第一单元总结:基于基础语言、继承和接口的简单OOP
前情提要
到目前为止,OO课程已经完成了前三次的作业,分别为:
- 第一次作业:简单多项式的构造和求导。【正则表达式】【数据结构】【排序】
- 第二次作业:含三角函数因子的复杂多项式的构造、求导和化简。【递归下降】【DFS】
- 第三次作业:含嵌套因子的复杂式的构造、求导和化简。【递归下降】【抽象类】【接口】【递归】
第一次作业
功能介绍
对某种格式的多项式进行parsing,之后计算其导数,按相同格式输出。
多项式由项组成,项有且仅有系数和x的幂。不存在多于两个因子的项。
类图
程序的大致结构如下图:

第一次作业程序结构比较简单,Main中构造一个Poly对象,Polynomial由Item聚合而成。
代码分析

可以看出,除了Polynomial类的构造函数,其他的方法的复杂度均不高。
而造成其构造函数复杂度稍高的原因是在不断parsing的时候需要一定的分支、循环等逻辑。
虽然该构造函数仅有不到23行,但是当逻辑进一步复杂的时候,不如将循环体内部的一些操作移出到一个类似工厂的小静态方法中。
测试与Bug
公测
不出意外,笔者的程序在公测阶段没有出现任何错误。
互测
不出意外,笔者的程序在互测阶段没有出现任何错误。
在互测中,笔者challenge中了同屋的5个数据点。其中有一个是当自己在刚开始写程序时,同时手造的数据,为了验证自己程序的正确性;其他的数据点均为数据生成器和对拍器发现的bug点。
在手造数据时,应该仔细针对输入格式说明,从基础的元件(如幂函数部分:x还是x^;x^后面的数是有符号还是无符号,是正是负)开始,逐步向上构造用例,使用“乘法原理”将不同的情况组合起来。
Bug分析与总结
- 正则中的"\s"是匹配所有空白字符,并不只有tab和space。
- Java的trim()是去掉所有ASCII码比space小的字符,因此可能会将其他不期望的空白字符一并去掉,在使用时应该注意。
- 使用正则表达式尝试完全匹配一个超长的字符串是慢且有爆栈可能性的,应该将重复的特征提取出来,并手动while()一段一段地匹配。
第二次作业
功能介绍
对含有sin(x)和cos(x)(及其幂)的多项式进行parsing,之后计算其导数,按相同格式输出。
多项式由项组成,项有且仅有系数、x的幂、sin(x)的幂和cos(x)的幂。每个项的因子数不定,类型不定,类型顺序不定、可重复。
类图
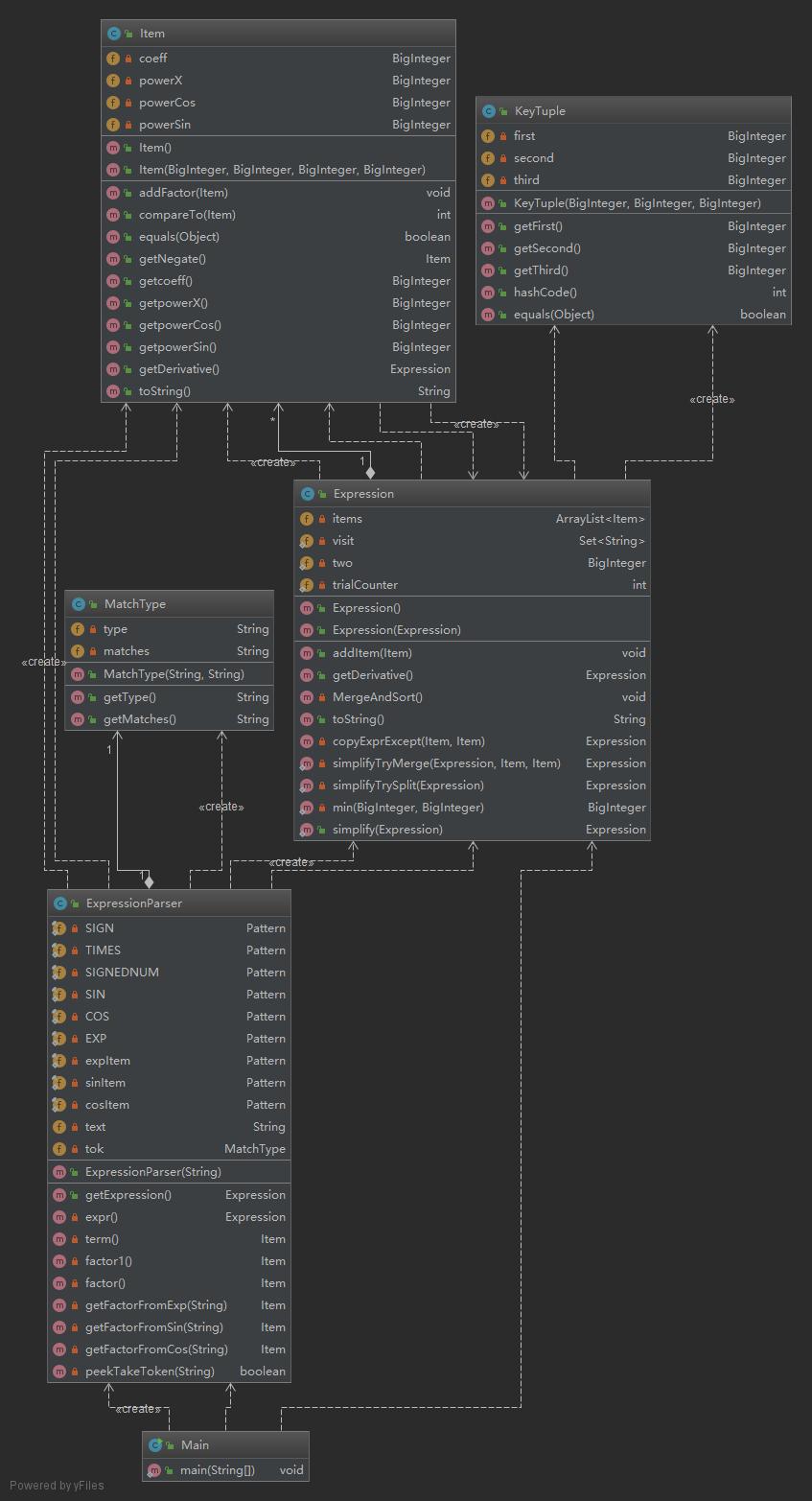
可以看出,第二次作业的代码结构复杂了许多。
Main调用ExpressionParser得到生产出的Expression。Expression由Item聚合而成。
除此之外,ExpressionParser还使用了辅助其进行递归下降的MatchType类;Expression还使用了辅助其进行合并同类项的Tuple类。这两个类较为独立,只执行很小的工作,与程序的主体耦合性很低。
