Django Rest Framework 分页组件, 解析器以及渲染器
分页组件
- DRF 提供了三种分页方式:
- PageNumberPagination:
- 该分页方式,支持在URL中添加页数,以及每页显示的个数:
- 源码:


class PageNumberPagination(BasePagination): """ A simple page number based style that supports page numbers as query parameters. For example: http://api.example.org/accounts/?page=4 http://api.example.org/accounts/?page=4&page_size=100 """ # The default page size. # Defaults to `None`, meaning pagination is disabled. page_size = api_settings.PAGE_SIZE django_paginator_class = DjangoPaginator # Client can control the page using this query parameter. page_query_param = 'page' page_query_description = _('A page number within the paginated result set.') # Client can control the page size using this query parameter. # Default is 'None'. Set to eg 'page_size' to enable usage. page_size_query_param = None page_size_query_description = _('Number of results to return per page.') # Set to an integer to limit the maximum page size the client may request. # Only relevant if 'page_size_query_param' has also been set. max_page_size = None last_page_strings = ('last',) template = 'rest_framework/pagination/numbers.html' invalid_page_message = _('Invalid page.') def paginate_queryset(self, queryset, request, view=None): """ Paginate a queryset if required, either returning a page object, or `None` if pagination is not configured for this view. """ page_size = self.get_page_size(request) if not page_size: return None paginator = self.django_paginator_class(queryset, page_size) page_number = request.query_params.get(self.page_query_param, 1) if page_number in self.last_page_strings: page_number = paginator.num_pages try: self.page = paginator.page(page_number) except InvalidPage as exc: msg = self.invalid_page_message.format( page_number=page_number, message=six.text_type(exc) ) raise NotFound(msg) if paginator.num_pages > 1 and self.template is not None: # The browsable API should display pagination controls. self.display_page_controls = True self.request = request return list(self.page) def get_paginated_response(self, data): return Response(OrderedDict([ ('count', self.page.paginator.count), ('next', self.get_next_link()), ('previous', self.get_previous_link()), ('results', data) ])) def get_page_size(self, request): if self.page_size_query_param: try: return _positive_int( request.query_params[self.page_size_query_param], strict=True, cutoff=self.max_page_size ) except (KeyError, ValueError): pass return self.page_size def get_next_link(self): if not self.page.has_next(): return None url = self.request.build_absolute_uri() page_number = self.page.next_page_number() return replace_query_param(url, self.page_query_param, page_number) def get_previous_link(self): if not self.page.has_previous(): return None url = self.request.build_absolute_uri() page_number = self.page.previous_page_number() if page_number == 1: return remove_query_param(url, self.page_query_param) return replace_query_param(url, self.page_query_param, page_number) def get_html_context(self): base_url = self.request.build_absolute_uri() def page_number_to_url(page_number): if page_number == 1: return remove_query_param(base_url, self.page_query_param) else: return replace_query_param(base_url, self.page_query_param, page_number) current = self.page.number final = self.page.paginator.num_pages page_numbers = _get_displayed_page_numbers(current, final) page_links = _get_page_links(page_numbers, current, page_number_to_url) return { 'previous_url': self.get_previous_link(), 'next_url': self.get_next_link(), 'page_links': page_links } def to_html(self): template = loader.get_template(self.template) context = self.get_html_context() return template.render(context) def get_schema_fields(self, view): assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`' assert coreschema is not None, 'coreschema must be installed to use `get_schema_fields()`' fields = [ coreapi.Field( name=self.page_query_param, required=False, location='query', schema=coreschema.Integer( title='Page', description=force_text(self.page_query_description) ) ) ] if self.page_size_query_param is not None: fields.append( coreapi.Field( name=self.page_size_query_param, required=False, location='query', schema=coreschema.Integer( title='Page size', description=force_text(self.page_size_query_description) ) ) ) return fields
- LimitOffsetPagination:
这种分页样式反映了查找多个数据库记录时使用的语法。
客户端包括“限制”和“偏移”查询参数。
限制表示要返回的最大项目数,并且与page_size其他样式相同。
偏移量表示查询相对于整套未标记项目的起始位置。
- 源码:
class LimitOffsetPagination(BasePagination): """ A limit/offset based style. For example: http://api.example.org/accounts/?limit=100 http://api.example.org/accounts/?offset=400&limit=100 """ default_limit = api_settings.PAGE_SIZE limit_query_param = 'limit' limit_query_description = _('Number of results to return per page.') offset_query_param = 'offset' offset_query_description = _('The initial index from which to return the results.') max_limit = None template = 'rest_framework/pagination/numbers.html' def paginate_queryset(self, queryset, request, view=None): self.count = self.get_count(queryset) self.limit = self.get_limit(request) if self.limit is None: return None self.offset = self.get_offset(request) self.request = request if self.count > self.limit and self.template is not None: self.display_page_controls = True if self.count == 0 or self.offset > self.count: return [] return list(queryset[self.offset:self.offset + self.limit]) def get_paginated_response(self, data): return Response(OrderedDict([ ('count', self.count), ('next', self.get_next_link()), ('previous', self.get_previous_link()), ('results', data) ])) def get_limit(self, request): if self.limit_query_param: try: return _positive_int( request.query_params[self.limit_query_param], strict=True, cutoff=self.max_limit ) except (KeyError, ValueError): pass return self.default_limit def get_offset(self, request): try: return _positive_int( request.query_params[self.offset_query_param], ) except (KeyError, ValueError): return 0 def get_next_link(self): if self.offset + self.limit >= self.count: return None url = self.request.build_absolute_uri() url = replace_query_param(url, self.limit_query_param, self.limit) offset = self.offset + self.limit return replace_query_param(url, self.offset_query_param, offset) def get_previous_link(self): if self.offset <= 0: return None url = self.request.build_absolute_uri() url = replace_query_param(url, self.limit_query_param, self.limit) if self.offset - self.limit <= 0: return remove_query_param(url, self.offset_query_param) offset = self.offset - self.limit return replace_query_param(url, self.offset_query_param, offset) def get_html_context(self): base_url = self.request.build_absolute_uri() if self.limit: current = _divide_with_ceil(self.offset, self.limit) + 1 # The number of pages is a little bit fiddly. # We need to sum both the number of pages from current offset to end # plus the number of pages up to the current offset. # When offset is not strictly divisible by the limit then we may # end up introducing an extra page as an artifact. final = ( _divide_with_ceil(self.count - self.offset, self.limit) + _divide_with_ceil(self.offset, self.limit) ) if final < 1: final = 1 else: current = 1 final = 1 if current > final: current = final def page_number_to_url(page_number): if page_number == 1: return remove_query_param(base_url, self.offset_query_param) else: offset = self.offset + ((page_number - current) * self.limit) return replace_query_param(base_url, self.offset_query_param, offset) page_numbers = _get_displayed_page_numbers(current, final) page_links = _get_page_links(page_numbers, current, page_number_to_url) return { 'previous_url': self.get_previous_link(), 'next_url': self.get_next_link(), 'page_links': page_links } def to_html(self): template = loader.get_template(self.template) context = self.get_html_context() return template.render(context) def get_schema_fields(self, view): assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`' assert coreschema is not None, 'coreschema must be installed to use `get_schema_fields()`' return [ coreapi.Field( name=self.limit_query_param, required=False, location='query', schema=coreschema.Integer( title='Limit', description=force_text(self.limit_query_description) ) ), coreapi.Field( name=self.offset_query_param, required=False, location='query', schema=coreschema.Integer( title='Offset', description=force_text(self.offset_query_description) ) ) ] def get_count(self, queryset): """ Determine an object count, supporting either querysets or regular lists. """ try: return queryset.count() except (AttributeError, TypeError): return len(queryset)
- CursorPagination:
基于光标的分页呈现不透明的“光标”指示符, 客户端可以使用该指示符来翻阅结果集。 这种分页样式仅呈现正向和反向控件, 并且不允许客户端导航到任意位置。 基于游标的分页要求结果集中的项具有唯一且不变的排序。 这种排序通常可以是记录上的创建时间戳,因为这提供了一致的分页排序。 基于游标的分页比其他方案更复杂。它还要求结果集呈现固定的排序, 并且不允许客户端任意索引到结果集中。但它确实提供了以下好处: - 提供一致的分页视图。 正确使用时CursorPagination确保客户端在分页记录时永远不会看到相同的项目, 即使在分页过程中其他客户端插入新项目时也是如此。 - 支持使用非常大的数据集。对于极大的数据集, 使用基于偏移的分页样式的分页可能变得低效或无法使用。 基于游标的分页方案具有固定时间属性,并且不会随着数据集大小的增加而减慢。
- 源码:
