
数据采集实践第三次作业
Gitee作业链接:
https://gitee.com/FunkTank/crawl_project/tree/master/作业3
作业①
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
1.作业内容
spider代码
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class WeatherImagesSpider(scrapy.Spider):
name = 'weather_images'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
def parse(self, response):
# 提取所有图片的src属性
images = response.css('img::attr(src)').getall()
for img in images:
if img.startswith('http'):
yield {'image_urls': [img]}
else:
# 处理相对链接
absolute_link = response.urljoin(img)
yield {'image_urls': [absolute_link]}
class WeatherImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
运行结果:
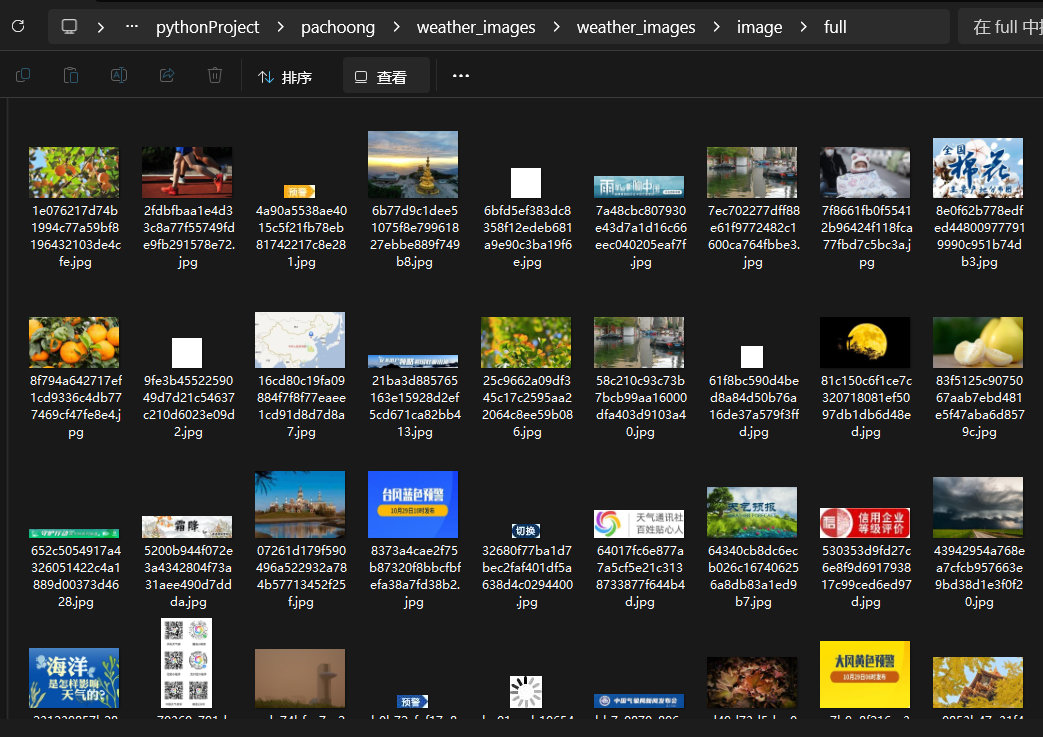
2.心得体会
在处理网页数据抓取任务时,我们不可避免地会面临网页结构变化带来的挑战。这次实验让我深刻认识到编写灵活且健壮的代码的重要性,尤其是在面对可能随时变化的网页结构时。实验初期,我们遇到了由于HTML结构修改导致的选择器失效问题,特别是对于温度信息的提取部分。这不仅突显了网页结构的不稳定性,也强调了选择器设计的灵活性。在编写选择器时,我们应尽量避免硬编码具体的标签或类名,而是采用更通用的选择器或结合多个选择器来提高匹配的准确性。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
1.作业内容
点击查看代码
import requests
import sqlite3
import json
import logging
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 数据库操作类
class StockDatabase:
def __init__(self, db_name):
self.conn = sqlite3.connect(db_name)
self.create_table()
logging.info(f"Database '{db_name}' connected.")
def create_table(self):
"""创建存储股票信息的表格"""
c = self.conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
stock_code TEXT,
stock_name TEXT,
latest_price REAL,
change_percent REAL,
change_amount REAL,
volume TEXT,
turnover TEXT,
amplitude REAL,
high REAL,
low REAL,
open_price REAL,
yesterday_close REAL
)
''')
self.conn.commit()
logging.info("Table 'stock_info' is ready.")
def save_stock_data(self, stock_data):
"""将股票数据保存到数据库"""
c = self.conn.cursor()
for stock in stock_data:
stock_record = (
stock.get('f12'), # 股票代码
stock.get('f14'), # 股票名称
stock.get('f2'), # 最新报价
stock.get('f3'), # 涨跌幅
stock.get('f4'), # 涨跌额
stock.get('f5'), # 成交量
stock.get('f6'), # 成交额
stock.get('f7'), # 振幅
stock.get('f15'), # 最高价
stock.get('f16'), # 最低价
stock.get('f17'), # 今开
stock.get('f18') # 昨收
)
try:
c.execute('''
INSERT INTO stock_info
(stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, high, low, open_price, yesterday_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', stock_record)
logging.info(f"Stock data for '{stock.get('f14')}' saved.")
