行下去,只是获取的结果我不做处理。有人可能会想,那我不是应该用true吗?如果是true,这里中断线程,可能会抛出异常,因此我们还是用false。
现在我们在controller中指定一下这些属性,这里使用HystrixCommand注解配置时,默认就是用了线程池(而不是信号量),那么该怎么配置呢?我们要用commandProperties属性,点进去后发现它需要的是一个HystrixProperty[]数组。点进去HystrixProperty发现它对应的是name和value两个字段。因此这里配置时应该是一个数组,里面是name和value配置具体的hystrix数据库信息。那么我们的name和value根据上面的配置即可(你想的太美了)。我们不能根据上面的name配置,那么name要去哪里找呢?要在类HystrixCommandProperties中去找,在里面我们才能真正找到你需要的key是什么。比如说我们要指定隔离策略,如下图所示。我们按住ctrl进入ExecutionIsolationStrategy,会找到隔离策略,再下翻找到另一幅图片,标注位置就是需要我们指定的key,






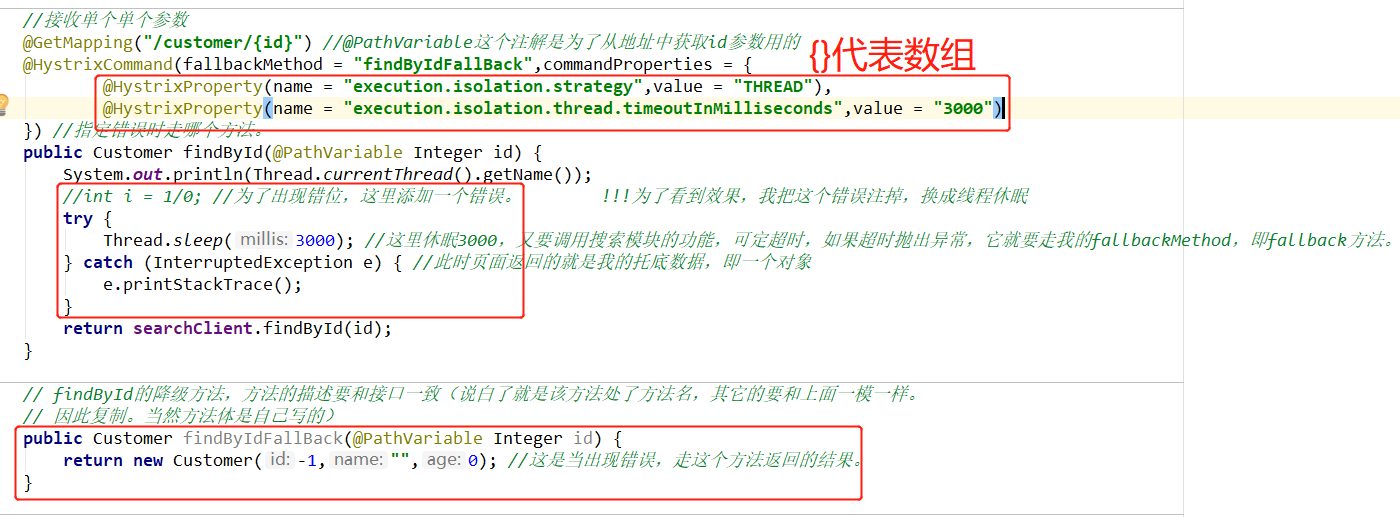
上面两幅图配置了隔离测录饿,和超时时间,并进行代码的修改,下面测试一下。
当然如果此时把休眠注释掉,再次访问,就可以拿到正常的数据了。
2、信号量的配置信息
在官网中紧接着就可以看到指定信号量的最大并发数。此时你会发现它的默认值是10,你可能会想,这样的话信号量会不会太少了,此时你会看到上面这句话,它说如果你有5000的并发数,那么只需要两个信号量,也就是说10的话,你可以处理2.5万的并发数,而Tomcat根本接收不了这么多的请求并发量。
![]()

