SQL基础随记1 SQL分类 常用函数 ALL ANY EXISTS IN 约束
SQL基础随记1 SQL分类 常用函数 ALL ANY EXISTS IN 约束
其实这里知识不难,只是好久不接触突然被问的话有时还真的一时答不上,自己写一遍胜过盲扫。当然,也有些常读常新的地方会记录下来。
对SQL语言进行划分
DDL --- Data Definition Language --- 定义 --- 增删改数据库和表的结构
create alter drop comment(注释) truncate(删除)
DML --- Data Manipulation Language --- 操作 --- 对记录增删改
insert update delete
DQL --- Data Quary Language --- 查询 --- 对记录进行查询
select from where group by having order by limit
DCL --- Data Control Language --- 控制 --- 访问权限和安全规则
commit rollback set transaction grant revoke
要是要突然问的话有时还真的一时回答不上,记住单词胜过记缩写
DBMS的分类
- 关系型
- 行存储 --- MySQL
- NosQL
- 键值型 --- Redis
- 文档型 --- MongoDB
- 搜索引擎 --- Elasticsearch
- 列存储(列族数据库)
- 图形数据库
-
列存储数据库说是“可以降低系统的I/O,但功能相对有限”,不过我看到了一段有意思的话觉得很有道理

列存储常见于分布式文件系统,如Hbase
-
图(这种数据结构)存储了实体(对象)之间的关系。以最典型的人与人社交关系为例,其数据模型主要是以节点和边来实现。特点在于可以有效解决复杂的关系问题。
DDL
-
创建表时可以在
create table tableName (...)后面追加参数,可以追加的有-
engine = InnoDB
-
CHARACTER SET = utf8 COLLATE = utf8_general_ci其中
CHARACTER SET是指定字符编码,COLLATE是指定排序规则。且utf8_general_ci是对大小写不敏感,对大小写敏感是utf8_bin在定义varchar()类型字段的时候也可以后缀
CHARACTER SET = xxx COLLATE = yyy
-
-
在创建索引的时候我们可以选择不同类型的索引(UNIQUE INDEX --- 唯一索引 或 NORMAL INDEX --- 普通索引)以及不同的索引方式(BTREE 或 HASH),如
CREATE TABLE XXX( ... UNNIQUE INDEX indexName (字段名) USING BTREE ... )索引分为单列索引和组合索引,组合即一个索引可以包含多个列
-
约束
- 主键,可以是一个字段也可以是多个字段
- 外键
- UNIQUE (唯一性)约束,
- NOT NULL 约束
- DEFAULT 约束,在插入记录时如果该字段为空,那么就会设置为默认值。(而不是“不变量”的意思,它仍然可变)
- CHECK 约束 (MySQL8.0.16后版本支持)
-
理论上设计数据表的“三少一多”原则
-
表个数少
-
表中字段少
-
联合主键字段少
-
主键和外键多
表的设计核心就是简单可复用,主键是一张表的代表,因此主键外键越多,说明表之间的利用率最高。
但这个原则不是绝对的,因为有时我们需要牺牲数据的冗余度来换取处理数据的效率,毕竟join总是会造成复杂。
另外在大型项目中,大量的更新以及高并发的情况下,外键会造成额外的开销,也容易造成死锁。因此在业务量较大时,可以采用在业务层实现,取消外键来提高效率。因此在实际生产中为了方便维护基本不使用外键。
另外也不推荐使用自增长主键,不利于维护。例如银行一般使用
唯一表示字段uuid+日期+渠道流水(unique index)来保证数据唯一性。 -
修改字段类型不要忘记
COLUMNALTER TABLE tableName MODIFY COLUMN newName type;修改字段名
ALTER TABLE tableName CHANGE oldName newName type;修改大表字段需要谨慎 容易引发表结构写锁。(0623)
-
DQL随记
-
发现一个有趣的新用法 --- 在查询时插入临时列