代码分析
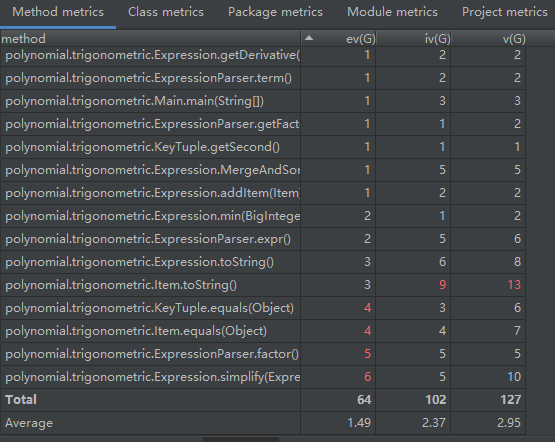
(篇幅所限,部分复杂度极低的方法在图中已隐去,现在只讨论复杂度高的方法实现。)
不出意外,Item.toString()方法、Parser.factor()和Expression.simplify()方法的复杂度较高。下面对其逐一分析:
- Item.toString()方法和ExpressionParser.factor()方法:
由于比较懒(因为可以直接套公式求导,就直接在Item里面存了4类因子的指数/系数),这样四种因子就没有设计独立的类,就导致了以下两个潜在的问题:- 1. 在Item的toString()方法和ExpressionParser的factor()方法中,需要同时对4种因子逐一进行处理。这意味着需要至少4个功能相似的if语句,再将不同的factor组合起来。
不如将其分散到4个独立的方法中,或者真的建立4个factor类的子类,将其单独管理。 - 2. 可扩展性差,在第三次作业中需要重构。
- 1. 在Item的toString()方法和ExpressionParser的factor()方法中,需要同时对4种因子逐一进行处理。这意味着需要至少4个功能相似的if语句,再将不同的factor组合起来。
- Expression.simplify()方法:
层次混乱、自己和其调用的子函数的功能分界不明晰。
思考后,不如这样总结:
在一个方法中,应该首先按“功能的基本单元”对其任务进行划分。对于并列 / 有先后顺序依赖的层级关系,应当将子任务剥离到子函数中,再在本方法中进行并列 / 顺序的组合。
【本方法的核心任务是组合不同任务的执行结果,而不是首先执行不同的子任务再组合它们。该提取的就要提取。】
测试与Bug
公测
不出意外,笔者的程序在公测阶段没有出现任何错误。
互测
不出意外,笔者的程序在互测阶段被challenge了一个TLE的点。
TLE的原因为,在尝试进行输出化简时,对过多的DFS分支进行了遍历,没有控制好尝试的次数因子。
而事实上,往往尝试300次就可以得到(公测条件下的)最优解,而笔者为了一点小小的性能分贪心地设置多了一点尝试的次数(分支数),最终导致了T。
在互测中,笔者challenge中了同屋的5个数据点。这5个数据点均为数据生成器和对拍器对拍发现的bug。其中大部分为相同的化简导致的TLE。
Bug分析与总结
- 在互测中,笔者challenge了同屋的一个正则表达式匹配错误。
这个bug很神奇:在jdk8下会TLE,而在jdk10下将会秒过。
记得当时查到一篇文章(现在找不到了QAQ)说,java8中一些设计丑陋的正则表达式在回溯时将会疯狂的吃时间。而巧合的是,这次作业中的这个同学,同样的是想用一个完整的正则表达式去匹配一个完整的字符串。
