数据采集实践第四次作业
Gitee作业链接:
https://gitee.com/FunkTank/crawl_project/tree/master/作业4
作业①
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
1.作业内容
点击查看代码
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
import time
import pymysql
def get_data(url):
html = driver.page_source
bs = etree.HTML(html)
lis = bs.xpath('//*[@id="table_wrapper-table"]/tbody/tr')
time.sleep(2)
for link in lis:
a = link.xpath('./td[1]/text()')[0] # 序号
b = link.xpath('./td[2]/a/text()')[0] # 代码
c = link.xpath('./td[3]/a/text()')[0] # 名称
d = link.xpath('./td[5]/span/text()')[0] # 最新价
e = link.xpath('./td[6]/span/text()')[0] # 涨跌幅
f = link.xpath('./td[7]/span/text()')[0] # 涨跌额
g = link.xpath('./td[8]/text()')[0] # 成交量
h = link.xpath('./td[9]/text()')[0] # 成交额
i = link.xpath('./td[10]/text()')[0] # 振幅
j = link.xpath('./td[11]/span/text()')[0] # 最高
k = link.xpath('./td[12]/span/text()')[0] # 最低
l = link.xpath('./td[13]/span/text()')[0] # 今开
m = link.xpath('./td[14]/text()')[0] # 昨收
# 使用 pymysql 连接数据库
connection = pymysql.connect(
host='localhost',
user='root',
password='',
database='pachoong',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
sql = "INSERT INTO stock4 (序号, 代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
val = (a, b, c, d, e, f, g, h, i, j, k, l, m)
cursor.execute(sql, val)
connection.commit()
print(a, b, c, d, e, f, g, h, i, j, k, l, m)
except Exception as e:
print(f"Error: {e}")
finally:
connection.close()
next_button = driver.find_element(By.XPATH, url)
next_button.click()
time.sleep(2)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board")
get_data('//*[@id="nav_sh_a_board"]/a')
get_data('//*[@id="nav_sz_a_board"]/a')
get_data('//*[@id="nav_bj_a_board"]/a')
输出信息:
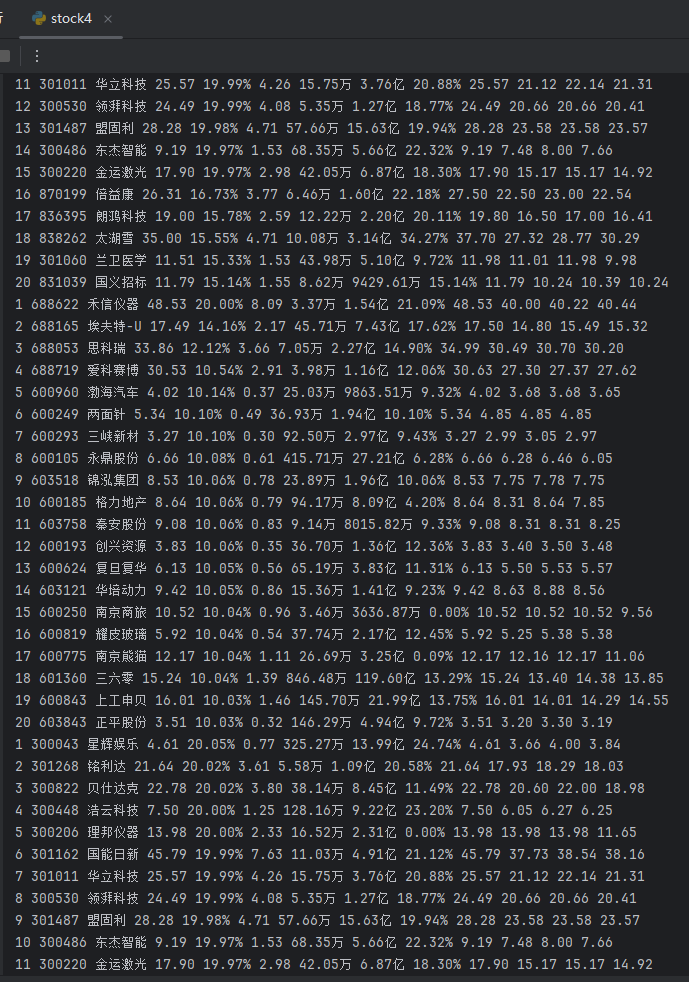
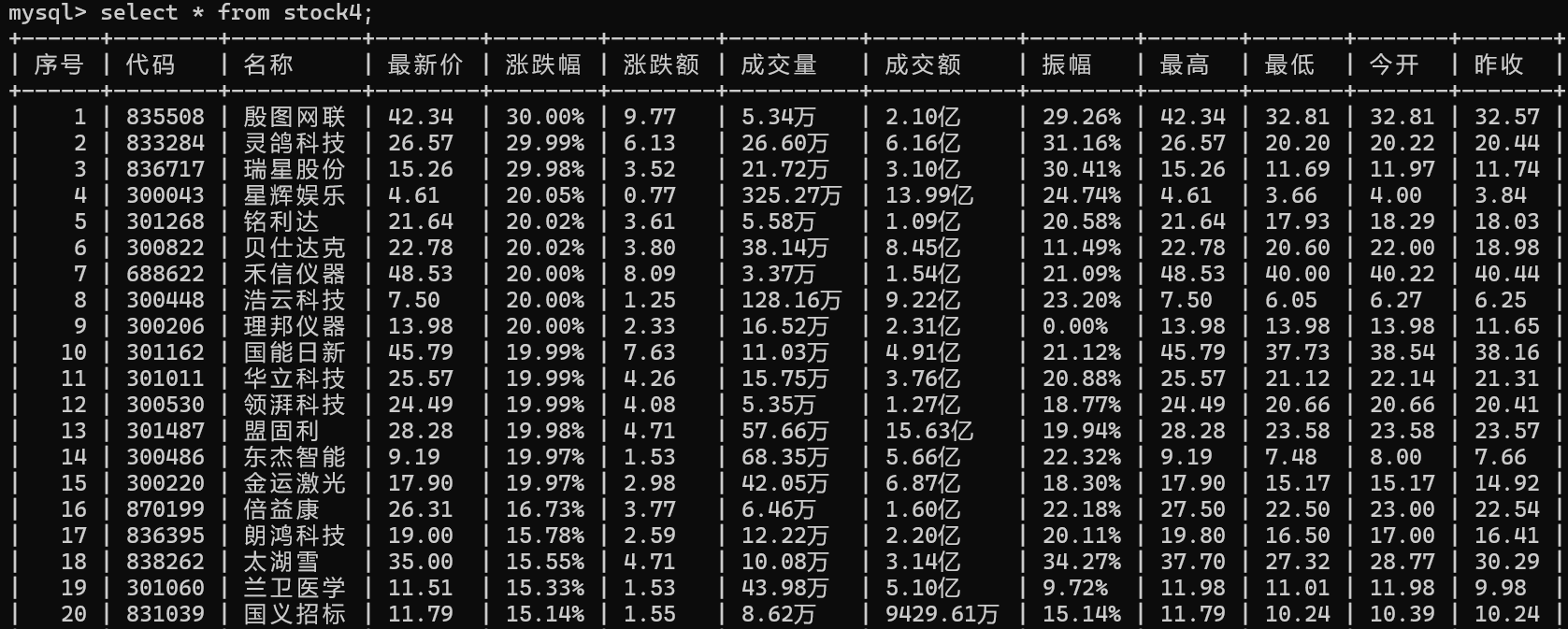
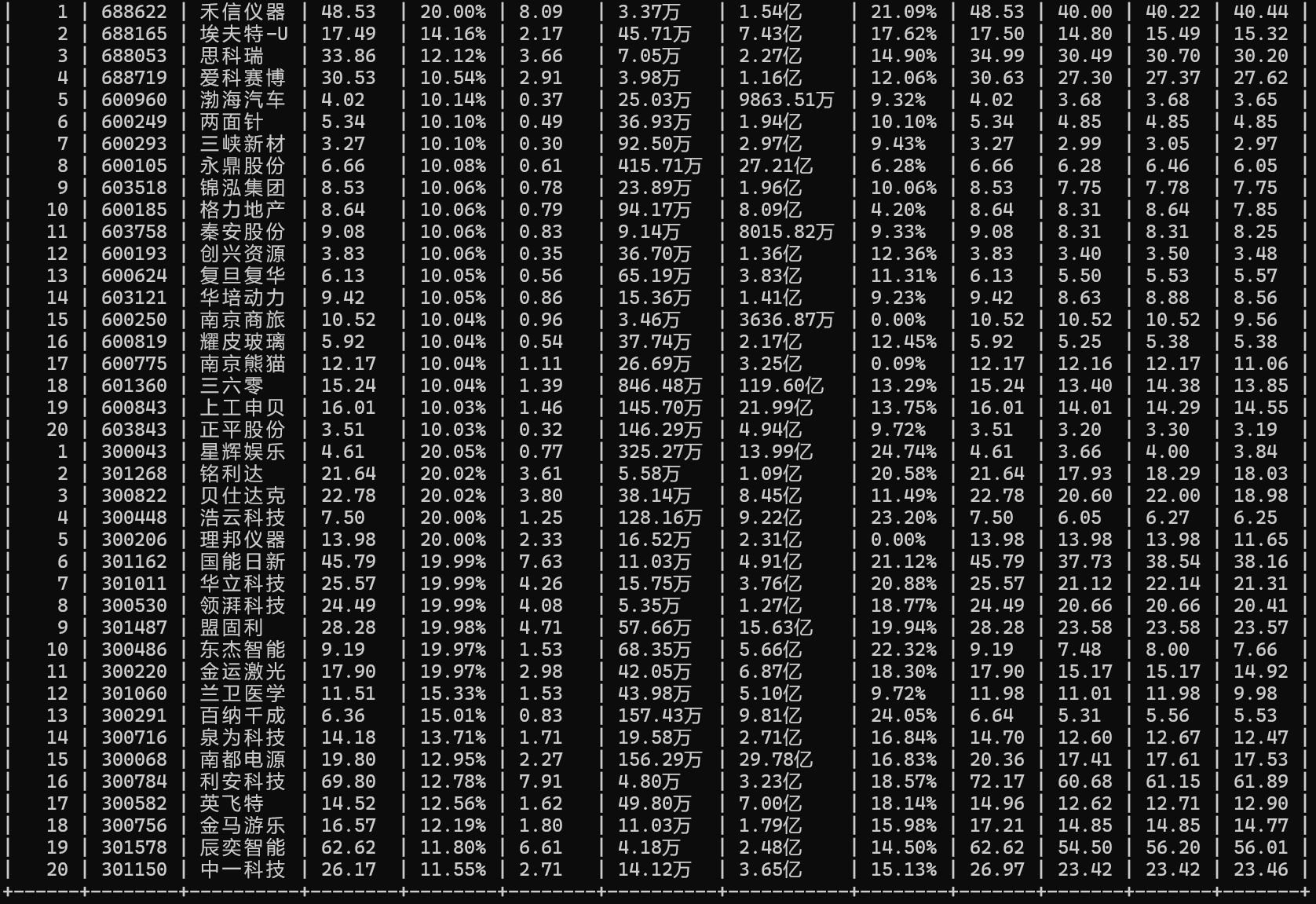
2.心得体会
在完成这个股票数据爬取任务的过程中,我深刻体会到了自动化数据处理的重要性以及Selenium工具在实际应用中的强大功能。这次实践不仅提升了我对Selenium和MySQL的掌握程度,也让我认识到在处理实际项目时,问题分析和解决能力的重要性。
作业②
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
1.作业内容
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import pymysql
# 数据库配置
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '',