1.线程隔离策略:name=hystrix.command.default.execution.isolation.strategy,value=SEMAPHORE。(value只用这两个结果,一个是线程池(默认),一个是信号量,当然在这里是配置信号量,自然选择SEMAPHORE)。
2、指定信号量的最大并发请求数:name=hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests,value=10;
当然我们上面已经说过了信号量是不支持超时时间的。下面测试一下:这里说明一下:如果不注释掉休眠,会走fallback方法,暂时不知道为什么。
 5.45
5.45
5.4 断路器(熔断机制)
5.4.1 断路器介绍
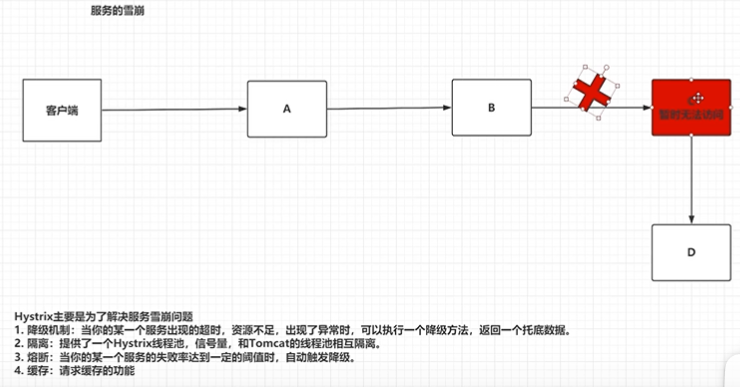
当我们B访问C的时候,正常情况下是可以访问的,但是如果访问C模块达到一定的阈值都无法访问,则启动供断路器机制,下次访问直接返回fallback方法(即访问该方法),不再访问正确逻辑。
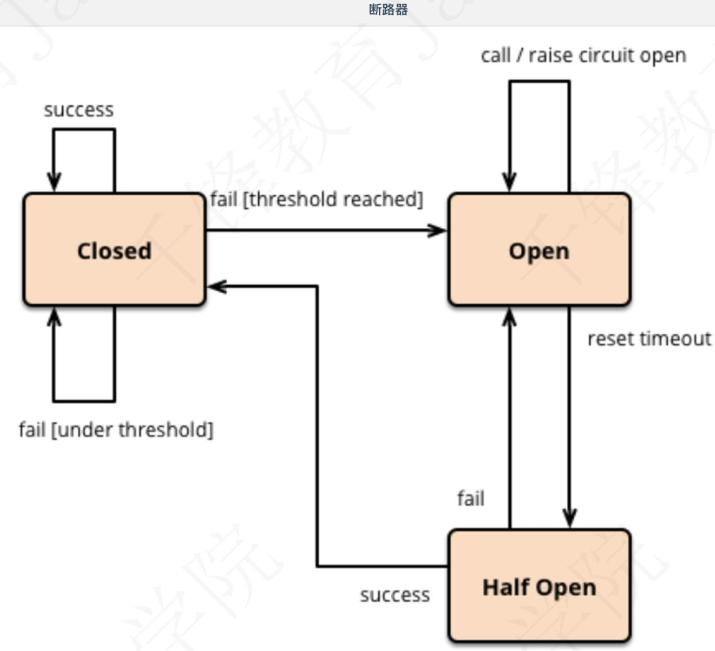
在调用指定服务时,如果说这个服务的失败率达到你输入的一个阈值,断路器则会从closed状态,转变为open状态。此时服务是无法被访问的,如果你访问就直接走fallback方法。但是这断路器是不可能一直开着的,你始终要访问正常的业务的,因此在一定的书简后,open状态会转变为half open状态,允许一个请求发送到我的指定服务(如果此时有人访问时,我会通过这个而请求,让它访问,不直接返回fallback方法),如果成功,转变为closed,以后就可以正常访问了,该服务启动了,正常了。如果失败,服务再次转变为open状态,会再次循环到half open,直到断路器回到一个closed状态。
5.4.2 配置断路器的监控界面
按道理这里就要配置断路器了,但是配置之前先配置一下监控界面,以便我们看到断路器是open状态还是closed状态。
1、导入依赖(是监控页面的依赖)
在customer模块的pom文件中输入springhystrix即可有提示:这里一样不要输入版本。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency>
2、在启动类中添加注解(控制界面)
@EnableHystrixDashboard
3、配置一个Servlet(我们的SpringCloud版本比较高,2.x之前的可能不需要,或者不这么做),制定上Hystrix的Seavlet(我们这里写的seavlet并不是我们自己写的,而是Hystrix已经帮我们写好了,但是他却还没有配置的)。名字就叫HsytrixStreamServlet,可以搜索到这个类。然后还要在启动类上加一个注解,要不然Springboot是不会管这个servlet的。

@ServletComponentScan("com.qf.servlet") //如果只是写了servlet,springboot是不管的,要在这里写上扫描servlet的位置
4、测试(重启并直接访问/hystrix路径即可)
https://localhost:8080/hystrix.stream
刚进来什么都没有
我们刷新一下之前的访问
这里暂时失败了,不知道为什么?不过为了进度,暂时先跳过这里,学习Zuul。
6. 服务的网关-Zuul
6.1 引言
zuul(和Negix有点像)是SpringCloud中最重要的组件之一。在本来的项目中可能有很多模块,比如上面我们写的客户模块、搜索模块、再比如缓存模块和充值模块。
1、在以前如果客户端访问指定服务,需要客户端维护大量的ip和port信息,有了Zuul后,直接访问指定服务。
2、如果每个模块需要添加认证和授权,在以前就需要在每一个模块中都添加认证和授权的操作,代码冗余。现在只需要Zuul来管理认证和授权即可,只要是Zuul认证通过的,就可以访问该模块。
3、如果项目迭代,服务就需要拆分或者是合并,比如客户模块的功能拆分为客户1和客户2模块,那么客户端就要有大量的改变,但是现在只需要在Zuul中配置即可。
4、统一的把安全性校验都放在Zuul中。

6.2 Zuul的快速入门
非常非常非常简单
1、新创建一个Maven项目,修改为SpringBoot
创建05-zuul模块(Maven工程),为了将这个Maven工程转变为SpringBoot,需要我们引入依赖spring-boot-starter-web;接下来还要把启动类构建出,现在其实就已经是SpringBoot工程了,就这两步就可以把Maven工程修改为Springboot;下面需要在resources下创建application.yml,这一步也算是吧,创建他的目的是待会要配置Eureka的内容。

2、导入依赖
还是在netflix官网中,看到Zuul

下面我们要明白一点,之所以Zuul能帮我们把请求转发到Eureka上,上因为他也注册到了Eureka上,因此Zuul模块要引入EurekaClient依赖;因此到这里加上web依赖,总共是三个依赖。
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-zuul</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies>
3、添加一个注解
这里需要添加两个注解:其中一个是EurekaClient的注解(当然这个以前讲过,添加和不添加都是一样的)。另外一个是关于Zuul的注解。@EnableEurekaClient,@EnableZuulProxy(注意不要添加成EnableZuulServe注解)
4、编写配置文件
这里编写配置文件其实是和Eureka有关的,就是讲将这个模块注册到Eureka上。(Eureka登陆需要用户名和密码,在连接上体现,还有要指定端口号,要不然冲突)
# 指定Eureka服务地址eureka:
eureka:
client:
service-url:
defaultZone: http://root:root@localhost:8761/eureka/,http://root:root@localhost:8762/eureka/
# 指定服务的名称
spring:
application:
name: ZUUL
server:
port: 80
5、直接测试(因此Zuul默认就有一个策略,将客户端的请求转发到其它服务)
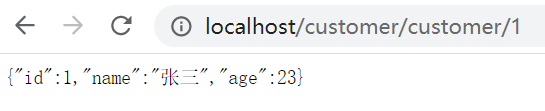
直接启动Zuul模块。先登陆localhost:8761看看有没有注册上(我8761上面的服务不全,8762上全,这两个信息不是互通的吗?暂时不知道为什么);接下来我们直接通过ZUUL访问一下CUSTOMER中的接口,怎么直接访问呢?http://localhost:80/customer/customer/1,前面红色部分代表的就是ZUUL上的CUSTOMER模块(地址上小写即可),然后访问该模块接口。其中80端口可以不用写,即http://localhost/customer/customer/1即可。这里就返回了正确数据。即地址:端口号(ZUUL的)/模块名/路径

6.3 Zuul常用配置信息
6.3.1 Zuul的监控界面
上面通过地址+模块名称和地址就能访问相应模块的信息,那到底是怎么处理的呢?我们现在通过Zuul的监控页面看看,当然Zuul的监控页面并不像Hystrix监控页面那么好,这里只是json字符串。
1、导入依赖(这个依赖不是SpringCloud的依赖,而是SpringBootStarter的依赖)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>
2、编写配置文件(上线不要配置zuul的监控信息,我们这里也为了监控下情况)
# 查看zuul的监控界面(开发时,配置为*,上线,不要配置该信息)
management:
endpoints:
web:
exposure:
include: "*"
3、直接访问(localhost:80/actuator/routes),下面就可以看到几个※※(路径)和后面的名字(服务名),用后面的字段就可以访问该模块,加上具体地址就能访问模块里面的地址。后面我们再配置的时候会先看看这上面有没有添加成功,再测试模块功能。

6.3.2 忽略服务配置
现在我们可以看到所有服务的信息都会映射上,包括Eureka,当然我们是不希望用户看到Eureka,所以要忽略。
# Zuul的配置
zuul:
# 基于服务名忽略服务,无法查看
ignored-services: eureka
![]()
其实当你在配置文件中输入zuul时,会发现两种忽略服务配置的方式:一种就是上面的,按照服务名配置;另一种就是按照访问路径(这里需要说明一下,自定义服务配置通过按服务名配置是无法忽略的,想要忽略的话可以通过后面的路径进行忽略,至于什么是自定义服务的配置,后面讲)
# Zuul的配置
zuul:
# 基于服务名忽略服务,无法查看,如果你要忽略全部的服务,不需要写全部的服务名称,用”"*"“,默认配置的全部路径都会被忽略掉(自定义服务的配置,无法忽略)
ignored-services: eureka
# 监控界面依然可以查看,在访问的时候,404
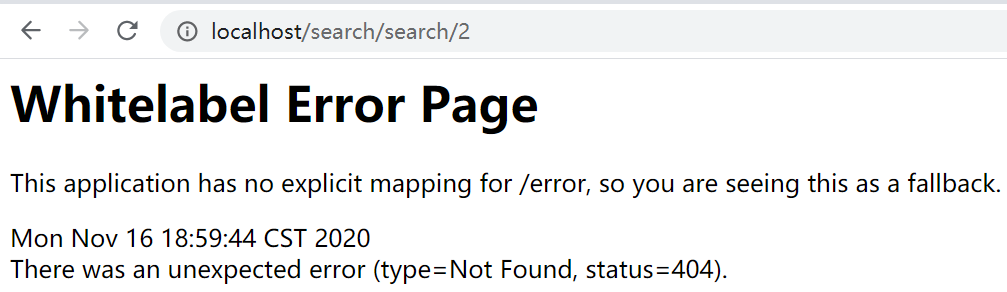
ignored-patterns: /**/search/** # 这里你可以使用/search/**,即search路径下的地址,但是官方更推荐/**/search/**,即包含search都会被忽略
此时再重启服务器查看一下:咦,怎么search模块还存在,这就是两种配置的不同之处了,这种按路径配置,在Zuul还是可以看到在,但是当你访问search里面的地址时,会报404错误。

6.3.3 自定义服务配置
我们上面是通过服务名称+服务下的controller中地址访问到某个路径,但是呢?我们有时候并不希望这些名称暴露在外面,或者后面我们的服务名称可能非常长。我们希望自定义路径去访问到你指定的服务。怎么办??
方式一:
# Zuul的配置
zuul:
# 基于服务名忽略服务,无法查看
# ignored-services: eureka
ignored-services: "*" # 这里忽略掉全部服务名称(但不包括自定义)
# 监控界面依然可以查看,在访问的时候,404
ignored-patterns: /**/search/** # 这里你可以使用/search/**,即search路径下的地址,但是官方更推荐/**/search/**,即包含search都会被忽略
# 指定自定义服务
routes:
search: /ss/**
customer: /cc/** # 这里是key-value的形式,可以有多个;比如这个是用/cc/**访问customer服务内容
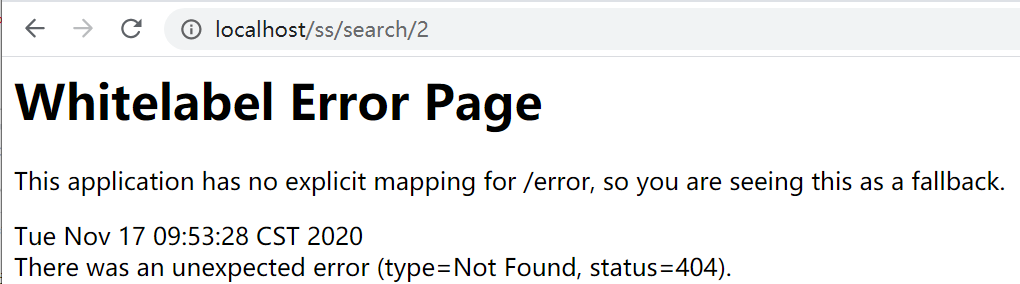
重新启动Zuul,访问监控界面

这时候我们访问search/search/2是访问不到的,因为我们已经忽略了所有的服务,那我们去访问/ss/search/2怎么样呢?也是访问不到的,因为我们在忽略路径时写了/**/search/**,即带有search的路径也会被忽略。

