
数据采集实践第一次作业
Gitee作业链接:https://gitee.com/FunkTank/crawl_project/tree/master/作业1
作业①
要求:用requests和BeautifulSoup库方法定向爬取给定网址( http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
1.实践过程
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
# 目标网址
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp = urllib.request.urlopen(url)
html = resp.read()
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html, 'html.parser')
# 找到包含排名信息的表格行
rows = soup.find_all('tr')
# 打印标题
print("排名\t学校名称\t\t省市\t学校类型\t总分")
# 遍历表格的每一行,提取信息
for row in rows:
# 找到排名
rank = row.find('td').text.strip() if row.find('td') else ""
# 找到学校名称的span
span = row.find('span', class_="name-cn")
uni_name = span.text.strip() if span else ""
# 找到剩余内容
province = row.find_all('td')[2].text.strip() if row.find('td') else ""
uni_type = row.find_all('td')[3].text.strip() if row.find('td') else ""
score = row.find_all('td')[4].text.strip() if row.find('td') else ""
# 打印提取的信息
print(f"{rank}\t{uni_name}\t\t{province}\t{uni_type}\t{score}")
输出信息:
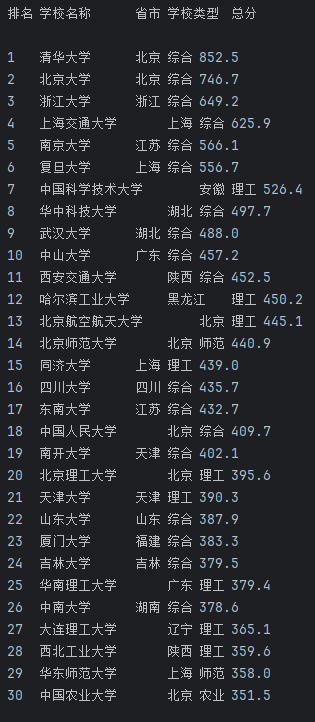
2.心得体会
在完成这次使用 requests 和 BeautifulSoup 库定向爬取大学排名信息的作业后,我深刻体会到了网络爬虫的强大与便捷。首先,通过 requests 库发送 HTTP 请求获取网页内容,让我感受到数据获取的灵活性和高效性。接着,利用 BeautifulSoup 库解析 HTML 结构,提取所需数据,这让我对网页的结构有了更深入的理解。整个过程不仅锻炼了我的编程能力,还让我认识到数据处理的重要性,特别是在处理复杂网页结构时,需要耐心和细致的调试。最终,成功在屏幕上打印出爬取的大学排名信息,成就感油然而生。
作业②
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
1.实践过程
点击查看代码
import requests
from bs4 import BeautifulSoup
import re
import sys
def fetch_html(url):
"""
发送HTTP GET请求获取网页内容。
Args:
url (str): 目标网页的URL。
Returns:
str: 网页的HTML内容。
Raises:
requests.HTTPError: 如果HTTP请求返回错误状态码。
requests.RequestException: 其他请求相关的异常。
"""
try:
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/115.0.0.0 Safari/537.36"
)
}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 如果HTTP请求返回错误状态码,将引发HTTPError
