SpringCloud微服务实战——搭建企业级开发框架(三十六):使用Spring Cloud Stream实现可灵活配置消息中间件的功能
在以往消息队列的使用中,我们通常使用集成消息中间件开源包来实现对应功能,而消息中间件的实现又有多种,比如目前比较主流的ActiveMQ、RocketMQ、RabbitMQ、Kafka,Stream等,这些消息中间件的实现都各有优劣。
在进行框架设计的时候,我们考虑是否能够和之前实现的短信发送、分布式存储等功能一样,抽象统一消息接口,屏蔽底层实现,在用到消息队列时,使用统一的接口代码,然后在根据自己业务需要选择不同消息中间件时,只需要通过配置就可以实现灵活切换使用哪种消息中间件。Spring Cloud Stream已经实现了这样的功能,下面我们在框架中集成并测试消息中间件的功能。
目前spring-cloud-stream官网显示已支持以下消息中间件,我们使用RabbitMQ和Apache Kafka来集成测试:
- RabbitMQ
- Apache Kafka
- Kafka Streams
- Amazon Kinesis
- Google PubSub (partner maintained)
- Solace PubSub+ (partner maintained)
- Azure Event Hubs (partner maintained)
- AWS SQS (partner maintained)
- AWS SNS (partner maintained)
- Apache RocketMQ (partner maintained)
一、集成RabbitMQ并测试消息收发
RabbitMQ是使用Erlang语言实现的,这里安装需要安装Erlang的依赖等,这里为了快速安装测试,所以使用Docker安装单机版RabbitMQ。
1、拉取RabbitMQ的Docker镜像,后缀带management的是带web管理界面的镜像
docker pull rabbitmq:3.9.13-management
2、创建和启动RabbitMQ容器
docker run -d\
-e RABBITMQ_DEFAULT_USER=admin\
-e RABBITMQ_DEFAULT_PASS=123456\
--name rabbitmq\
-p 15672:15672\
-p 5672:5672\
-v `pwd`/bigdata:/var/lib/rabbitmq\
rabbitmq:3.9.13-management
3、查看RabbitMQ是否启动
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ff1922cc6b73 rabbitmq:3.9.13-management "docker-entrypoint.s…" About a minute ago Up About a minute 4369/tcp, 5671/tcp, 0.0.0.0:5672->5672/tcp, :::5672->5672/tcp, 15671/tcp, 15691-15692/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp, :::15672->15672/tcp rabbitmq
4、访问管理控制台http://172.16.20.225:15672 ,输入设置的用户名密码 admin/123456登录。如果管理台不能访问,可以尝试使用一下命令启动:
docker exec -it rabbitmq rabbitmq-plugins enable rabbitmq_management
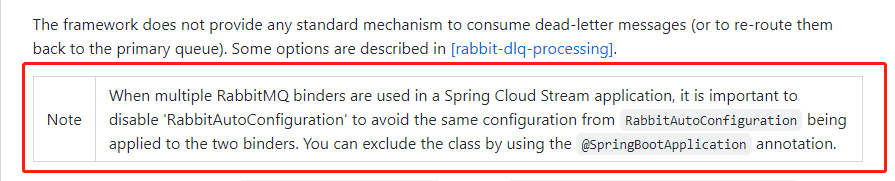
5、Nacos添加配置,我们以操作日志和API日志为示例,说明自定义输入和输出通道进行消息收发,operation-log为操作日志,api-log为API日志。注意,官网有文档说明:使用multiple RabbitMQ binders 时需要排除RabbitAutoConfiguration,实际应用过程中,如果不排除,也不直接配置RabbitMQ的连接,那么RabbitMQ健康检查会默认去连接127.0.0.1:5672,导致后台一直报错。
spring:
autoconfigure:
# 使用multiple RabbitMQ binders 时需要排除RabbitAutoConfiguration
exclude:
- org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration
cloud:
stream:
binders:
defaultRabbit:
type: rabbit
environment: #配置rabbimq连接环境
spring:
rabbitmq:
host: 172.16.20.225
username: admin
password: 123456
virtual-host: /
bindings:
output_operation_log:
destination: operation-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: defaultRabbit
output_api_log:
destination: api-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: defaultRabbit
input_operation_log:
destination: operation-log
content-type: application/json
binder: defaultRabbit
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
input_api_log:
destination: api-log
content-type: application/json
binder: defaultRabbit
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
6、在gitegg-service-bigdata中添加spring-cloud-starter-stream-rabbit依赖,这里注意,只需要在具体使用消息中间件的微服务上引入,不需要统一引入,并不是每个微服务都会用到消息中间件,况且可能不同的微服务使用不同的消息中间件。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
7、自定义日志输出通道LogSink.java
/**
* @author GitEgg
*/
public interface LogSink {
String INPUT_OPERATION_LOG = "output_operation_log";
String INPUT_API_LOG = "output_api_log";
/**
* 操作日志自定义输入通道
* @return
*/
@Input(INPUT_OPERATION_LOG)
SubscribableChannel inputOperationLog();
/**
* API日志自定义输入通道
* @return
*/
@Input(INPUT_API_LOG)
SubscribableChannel inputApiLog();
}
8、自定义日志输入通道LogSource.java
/**