当我们去访问/cc/customer/2的时候就可以访问到了。
![]()
方式二:
# Zuul的配置
zuul:
# 基于服务名忽略服务,无法查看
# ignored-services: eureka
ignored-services: "*" # 这里忽略掉全部服务名称(但不包括自定义)
# 监控界面依然可以查看,在访问的时候,404
ignored-patterns: /**/search/** # 这里你可以使用/search/**,即search路径下的地址,但是官方更推荐/**/search/**,即包含search都会被忽略
# 指定自定义服务(方式一,key(服务名):value(路径))
# routes:
# search: /ss/**
# customer: /cc/** # 这里是key-value的形式,可以有多个;比如这个是用/cc/**访问customer服务内容
# 指定自定义服务(方式二)
rotes:
kehu: #自定义名称
path: /ccc/** # 映射的路径
serviceId: customer # 服务名称
大家可能看这种方式更加麻烦一点,但是呢?他也有好处,可以指定更多的内容。具体可以指定那些内容?点击kehu进去,发现他需要的是一个map,其中value是ZuulRoute,点进去这个类,发现里面有许多可以设置的,我们这里设置了path和serviceId。

重新启动Zuul,访问监控界面
![]()
访问一波:

对于上面两种配置,第一种可能更方便一些,如果你没有特别需求就可以用第一种;如果有特殊需求可能需要其他配置,就用第二种。
6.3.4 灰度发布
什么是灰度发布:灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
说人话:我们用手机上的app,有时候会遇到更新版本。有人会选择更新,有人则不会。那我们开发人员后台肯定会维护两个系统,你请求过来的时候,我们要看是版本v1还是版本V2,然后根据不同版本,发那会不同内容。当然时间长了,大家就都升级版本了。
步骤如下:
1、添加一个配置类(官网可以看到),将其放入启动类即可。


我们现在就用customer模块玩一下,首先我们要给服务改名字以前就叫CUSTOMER,但是呢?现在我们要修改成服务名-V几的样子。
2、准备一个服务,提供2个版本
修改服务名
#指定服务的名称,因为后续会有很多服务注册到eureka中,为了区分,这里起个名字
spring:
application:
name: CUSTOMER-v1
为了起两个服务,我们不用上面这种引用的方式:
version: v1
#指定服务的名称,因为后续会有很多服务注册到eureka中,为了区分,这里起个名字
spring:
application:
name: CUSTOMER-${version}
为了看到测试效果,我加一个全新的controller接口,以方便我知道访问的是不同的版本。
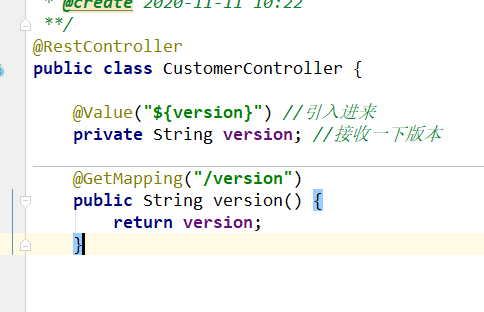
上面接口已经准备好,我们访问这个就可以知道版本号。我们重启这个customer-v1服务。然后我再追加一个,将这个customer再复制一份。然后再启动这个。注意:下图中Main class后面的(1)要去掉,是多写的。
3、修改Zuul的配置
这里都是用Zuul来转发的,因此我们要修改一下Zuul,因为之前我们忽略服务时,忽略了所有服务。然后重启Zuul。

4、测试
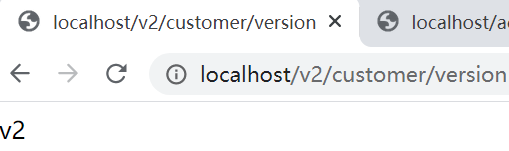
重启之后,我们看下监控界面,发现customer-v1和customer-v2已经起来了,访问路径是需要带上版本号的,如/v2/customer/**。我们访问一下,成功。


6.4 Zuul的过滤器执行流程
过滤器是Zuul的核心组件,上面的这些转发功能就是过滤器帮我们实现的。
客户端请求发送到Zuul服务商,首先通过PreFilter链(不止一个前置过滤器),如果正常放行,会把请求转发给RoutingFilter(这个过滤器就非常简单,是根据你的请求路径转发给不同的服务,我们上面的配置就是配置的这个过滤器),请求转发到一个指定的服务,在指定的服务响应一个结果之后,再次走一个PostFilter的过滤器链,最终再将响应信息交给客户端。
在Spring Cloud Zuul组件中,一共有四种类型的过滤器:Pre前置过滤器、Post后置过滤器、Route路由过滤器、Error错误过滤器。通过自定义前置过滤器、后置过滤器,可以实现对请求的Request处理和Response处理,比如在前置过滤器中实现用户登录验证、权限验证等业务,在后置过滤器中实现对响应数据的统一处理等。
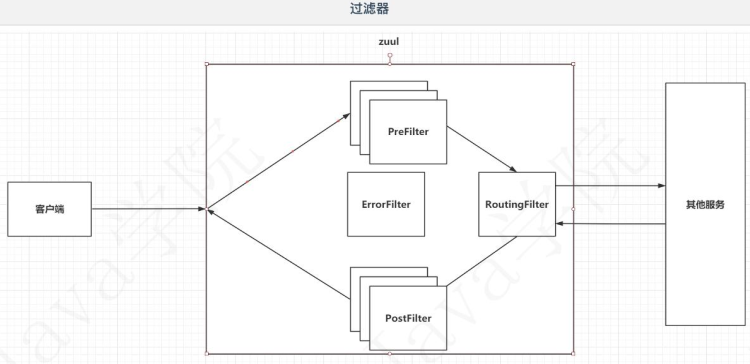
6.5 Zuul过滤器入门
1、创建POJO类,继承ZuulFilter抽象类(里面有4个抽象方法需要实现);
2、第一个抽象方法是指定当前过滤器的类型;
不建议直接写名字,这里用类名.常量
3、指定过滤器的执行顺序(因为是过滤器链,有好几个);
值越小,优先级越高,不建议直接写数字,用常量+/-的方式决定前后