response.encoding = response.apparent_encoding
return response.text.encode('utf-8')
except requests.RequestException as e:
print(f"请求错误: {e}", file=sys.stderr)
sys.exit(1)
def parse_goods(html_content):
"""
解析网页HTML内容,提取商品信息。
Args:
html_content (str): 网页的HTML内容。
Returns:
list of dict: 包含商品序号、价格和名称的列表。
"""
soup = BeautifulSoup(html_content, 'html.parser')
ul = soup.find('ul', class_='bigimg')
if not ul:
print("未找到包含商品信息的<ul>标签。", file=sys.stderr)
sys.exit(1)
items = ul.find_all("li")
goods_list = []
# 定义正则表达式模式
title_regex = r'<a.*?单品标题.*?>(.*?)</a>'
price_regex = r'<p class="price">.*?<span class="search_now_price">(.*?)</span>'
for index, item in enumerate(items, start=1):
# 提取价格
price_match = re.search(price_regex, str(item), re.S)
price = price_match.group(1) if price_match else "N/A"
# 提取商品名称
name_match = re.search(title_regex, str(item), re.S)
if name_match:
name = BeautifulSoup(name_match.group(1), 'html.parser').get_text(strip=True)
else:
name = "N/A"
# 添加到商品列表
goods_list.append({
"序号": index,
"价格": price,
"商品名": name
})
return goods_list
def display_goods(goods_list):
"""
打印商品信息到控制台。
Args:
goods_list (list of dict): 包含商品信息的列表。
"""
if not goods_list:
print("未找到任何商品信息。", file=sys.stderr)
return
# 定义表头
headers = ["序号", "价格", "商品名"]
header_str = "\t".join(headers)
print(header_str)
# 打印每个商品的信息
for item in goods_list:
print(f"{item['序号']}\t{item['价格']}\t{item['商品名']}")
def main():
"""
主函数,执行爬虫流程。
"""
page_url = "https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&wq=shu&pvid=ea9bef8ed6114b1a9106f35315b8bf24"
# 获取网页HTML内容
html_content = fetch_html(page_url)
# 解析商品信息
goods = parse_goods(html_content)
# 显示商品信息
display_goods(goods)
if __name__ == "__main__":
main()
输出信息:
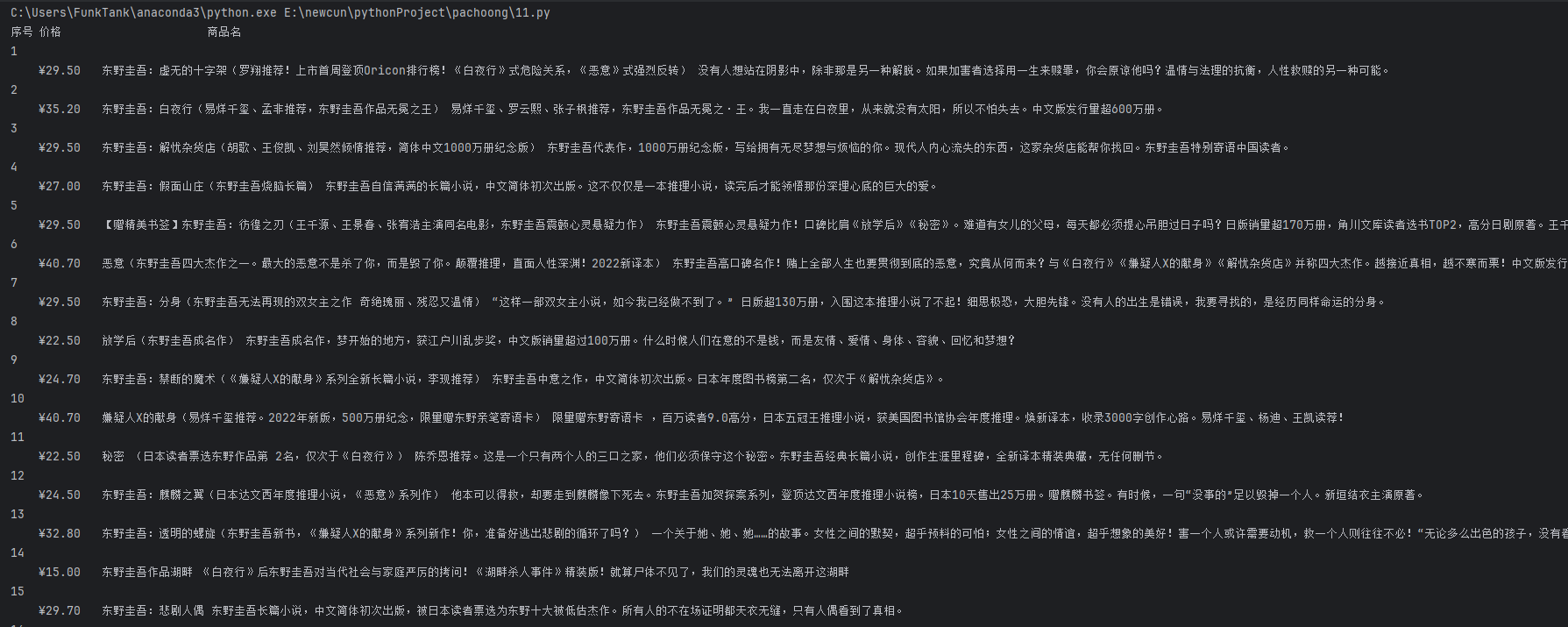
2.心得体会
通过使用 requests 和 re 库设计商品比价定向爬虫,我深刻体会到网页结构分析的重要性。在爬取过程中,我学会了如何利用正则表达式精准提取商品名称和价格,并掌握了设置合适的请求头和处理反爬机制的技巧。同时,我也意识到数据清洗和遵守网站规则的重要性。这次实践不仅提高了我的编程能力,还让我对网络爬虫的整体流程有了更清晰的认识。
作业③
要求:爬取一个给定网页或者自选网页的所有JPEG和JPG格式文件
1.实践过程
点击查看代码
import requests
from bs4 import BeautifulSoup
import re
import os
def get_html(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except requests.RequestException as e:
print(f"请求错误: {e}")
return None
def get_img(html, path):
soup = BeautifulSoup(html, 'html.parser')
# 查找所有 <p class="vsbcontent_img"> 标签
p_tags = soup.find_all('p', class_='vsbcontent_img')
img_list = []
for p in p_tags:
# 在每个 <p> 标签下查找 <img> 标签
img_tag = p.find('img')
if img_tag and 'src' in img_tag.attrs:
img_url = img_tag['src']
img_list.append(img_url)
if not img_list:
print("未找到符合条件的图片。")
return
index = 1
for img_url in img_list:
# 如果图片URL不是完整的URL,尝试补全
if not img_url.startswith('http'):
img_url = 'https://news.fzu.edu.cn/' + img_url.lstrip('/')
try:
img_response = requests.get(img_url, timeout=10)
img_response.raise_for_status()
img_data = img_response.content
img_filename = os.path.join(path, f"{index}.jpg")
with open(img_filename, 'wb') as f:
f.write(img_data)
print(f'图片{index}下载完成: {img_filename}')
index += 1
except requests.RequestException as e:
print(f"下载图片 {img_url} 失败: {e}")
if __name__ == '__main__':
url = 'https://news.fzu.edu.cn/info/1011/36544.htm'
path = 'picture'
# 如果目录不存在,则创建
if not os.path.exists(path):
os.makedirs(path)
html = get_html(url)
if html:
get_img(html, path)
输出结果:

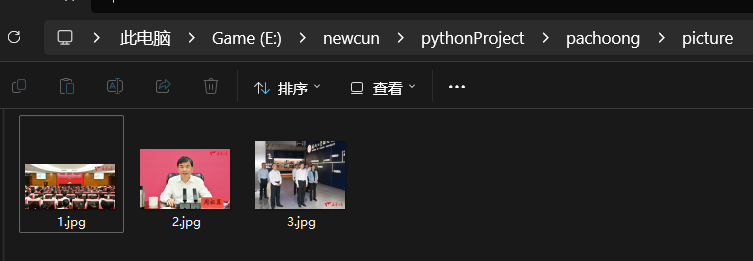
2.心得体会
在完成这次网页图片爬取作业的过程中,我深入学习了如何使用Python进行网页内容解析和文件下载。通过使用requests和BeautifulSoup库,我成功实现了从指定网页中提取所有JPEG和JPG格式的图片,并将其下载到本地。同时,通过处理相对路径和生成唯一文件名,我确保了图片的正确保存和避免覆盖。这次实践不仅巩固了我的编程技能,还让我对网络爬虫的工作原理有了更深的理解,特别是在处理不同类型的URL和文件格式时遇到的各种挑战和解决方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号