这里引用一下学长的话:
“第一次据笔者观察,很多同学还对java这门语言完全处于不熟悉的状态,对于正则表达式等概念及其具体原理也完全不了解,更不用说面向对象的设计思想了。据笔者所知,像这样试图用一个庞大的正则表达式判断格式的同学并不在少数。然而了解正则表达式相关原理的同学都应该清楚,正则表达式不是让你这么用的。正则表达式更多的用于相对简单且没有复杂的重复和嵌套的一些的模式匹配,以及其内部关键位置信息的提取。”
这里的话就很精髓:正则表达式是为了我们提取匹配串中的特定位置的信息的工具,常用于检查如输入表单的合法性,提取URL、数字串、时间日期,或者类似于提取特定标签内的内容等工作。
而处理含有复杂的语法规则的、拥有许多分支的类似“代码”的串,并不是正则表达式的真正用武之地。
无论这个bug是不是java8的锅,笔者认为到了第二次作业还想用大正则判断合法性的想法,是不可取的。(可能仅仅是因为长度只有100,很多人才摸过一劫) - 在互测中,笔者还challenge了另外一个同学的"\u0010"bug。
这个bug,说实话可能会被认为很无聊。但是这位同学写的其实是:如果输入串contains “\f” "\v",就throw WrongFormatException。否则就认为不含有非法空白字符。
这样的对输入情况的特判,是极其没有鲁棒性的。同时这也提醒我们,在所有的分支逻辑处,都一定要思考清楚自己在干什么、程序在干什么,有没有把该覆盖的情况覆盖全。
第三次作业
功能介绍
对含有嵌套的复杂表达式进行parsing,之后计算其导数,按相同格式输出。
可推出如下形式的递归下降文法:
expr ::= SIGN? term { SIGN term }*
term ::= SIGN? factor { TIMES factor }*
factor ::= SIGNEDNUM | x^SIGNEDNUM | SIN(factor)^SIGNEDNUM | COS(factor)^SIGNEDNUM | (expr)
类图(只显示继承、实现等关系)
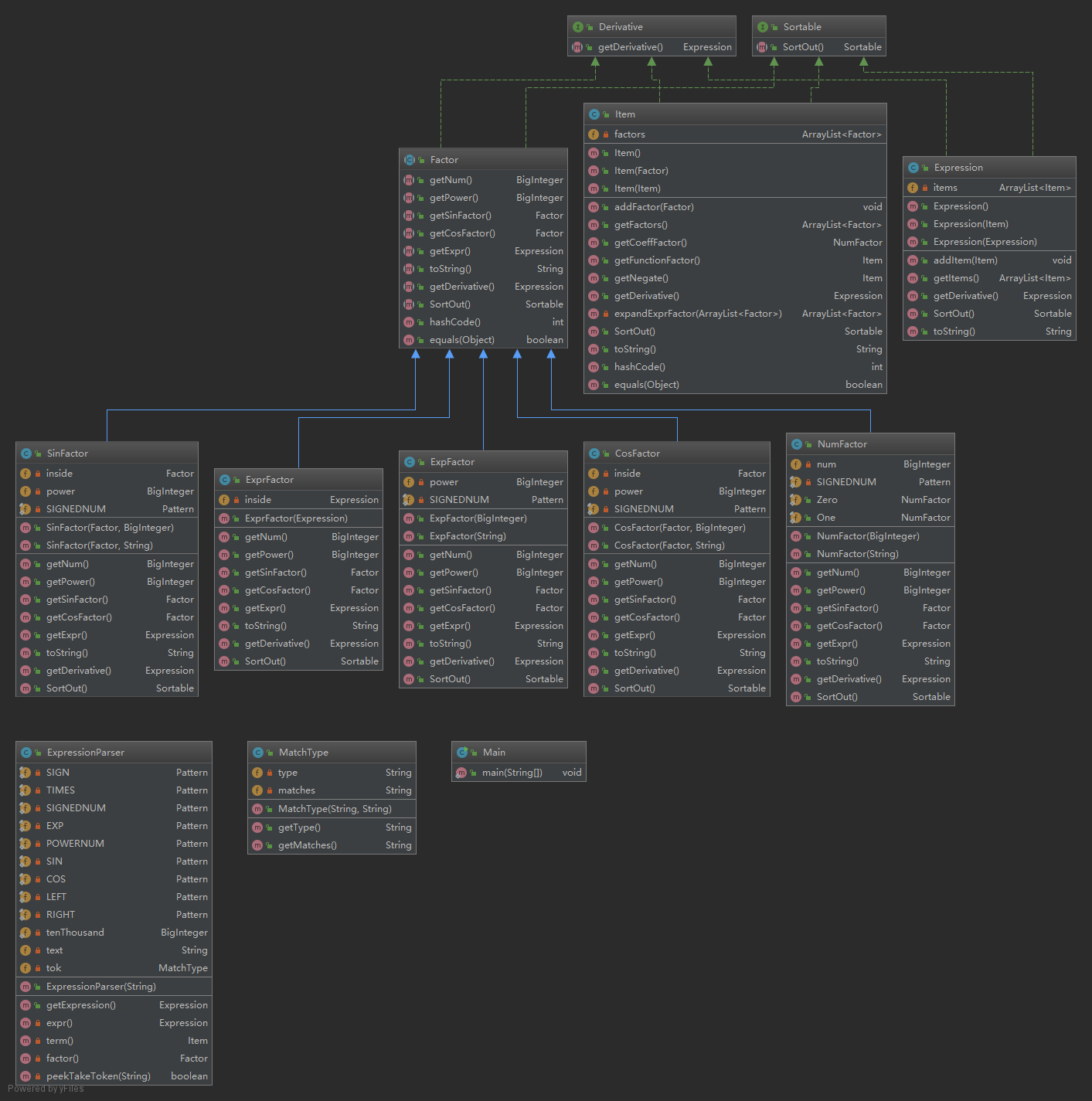
第三次作业经过第二次作业的大修,终于将Item与Factor分离,设定了抽象类Factor,并继承了数字、幂函数、三角嵌套函数、表达式因子等5种具体因子类。
同时,实现了Sortable接口,用于化简时利用多态更易处理。
注意到,定义和实现的Derivative接口实际上是一个假接口,其与Sortable接口不同:
- SortOut()方法的返回值不定,比如ExprFactor.Sortout()的返回值并不一定是ExprFactor类型,
