Java-集合
课程目标
1.集合的概念
2.Collection接口
3.List接口与实现类
4.泛型和工具类
5.Set接口与实现类
6.Map接口与实现类
1.集合的概念
概念:对象的容器,定义了对多个对象进行操作的常用方法。可实现数组的功能。
和数组的区别:
- 数组长度固定,集合长度不固定;
- 数组可以存储基本类型和引用类型,集合只能存储引用类型。
位置:java.util.*;
2.Collection接口
2.1 Collection体系集合

2.2 Collection父接口
特点:Collection是集合的根接口。Collection表示一组对象,这些对象也称为collection的元素。一些collection允许有重复的元素,而另一些则不允许。一些collection是有序的,而另一些则是无序的。JDK不提供接口的任何直接实现:它提供更具体的子接口(如Set和List)实现。此接口通常用来传递collection,并在需要最大普遍性的地方操作这些collection。
方法:
- boolean add(Object obj) //添加一个对象
- boolean addAll(Collection c) //将一个集合中的所有对象添加到此集合中。
- void clear() //清空刺激和中的所有对象。
- boolean contains(Object o) //检查此集合中是否包含o对象。
- boolean equals(Object o) //比较此集合中是否与指定对象相等。
- boolean isEmpty() //判断此集合是否为空
- boolean remove(Object o) //在此集合中移除o对象
- is size() //返回此集合中的元素个数。
- Object[] toArray() //将此集合和转换成数组。
对于方法的演示,这里就不操作了,你可以用其具体实现类操作,比如ArrayList等。
但是这里对遍历的重点知识说明以下:第一种就是用增强for循环遍历,第二种就是用Collection接口的Iterator接口遍历。
对于Iterator接口,有三个重要的方法:hasNext();next()和remove()。其实就遍历而言用前两个方法配合就可以了,那为什么还需要第三个方法呢?这是因为在用Iterator遍历过程中是不能用Collection接口的remove方法删除元素的,如果这样做会报错。
3.List接口与实现类
3.1 List接口的使用
特点:有序(是添加顺序和获取顺序一致,并非排序)、有下标(可以通过下标访问,但是我们用Collection接口时,就未必可以用下标访问,因为还有Set接口的元素集合,因此这里遍历就又多了个普通for循环)、元素可以重复。
方法:(除去Collection的方法,新增了一些因角标而特有的方法)
- void add(int index,Object o) //在index位置插入对象o。
- boolean addAll(int index, Collection c) //将一个集合中的元素添加到此集合中的index位置。
- Object get(int index) //返回集合中指定位置的元素。
- List subList(int fromIndex, int toIndex) //返回fromIndex和toIndex之间的集合元素。
遍历:上面对于Collection接口有两种遍历方式,这里对于List接口共有四种遍历方式(其实也算三种):普通for循环(借用角标);增强for循环;通过Iterator迭代器;通过ListIterator
对于第四种方法,我这里特别说明以下,这个迭代器是在原有Iterator(三个方法)的基础上进行了增强
ListIterator接口允许程序沿任一方向进行迭代遍历,在迭代期间修改列表,并获取列表中迭代器的当前位置。ListIterator不指向任何元素,其光标始终位于通过调用previous()返回的元素和通过next()返回的元素之间。长度为n的列表的迭代器具有n+1可能的光标位置。
对于反向遍历,需要注意的是,刚开始遍历List时,光标时位于开始的,时不能反向遍历的,只有移动一些位置后才可以反向遍历。
List方法:

3.2 List接口的实现类
ArrayList【重点】
- 数组结构实现(内部维护的是数组)。查询快(为什么)、增删慢(为什么);
- JDK1.2版本加入的,运行效率快、线程不安全。
Vector:
- 数组结构实现(和ArrayList一样维护的是数组结构),查询快、增删慢;
- JDK1.0版本,运行效率慢(为什么)、线程安全。
LinkedList【重点】
- 链表结构实现(内部维护的是双向链表),增删快(为什么),查询慢(为什么)。
3.2.1 ArrayList
package com.yuncong.java_collection; import java.util.ArrayList; //ArrayList:查询遍历快,增加删除慢 public class ArrayListDemo01 { public static void main(String[] args) { // 创建集合 ArrayList arrayList = new ArrayList<>(); // 1.添加元素 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); arrayList.add(s1); arrayList.add(s2); arrayList.add(s3); arrayList.add(s3); System.out.println("元素个数:"+arrayList.size()); System.out.println(arrayList.toString()); //2.删除元素 arrayList.remove(s3); System.out.println("删除之后元素个数:" + arrayList.size()); //注意:此时是无法删除s2的,因为这个删除比较的是equals方法,在没有重写前底层是equals(this==obj),即比较的地址。 arrayList.remove(new Student(18, "张无忌")); System.out.println("再次删除之后元素个数:" + arrayList.size()); } }
运行结果:
下面这个代码是Student类重写equals方法(要记住这五步走战略):此外需要注意的是,重写这个equals方法后,不仅remove方法可以删除同名同龄的新对象,用contains方法判断是否存在也可以(没有重写前返回是false)
还有其它方法,比如indexOf,也可以传入一个新new的同名同龄的对象。因此可以得出结论,但凡是该方法传入了对象,那么我重写equals方法后,传入新new的对象,就会使用该新的equals方法,当然前提是该方法用到了equals。
//重写equals方法的五步走战略 @Override public boolean equals(Object obj) { // 判断是不是同一个对象 if (this == obj) { return true; } //2. 判断是否为空 if (obj == null) { return false; } //3.判断是否是Student类型 if (obj instanceof Student) { Student s = (Student) obj; // 4.比较属性 if (this.name.equals(s.getName()) && this.age == s.getAge()) { return true; } } //5.不满足条件返回false return false; }
此时再次运行则删除成功:
package com.yuncong.java_collection; import java.util.ArrayList; import java.util.Iterator; import java.util.ListIterator; //ArrayList:查询遍历快,增加删除慢 public class ArrayListDemo01 { public static void main(String[] args) { // 创建集合 ArrayList arrayList = new ArrayList<>(); // 1.添加元素 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); arrayList.add(s1); arrayList.add(s2); arrayList.add(s3); arrayList.add(s3); System.out.println("元素个数:"+arrayList.size()); System.out.println(arrayList.toString()); //2.删除元素 arrayList.remove(s3); System.out.println("删除之后元素个数:" + arrayList.size()); //注意:此时是无法删除s2的,因为这个删除比较的是equals方法,在没有重写前底层是equals(this==obj),即比较的地址。 arrayList.remove(new Student(18, "张无忌")); System.out.println("重写Student类中的equals方法后再次删除之后元素个数:" + arrayList.size()); //3.遍历元素【重点】 //3.1使用普通for循环 //3.2使用增强for循环 //3.3使用Iterator迭代器 System.out.println("==========使用Iterator迭代器遍历========"); Iterator iterator = arrayList.iterator(); while (iterator.hasNext()) { Student next = (Student) iterator.next(); System.out.println(next); } //3.4使用ListIterator迭代器 System.out.println("==========使用ListIterator迭代器遍历========"); ListIterator listIterator = arrayList.listIterator(); while (listIterator.hasNext()) { Student next = (Student) listIterator.next(); System.out.println(next); } System.out.println("==========使用ListIterator迭代器逆序遍历========"); while (listIterator.hasPrevious()) { Student previous = (Student) listIterator.previous(); System.out.println(previous); } //4.判断 System.out.println(arrayList.contains(s1)); System.out.println(arrayList.contains(new Student(22,"张三丰"))); System.out.println(arrayList.isEmpty()); //5.查找 System.out.println(arrayList.indexOf(s1)); System.out.println(arrayList.indexOf(new Student(22,"张三丰"))); } }
运行结果: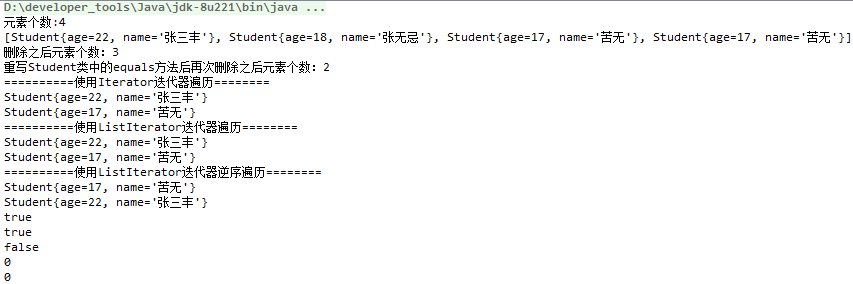
源码分析:
DEFAULT_CAPACITY=10;默认容量
注意:如果没有向集合中添加任何元素时,容量0,添加一个元素之后,容量10
每次扩容大小是原来的1.5倍。
elementData存放元素的数组
size实际元素个数
add{}添加元素
3.2.2 Vector
该类的用法和ArrayList相似,这里就不再说了。面试可能用到,平时很少使用,至于为什么很少使用?百度一下

3.2.3 LinkedList