class CursorPagination(BasePagination): """ The cursor pagination implementation is necessarily complex. For an overview of the position/offset style we use, see this post: https://cra.mr/2011/03/08/building-cursors-for-the-disqus-api """ cursor_query_param = 'cursor' cursor_query_description = _('The pagination cursor value.') page_size = api_settings.PAGE_SIZE invalid_cursor_message = _('Invalid cursor') ordering = '-created' template = 'rest_framework/pagination/previous_and_next.html' # Client can control the page size using this query parameter. # Default is 'None'. Set to eg 'page_size' to enable usage. page_size_query_param = None page_size_query_description = _('Number of results to return per page.') # Set to an integer to limit the maximum page size the client may request. # Only relevant if 'page_size_query_param' has also been set. max_page_size = None # The offset in the cursor is used in situations where we have a # nearly-unique index. (Eg millisecond precision creation timestamps) # We guard against malicious users attempting to cause expensive database # queries, by having a hard cap on the maximum possible size of the offset. offset_cutoff = 1000 def paginate_queryset(self, queryset, request, view=None): self.page_size = self.get_page_size(request) if not self.page_size: return None self.base_url = request.build_absolute_uri() self.ordering = self.get_ordering(request, queryset, view) self.cursor = self.decode_cursor(request) if self.cursor is None: (offset, reverse, current_position) = (0, False, None) else: (offset, reverse, current_position) = self.cursor # Cursor pagination always enforces an ordering. if reverse: queryset = queryset.order_by(*_reverse_ordering(self.ordering)) else: queryset = queryset.order_by(*self.ordering) # If we have a cursor with a fixed position then filter by that. if current_position is not None: order = self.ordering[0] is_reversed = order.startswith('-') order_attr = order.lstrip('-') # Test for: (cursor reversed) XOR (queryset reversed) if self.cursor.reverse != is_reversed: kwargs = {order_attr + '__lt': current_position} else: kwargs = {order_attr + '__gt': current_position} queryset = queryset.filter(**kwargs) # If we have an offset cursor then offset the entire page by that amount. # We also always fetch an extra item in order to determine if there is a # page following on from this one. results = list(queryset[offset:offset + self.page_size + 1]) self.page = list(results[:self.page_size]) # Determine the position of the final item following the page. if len(results) > len(self.page): has_following_position = True following_position = self._get_position_from_instance(results[-1], self.ordering) else: has_following_position = False following_position = None if reverse: # If we have a reverse queryset, then the query ordering was in reverse # so we need to reverse the items again before returning them to the user. self.page = list(reversed(self.page)) # Determine next and previous positions for reverse cursors. self.has_next = (current_position is not None) or (offset > 0) self.has_previous = has_following_position if self.has_next: self.next_position = current_position if self.has_previous: self.previous_position = following_position else: # Determine next and previous positions for forward cursors. self.has_next = has_following_position self.has_previous = (current_position is not None) or (offset > 0) if self.has_next: self.next_position = following_position if self.has_previous: self.previous_position = current_position # Display page controls in the browsable API if there is more # than one page. if (self.has_previous or self.has_next) and self.template is not None: self.display_page_controls = True return self.page def get_page_size(self, request): if self.page_size_query_param: try: return _positive_int( request.query_params[self.page_size_query_param], strict=True, cutoff=self.max_page_size ) except (KeyError, ValueError): pass return self.page_size def get_next_link(self): if not self.has_next: return None if self.cursor and self.cursor.reverse and self.cursor.offset != 0: # If we're reversing direction and we have an offset cursor # then we cannot use the first position we find as a marker. compare = self._get_position_from_instance(self.page[-1], self.ordering) else: compare = self.next_position offset = 0 for item in reversed(self.page): position = self._get_position_from_instance(item, self.ordering) if position != compare: # The item in this position and the item following it # have different positions. We can use this position as # our marker. break # The item in this position has the same position as the item # following it, we can't use it as a marker position, so increment # the offset and keep seeking to the previous item. compare = position offset += 1 else: # There were no unique positions in the page. if not self.has_previous: # We are on the first page. # Our cursor will have an offset equal to the page size, # but no position to filter against yet. offset = self.page_size position = None elif self.cursor.reverse: # The change in direction will introduce a paging artifact, # where we end up skipping forward a few extra items. offset = 0 position = self.previous_position else: # Use the position from the existing cursor and increment # it's offset by the page size. offset = self.cursor.offset + self.page_size position = self.previous_position cursor = Cursor(offset=offset, reverse=False, position=position) return self.encode_cursor(cursor) def get_previous_link(self): if not self.has_previous: return None if self.cursor and not self.cursor.reverse and self.cursor.offset != 0: # If we're reversing direction and we have an offset cursor # then we cannot use the first position we find as a marker. compare = self._get_position_from_instance(self.page[0], self.ordering) else: compare = self.previous_position offset = 0 for item in self.page: position = self._get_position_from_instance(item, self.ordering) if position != compare: # The item in this position and the item following it # have different positions. We can use this position as # our marker. break # The item in this position has the same position