4、配置是否启用
5、指定过滤器中的具体业务代码
6、测试
为了测试有效果,我们写了两个
package com.qf.filter; import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.exception.ZuulException; import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants; import org.springframework.stereotype.Component; @Component public class TestZuulFilter extends ZuulFilter { @Override public String filterType() { //类型有四个:pre、post、routing、error //return "pre,post,routing,error"; 但是他不推荐我们这么写,因为他把他们都设置成一个常量,放在了FilterConstants类中 return FilterConstants.PRE_TYPE; } @Override public int filterOrder() { //上面指定好类型,这里就是指定顺序了,这里也是不太推荐些数字的,我们进入FilterConstants类中 //官方推荐用常数的减法或加法表示在这个过滤器前还是后执行。值越小,优先级越高。 return FilterConstants.PRE_DECORATION_FILTER_ORDER - 1; } @Override public boolean shouldFilter() { //返回true代表开启当前过滤器 return true; } @Override public Object run() throws ZuulException { //这里就是过滤器的具体逻辑了 System.out.println("prefix过滤器执行了~~"); return null; } }
第二个:和第一个区别只是优先级和输出
package com.qf.filter; import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.exception.ZuulException; import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants; import org.springframework.stereotype.Component; @Component public class TestZuulFilter2 extends ZuulFilter { @Override public String filterType() { //类型有四个:pre、post、routing、error //return "pre,post,routing,error"; 但是他不推荐我们这么写,因为他把他们都设置成一个常量,放在了FilterConstants类中 return FilterConstants.PRE_TYPE; } @Override public int filterOrder() { //上面指定好类型,这里就是指定顺序了,这里也是不太推荐些数字的,我们进入FilterConstants类中 //官方推荐用常数的减法或加法表示在这个过滤器前还是后执行。值越小,优先级越高。 return FilterConstants.PRE_DECORATION_FILTER_ORDER + 1; } @Override public boolean shouldFilter() { //返回true代表开启当前过滤器 return true; } @Override public Object run() throws ZuulException { //这里就是过滤器的具体逻辑了 System.out.println("prefix过滤器222执行了~~"); return null; } }
测试:重启Zuul后,在浏览器端访问任意一个地址:比如http://localhost/v2/customer/version,在Zuul的控制台可以看到

6.6 PreFilter实现token校验
使用前置过滤器来实现token,说白了就是校验你身份。
1、准备访问路径,请求参数传递token(传递token的方式有很多,比如请求头,参数,cookie等,我们这里选择最方便的就是参数)
就拿刚刚的访问为例:http://localhost/v2/customer/version,如果你访问的时候有参数,带有token:即http://localhost/v2/customer/version?token=123,则是可以通过的,否则就给你拦截下来,告诉你权限不足。
2、创建AuthenticationFilter
3、在run方法中编写具体的业务逻辑代码
package com.qf.filter; import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.context.RequestContext; import com.netflix.zuul.exception.ZuulException; import org.apache.http.HttpStatus; import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants; import org.springframework.stereotype.Component; import javax.servlet.http.HttpServletRequest; @Component public class AuthenticationFilter extends ZuulFilter { @Override public String filterType() { return FilterConstants.PRE_TYPE; } @Override public int filterOrder() { //在另外两个过滤器前执行 return FilterConstants.PRE_DECORATION_FILTER_ORDER - 2; } @Override public boolean shouldFilter() { return true; } @Override public Object run() throws ZuulException { // 1.获取Request对象 RequestContext requestContext = RequestContext.getCurrentContext(); HttpServletRequest request = requestContext.getRequest(); // 2.获取token参数 String token = request.getParameter("token"); // 3.对比token(后期123这个数据就是从redis或者其他地方获得的) if (token == null || !"123".equalsIgnoreCase(token)) { // 4. token校验失败,直接相应数据,返回401状态码,权限不足 // 4. token校验失败,直接相应数据 requestContext.setSendZuulResponse(false); //这句话意思是不再向下执行,后面的过滤器还会执行,只是Zuul不再转发请求 requestContext.setResponseStatusCode(HttpStatus.SC_UNAUTHORIZED); } return null; //这个返回null不用管,但必须有 } }
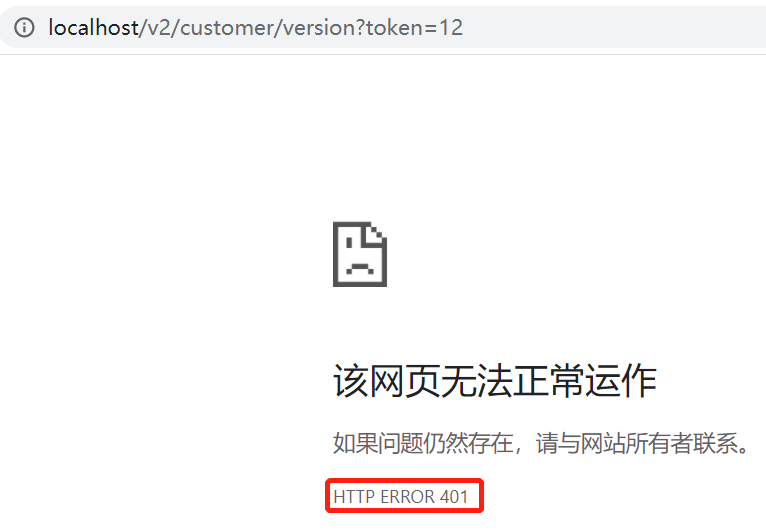
4、测试:携带正确token则成功,携带错误token或不携带,什么也访问不到,但是可以看到错误的状态码。

6.7 Zuul的降级
这个可以理解为Zuul和Hystrix的整合
我们之前在学习Hystrix的时候可能看到过降级,当访问出现错误时,我们走降级方法,返回一个托底数据。但是这里可能有这样一个情况。假如我们有一个访问没有用Hystrix降级处理,但是假设这个方法休眠了三秒钟或者直接不能访问了,那么就会给浏览器(客户端)返回一个错误信息,这是很不友好的。因此在Zuul这里给大家统一降级一下,如果你没有降级,我这里给你降。
步骤如下,非常简单:(我们这里降级不需要单独导入Hystrix的依赖,因为我们导入Zuul的时候,就已经把Hystrix依赖导入过来了。)

1、创建POJO类,实现接口FallbackProvider(实现两个方法,在方法中指定拖地数据,响应信息等)
2、重写两个方法
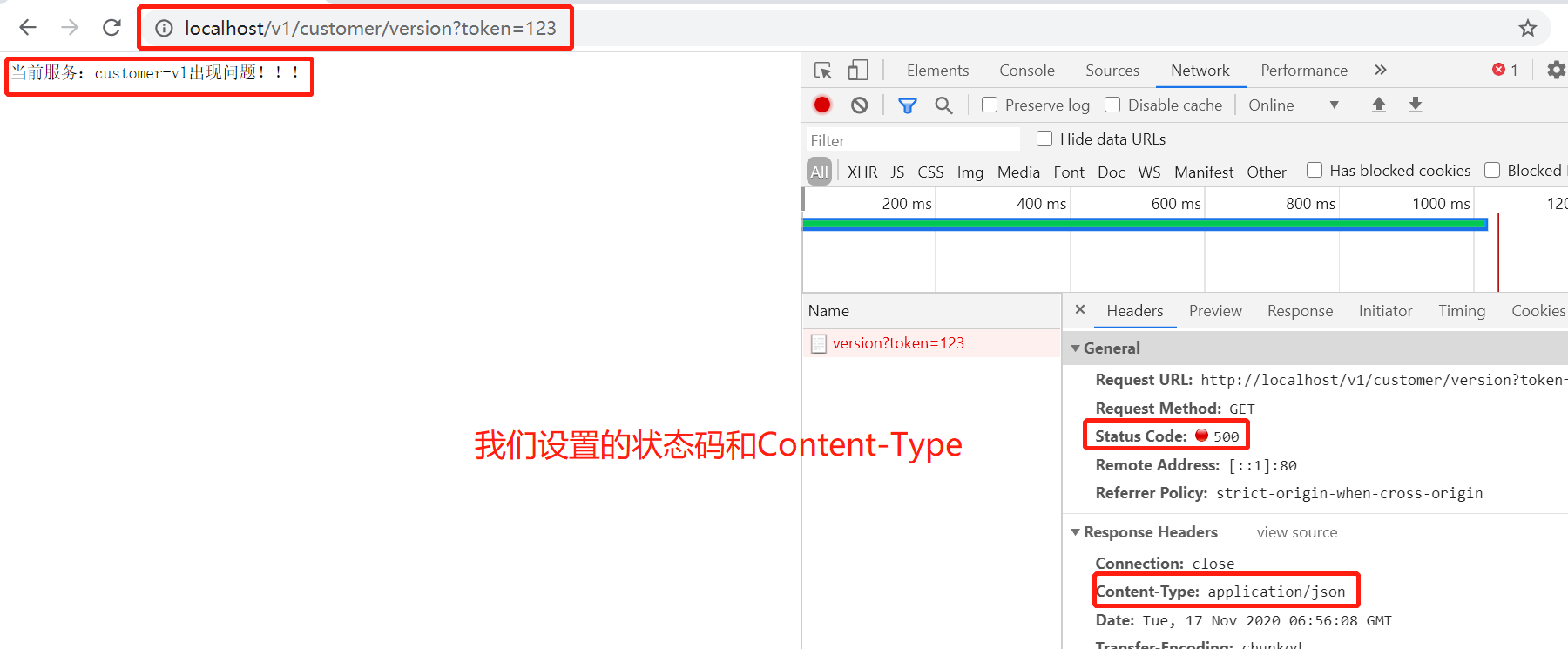
package com.qf.fallback; import org.springframework.cloud.netflix.zuul.filters.route.FallbackProvider; import org.springframework.http.HttpHeaders; import org.springframework.http.HttpStatus; import org.springframework.http.MediaType; import org.springframework.http.client.ClientHttpResponse; import org.springframework.stereotype.Component; import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; @Component public class ZuulFallBack implements FallbackProvider { //这个方法的意思时候当前的fallback要针对哪个服务,我这里直接来个痛快的,"*",针对所有服务 @Override public String getRoute() { //只要你那边没有降级的,全部到我这边的降级方法,返回托底数据 return "*"; //代表指定全部出现问题的服务,都走这个降级方法,而降级方法就是下面这个方法fallbackResponse } //这个是降级方法,参数是两个,route代表降级的服务;cause代表出现的一场信息 @Override public ClientHttpResponse fallbackResponse(String route, Throwable cause) { System.out.println("降级的服务:"+route); cause.printStackTrace(); //这里也可以用日志记录下 //最重要的是返回信息,ClientHttpResponse是接口,你要用匿名内部类重写所有方法 return new ClientHttpResponse() { @Override public HttpStatus getStatusCode() throws IOException { // 指定具体的HttpStatus return HttpStatus.INTERNAL_SERVER_ERROR; //错误类型 } @Override public int getRawStatusCode() throws IOException { // 返回的状态码 return HttpStatus.INTERNAL_SERVER_ERROR.value(); //500错误码 } @Override public String getStatusText() throws IOException { // 指定错误信息 return HttpStatus.INTERNAL_SERVER_ERROR.getReasonPhrase(); } @Override public void close() { } @Override public InputStream getBody() throws IOException { // 给用户相应的信息 String msg = "当前服务:" + route + "出现问题!!!"; return new ByteArrayInputStream(msg.getBytes()); } @Override public HttpHeaders getHeaders() { // 指定响应头信息 HttpHeaders headers = new HttpHeaders(); headers.setContentType(MediaType.APPLICATION_JSON); return headers; } }; } }
为了报错,我们在customer的v1中进行了休眠
3、测试
6.8 Zuul动态路由
我们之前写项目和映射路径时时在配置文件中的,但是当我们项目上线后,再在配置文件里面修改就不行了,因为项目重启的代价非常大。那怎么办?就用动态路由,以后做项目是用redis里面的key和value执行,这里先模拟一下
zuul:
# 基于服务名忽略服务,无法查看
# ignored-services: eureka
# ignored-services: "*" # 这里忽略掉全部服务名称(但不包括自定义)
# 监控界面依然可以查看,在访问的时候,404
ignored-patterns: /**/search/**
# 这里你可以使用/search/**,即search路径下的地址,但是官方更推荐/**/search/**,即包含search都会被忽略
# 指定自定义服务(方式一,key(服务名):value(路径))
# routes:
# search: /ss/**
# customer: /cc/** # 这里是key-value的形式,可以有多个;比如这个是用/cc/**访问customer服务内容
# 指定自定义服务(方式二)
routes:
kehu: # 自定义名称
path: /ccc/** # 映射的路径
serviceId: customer # 服务名称
1、创建一个过滤器
//执行顺序最好放在pr过滤器的最后面
2、在run方法中编写业务逻辑
package com.qf.filter; import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.context.RequestContext; import com.netflix.zuul.exception.ZuulException; import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants; import javax.servlet.http.HttpServletRequest; import java.awt.*; /** * @author YCKJ-GaoJT * @create 2020-11-17 15:15 **/ public class DynamicRoutingFilter extends ZuulFilter { @Override public String filterType() { return FilterConstants.PRE_TYPE; //依然是前置路由 } @Override public int filterOrder() { // 前置过滤器中最后一个执行的 return FilterConstants.PRE_DECORATION_FILTER_ORDER + 2; //最好是所有前置过滤器的最后,在身份校验等结束后再路由 } @Override public boolean shouldFilter() { return true; //开启 } @Override public Object run() throws ZuulException { //1.获取Request对象 RequestContext context = RequestContext.getCurrentContext(); HttpServletRequest request = context.getRequest(); //2.获取参数,redisKey String redisKey = request.getParameter("redisKey"); //我们就不去redis拿数据了,直接判断 //3.直接判断 if (redisKey != null && redisKey.equalsIgnoreCase("customer")) { // http://localhost:8080/customer context.put(FilterConstants.SERVICE_ID_KEY,"customer-v1"); context.put(FilterConstants.REQUEST_URI_KEY,"/customer"); } else if (redisKey != null && redisKey.equalsIgnoreCase("search")) { // http://localhost:8081/search/1 context.put(FilterConstants.SERVICE_ID_KEY,"search"); context.put(FilterConstants.REQUEST_URI_KEY,"/search/1"); } return null; } }
3、测试(拿任一地址访问,返回原有结果,现在我们在里面追加参数redisKey=customer,则会自动跳到我们设定的地址)

![]()
我这里没有成功,但我实在不想尝试了,太累了。 控制台错误我也不想看了,就这了吧。

还是找了错误,其实控制台写的就是超时,我们把上面那个customer模块的超时3000ms注释掉即可。但是测试另外一个好像也不对,哎,累,下一个。
7. 多语言支持-Sidecar
7.1 引言
在SpringCloud的项目中,需要引入一些非java的程序(当然也可能是java程序,其实就是和我们不是一个项目),第三方接口,无法接入erueka,hystrix,feign等等组件(当然了,这是另一个项目,如果是非java语言的,哪有springCloud,如果是java的,比如ssm框架,也谈不上SpringCloud)。启动一个代理的微服务,代理微服务去和非Java的程序或第三方接口交流,通过代理的微服务去计入SpringCloud的相关组件。
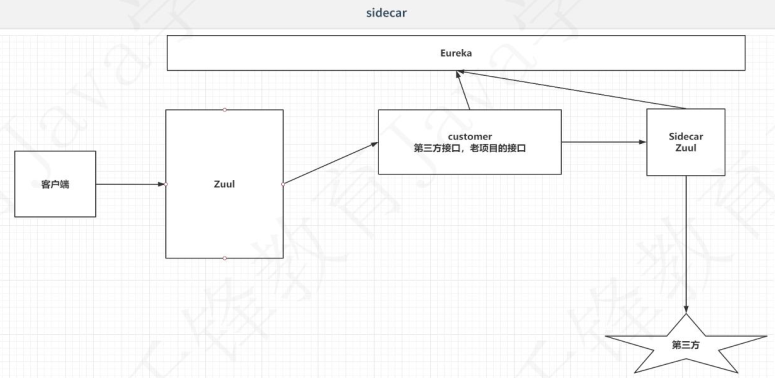
比如这里的星星就是第三方的项目,我们要在自己的SpringCloud项目去调用,正常情况下我们项目的Controller可以直接去调用其他项目(通过restTemplate或者是Feign等,此时需要ip+端口号),但是呢?我们想让这个项目拥有SpringCloud里面组件的功能,如erueka,hystrix,feign。比如现在可以用Eureka的话,就可以让第三方项目的ip和端口号维护在Eureka中(本身是不可能的)。这样就更方便了,不需要记住IP和端口号。这里就用到了Sidecar,他其实也相当于是一个zuul,只是比zuul的配置少的多。下面我们实现一下。
7.2 SideCar实现
步骤如下:
1、创建一个第三方的服务(就是另一个项目,我们这里就在原本的项目中创建一个模块,但是要记住,这个模块不是maven工程,是SpringBoot工程,意思就是和原有的工程没有联系,虽然是其中一个模块,但是模拟两个工程。)
创建一个SpringBoot(other-service)工程,并且添加一个Controller,设置下端口号。
![]()
2、创建maven工程,修改为SpringBoot
这里创建maven工程,还是原有项目的一个模块,只是这里是maven工程,代表是上个工程的子模块。名字是06-sidecar,并修改为SpringBoot工程,添加web依赖spring-boot-starter-web;添加启动类;添加配置文件yml。