package com.yuncong.java_collection; import java.util.Iterator; import java.util.LinkedList; import java.util.ListIterator; public class LinkedListDemo01 { public static void main(String[] args) { //创建集合 LinkedList<Object> linkedList = new LinkedList<>(); //1.添加元素 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); linkedList.add(s1); linkedList.add(s2); linkedList.add(s3); linkedList.add(s3); System.out.println("元素个数:" + linkedList.size()); System.out.println(linkedList.toString()); //2.删除 linkedList.remove(s3); System.out.println("用remove直接传引用删除后个数:" + linkedList.size()); linkedList.remove(new Student(17, "苦无")); System.out.println("重写equals方法后,用new对象删除后个数:" + linkedList.size()); //3.遍历 //3.1普通for循环 System.out.println("普通for循环遍历"); for (int i = 0; i < linkedList.size(); i++) { System.out.println(linkedList.get(i)); } //3.2增强for循环 System.out.println("利用增强for循环遍历"); for (Object o : linkedList) { System.out.println(o); } //3.3利用Iterator迭代器遍历 System.out.println("利用迭代器遍历"); Iterator<Object> iterator = linkedList.iterator(); while (iterator.hasNext()) { Student next = (Student) iterator.next(); System.out.println(next); } //3.4利用ListIterator System.out.println("利用列表迭代器"); ListIterator<Object> objectListIterator = linkedList.listIterator(); while (objectListIterator.hasNext()) { System.out.println(objectListIterator.next()); } //4.判断 System.out.println(linkedList.contains(s1)); System.out.println(linkedList.isEmpty()); //5.获取 System.out.println(linkedList.indexOf(s1)); } }
运行结果: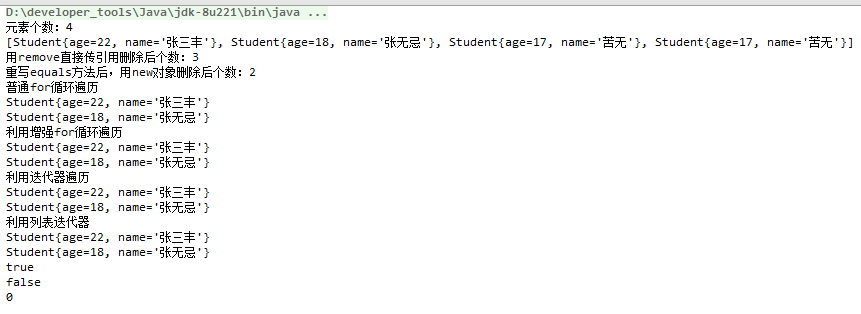
源码分析:
4.泛型和工具类
Java泛型是JDK1。5中引入的一个新特性,其本质是参数化类型,把类型作为参数传递。(其实也就是说用这个类、接口或方法可以传入一个类型参数,可以使用该泛型(表示类型)创建变量等操作,但是不能用来创建对象,如T t = new T();为什么不能??因为你不知道是什么类型,万一这个类型没有无参构造,或者该公祖奥方法是私有的怎么办??)
常见形式有泛型类、泛型接口、泛型方法。
语法:<T,...> T称为类型占位符,表示一种引用类型。(不能是基本类型)
好处:
- 提高代码的重用性;(演示后才会理解,如用泛型方法的时候,一个方法搞定所有类型数据,其实我这里就有疑问,那平时我们用的print、println方法为什么不用泛型呢,以后我可以研究一下)
- 放置类型转换异常,提高代码的安全性。(演示后才会理解,在)
泛型类
package com.yuncong.java_collection; //泛型类 //语法:类名<T>,如果添加多个泛型,用逗号隔开<T,K,E,V> public class GenericDemo01<T> { //使用泛型可以创建变量,但无法实例化 T t; //泛型作为方法的参数 public void show(T t) { System.out.println(t); } //3泛型作为方法的返回值 public T getT() { return t; } public static void main(String[] args) { //使用泛型创建对象(此时就不能使用泛型了,要传递给他具体的类型,且必须是引用类型,如果要用基本类型,必须是包装类) GenericDemo01<String> genericDemo01 = new GenericDemo01<>(); genericDemo01.t = "我和你"; genericDemo01.show("大家好"); System.out.println(genericDemo01.getT()); //不同泛型类型对象之间不能相互赋值,这是错误的,为什么也特意提醒一下,因为其它类型之间都可以正常赋值 //GenericDemo01<Integer> my = genericDemo01; } }
运行结果:
泛型接口:
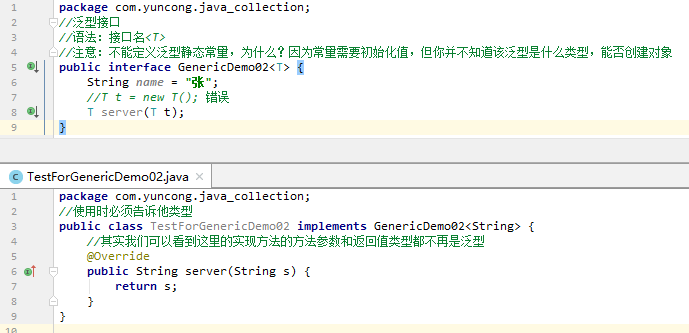
这是使用泛型接口的其中一种方法,也就是某类实现该接口时,就在接口右边明确这个泛型。
还有一种方式是,某类实现该接口,但是接口右侧还是泛型,且类的右侧也是泛型(和接口一样的泛型),然后这个泛型什么时候明确呢?由创建该类的对象时创建。

泛型方法:
package com.yuncong.java_collection; //泛型方法 //语法:<T> 返回值类型 //这里需要解释一下:泛型方法和泛型类与泛型接口不同,泛型放在方法的返回值前面 // //然后这个方法中可以在参数,返回值,方法内(如声明变量,但不能创建对象)使用。 public class GenericDemo03 { //泛型方法 public <T> void show(T t) { System.out.println("泛型方法执行,传入参数是:"+t+"类型为"+t.getClass()); return; } public <T> T read(T t) { System.out.println("泛型方法执行,传入参数是:"+t+"类型为"+t.getClass()); return t; } public static void main(String[] args) { //注意:泛型方法的时候不需要你特意声明泛型的类型,他会根据你传入的方法的类型决定 GenericDemo03 genericDemo03 = new GenericDemo03(); genericDemo03.show(3.14);//其实这里就体现了提高代码重用性的作用 genericDemo03.show(1); genericDemo03.show(new Student(18,"高")); System.out.println(genericDemo03.read(true)); } }