as the item # following it, we can't use it as a marker position, so increment # the offset and keep seeking to the previous item. compare = position offset += 1 else: # There were no unique positions in the page. if not self.has_next: # We are on the final page. # Our cursor will have an offset equal to the page size, # but no position to filter against yet. offset = self.page_size position = None elif self.cursor.reverse: # Use the position from the existing cursor and increment # it's offset by the page size. offset = self.cursor.offset + self.page_size position = self.next_position else: # The change in direction will introduce a paging artifact, # where we end up skipping back a few extra items. offset = 0 position = self.next_position cursor = Cursor(offset=offset, reverse=True, position=position) return self.encode_cursor(cursor) def get_ordering(self, request, queryset, view): """ Return a tuple of strings, that may be used in an `order_by` method. """ ordering_filters = [ filter_cls for filter_cls in getattr(view, 'filter_backends', []) if hasattr(filter_cls, 'get_ordering') ] if ordering_filters: # If a filter exists on the view that implements `get_ordering` # then we defer to that filter to determine the ordering. filter_cls = ordering_filters[0] filter_instance = filter_cls() ordering = filter_instance.get_ordering(request, queryset, view) assert ordering is not None, ( 'Using cursor pagination, but filter class {filter_cls} ' 'returned a `None` ordering.'.format( filter_cls=filter_cls.__name__ ) ) else: # The default case is to check for an `ordering` attribute # on this pagination instance. ordering = self.ordering assert ordering is not None, ( 'Using cursor pagination, but no ordering attribute was declared ' 'on the pagination class.' ) assert '__' not in ordering, ( 'Cursor pagination does not support double underscore lookups ' 'for orderings. Orderings should be an unchanging, unique or ' 'nearly-unique field on the model, such as "-created" or "pk".' ) assert isinstance(ordering, (six.string_types, list, tuple)), ( 'Invalid ordering. Expected string or tuple, but got {type}'.format( type=type(ordering).__name__ ) ) if isinstance(ordering, six.string_types): return (ordering,) return tuple(ordering) def decode_cursor(self, request): """ Given a request with a cursor, return a `Cursor` instance. """ # Determine if we have a cursor, and if so then decode it. encoded = request.query_params.get(self.cursor_query_param) if encoded is None: return None try: querystring = b64decode(encoded.encode('ascii')).decode('ascii') tokens = urlparse.parse_qs(querystring, keep_blank_values=True) offset = tokens.get('o', ['0'])[0] offset = _positive_int(offset, cutoff=self.offset_cutoff) reverse = tokens.get('r', ['0'])[0] reverse = bool(int(reverse)) position = tokens.get('p', [None])[0] except (TypeError, ValueError): raise NotFound(self.invalid_cursor_message) return Cursor(offset=offset, reverse=reverse, position=position) def encode_cursor(self, cursor): """ Given a Cursor