* 自定义Stream输出通道
* @author GitEgg
*/
public interface LogSource {
String OUTPUT_OPERATION_LOG = "input_operation_log";
String OUTPUT_API_LOG = "input_api_log";
/**
* 操作日志自定义输出通道
* @return
*/
@Output(OUTPUT_OPERATION_LOG)
MessageChannel outputOperationLog();
/**
* API日志自定义输出通道
* @return
*/
@Output(OUTPUT_API_LOG)
MessageChannel outputApiLog();
}
9、实现日志推送接口的调用, @Scheduled(fixedRate = 3000)是为了测试推送消息,每隔3秒执行一次定时任务,注意:要使定时任务执行,还需要在Application启动类添加@EnableScheduling注解。
ILogSendService.java
/**
* @author GitEgg
*/
public interface ILogSendService {
/**
* 发送操作日志消息
* @return
*/
void sendOperationLog();
/**
* 发送api日志消息
* @return
*/
void sendApiLog();
}
LogSendImpl.java
/**
* @author GitEgg
*/
@EnableBinding(value = { LogSource.class })
@Slf4j
@Component
@RequiredArgsConstructor(onConstructor_ = @Autowired)
public class LogSendImpl implements ILogSendService {
private final LogSource logSource;
@Scheduled(fixedRate = 3000)
@Override
public void sendOperationLog() {
log.info("推送操作日志-------开始------");
logSource.outputOperationLog()
.send(MessageBuilder.withPayload(UUID.randomUUID().toString()).build());
log.info("推送操作日志-------结束------");
}
@Scheduled(fixedRate = 3000)
@Override
public void sendApiLog() {
log.info("推送API日志-------开始------");
logSource.outputApiLog()
.send(MessageBuilder.withPayload(UUID.randomUUID().toString()).build());
log.info("推送API日志-------结束------");
}
}
10、实现日志消息接收接口
ILogReceiveService.java
/**
* @author GitEgg
*/
public interface ILogReceiveService {
/**
* 接收到操作日志消息
* @param msg
*/
<T> void receiveOperationLog(GenericMessage<T> msg);
/**
* 接收到API日志消息
* @param msg
*/
<T> void receiveApiLog(GenericMessage<T> msg);
}
LogReceiveImpl.java
/**
* @author GitEgg
*/
@Slf4j
@Component
@EnableBinding(value = { LogSink.class })
public class LogReceiveImpl implements ILogReceiveService {
@StreamListener(LogSink.INPUT_OPERATION_LOG)
@Override
public synchronized <T> void receiveOperationLog(GenericMessage<T> msg) {
log.info("接收到操作日志: " + msg.getPayload());
}
@StreamListener(LogSink.INPUT_API_LOG)
@Override
public synchronized <T> void receiveApiLog(GenericMessage<T> msg) {
log.info("接收到API日志: " + msg.getPayload());
}
}
10、启动微服务,可以看到日志打印推送和接收消息已经执行的情况

二、集成Kafka测试消息收发并测试消息中间件切换
使用Spring Cloud Stream的其中一项优势就是方便切换消息中间件又不需要改动代码,那么下面我们测试在Nacos的Spring Cloud Stream配置中同时添加Kafka配置,并且API日志继续使用RabbitMQ,操作日志使用Kafka,查看是否能够同时运行。这里先将配置测试放在前面方便对比,Kafka集群搭建放在后面说明。
1、Nacos添加Kafka配置,并且将operation_log的binder改为Kafka
spring:
autoconfigure:
# 使用multiple RabbitMQ binders 时需要排除RabbitAutoConfiguration
exclude:
- org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration
cloud:
stream:
binders:
defaultRabbit:
type: rabbit
environment: #配置rabbimq连接环境
spring:
rabbitmq:
host: 172.16.20.225
username: admin
password: 123456
virtual-host: /
kafka:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: 172.16.20.220:9092,172.16.20.221:9092,172.16.20.222:9092
zkNodes: 172.16.20.220:2181,172.16.20.221:2181,172.16.20.222:2181
# 自动创建Topic
auto-create-topics: true
bindings:
output_operation_log:
destination: operation-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: kafka
output_api_log:
destination: api-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: defaultRabbit
input_operation_log:
destination: operation-log
content-type: application/json
binder: kafka
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
input_api_log:
destination: api-log
content-type: application/json
binder: defaultRabbit
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
2、登录Kafka服务器,切换到Kafka的bin目录下启动一个消费operation-log主题的消费者
./kafka-console-consumer.sh --bootstrap-server 172.16.20.221:9092 --topic operation-log
3、启动微服务,查看RabbitMQ和Kafka的日志推送和接收是否能够正常运行
- 微服务后台日志显示能够正常推送和接收消息:
![服务后台日志]()
- Kafka服务器显示收到了操作日志消息
![Kafka服务器]()


三、Kafka集群搭建
1、环境准备:
首先准备好三台CentOS系统的主机,设置ip为:172.16.20.220、172.16.20.221、172.16.20.222。
Kafka会使用大量文件和网络socket,Linux默认配置的File descriptors(文件描述符)不能够满足Kafka高吞吐量的要求,所以这里需要调整(更多性能优化,请查看Kafka官方文档):
vi /etc/security/limits.conf
# 在最后加入,修改完成后,重启系统生效。
* soft nofile 131072
* hard nofile 131072
新建kafka的日志目录和zookeeper数据目录,因为这两项默认放在tmp目录,而tmp目录中内容会随重启而丢失,所以我们自定义以下目录:
mkdir /data/zookeeper
mkdir /data/zookeeper/data
mkdir /data/zookeeper/logs
mkdir /data/kafka
mkdir /data/kafka/data
mkdir /data/kafka/logs
2、zookeeper.properties配置
vi /usr/local/kafka/config/zookeeper.properties
修改如下:
# 修改为自定义的zookeeper数据目录
dataDir=/data/zookeeper/data
# 修改为自定义的zookeeper日志目录
dataLogDir=/data/zookeeper/logs
# 端口
clientPort=2181
# 注释掉
#maxClientCnxns=0
# 设置连接参数,添加如下配置
# 为zk的基本时间单元,毫秒
tickTime=2000
# Leader-Follower初始通信时限 tickTime*10
initLimit=10
# Leader-Follower同步通信时限 tickTime*5
syncLimit=5
# 设置broker Id的服务地址,本机ip一定要用0.0.0.0代替
server.1=0.0.0.0:2888:3888
server.2=172.16.20.221:2888:3888
server.3=172.16.20.222:2888:3888
3、在各台服务器的zookeeper数据目录/data/zookeeper/data添加myid文件,写入服务broker.id属性值
在data文件夹中新建myid文件,myid文件的内容为1(一句话创建:echo 1 > myid)
cd /data/zookeeper/data
vi myid
#添加内容:1 其他两台主机分别配置 2和3
1
4、kafka配置,进入config目录下,修改server.properties文件
vi /usr/local/kafka/config/server.properties
# 每台服务器的broker.id都不能相同
broker.id=1
# 是否可以删除topic
delete.topic.enable=true
# topic 在当前broker上的分片个数,与broker保持一致
num.partitions=3
# 每个主机地址不一样:
listeners=PLAINTEXT://172.16.20.220:9092
advertised.listeners=PLAINTEXT://172.16.20.220:9092
# 具体一些参数
log.dirs=/data/kafka/kafka-logs
# 设置zookeeper集群地址与端口如下:
zookeeper.connect=172.16.20.220:2181,172.16.20.221:2181,172.16.20.222:2181
5、Kafka启动
kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper。
- zookeeper启动命令
./zookeeper-server-start.sh ../config/zookeeper.properties &
后台运行启动命令:
nohup ./zookeeper-server-start.sh ../config/zookeeper.properties >/data/zookeeper/logs/zookeeper.log 2>1 &
或者
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties &
查看集群状态:
./zookeeper-server-start.sh status ../config/zookeeper.properties
- kafka启动命令
./kafka-server-start.sh ../config/server.properties &
后台运行启动命令:
nohup bin/kafka-server-start.sh ../config/server.properties >/data/kafka/logs/kafka.log 2>1 &
或者
./kafka-server-start.sh -daemon ../config/server.properties &
- 创建topic,最新版本已经不需要使用zookeeper参数创建。
./kafka-topics.sh --create --replication-factor 2 --partitions 1 --topic test --bootstrap-server 172.16.20.220:9092
参数解释:
复制两份
--replication-factor 2
创建1个分区
--partitions 1
topic 名称
--topic test
- 查看已经存在的topic(三台设备都执行时可以看到)
./kafka-topics.sh --list --bootstrap-server 172.16.20.220:9092
- 启动生产者:
./kafka-console-producer.sh --broker-list 172.16.20.220:9092 --topic test
- 启动消费者:
./kafka-console-consumer.sh --bootstrap-server 172.16.20.221:9092 --topic test
./kafka-console-consumer.sh --bootstrap-server 172.16.20.222:9092 --topic test
添加参数 --from-beginning 从开始位置消费,不是从最新消息
./kafka-console-consumer.sh --bootstrap-server 172.16.20.221 --topic test --from-beginning
- 测试:在生产者输入test,可以在消费者的两台服务器上看到同样的字符test,说明Kafka服务器集群已搭建成功。
四、完整的Nacos配置
spring:
jackson:
time-zone: Asia/Shanghai
date-format: yyyy-MM-dd HH:mm:ss
servlet:
multipart:
max-file-size: 2048MB
max-request-size: 2048MB
security:
oauth2:
resourceserver:
jwt:
jwk-set-uri: 'http://127.0.0.1/gitegg-oauth/oauth/public_key'
autoconfigure:
# 动态数据源排除默认配置
exclude:
- com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
- org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
dynamic:
# 设置默认的数据源或者数据源组,默认值即为master
primary: master
# 设置严格模式,默认false不启动. 启动后在未匹配到指定数据源时候会抛出异常,不启动则使用默认数据源.
strict: false
# 开启seata代理,开启后默认每个数据源都代理,如果某个不需要代理可单独关闭
seata: false
#支持XA及AT模式,默认AT
seata-mode: AT
druid:
initialSize: 1
minIdle: 3
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: config,stat,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000;
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
datasource:
master:
url: jdbc:mysql://127.0.0.188/gitegg_cloud?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
cloud:
sentinel:
filter:
enabled: true
transport:
port: 8719
dashboard: 127.0.0.188:8086
eager: true
datasource:
ds2:
nacos:
data-type: json
server-addr: 127.0.0.188:8848
dataId: ${spring.application.name}-sentinel
groupId: DEFAULT_GROUP
rule-type: flow
gateway:
discovery:
locator:
enabled: true
routes:
- id: gitegg-oauth
uri: lb://gitegg-oauth
predicates:
- Path=/gitegg-oauth/**
filters:
- StripPrefix=1
- id: gitegg-service-system
uri: lb://gitegg-service-system
predicates:
- Path=/gitegg-service-system/**
filters:
- StripPrefix=1
- id: gitegg-service-extension
uri: lb://gitegg-service-extension
predicates:
- Path=/gitegg-service-extension/**
filters:
- StripPrefix=1
- id: gitegg-service-base
uri: lb://gitegg-service-base
predicates:
- Path=/gitegg-service-base/**
filters:
- StripPrefix=1
- id: gitegg-code-generator
uri: lb://gitegg-code-generator
predicates:
- Path=/gitegg-code-generator/**
filters:
- StripPrefix=1
plugin:
config:
# 是否开启Gateway日志插件
enable: true
# requestLog==true && responseLog==false时,只记录请求参数日志;responseLog==true时,记录请求参数和返回参数。
# 记录入参 requestLog==false时,不记录日志
requestLog: true
# 生产环境,尽量只记录入参,因为返回参数数据太大,且大多数情况是无意义的
# 记录出参
responseLog: true
# all: 所有日志 configure:serviceId和pathList交集 serviceId: 只记录serviceId配置列表 pathList:只记录pathList配置列表
logType: all
serviceIdList:
- "gitegg-oauth"
- "gitegg-service-system"
pathList:
- "/gitegg-oauth/oauth/token"
- "/gitegg-oauth/oauth/user/info"
stream:
binders:
defaultRabbit:
type: rabbit
environment: #配置rabbimq连接环境
spring:
rabbitmq:
host: 127.0.0.225
username: admin
password: 123456
virtual-host: /
kafka:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: 127.0.0.220:9092,127.0.0.221:9092,127.0.0.222:9092
zkNodes: 127.0.0.220:2181,127.0.0.221:2181,127.0.0.222:2181
# 自动创建Topic
auto-create-topics: true
bindings:
output_operation_log:
destination: operation-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: kafka
output_api_log:
destination: api-log #exchange名称,交换模式默认是topic
content-type: application/json
binder: defaultRabbit
input_operation_log:
destination: operation-log
content-type: application/json
binder: kafka
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
input_api_log:
destination: api-log
content-type: application/json
binder: defaultRabbit
group: ${spring.application.name}
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量,默认1
redis:
database: 1
host: 127.0.0.188
port: 6312
password: 123456
ssl: false
timeout: 2000
redisson:
config: |
singleServerConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: 123456
subscriptionsPerConnection: 5
clientName: null
address: "redis://127.0.0.188:6312"
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
connectionMinimumIdleSize: 32
connectionPoolSize: 64
database: 0
dnsMonitoringInterval: 5000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
#业务系统相关初始化参数
system:
#登录密码默认最大尝试次数
maxTryTimes: 5
#不需要验证码登录的最大次数
maxNonCaptchaTimes: 2
#注册用户默认密码
defaultPwd: 12345678
#注册用户默认角色ID
defaultRoleId: 4
#注册用户默认组织机构ID
defaultOrgId: 79
#不需要数据权限过滤的角色key
noDataFilterRole: DATA_NO_FILTER
#AccessToken过期时间(秒)默认为2小时
accessTokenExpiration: 60
#RefreshToken过期时间(秒)默认为24小时
refreshTokenExpiration: 300
logging:
config: http://${spring.cloud.nacos.discovery.server-addr}/nacos/v1/cs/configs?dataId=log4j2.xml&group=${spring.nacos.config.group}
file:
# 配置日志的路径,包含 spring.application.name Linux: /var/log/${spring.application.name}
path: D:\\log4j2_nacos\\${spring.application.name}
feign:
hystrix:
enabled: false
compression:
# 配置响应 GZIP 压缩
response:
enabled: true
# 配置请求 GZIP 压缩
request:
enabled: true
# 支持压缩的mime types
mime-types: text/xml,application/xml,application/json
# 配置压缩数据大小的最小阀值,默认 2048
min-request-size: 2048
client:
config:
default:
connectTimeout: 8000
readTimeout: 8000
loggerLevel: FULL
#Ribbon配置
ribbon:
#请求连接的超时时间
ConnectTimeout: 50000
#请求处理/响应的超时时间
ReadTimeout: 50000
#对所有操作请求都进行重试,如果没有实现幂等的情况下是很危险的,所以这里设置为false
OkToRetryOnAllOperations: false
#切换实例的重试次数
MaxAutoRetriesNextServer: 5
#当前实例的重试次数
MaxAutoRetries: 5
#负载均衡策略
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule
#Sentinel端点配置
management:
endpoints:
web:
exposure:
include: '*'
mybatis-plus:
mapper-locations: classpath*:/com/gitegg/*/*/mapper/*Mapper.xml
typeAliasesPackage: com.gitegg.*.*.entity
global-config:
#主键类型 0:"数据库ID自增", 1:"用户输入ID",2:"全局唯一ID (数字类型唯一ID)", 3:"全局唯一ID UUID";
id-type: 2
#字段策略 0:"忽略判断",1:"非 NULL 判断"),2:"非空判断"
field-strategy: 2
#驼峰下划线转换
db-column-underline: true
#刷新mapper 调试神器
refresh-mapper: true
#数据库大写下划线转换
#capital-mode: true
#逻辑删除配置
logic-delete-value: 1
logic-not-delete-value: 0
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 多租户配置
tenant:
# 是否开启租户模式
enable: true
# 需要排除的多租户的表
exclusionTable:
- "t_sys_district"
- "t_sys_tenant"
- "t_sys_role"
- "t_sys_resource"
- "t_sys_role_resource"
- "oauth_client_details"
# 租户字段名称
column: tenant_id
# 数据权限
data-permission:
# 注解方式默认关闭,否则影响性能
annotation-enable: true
seata:
enabled: false
application-id: ${spring.application.name}
tx-service-group: gitegg_seata_tx_group
# 一定要是false
enable-auto-data-source-proxy: false
service:
vgroup-mapping:
#key与上面的gitegg_seata_tx_group的值对应
gitegg_seata_tx_group: default
config:
type: nacos
nacos:
namespace:
serverAddr: 127.0.0.188:8848
group: SEATA_GROUP
userName: "nacos"
password: "nacos"
registry:
type: nacos
nacos:
#seata服务端(TC)在nacos中的应用名称
application: seata-server
server-addr: 127.0.0.188:8848
namespace:
userName: "nacos"
password: "nacos"
#验证码配置
captcha:
#验证码的类型 sliding: 滑动验证码 image: 图片验证码
type: sliding
aj:
captcha:
#缓存local/redis...
cache-type: redis
#local缓存的阈值,达到这个值,清除缓存
#cache-number=1000
#local定时清除过期缓存(单位秒),设置为0代表不执行
#timing-clear=180
#验证码类型default两种都实例化。
type: default
#汉字统一使用Unicode,保证程序通过@value读取到是中文,在线转换 https://tool.chinaz.com/tools/unicode.aspx 中文转Unicode
#右下角水印文字(我的水印)
water-mark: GitEgg
#右下角水印字体(宋体)
water-font: 宋体
#点选文字验证码的文字字体(宋体)
font-type: 宋体
#校验滑动拼图允许误差偏移量(默认5像素)
slip-offset: 5
#aes加密坐标开启或者禁用(true|false)
aes-status: true
#滑动干扰项(0/1/2) 1.2.2版本新增
interference-options: 2
# 接口请求次数一分钟限制是否开启 true|false
req-frequency-limit-enable: true
# 验证失败5次,get接口锁定
req-get-lock-limit: 5
# 验证失败后,锁定时间间隔,s
req-get-lock-seconds: 360
# get接口一分钟内请求数限制
req-get-minute-limit: 30
# check接口一分钟内请求数限制
req-check-minute-limit: 60
# verify接口一分钟内请求数限制
req-verify-minute-limit: 60
#SMS短信通用配置
sms:
#手机号码正则表达式,为空则不做验证
reg:
#负载均衡类型 可选值: Random、RoundRobin、WeightRandom、WeightRoundRobin
load-balancer-type: Random
web:
#启用web端点
enable: true
#访问路径前缀
base-path: /commons/sms
verification-code:
#验证码长度
code-length: 6
#为true则验证失败后删除验证码
delete-by-verify-fail: false
#为true则验证成功后删除验证码
delete-by-verify-succeed: true
#重试间隔时间,单位秒
retry-interval-time: 60
#验证码有效期,单位秒
expiration-time: 180
#识别码长度
identification-code-length: 3
#是否启用识别码
use-identification-code: false
redis:
#验证码业务在保存到redis时的key的前缀
key-prefix: VerificationCode
# 网关放行设置 1、whiteUrls不需要鉴权的公共url,白名单,配置白名单路径 2、authUrls需要鉴权的公共url
oauth-list:
staticFiles:
- "/doc.html"
- "/webjars/**"
- "/favicon.ico"
- "/swagger-resources/**"
whiteUrls:
- "/*/v2/api-docs"
- "/gitegg-oauth/login/phone"
- "/gitegg-oauth/login/qr"
- "/gitegg-oauth/oauth/token"
- "/gitegg-oauth/oauth/public_key"
- "/gitegg-oauth/oauth/captcha/type"
- "/gitegg-oauth/oauth/captcha"
- "/gitegg-oauth/oauth/captcha/check"
- "/gitegg-oauth/oauth/captcha/image"
- "/gitegg-oauth/oauth/sms/captcha/send"
- "/gitegg-service-base/dict/list/{dictCode}"
authUrls:
- "/gitegg-oauth/oauth/logout"
- "/gitegg-oauth/oauth/user/info"
- "/gitegg-service-extension/extension/upload/file"
- "/gitegg-service-extension/extension/dfs/query/default"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号