3、导入依赖
官网还是在Netflix下,同时我们还要将sidecar模块注册到Eureka上面,所以还要导入EurekaClient的依赖。

<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-sidecar</artifactId>
</dependency>
</dependencies>
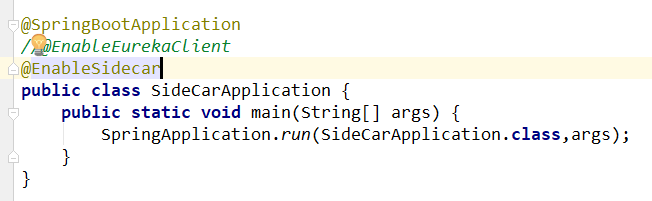
4、添加注解
按道理这里需要导入EurekaClient的注解和Sidecar的注解,但是我们看到官网说这个SideCar说组合注解,所以不用添加EurekaClient注解。但是这是老师说的,我怎么没有在官网看到组合注解包括EurekaClient注解呢?这里省略的真正原因可能是:本来这个注解就可以省略(我猜的,我记得上文学的时候说的)

5、编写配置文件
server:
port: 81 # 指定项目端口号
eureka:
client:
service-url:
defaultZone: http://root:root@localhost:8761/eureka/,http://root:root@localhost:8762/eureka/ #注册到集群
spring:
application:
name: other-service # 指定服务名称,这里我们是代理的other-service,因此就写这个了
# 指定代理的第三方服务,这里你可能有以为,为什么只有端口号,二没有ip呢?因为sidecar只能指定本机的服务,也就是说sidecar模块要和这个模块放一起
sidecar:
port: 7001
现在我们先不着急编写customer,先将other-service和sidecar启动起来。首先访问other-service没有问题,再看下eureka,访问两个监控页面还是有问题,这里就不展示了,也不知道是什么问题。
6、通过customer通过Feign调用第三方服务
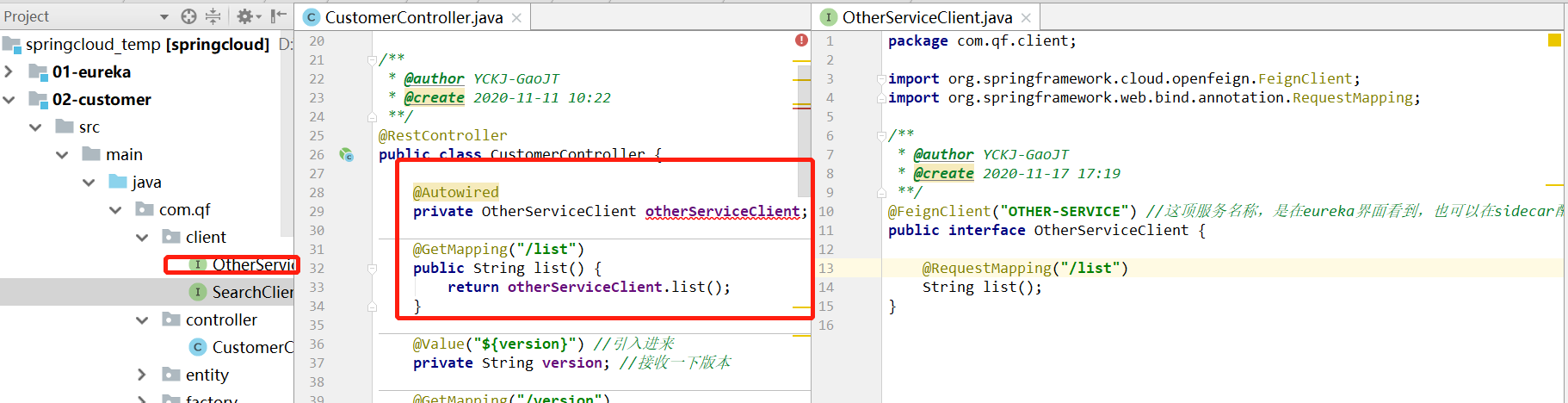
这里又报错了,我甩手不干了,根据错误提示是oadBalance的问题,可能还是我没有注册到Eureka上面吧。
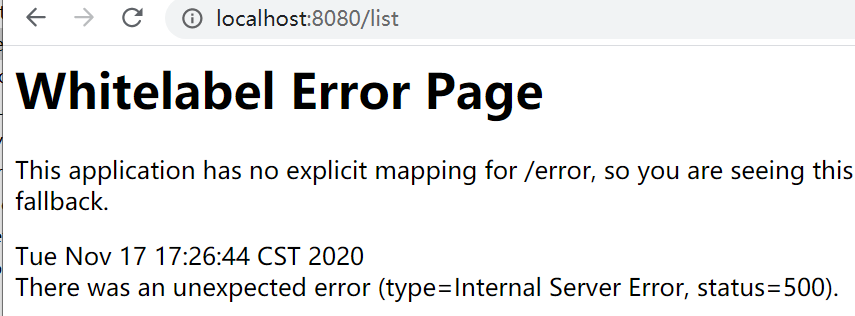
下一个。。。。
这里本来是通过sidecar将一个其他项目注册到我的项目,使用eureka注册和feign调用呢?又有问题了。我们这里不是直接访问的第三方,是通过sidecar调用的。
8. 服务间消息传递-Stream
8.1 引言
在实际开发过程中,服务与服务之间通信经常会使用到消息中间件,而以往使用了哪个中间件比如RabbitMQ,那么该中间件和系统的耦合性就会非常高,如果我们要替换为Kafka那么变动会比较大,这时我们可以使用SpringCloudStream来整合我们的消息中间件,来降低系统和中间件的耦合性。

8.2 Stream快速入门
这里直接跳过因为消息中间件RabbitMQ我还没有学习。
1、启动RabbitMQ
9. 服务的动态配置-Config【重点】
9.1 引言
9.2 搭建Config-server
9.3 搭建Config-Client
9.4 实现动态配置
9.4.1 实现原理
9.4.2 服务连接RabbitMQ
10. 服务的追踪-Sleuth【重点】
10.1 引言
10.2 Sleuth的使用