其可以是Expression类型、Item类型和其他Factor类型。使用接口则方便了许多,只需要将返回值声明成Sortable类型; - 然而getDerivative()方法的返回值在不同类中均是确定的,不需要进行多态处理。
同时,在循环中调用getDerivative()方法时的this对象的类型也是确定的(因为Expression的List必是Item,Item的List必是Factor),这样设计下接口的意义仅仅是“确保大家都实现了getDerivative方法”。
这样的接口毫无意义,是为了设计而设计;或者说,不如将其与Sortable接口合并。这样虽然现在没有用,但是在以后的拓展性也还能保持。
代码分析

(篇幅所限,部分复杂度极低的方法在图中已隐去,现在只讨论复杂度高的方法实现。)
很遗憾,在补充第二次作业的递归下降Parser的时候,笔者仍然菜到没有将5种因子分别从Parser.factor()中剥离出去,才导致了metric分析出来方法三项指标都爆炸。
这样不但导致了单方法的复杂度过高,还使其可拓展性、可维护性大大降低(试想如果今后加入更多种的因子,该方法将会变的冗长且有很多重复部分。)
而几个equals()方法被判定ev过高是因为笔者采取了先判断引用再判断null再判断同类、最后再判断内部对象的写法(从《Java核心技术》学来的),就会有三四个if,个人认为问题不大。
而两个SortOut()方法的复杂度过高的主要原因为,要分别针对5种factor进行处理,然而处理中需要用到该方法的局部变量,所以就没有将其下放的factor类中,或者是单独实现5个方法。
思考后认为解决方法有:
- HashMap、ArrayList均为可变对象,可以作为参数传入负责该问题的方法中对其进行修改,而也没有进行clone等操作浪费时间;
- 灵活使用多态和null,减少不必要的逻辑分支
- 将不必要的for循环换成collection的addAll()方法
- 当时间性能要求低时,合理使用lambda去除分支语句
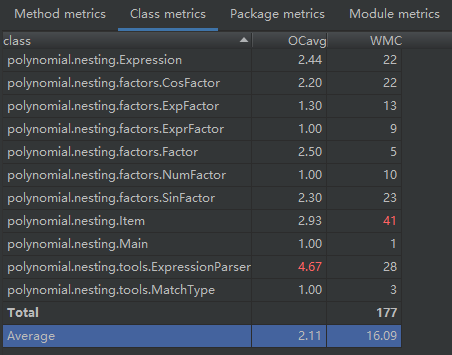
同样的,从类复杂度度量中也可以看出,Item的部分操作应该下放到Factor中,并合理使用多态减少逻辑分支。
同时,ExpressionParser中存在部分冗余代码,应该将其抽提出来。
测试与Bug
公测
在强测中,笔者的程序TLE了两个点。(下文分析)
互测
在互测中,笔者的程序被challenge了一个TLE的点。(下文分析)
而笔者利用对拍器+数据生成器,共challenge成功10个数据点(此外还包括6个同质数据点)。其中大部分的bug均为:
- 对Format判定的准确度不够,经常将正确数据判定成错误,也有少见的将错误数据判定成正确的情况。
大多数均是对文法设计不够精确(从而暴露出自己在提交代码之前没有好好覆盖测试的问题),也有在递归下降分析器中的bug。 - 在递归下降分析器中思路不够清晰、容易遗漏情况,经常忘记形如"-(1+x+cos(x))"括号前面的负号的问题。