运行结果:
泛型集合
概念:参数化类型、类型安全的集合(可以避免类型转换失败的情况,如果你不设置类型,默认object,你又放了各种类型,万一你失误转错了),强制集合元素的类型必须一致。(这句话有点迷茫哎)
特点:
- 编译时即可检查,而非运行时排除异常。(不太理解)
- 访问时,不必类型转换(拆箱)。(其实我们平时用集合都是确定了泛型,如果没有确定,比如上面我们的代码,此时就默认是Object类型,这时候也有个好处,就是你放什么类型都可以,但好像这样没什么用)
- 不同泛型之间引用不能相互赋值,泛型不存在多态。(这个上面已经提到过)
5.Set接口与实现类
Set子接口
特点:无序、无下标、元素不可重复。
方法:全部继承自Collection中的方法。(也就是说没有自定义方法,因此其遍历方式也只有两种)
HashSet【重点】
- 基于HashCode计算元素存放位置。(基于Hash算法实现位置存放)
- 当存入元素的哈希码相同时,会调用equals进行确认,如果为true,则拒绝后者存入。(在没有重写的情况下,这里equals比较的是引用)
- 存储结果是哈希表,什么是哈希表(数组+链表),其实在JDK1.8后变为(数组+链表+红黑树)
package com.yuncong.java_collection; import java.util.HashSet; //HashSet集合的使用 //存储结构:哈希表(数组+链表),JDK1.8后(数组+链表+红黑树) public class HashSetDemo01 { public static void main(String[] args) { //创建集合 HashSet<Student> students = new HashSet<>(); //1.添加数据 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); students.add(s1); students.add(s2); students.add(s3); students.add(s3);//重复,添加失败 System.out.println("元素个数:"+students.size()); //如果想同名同龄的新new的对象为同一对象,则student类中重写equals方法 students.add(new Student(17, "苦无"));//不同对象,添加成功,但这里是失败的,因为重写了equals方法 //但是当你看到结果的时候,打脸了,已经重写了equals方法,按道理已经是一样了,怎么还添加了??? System.out.println("元素个数:"+students.size()); System.out.println(students); } }
运行结果:
HashSet存储过程:
下面通过存储过程来解决这个疑问
(1)根据hashCode计算保存的位置,如果此位置为空,则直接保存,如果不为空执行第二步。
(2)再执行equals方法,如果equals方法为true,则认为重复,否则,形成链表。
因此为了解决上一个同名同龄也存入进去的问题,需要重写hashcode方法。(即既要重写hashcode方法,也要重写equals方法)
package com.yuncong.java_collection; import java.util.HashSet; //HashSet集合的使用 //存储结构:哈希表(数组+链表),JDK1.8后(数组+链表+红黑树) public class HashSetDemo01 { public static void main(String[] args) { //创建集合 HashSet<Student> students = new HashSet<>(); //1.添加数据 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); students.add(s1); students.add(s2); students.add(s3); students.add(s3);//重复,添加失败 System.out.println("元素个数:"+students.size()); //如果想同名同龄的新new的对象为同一对象,则student类中重写equals方法 students.add(new Student(17, "苦无"));//不同对象,添加成功,但这里是失败的,因为重写了equals方法 //但是当你看到结果的时候,打脸了,已经重写了equals方法,按道理已经是一样了,怎么还添加了??? System.out.println("元素个数:"+students.size()); System.out.println(students); //2.删除操作 students.remove(s1); //这个也会调用hashcode和equals进行删除,最终成功 students.remove(new Student(17, "苦无")); System.out.println(students); //3.遍历【重点】 //3.1使用增强for //3.2使用迭代器 //4.判断 //这个一样会调用hashcode和equals方法 System.out.println(students.contains(new Student(18, "张无忌"))); } }
Student重写方法即运行结果:
如果每次这种情况都重写hashcode和equals方法是不是太麻烦??altr+insert重写(IDEA)
当你用IDEA去重写这两个方法时,可以看到hashcode方法中出现了31,为什么用这个数??1.31是一个质数,减少散列冲突;(2)31提高执行效率 31*i=(i<<5)-i
当然网上也有质疑这个31的,大家了解一下即可。
TreeSet:【基于红黑树数据结构】
- 基于排列顺序实现元素不重复。
- 实现了SortedSet接口,对集合元素自动排序。
- 元素对象的类型必须实现Comparable接口,指定排序规则。
- 通过CompareTo方法确定是否为重复元素。
package com.yuncong.java_collection; import java.util.TreeSet; public class TreeSetDemo01 { public static void main(String[] args) { //创建集合 TreeSet<String> treeSet = new TreeSet<>(); //1.添加元素 treeSet.add("你好"); treeSet.add("我好"); treeSet.add("大家好"); System.out.println(treeSet.toString()); System.out.println("元素个数:"+treeSet.size()); } }
运行结果: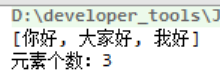
这里插入String是成功了,现在我们插入其它引用类型试试。
package com.yuncong.java_collection; import java.util.TreeSet; public class TreeSetDemo02 { public static void main(String[] args) { //创建集合 TreeSet<Student> treeSet = new TreeSet<>(); //1.添加元素 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); treeSet.add(s1); treeSet.add(s2); treeSet.add(s3); System.out.println(treeSet.toString()); System.out.println("元素个数:"+treeSet.size()); } }
运行结果:
结果显示:类型转换异常,说Student类不能转换成Comparable类型,这是什么鬼??这是说Student必须实现Comparable接口。这是为什么呢?因为TreeSet的数据结构是红黑树,什么是红黑树?
红黑树=二叉排序树(二叉查找树、二叉搜索树)+有红黑两种颜色的标记
二叉排序树:它或者是一棵空树;或者是具有下列性质的二叉树;
- 若左子树不空,则左子树上所有的节点的值均小于它的根节点的值;
- 若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 左、右子树也分别为二叉排序树;
当给你一组数据的时候【3,5,2,1,6】,如何实现二叉排序树??3为第一个元素;然后取出5,5大于3,则放在右子树;取出2,2小于3,则放在左子树;取出1,1小于3,放在左子树,又小于2,放在其左子树;取出6,6大于3,放在右子树,又大于5,放在5的右子树。
而红黑树是二叉排序树+有颜色的标记(为了平衡,防止一边元素过重),因此要实现排序,对于String类型而言,里面已经实现了排序,即实现了Comparable接口(该接口是泛型的,里面仅有一个方法),但是Student类没有,请问用他来排序,是拿什么排序?拿内存地址?年龄?姓名?不确定,因此要让其实现Comparable接口后才能放入TreeSet集合中。


package com.yuncong.java_collection; import java.util.TreeSet; //使用TreeSet保存数据 //存储结果:红黑树 //要求:元素必须要实现Comparable接口,compareTo()方法返回值为0,认为是重复元素,则不能添加 public class TreeSetDemo02 { public static void main(String[] args) { //创建集合 TreeSet<Student> treeSet = new TreeSet<>(); //1.添加元素 Student s1 = new Student(22,"张三丰"); Student s2 = new Student(18, "张无忌"); Student s3 = new Student(17, "苦无"); treeSet.add(s1); treeSet.add(s2); treeSet.add(s3); treeSet.add(new Student(17, "苦无")); System.out.println(treeSet.toString()); System.out.println("元素个数:"+treeSet.size()); //2.删除 treeSet.remove(s3); //这个删除就是一句compareTo方法去做的 treeSet.remove(new Student(18, "张无忌")); System.out.println("删除后元素个数:"+treeSet.size()); //3.遍历(对于Set接口,只有两种遍历方式) //3.1增强for循环 //3.2使用迭代器 //4.判断 //也是根据comparableTo来比较 System.out.println(treeSet.contains(new Student(22,"张三丰"))); } }
运行结果:
补充Compatator接口的使用
package com.yuncong.java_collection; import java.util.Comparator; import java.util.TreeSet; //使用TreeSet保存数据 //Comparator:是按定制比较(比较器) //优势,或者说作用,其实与上一个Comparable相比,都是比较,那什么还要又这个? public class TreeSetDemo03 { public static void main(String[] args) { //创建集合 TreeSet<Student> treeSet = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int n1 = o1.getAge() - o2.getAge(); int n2 = o1.getName().compareTo(o2.getName()); return n1 == 0? n2:n1; } }); } }
上面的实现Comparable接口不就可以实现比较了吗?为什么这里还要有这个接口??不是多此一举吗??
当然不是的,这个接口是用在原有类不能更改,或者说无法更改的情况下,自己在创建TreeSet对象时传入比较方法。你可能会问,类不都是我自己写的吗?还有不能改的,骚年,是你年龄太小,以后就知道了。
案例:
用过TreeSet集合实现字符串按照长度进行排序。
package com.yuncong.java_collection; import java.util.Comparator; import java.util.TreeSet; //要求:使用TreeSet集合实现字符串按照长度进行排序 public class TestForTreeSet { public static void main(String[] args) { String[] res = sortByLengthForStringArray(new String[]{"he","h","hello1","111","11"}); for (String re : res) { System.out.println(re); } } public static String[] sortByLengthForStringArray(String[] arrs){ TreeSet<String> set = new TreeSet<>(new Comparator<String>() { @Override public int compare(String o1, String o2) { int n1 = o1.length() - o2.length(); int n2 = o1.compareTo(o2); return n1==0?n2:n1; } }); for (String arr : arrs) { set.add(arr); } int index = 0; for (String s : set) { arrs[index++] = s; } return arrs; } }
运行结果: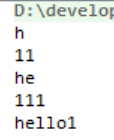
这道题同样也说明了Comparator接口的优先级更高,什么意思呢?如果一个类实现了Comparable接口,将其放入TreeSet集合时又传入了Comparator接口,则会按后者执行。
6.Map接口与实现类
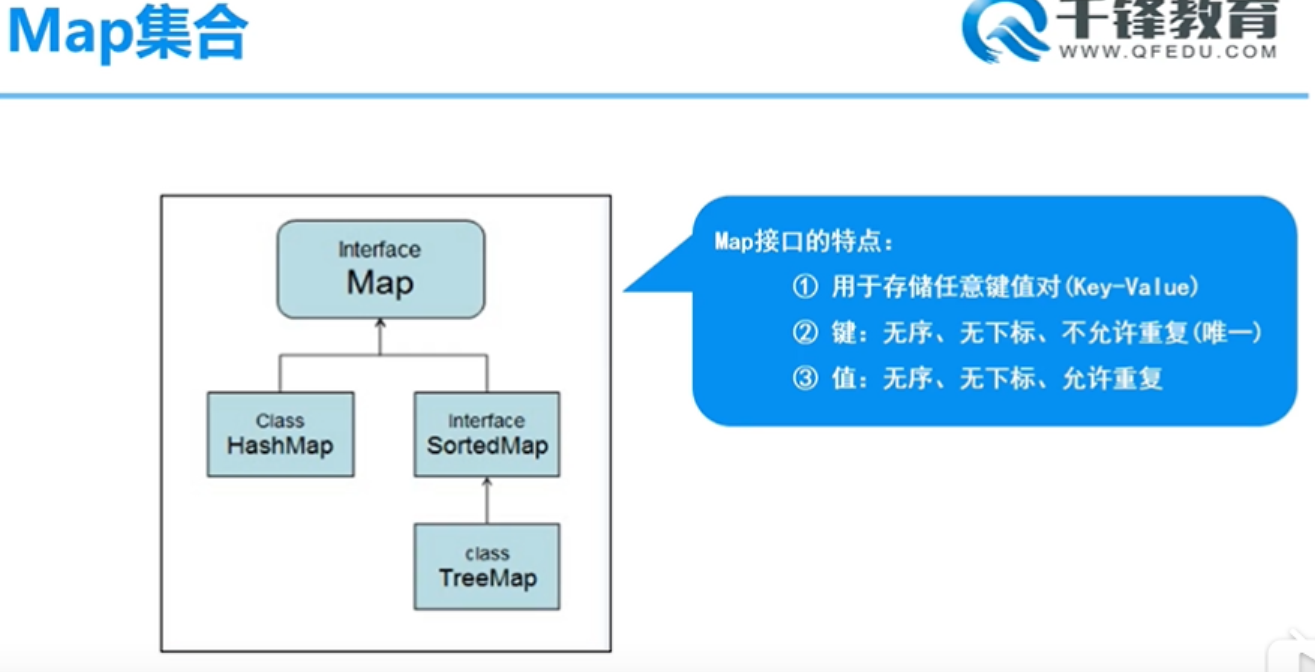
Map父接口(遍历方法有两种,一种是keySet,一种是EntrySet)
特点:村粗一堆数据。无序、无下标,键不可重复。
方法:
- V put(K key,V value); //将对象存入到集合中,关联键值。key重复则覆盖原值。
- Object get(Object key); //根据键获取对应的值
- keySet(K); //返回所有key。
- Collection<V> values(); //返回包含所有值的Collection集合。
- Set<Map,Entry<K,V>>; //键值匹配的Set集合。
Map集合的实现类
HashMap【重点】
- JDK1.2版本,线程不安全,运行效率快;允许用null作为key或是value。
Hashtable:
- JDK1.0版本,线程安全,运行效率慢,不允许null作为key或是value。
Properties:
- Hashtable的子类,要求key和value都是String。通常用于配置文件的读取。
TreeMap:
- 实现了SortedMap接口(是Map的子接口),可以对key自动排序。
HashMap
package com.yuncong.java_collection; import java.util.HashMap; //HashMap集合的使用 //存储结果:哈希表(数组+链表),在JDK1.8之后为(数组+链表+红黑树) //使用key的hashcode和equals方法作为重复的依据 public class HashMapDemo01 { public static void main(String[] args) { //创建集合 HashMap<Person,String> hashMap = new HashMap<>(); //1.添加元素 Person p1 = new Person("唐僧", 13); Person p2 = new Person("猪八戒", 14); Person p3 = new Person("悟空", 18); hashMap.put(p1,"北京"); hashMap.put(p2,"上海"); hashMap.put(p3,"杭州"); hashMap.put(p3,"驻马店"); hashMap.put(new Person("悟空", 18),"扬州"); System.out.println("元素个数:"+hashMap.size()); } }
运行结果:元素个数:4
这说明添加new的对象成功,这是为什么呢?其是使用key值的hashcode和equals作为重复依据,如果想让new出来的新同名同龄对象一样,则要重写这两个方法(可以用IDEA的快捷键重写)
重写后:
package com.yuncong.java_collection; import java.util.HashMap; import java.util.Map; //HashMap集合的使用 //存储结果:哈希表(数组+链表),在JDK1.8之后为(数组+链表+红黑树) //使用key的hashcode和equals方法作为重复的依据 public class HashMapDemo01 { public static void main(String[] args) { //创建集合 HashMap<Person,String> hashMap = new HashMap<>(); //1.添加元素 Person p1 = new Person("唐僧", 13); Person p2 = new Person("猪八戒", 14); Person p3 = new Person("悟空", 18); hashMap.put(p1,"北京"); hashMap.put(p2,"上海"); hashMap.put(p3,"杭州"); hashMap.put(p3,"驻马店"); hashMap.put(new Person("悟空", 18),"扬州"); System.out.println("元素个数:"+hashMap.size()); //2.删除 hashMap.remove(p3); System.out.println("删除之后元素个数:"+hashMap.size()); //3.遍历 //3.1使用keySet for (Person key : hashMap.keySet()) { System.out.println(key.toString()+"========="+hashMap.get(key)); } //3.2使用entrySet for (Map.Entry<Person, String> entry : hashMap.entrySet()) { System.out.println(entry.getKey()+"=========="+entry.getValue()); } //4.判断 System.out.println(hashMap.containsKey(new Person("唐僧", 13))); System.out.println(hashMap.containsValue("上海")); } }
运行结果:
源码分析


之前没有讲HashSet的源码,其实其底层用的就是HashMap的key。
Hashtable
其底层还是哈希表,即数组+链表,没有像HashMap一样在JDK1.8后修改为数组+链表+红黑树的形式。因为这个类不怎么用了。
这个类是在JDK1.0版本就有的,线程安全,效率慢,我们已经不用了,但是这个类有一个子类Properties(这个类和流有着紧密关系),我们还是会用的。
Properties:
- Hashtable的子类,要求key和value都是String。通常用于配置文件的读取。这个在流之后更加详细的讲解。
TreeMap(底层是红黑树结构)
package com.yuncong.java_collection; import java.util.TreeMap; //底层是红黑树,因此要排序 public class TreeMapDemo01 { public static void main(String[] args) { //创建集合 TreeMap<Person, String> treeMap = new TreeMap<>(); //1.添加元素 Person p1 = new Person("唐僧", 13); Person p2 = new Person("猪八戒", 14); Person p3 = new Person("悟空", 18); treeMap.put(p1,"北京"); treeMap.put(p2,"上海"); treeMap.put(p3,"杭州"); treeMap.put(p3,"驻马店"); System.out.println("元素个数:"+treeMap.size()); System.out.println(treeMap.toString()); } }
运行结果:
因此运用TreeMap和TreeSet时,如果存放自定义类型,要实现Comparable接口,或者传入比较对象。
package com.yuncong.java_collection; import java.util.Comparator; import java.util.Map; import java.util.TreeMap; //底层是红黑树,因此要排序 public class TreeMapDemo01 { public static void main(String[] args) { //创建集合 TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { int n1 = o1.getName().compareTo(o2.getName()); int n2 = o1.getAge() - o2.getAge(); return n1==0?n2:n1; } }); //1.添加元素 Person p1 = new Person("唐僧", 13); Person p2 = new Person("猪八戒", 14); Person p3 = new Person("悟空", 18); treeMap.put(p1,"北京"); treeMap.put(p2,"上海"); treeMap.put(p3,"杭州"); treeMap.put(p3,"驻马店"); System.out.println("元素个数:"+treeMap.size()); System.out.println(treeMap.toString()); //2.删除 treeMap.remove(new Person("悟空", 18)); treeMap.remove(p2); System.out.println("删除后元素个数:"+treeMap.size()); //3.遍历 //3.1使用keyset for (Person person : treeMap.keySet()) { System.out.println(person+"========="+treeMap.get(person)); } //3.2使用entrySet for (Map.Entry<Person, String> entry : treeMap.entrySet()) { System.out.println(entry.getKey()+"========"+entry.getValue()); } //4.判断 System.out.println(treeMap.containsKey(p1)); System.out.println(treeMap.containsKey(new Person("唐僧", 13))); } }
运行结果:
TreeMap与TreeSet的关系,通过源码发现,其实TreeSet底层用的就是TreeMap的key。换句话说TreeSet这个类就是在维护一个TreeMap类,用的是该类的key集合。
Collections工具类
概念:集合工具类,定义了除了存取以外的集合常用方法。(之前我们学过Arrays,其是对数组进行操作的,现在这个是对集合进行操作的)
方法:
- public static void reverse(List<?> list); //反转集合中元素的顺序
- public static void shuffle(List<?> list); //随机重置集合元素的顺序
- public static void sort(List<T> list); //升序排序(元素类型必须实现Comparable接口)
package com.yuncong.java_collection; import java.util.ArrayList; import java.util.Collections; import java.util.List; //Collections工具类的使用 public class CollectionsDemo01 { public static void main(String[] args) { //Integer内部实现了Comparable接口 List<Integer> list = new ArrayList<>(); list.add(20); list.add(5); list.add(12); list.add(30); list.add(6); //sort排序 System.out.println("排序前:"+list.toString()); Collections.sort(list);//你也可以自定义排序规格 System.out.println("排序后:"+list.toString()); //binarySearch,二分查找,这个要求该集合必须已经排好序,查到返回下标,找不到返回-4 System.out.println(Collections.binarySearch(list,12)); System.out.println(Collections.binarySearch(list,14)); //copy复制 List<Integer> dest = new ArrayList<>(); Collections.copy(dest,list); } }
运行结果:
这个方法设计不是很好,它要求你复制的对象和被复制的对象大小必须一样,这里list长度是5,而dest是新建的,长度是0,因此失败。这设计的岂不是很差,毕竟是不定长,怎么这么设计。
修改后:
package com.yuncong.java_collection; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List; //Collections工具类的使用 public class CollectionsDemo01 { public static void main(String[] args) { //Integer内部实现了Comparable接口 List<Integer> list = new ArrayList<>(); list.add(20); list.add(5); list.add(12); list.add(30); list.add(6); //sort排序 System.out.println("排序前:"+list.toString()); Collections.sort(list);//你也可以自定义排序规格 System.out.println("排序后:"+list.toString()); //binarySearch,二分查找,这个要求该集合必须已经排好序,查到返回下标,找不到返回-4 System.out.println(Collections.binarySearch(list,12)); System.out.println(Collections.binarySearch(list,14)); //copy复制 List<Integer> dest = new ArrayList<>(); for (int i = 0; i < list.size(); i++) { dest.add(0); } Collections.copy(dest,list); System.out.println(dest.toString()); //reverse反转 Collections.reverse(list); System.out.println("反转之后:"+list); //shuffle 打乱 Collections.shuffle(list); System.out.println("打乱之后:"+list); //补充!!!!! //补充:list转成数组 System.out.println("-------list转成数组--------"); //这里传入的参数,0是数组长度,其实你传几都可以,当传入小于长度是,自动变为集合长度,当大于时,后面就是null了 //因此一般传入0,这样能保证数组长度和集合长度一定相同。 Integer[] array = list.toArray(new Integer[0]); System.out.println(array.length); System.out.println(array.toString()); System.out.println(Arrays.toString(array)); //数组转成集合 System.out.println("-------数组转成集合-------"); String[] names = {"张三","李四","王五","赵六"}; //但是请注意:数组转成的集合是一个受限的集合,不能添加和删除,会报错 List<String> asList = Arrays.asList(names); System.out.println(asList); //这里还有一个小问题,基本类型数据数组转成集合的时候,这个数组可用int定义,也可用Integer,但是写法有点不一样 int[] nums = {1,2,3,4,5}; List<int[]> ints = Arrays.asList(nums);//多了[] System.out.println(ints);//且list里面的每一个元素都是一个int数组 Integer[] nums2 = {1,2,3,4,5};//建议 List<Integer> integers = Arrays.asList(nums2); System.out.println(integers); } }
运行结果:
集合总结:

LinkedHashSet具有可预测的迭代顺序,也就是我们插入的顺序,其是线程不安全的。