'database': 'pachoong',
'charset': 'utf8mb4'
}
# 目标网址
LOGIN_URL = 'https://www.icourse163.org/'
COURSE_URL = 'https://www.icourse163.org/search.htm?search=%20#/'
# 初始化Chrome选项
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--disable-gpu')
# 初始化WebDriver
driver = webdriver.Chrome(options=chrome_options)
def wait_for_element(driver, by, value, timeout=10):
"""
等待元素加载完成
"""
return WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((by, value))
)
def login(driver, login_url, account, password):
"""
登录到网站
"""
driver.get(login_url)
wait_for_element(driver, By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div').click()
# 切换到iframe
frame = wait_for_element(driver, By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)
# 输入账号和密码
wait_for_element(driver, By.ID, 'phoneipt').send_keys(account)
wait_for_element(driver, By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(password)
# 点击登录按钮
wait_for_element(driver, By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
# 等待登录完成,可以根据实际情况调整
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))
)
def fetch_course_data(driver, course_url):
"""
获取课程信息并存储到数据库
"""
driver.get(course_url)
wait_for_element(driver, By.XPATH, '/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[1]/div[1]/label/div').click()
# 滚动页面以加载所有课程
scroll_script = """
var timer = setInterval(function(){
var scrollTop = document.documentElement.scrollTop || document.body.scrollTop;
var ispeed = Math.floor(document.body.scrollHeight / 100);
if(scrollTop > document.body.scrollHeight * 90 / 100){
clearInterval(timer);
}
console.log('scrollTop:' + scrollTop);
console.log('scrollHeight:' + document.body.scrollHeight);
window.scrollTo(0, scrollTop + ispeed);
}, 20);
"""
driver.execute_script(scroll_script)
time.sleep(4) # 等待滚动完成
# 获取页面源代码并解析
html = driver.page_source
bs = etree.HTML(html)
courses = bs.xpath('/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
# 连接到数据库
mydb = pymysql.connect(**DB_CONFIG)
cursor = mydb.cursor()
try:
for course in courses:
# 提取课程信息
a = course.xpath('./div[2]/div/div/div[1]/a[2]/span/text()')
if len(a) != 0 and a[0] == '国家精品':
b = course.xpath('./div[2]/div/div/div[1]/a[1]/span/text()')
c = course.xpath('./div[2]/div/div/div[2]/a[1]/text()')
d = course.xpath('./div[2]/div/div/div[2]/a[2]/text()')
e = course.xpath('./div[2]/div/div/div[2]/a[2]/text()')
f = course.xpath('./div[2]/div/div/div[3]/span[2]/text()')
g = course.xpath('./div[2]/div/div/div[3]/div/span[2]/text()')
h = course.xpath('./div[2]/div/div/a/span/text()')
# 数据清洗
course_name = b[0] if b else ''
college = c[0] if c else ''
teacher = d[0] if d else ''
team = e[0] if e else ''
count = f[0] if f else ''
process = g[0] if g else '已结束'
brief = h[0] if h else '空'
# 插入数据库
sql = "INSERT INTO mooc (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)"
val = (course_name, college, teacher, team, count, process, brief)
cursor.execute(sql, val)
mydb.commit()
print(course_name, college, teacher, team, count, process, brief)
except Exception as e:
print(f"Error: {e}")
finally:
cursor.close()
mydb.close()
def main():
# 登录
login(driver, LOGIN_URL, '', '') # 实际的账号和密码