instance, return an url with encoded cursor. """ tokens = {} if cursor.offset != 0: tokens['o'] = str(cursor.offset) if cursor.reverse: tokens['r'] = '1' if cursor.position is not None: tokens['p'] = cursor.position querystring = urlparse.urlencode(tokens, doseq=True) encoded = b64encode(querystring.encode('ascii')).decode('ascii') return replace_query_param(self.base_url, self.cursor_query_param, encoded) def _get_position_from_instance(self, instance, ordering): field_name = ordering[0].lstrip('-') if isinstance(instance, dict): attr = instance[field_name] else: attr = getattr(instance, field_name) return six.text_type(attr) def get_paginated_response(self, data): return Response(OrderedDict([ ('next', self.get_next_link()), ('previous', self.get_previous_link()), ('results', data) ])) def get_html_context(self): return { 'previous_url': self.get_previous_link(), 'next_url': self.get_next_link() } def to_html(self): template = loader.get_template(self.template) context = self.get_html_context() return template.render(context) def get_schema_fields(self, view): assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`' assert coreschema is not None, 'coreschema must be installed to use `get_schema_fields()`' fields = [ coreapi.Field( name=self.cursor_query_param, required=False, location='query', schema=coreschema.String( title='Cursor', description=force_text(self.cursor_query_description) ) ) ] if self.page_size_query_param is not None: fields.append( coreapi.Field( name=self.page_size_query_param, required=False, location='query', schema=coreschema.Integer( title='Page size', description=force_text(self.page_size_query_description) ) ) ) return fields
- 实现分页的原理逻辑:
解析器
- 解析器:
将浏览器发送过来的数据类型解析为后台指定类型的数据结构;
REST框架包含许多内置的Parser类,允许您接受各种媒体类型的请求。
还支持定义自己的自定义解析器,这使您可以灵活地设计API接受的媒体类型
- Content-Type:
- 浏览器在发送POST请求时,发送中的request的请求头中所声明的 发送的数据格式:
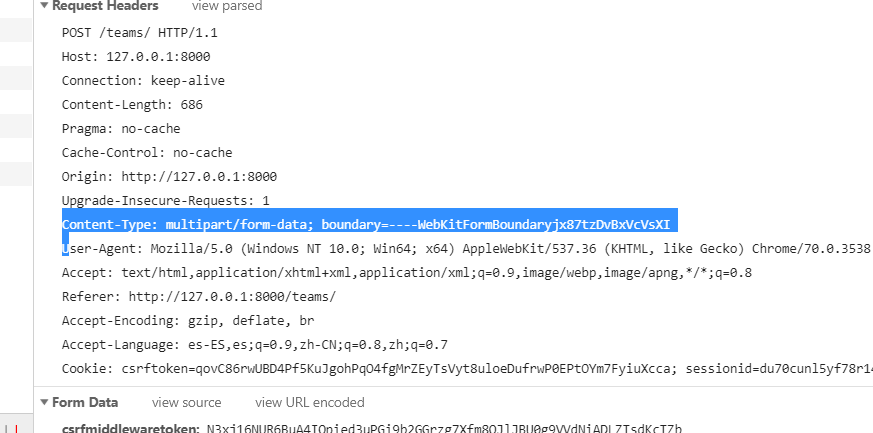
- 根据 Content-Type后台即可调用匹配的解析器来对数据进行解析;
- DRF调用解析的源码解析:
- 在调用POST请求时,调用解析器:
from django.shortcuts import render from rest_framework.views import APIView from rest_framework.response import Response class Parser(APIView): def get(self, request): return Response("This is GET") def post(self, request): dic = request.data # 调用解析器 return Response("This is POST")

- 执行_parse方法 循环执行注册的解析器:
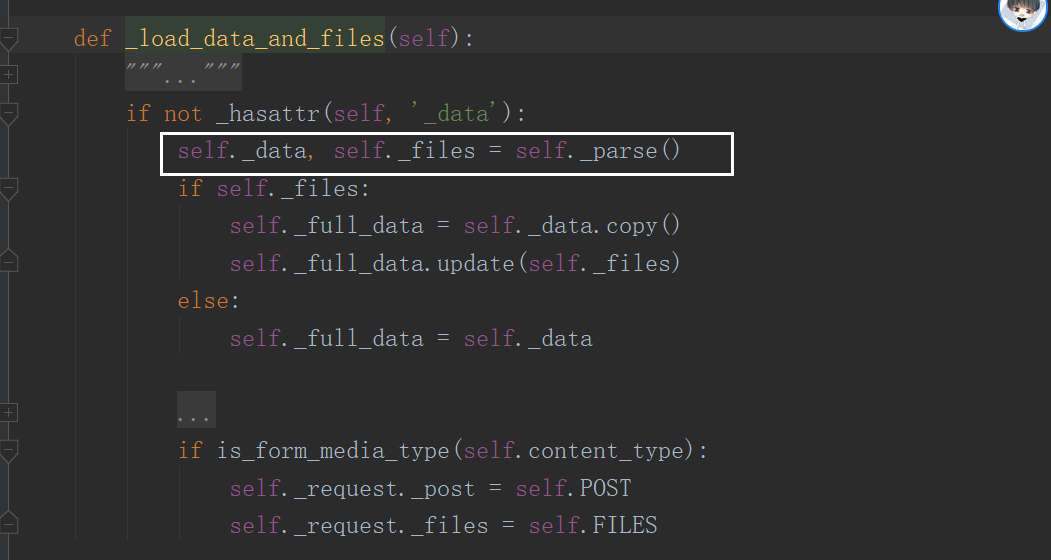
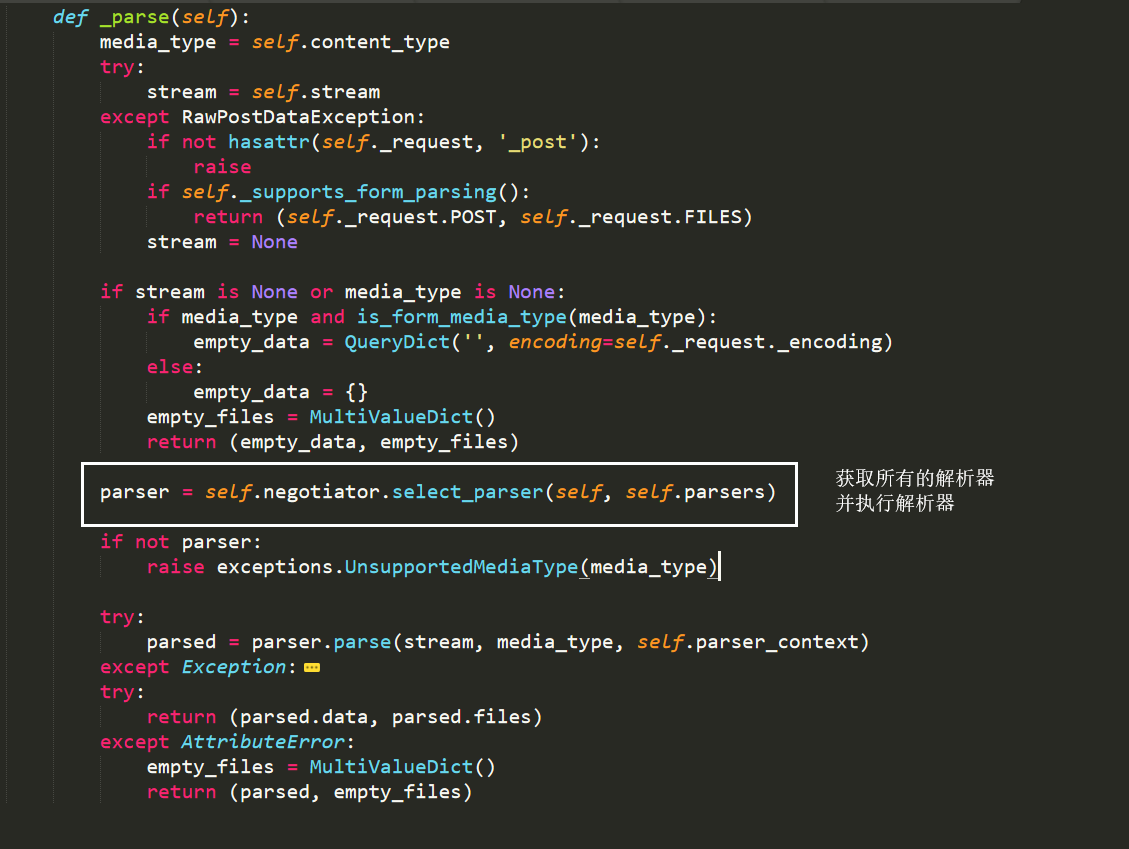
- self.parsers 在初始化Request时被赋值,赋值为注册的所有解析器类的列表的实例化对象;
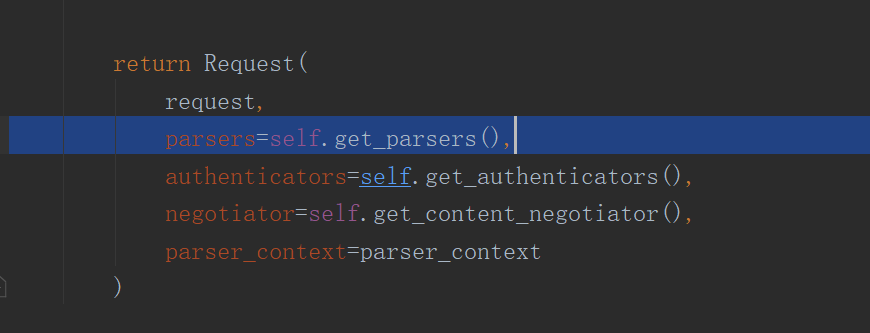
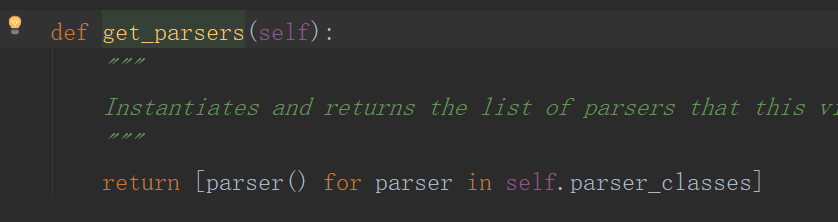
- DRF自带的四种解析器的API:
- JSONParser:
- 解析JSON请求内容;
- Content-Type :application/json
- FormParser:
- 解析HTML表单内容
- Content-Type :application/x-www-form-urlencoded
- MultiPartParser:
- 解析多部分HTML表单内容,支持文件上载
- Content-Type :multipart/form-data
- FileUploadParser
- 解析原始文件上传内容
- Content-Type :*/*
- 自定义Parser:
- 继承 rest_framework.parsers.py中的 类 BaseParser
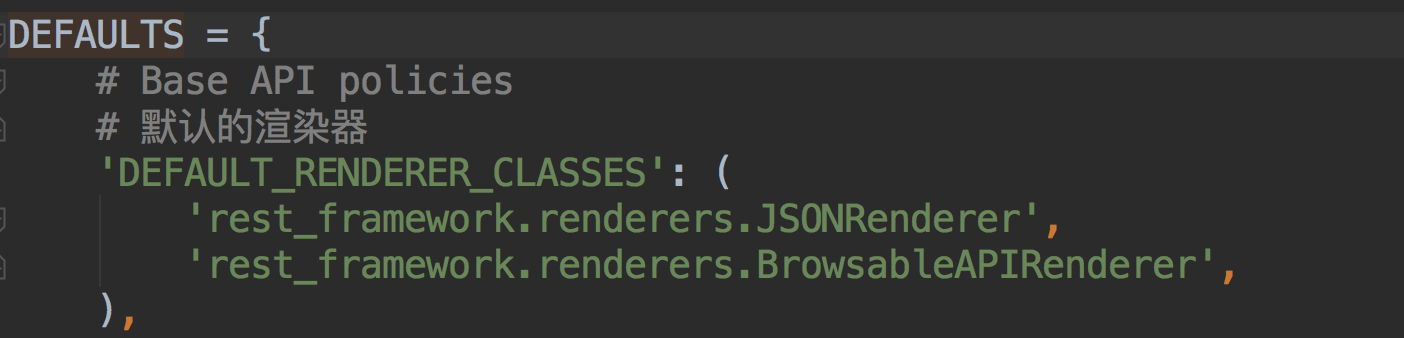
- settings.py中注册自己写的parser类的路径:
REST_FRAMEWORK = { "DEFAULT_PARSER_CLASSES": [ "util.parsers.MyParser", ] }
渲染器
- 渲染器:返回各种媒体类型的响应
- 展示数据;
- 设置使用渲染器: