性能测试误差分析文字版-上
在之前的文章中,我都提到过QPS计算的两种公式,今天特意来研究一下在固定线程模型下,两种统计公式误差问题。
QPS = 总请求量除以总时间,以下:
QPS = count(r)/T
QPS = 线程数除以平均响应时间
QPS = thread/rt
计算模型
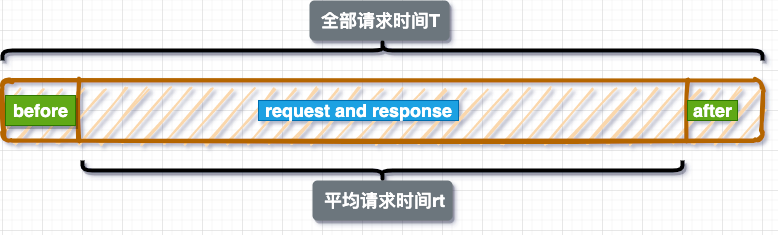
如图所示,这是单个线程单个请求的耗时简易模型,分成三部分:请求前(对应before)、请求与响应(对应request and response)和请求后(对应after)。其中T代表三个部分的总时间,rt代表了请求与响应的时间。
fds
误差来源
理论误差
这部分误差来源其实就是before和after两部分。不同于FunTester测试框架中的before()与after()方法。这里代表的是每次请求之前和请求之后进行的各种处理。
请求前的时间消耗在性能测试中,经常会进行请求前的数据引入、参数处理和请求设置等等。举个例子:在请求之前要拼装URL,获取字符型和数字型参数(可能是随机参数亦或从配置中获取),组装成请求对象HttpRequestBase等等。这些都需要时间,但是很短。耗时比较长的有可能是读取MySQL、巨量的数据、加锁的数据和参数运算等。
在请求后的时间消耗,大多数都是请求结果的解析和响应,例如测试工具和框架的基本验证,用户自己编写的各类断言,解析数据赋值变量等等。其中工作中常遇到的使用正则表达式和其他脚本引擎(即使用SDK)进行响应解析会消耗比较长的时间。可以参考文章:JMeter吞吐量误差分析中的例子。
在利用微基准测试修正压测结果中,遇到一种参数签名导致消耗时间过长,导致测试结果误差偏大,必需要进行空转的基准测试修正压测结果。
实际误差
这类误差来源是我根据经验划分的,是一些通用的理论上影响不大,或者在实际工作中发现脱离理论之外的情况。就如上图请求计算模型中所示,这其实也是一种理想化模型。
下面是我总结的一些来源:
日志打印
这个日志打印包括了正常日志和测试中文件读写。
由于性能测试数据量比较大,如果不加以区分和过滤,直接将所有日志都输出到文件中,那么必然会导致整个测试用例执行过程中的较大误差。之前经常能够看到有粉丝提问如果处理JMeter的测试日志中的数据。这些文件往往不只是几百M,而是以G为单位。试问,如果是串行日志输出,那么单单写入这些日志的时间消耗就必需进行数据的修正了。
在实际测试中,很多人并不会在意JMeter等工具的系统日志,因为实在太多了。而是会通过使用某个元器件(假设存在这个功能)或者工具的API进行个性化的日志输出。比如我之前写过的:用Groovy处理JMeter断言和日志中使用Groovy脚本引擎独立个性化处理日志和用Groovy记录JMeter请求和响应中根据响应结果分别记录异常的请求的功能。如果数据量比较小,消耗基本都在微秒级别,但是一旦发生以外情况,需要大量的数据记录时,又会回到日志记录相同的问题,影响测试结果。
数据实时处理
在部分的测试框架和测试工具中,测试中的数据是会实时展示的,包括常用的QPS、rt、95%、total等指标,还会监控服务端的各项指标。包括将这些指标计算绘图等等操作,都是非常耗时的,而且消耗更多硬件资源,不利于测试准确性的提高。大部分工具卡死都是因为在GUI执行测试用例的时候,各种实时数据处理占用过多硬件资源导致的,实不可取。目前我一直采用数据的后处理,既在测试完成之后进行数据的统计和分析。
- 未完待续……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号