使用单引号可以将单引号中内容作为定值,然后在查询中临时加入该列(临时意味着并不改变表的结构,仅在返回时临时插入)
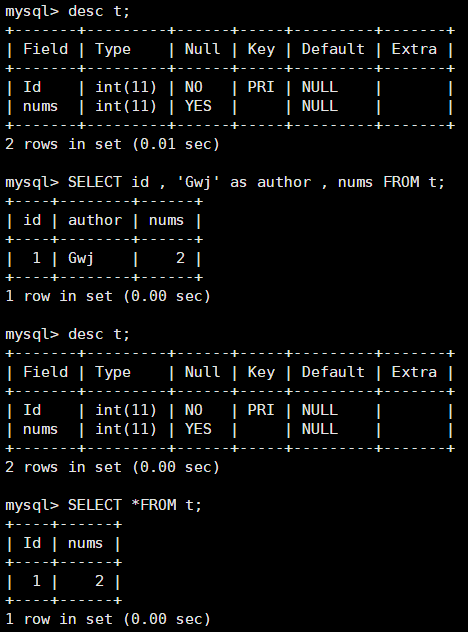
-
Order by 后有多个列时,会先按照第一个列进行排序,如果第一列的值相同,则会根据第二列进行排序,以此类推。
-
select 语句的关键词顺序(很基础的还是默一遍吧)
SELECT...(DISTINCT)...FROM...WHERE...GROUP BY...HAVING...ORDER BY...LIMIT -
select 语句执行顺序 (0624)
先找表再分组再排序;分组前WHERE分组后HAVING;排序前SELECT+DISTINCT,排序后LIMIT
FROM WHERE GROUP BY HAVING SELECT+DISTINCT ORDER BY LIMIT
-
BETWEEN AND 的边界值
-
对于数值,包含左右边界
-
对于data类型,查询时不带分秒,包含左右边界
-
对于datatime类型,查询时不带分秒,只包含左边界。
因为只查询yyyy-MM-DD时,默认将时分秒设置为00:00:00,即在右边界的日期一开始的时候就会停止查询,遂不包含右边界。
-
-
少见的运算符号
-
REGEXP --- 正则表达式(RegExp)--- SELECT REGEXP
-
<=> --- SELECT a<=>b FROM ... --- 当a,b都为NULL时返回1,否则返回0
<=>与=不同的是,当a,b都为null时 a<=>b 返回 1 a=b 返回 null
-
- 通配符 % 是匹配 大于等于0个任意数量的字符
SQL常用函数
算术函数
- ABS() --- 取绝对值
- MOD(a,b) --- 取余,a%b的余数
- ROUND(a,b) --- 四舍五入保留位数,保留b位小数
字符串函数
-
CONCAT("a",b) --- 拼接字符串,a必须有单引号或者双引号,后面的可以没有,在MySQL中可以连接多个字符串
-
LENGTH(“a”) --- 返回字符串a的长度,中文占三个字符
CHAR_LENGTH() --- 返回字符串的长度,中文也只算一个字符
-
LOWER(),UPPER()
-
REPALCE("要被替换的字符串","要替换的部分","替换内容")
SELECT REPLACE("CIVILAZATION","IVILAZATION",LOWER("IVILAZATION"));返回
+------------------------------------------------------------+ | REPLACE("CIVILAZATION","IVILAZATION",LOWER("IVILAZATION")) | +------------------------------------------------------------+ | Civilazation | +------------------------------------------------------------+ 1 row in set (0.00 sec) -
SUBSTRING ("要被截取的字符串",开始截取的位置,截取长度)
截取位置的第一位从1开始
每个中文汉字也只占一个长度
时间函数
-
当前时间
-
CURRENT_DATE -
CURRENT_TIME -
CURRENT_TIMESTAMP--- (时间戳)具体从年到秒的时间 -
EXTRACT(xxx FROM (符合格式的时间或者函数))
mysql> SELECT EXTRACT(YEAR FROM CURRENT_TIMESTAMP); +--------------------------------------+ | EXTRACT(YEAR FROM CURRENT_TIMESTAMP) | +--------------------------------------+ | 2020 | +--------------------------------------+ 1 row in set (0.00 sec)
-
-
上面的
xxx可以用下列函数的名称替换 YEAR()、MONTH()、DAY()、HOUR()、MINUTE()、SECOND()
-
DATE()
转换函数
-
CAST(),目标类型可以是以下类型之一:
BINARY,CHAR,DATE,DATETIME,TIME,DECIMAL,SIGNED,UNSIGNED。mysql> SELECT CONCAT('Your num is ',CAST(7 as char)); +----------------------------------------+ | CONCAT('Your num is ',CAST(7 as char)) | +----------------------------------------+ | Your num is 7 | +----------------------------------------+ 1 row in set (0.00 sec) -
CONVERT(字段名/字符串 as 字符集名)
用于转换字符集
-
COALESCE(),返回参数中第一个非空返回值
mysql> SELECT COALESCE(NULL, NULL, NULL, 'Google', NULL, 'baidu'); +-----------------------------------------------------+ | COALESCE(NULL, NULL, NULL, 'Google', NULL, 'baidu') | +-----------------------------------------------------+ | Google | +-----------------------------------------------------+ 1 row in set (0.00 sec)
忽略NULL
-
COUNT(*) 只统计行数,无论某行中某些字段是否为null
COUNT(字段)时会忽略
字段值为NULL的行,只统计字段值不为NULL的行的总数 -
AVG(),MAX(),MIN() 也会忽略为NULL的数据行
- MAX(),MIN() 也可以对字符串类型进行统计,按照英文或汉语字母顺序从前到后,越向后越大
ANY ALL
- any是
只要满足任何一个子查询的返回值&&满足比较条件就返回结果。some是any的别名 - all是
只有满足所有子查询的返回值&&满足比较条件才返回结果
EXISTS IN
-
EXISTS 和IN 很相似,使用IN时要提起写出字段,因此适合在知道去哪个字段里查询时使用
-
in是先执行子查询并得到一个结果集,再将结果集带入外层谓词条件。子查询只进行一次。
EXISTS是先取一条主查询中的数据,再将数据带入并执行一次子查询。主查询有多少数据子查询就会进行多少次。
-
因为in和exists的查询机制,为了效率,外表数据量大使用in,外表数据量小使用exists
即
小表驱动大表#现有A,B两表, SELECT * FROM A WHERE columnA IN (SELECT columnA FROM B); SELECT * FROM A WHERE columnA EXISTS (SELECT columnA FROM B WHERE B.columnA=A.columnA);假如A表大于B表,使用IN较好,因为IN先使用的是较小的表B
假如A表小于B表,使用EXISTS较好,因为EXISTS先使用的是较小的表A
-
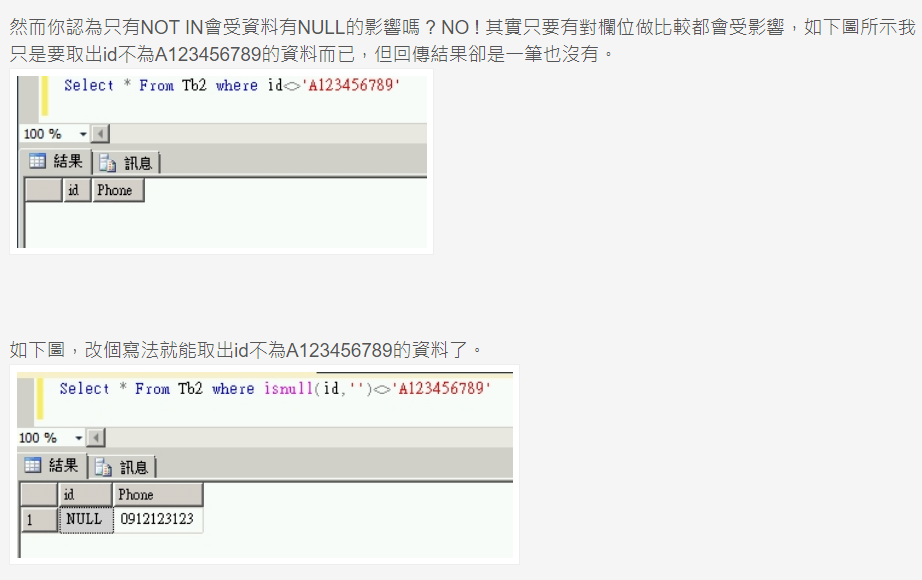
NOT EXISTS 与 NOT IN 之间最好使用 NOT EXIST 或者是 NOT IN ( ... IS NOT NULL)
因为NULL值是无法被比较的,IN在先执行子查询时可能会过滤掉有null值得那一行
當一句Where id not in('A123456789','B123456789')執行時其實就是跟 Where id<>'A123456789' and id<>'B123456789' 是一樣的。而用and就是要所有條件都是True才會是True,只要有一個條件不成立就會是False。因此當比對的欄位有NULL時(例 : Where id<>'A123456789' and id<>NULL),而NULL是不能比較的,因此id<>NULL會判斷是False。一但有一條件是回傳False,那整個Where條件式就是False了,因此這一筆資料就會被認為是不符合的。
具体案例可见此处
NULL对NOT IN的影响本质上是对SELECT子查询的影响,因此在select查询时也要注意
- MySQL不支持全外连接 (0625)
随记2