- 对递归下降的理解不够深刻,稍微复杂的表达式就会出现TLE/爆栈错误。
此外,笔者还通过手构数据对关键的易错点进行定点尝试,成功发现了1个罕见的bug并challenge成功。
Bug分析与总结
笔者在公测和互测中TLE的3个点均为同质的恶性bug,分析如下:
首先看这样一段代码:
for (Item i : items) { i = i.SortOut(); // do something with i if (some condition) { newItems.add(newI); } else { newItems.add(i); } } for (Item i : newItems) { i = i.SortOut(); // do something with i }
可以看到,为了优化当前表达式(由items组成),首先优化各个Item i,之后将其进一步处理。
然而,在中间变量newItems中,可以说大部分的元素都是已经调用过SortOut()方法,已经保证最优的了。只有少部分newI对象是没有调用过
可是笔者在写代码时一时脑抽,想进一步确保i的最优性,于是重复调用了SortOut(),而且没有对当前对象是否是已优化进行标记。于是造成了时间复杂度成指数增加的恶性bug。
显然正确的写法应该是:
for (Item i : items) { i = i.SortOut(); // do something with i if (some condition) { newItems.add(newI.SortOut()); } else { newItems.add(i); } } for (Item i : newItems) { // do something with i }
这样就确保每个newItems里面的对象,都有且仅有被调用过一次SortOut()方法。
这个bug的存在原因大致有三:
- 在写代码时没有想清楚,拿起键盘就是干;
- 在oo作业中没有去考虑时间复杂度(除了第二次作业的暴力),根本就没有去像算法竞赛似的去考虑会不会T的问题;
- 测试不到位,在手构数据基础覆盖测试的时候没有“乘法原理”式的覆盖所有可能的情况。
一个显然的性能测试应该如下:- 首先测试基础样例,这里指所有不含冗余嵌套的规则输入;如"x"、"sin(x)*x"、"sin(0)*x"、"sin(x)*5*x-4*x^3*cos(x^2)"等
- 之后尝试冗余嵌套,包括在外部和在内部等,包括括号和三角函数等;
- 以在外部的冗余括号嵌套为例,测试时应当在"((((((?))))))"的?处填入所有基础样例中的数据,而不是仅仅测一组"((((((x))))))"就敷衍了事。
如果在自己测试的时候真正做到了这点,这个TLE的潜在可能就会被发现!
设计模式探讨
在基于metric的代码分析中可以看到,ExpressionParser的部分方法的复杂度很高。
现在笔者使用的是直接由Parser看出需要创建什么样的对象,并直接调取对应具体类的构造方法进行构造。
因此,在Parser中将会存在一些对“要创建什么样的具体对象”的判断工作。
而工厂方法模式对解决这个问题就很适合,下面引用一段介绍:
意图
- 定义一个用于创建对象的接口,让子类决定实例化哪一个类;
- 使一个类的实例化延迟到其子类。
问题
一般来说有几种情况需要用到Factory Method:
- 一套工具库或者框架实现并没有考虑业务相关的东西,在我们实现自己的业务逻辑时,可能需要注册我们自己的业务类型到框架中;
- 面向对象中,在有继承关系的体系下,可能给最初并不知道要创建何种类型,需要在特定时机下动态创建;
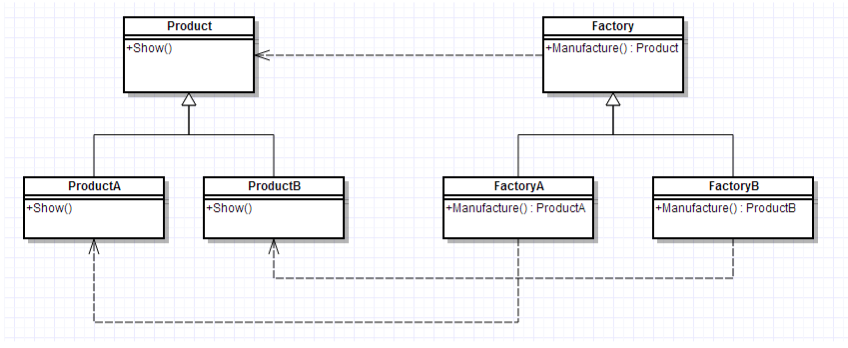
其实就现在而言,Parser就像一个大工厂:它先解析字符串,然后它既制造Expression,又制造Item,又制造Factor。
这样的设计模式显然是不够优美的:Parser的工作应该是(且仅仅应该是)判断接下来的一段字符串是一个Expression,还是一个Item,还是一个Factor。
换句话说,Parser应该来判断是要创建expr、item、factor三棵树中的哪一个(参见类图),而不应该继续探究“应该创建ROOT树下的哪一个叶子节点(如numFactor、expFactor等等)”!
因此,为了
- 可拓展性:将来如果增加Factor种类怎么办?
- Parser的复杂度:干好Parser的本职工作
应当设计一个创建Factor的工厂。
工厂模式的简要UML图如下:(引用自https://blog.csdn.net/carson_ho/article/details/52343584)
总结
- 测试的问题
- 手构数据按照一定树形结构和不同树间的乘法原理,尽量覆盖所有情况,不要有侥幸心理
- 对拍器+数据生成器的方法很好用,但是要保证数据生成器与oo代码不能是高度一致的,否则没有意义
- 性能
- 时间和空间的性能比所谓的长度优化更为重要,是程序设计的基础
- 减少clone,多用引用
- 不要进行重复性的、无意义的工作
- 面向对象
- 利用多态和null等技巧,减少在上层不必要的逻辑、将逻辑下放,防止某一层结构的类和方法复杂度激增
- 每个方法各司其职,如有必要大胆创建子方法,在父方法中只进行组合(并列、顺序等)关系的操作,具体的任务分散到子方法 / 子对象的方法中
- 尽量使用继承和接口,提升自己上层类设计的复杂度,同时尽量更好地支持可拓展性和可维护性
- 基础语言
- 正则表达式的正确打开方式,和不适宜的使用场景
- 可变对象可以作为参数传入方法中,并可以对其进行修改。基于此,可以有效地降低方法的复杂度,使方法各司其职

 浙公网安备 33010602011771号
浙公网安备 33010602011771号