# 获取课程数据
fetch_course_data(driver, COURSE_URL)
# 关闭浏览器
driver.quit()
if __name__ == "__main__":
main()
输出信息:
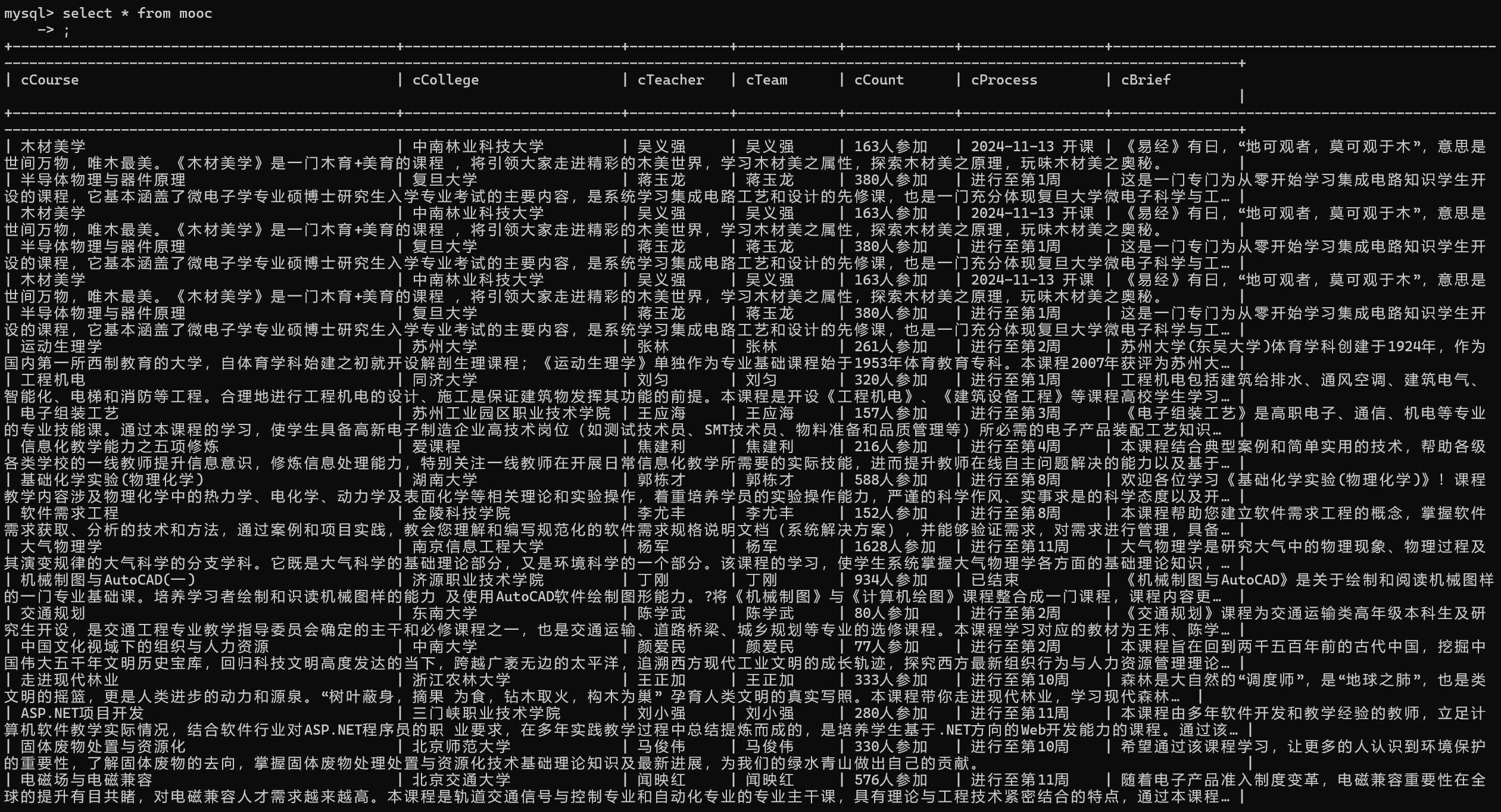
2.心得体会
在熟练掌握Selenium框架后,我成功实现了对中国大学MOOC网课程资源的自动化爬取。首先,我通过Selenium模拟用户登录,通过显式等待(WebDriverWait)处理动态加载的元素,确保登录流程的稳定性。接着,我使用Selenium的XPath定位功能,精准抓取课程信息,包括课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度和课程简介等关键数据。
作业③
要求:掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
- 任务一:开通MapReduce服务
![]()
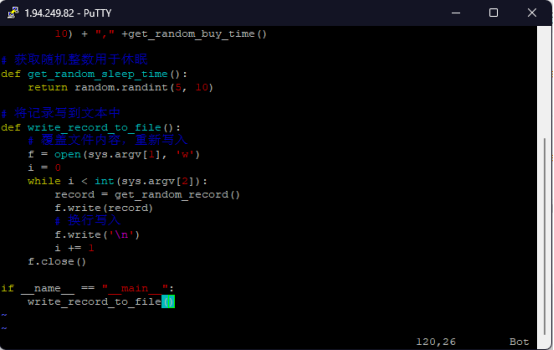
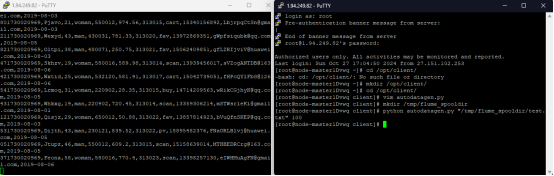
实时分析开发实战: - 任务一:Python脚本生成测试数据
![]()
![]()
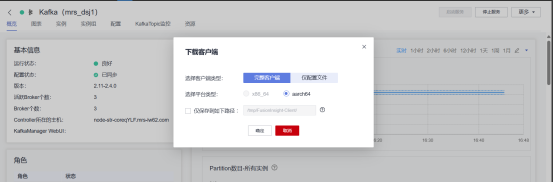
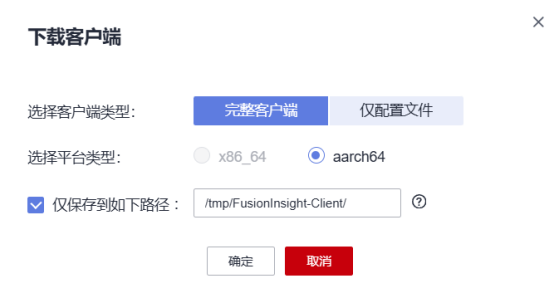
- 任务二:配置Kafka
![]()
![]()
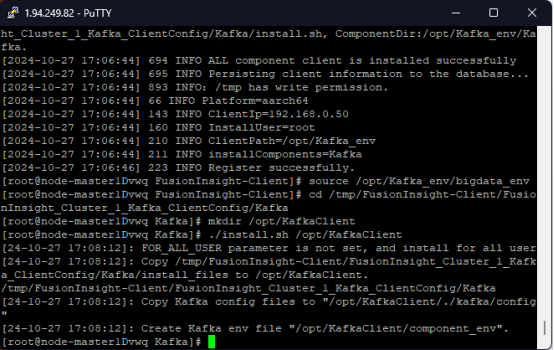
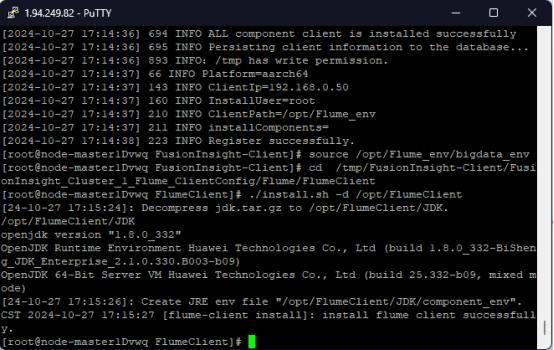
- 任务三:安装Flume客户端
![]()
![]()
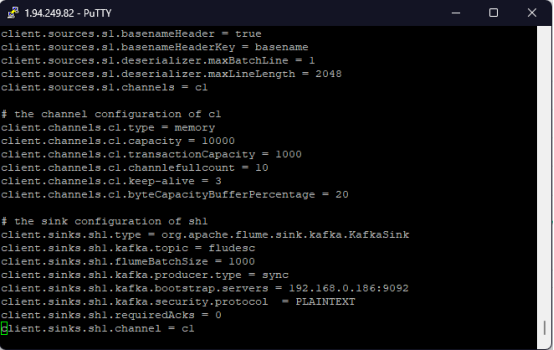
- 任务四:配置Flume采集数据
![]()
![]()


2.心得体会
通过使用Flink、Flume和Kafka等工具,我学会了如何构建一个完整的实时数据处理流程。我掌握了Flink SQL的编写技巧,这让我能够灵活地处理和分析流数据。此外,通过DLV服务进行数据可视化,我学会了如何将处理后的数据以直观的方式展示出来,这对于数据驱动的决策制定非常有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号