except Exception as e:
logging.error(f"Error saving stock data: {e}")
self.conn.commit()
def display_stock_data(self):
"""显示数据库中的股票数据"""
c = self.conn.cursor()
c.execute("SELECT * FROM stock_info")
rows = c.fetchall()
# 打印表头
print(f"{'序号':<5} {'股票代码':<10} {'股票名称':<10} {'最新报价':<10} {'涨跌幅':<10} {'涨跌额':<10} {'成交量':<10} {'成交额':<15} {'振幅':<10} {'最高':<10} {'最低':<10} {'今开':<10} {'昨收':<10}")
# 打印每行数据
for row in rows:
latest_price = float(row[3]) if row[3] not in ('-', None) else 0.0
change_percent = float(row[4]) if row[4] not in ('-', None) else 0.0
change_amount = float(row[5]) if row[5] not in ('-', None) else 0.0
amplitude = float(row[8]) if row[8] not in ('-', None) else 0.0
high = float(row[9]) if row[9] not in ('-', None) else 0.0
low = float(row[10]) if row[10] not in ('-', None) else 0.0
open_price = float(row[11]) if row[11] not in ('-', None) else 0.0
yesterday_close = float(row[12]) if row[12] not in ('-', None) else 0.0
print(f"{row[0]:<5} {row[1]:<10} {row[2]:<10} "
f"{latest_price:<10.2f} {change_percent:<10.2f} {change_amount:<10.2f} "
f"{row[6]:<10} {row[7]:<15} {amplitude:<10.2f} {high:<10.2f} "
f"{low:<10.2f} {open_price:<10.2f} {yesterday_close:<10.2f}")
def close_connection(self):
"""关闭数据库连接"""
self.conn.close()
logging.info("Database connection closed.")
# 获取股票数据
def get_stock_data():
url = 'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409840494931556277_1633338445629&pn=1&pz=10&po=1&np=1&fltt=2&invt=2&fid=f3&fs=b:MK0021&fields=f12,f14,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f18,f15,f16,f17,f23'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
response = requests.get(url, headers=headers)
# 去除不必要的字符,提取有效的JSON部分
response_text = response.text.split('(', 1)[1].rsplit(')', 1)[0]
stock_data = json.loads(response_text)['data']['diff'] # 解析JSON并提取有用的字段
return stock_data
# 主函数
def main():
# 创建数据库连接
db = StockDatabase('eastmoney_stock.db')
# 获取股票数据
stock_data = get_stock_data()
# 保存数据到数据库
db.save_stock_data(stock_data)
# 显示表格数据
db.display_stock_data()
# 关闭数据库连接
db.close_connection()
if __name__ == '__main__':
main()
运行结果:
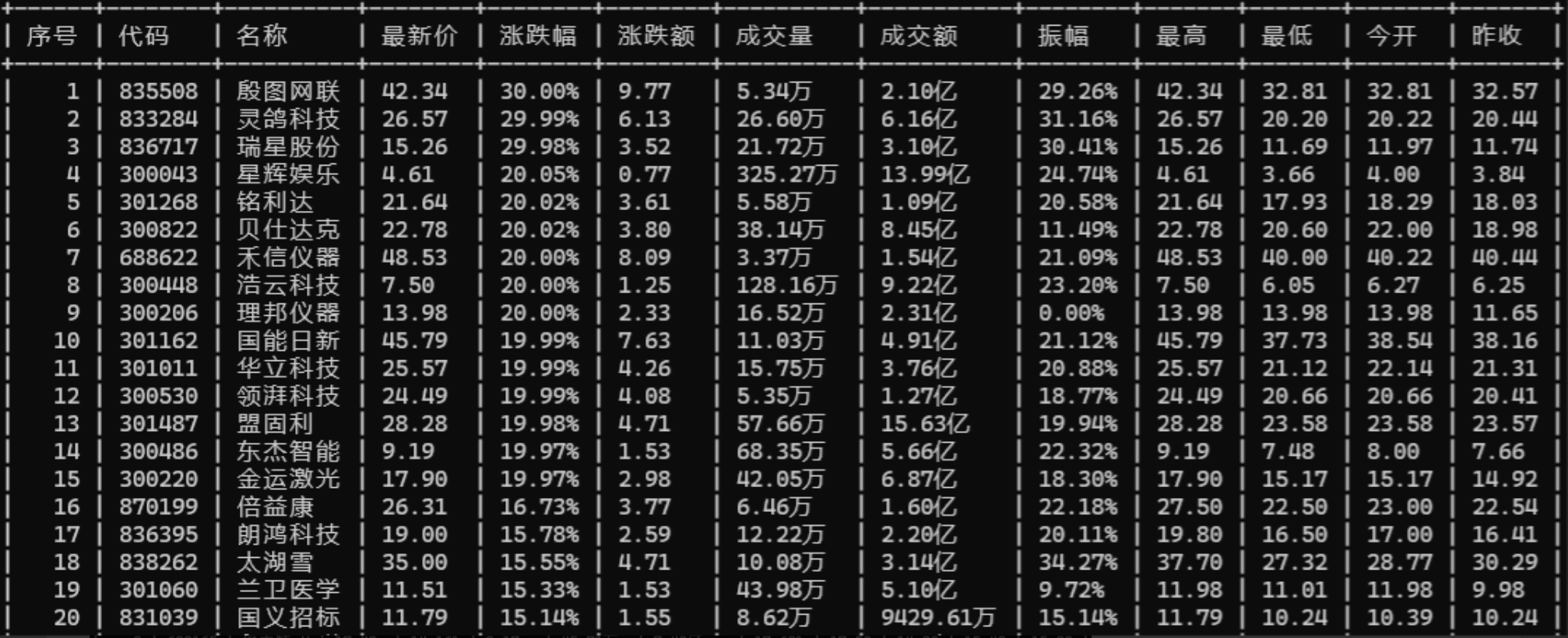
2.心得体会
通过本次作业,我深入掌握了Scrapy中Item和Pipeline的使用,实现了数据的序列化输出。利用XPath解析网页内容,我成功爬取了股票相关信息,并将其存储到MySQL数据库中。整个过程让我熟悉了Scrapy框架的数据处理流程,提升了数据抓取、解析和存储的技能,深刻体会到数据管道在项目中的重要性,为后续数据处理打下了坚实基础。
作业③
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
1.作业内容
spider代码
import scrapy
from boc_exchange_rates.items import BocExchangeRatesItem
class ExchangeRatesSpider(scrapy.Spider):
name = 'exchange_rates'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data = response.body.decode()
selector = scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for row in data_lists:
item = BocExchangeRatesItem()
item['currency'] = row.xpath('./td[1]/text()').get()
item['cash_buy'] = row.xpath('./td[2]/text()').get()
item['cash_sell'] = row.xpath('./td[3]/text()').get()
item['spot_buy'] = row.xpath('./td[4]/text()').get()
item['spot_sell'] = row.xpath('./td[5]/text()').get()
item['bank_rate'] = row.xpath('./td[6]/text()').get()
yield item
运行结果:
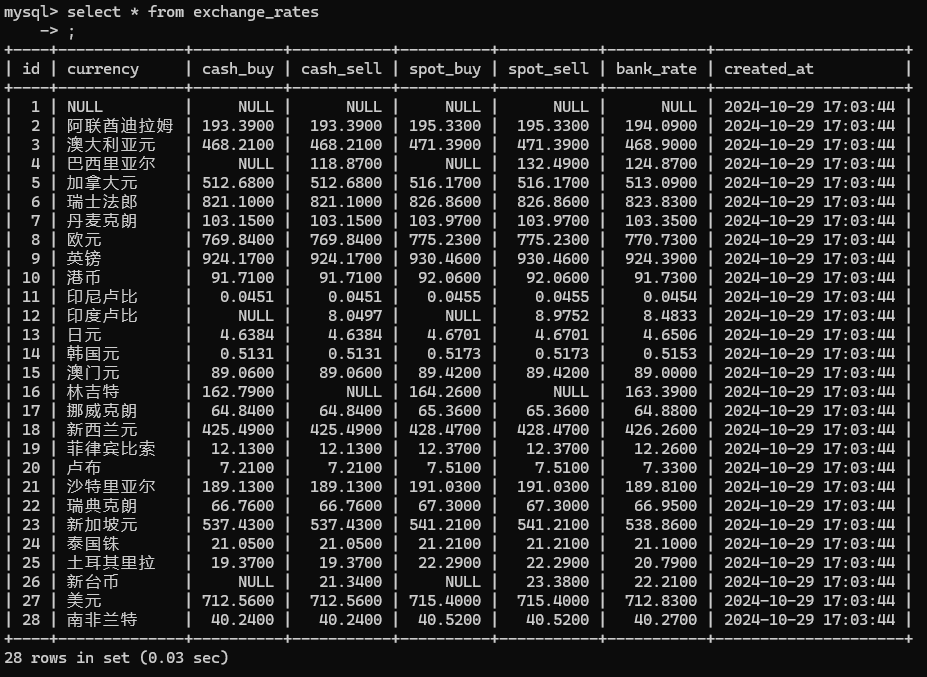
2.心得体会
本次作业中,我熟练掌握了Scrapy框架中Item和Pipeline的数据序列化输出方法。通过结合XPath解析,我成功从外汇网站抓取了所需数据,并利用Scrapy的Pipeline将数据存储到MySQL数据库中。整个过程让我深刻理解了数据抓取、清洗、存储的完整流程,提升了数据处理能力,并为后续大数据分析奠定了基础。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号