
个人项目
一、本次项目的介绍:
| 有关本次项目的Github链接 | 请点击这里进行跳转 |
|---|---|
| 本次项目的目标 | 进行论文的查重 |
二、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 240 | 180 |
| Development | 开发 | 1200 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 1000 | 100 |
| Design Spec | 生成设计文档 | 200 | 60 |
| Design Review | 设计复审 | 100 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| Design | 具体设计 | 120 | 60 |
| Coding | 具体编码 | 300 | 160 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 10 |
| Reporting | 报告 | 1000 | 240 |
| Test Report | 测试报告 | 500 | 250 |
| Size Measurement | 计算工作量 | 60 | 60 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进划 | 60 | 60 |
| Addition | 合计 | 5020 | 1540 |
三、计算模块接口的设计与实现过程:
前言:
本次设计只有一个函数,这个函数的算法由本人自己设计,未曾看过任何有关查重的文章与博客,不过不排除有其他的大牛设计过这样的算法。不过该算法目前仍算半成品,只适用与两篇相似度较高的文章进行比对查重。
算法核心:
把原文和抄袭的文章通过“,”分成两个字符串数组,然后运用UTF-8编码把每个字符串编码为他们的数字序列,并对这些序列中的每个数值取绝对值并求和,可得到两个求和数组,即分别为原文和抄袭文章的字符串数组的每个字符串元素的求和而得到的求和数组。例如,原文为“你好,你是一个人吗”,可得到两个原文的字符串数组为[你好,你是一个人吗]两个元素,通过UTF-8绝对值求和可得到求和数组[50,650]。(注意,这里只是举例,结果不一定为50和650)。相应的,抄袭文章也可以得到这样的数组,再通过数值比对,用小的那个求和值除大的那个求和值,即可得出每一个元素的查重率。最后再把所有的查重率相加取平均值可得到最终的查重率,非常好用!当然,关于他的优缺点,以下会作出一些有关情况的分析,如果读者也有其他的问题或者想法,也欢迎留言与我进行讨论,我会及时回复的。
这个函数算法目前的优点:
1.对于通过原文的增删减而得到的文章有较高的查重率,约为80%左右。
2.对于试图通过进行句子中的文字进行顺序颠倒,或者肆意换行的抄袭行为,具有高达百分之九十九的查重率,这种行为在这种算法面前无所遁形,避无可避,死路一条。
3.如果是不相似的文章进行比对,查重率结果会较低。
4.所有计算都是UTF-8编码求值,具有极其优良的可移植性,不会因软件测试环境,硬件环境而出现任何误差,除非你电脑的编码映射出现了问题,不能进行UTF-8编码。
这个函数算法目前的缺点及相关改进想法:
1.抄袭文章基于原文增加了大量的“,”这种标点符号,会导致字符串数组的大小不一,不易比对,解决方法可以通过进行两两元素继续相加求和,类似归并排序那样,再每每进行比对,预测时间复杂度O(nlogn)。
2.当抄袭文章进行句子或者句子之间的排序转换,即字符串的数组中的元素乱序,从而导致比对结果出现偏差,不过要想解决也并不难,把每一个字符串数组的元素与另一个字符串的数组的元素进行局部比对就可,又或者以文章的每一行来进行比对,用readline()来得到,又或者文章的每一段进行局部比对,预测时间复杂度O(n^2),这样可以减少误差,或者用更好的权重比对,每个部分设定适合的权重来取得最后的查重率。为什么要局部比对?答案很简单,如果你非要说把文章的第一句和最后一句互换,可以当我没说,我想没有哪篇抄袭文章能抄得这么离谱吧。
四、计算模块接口部分的性能改进
计算改进,由于我对java编程仍不是十分了解所以用了不少循环,其实感觉大可不必,不过现在我还没有太好的改进想法
以下为性能分析图:
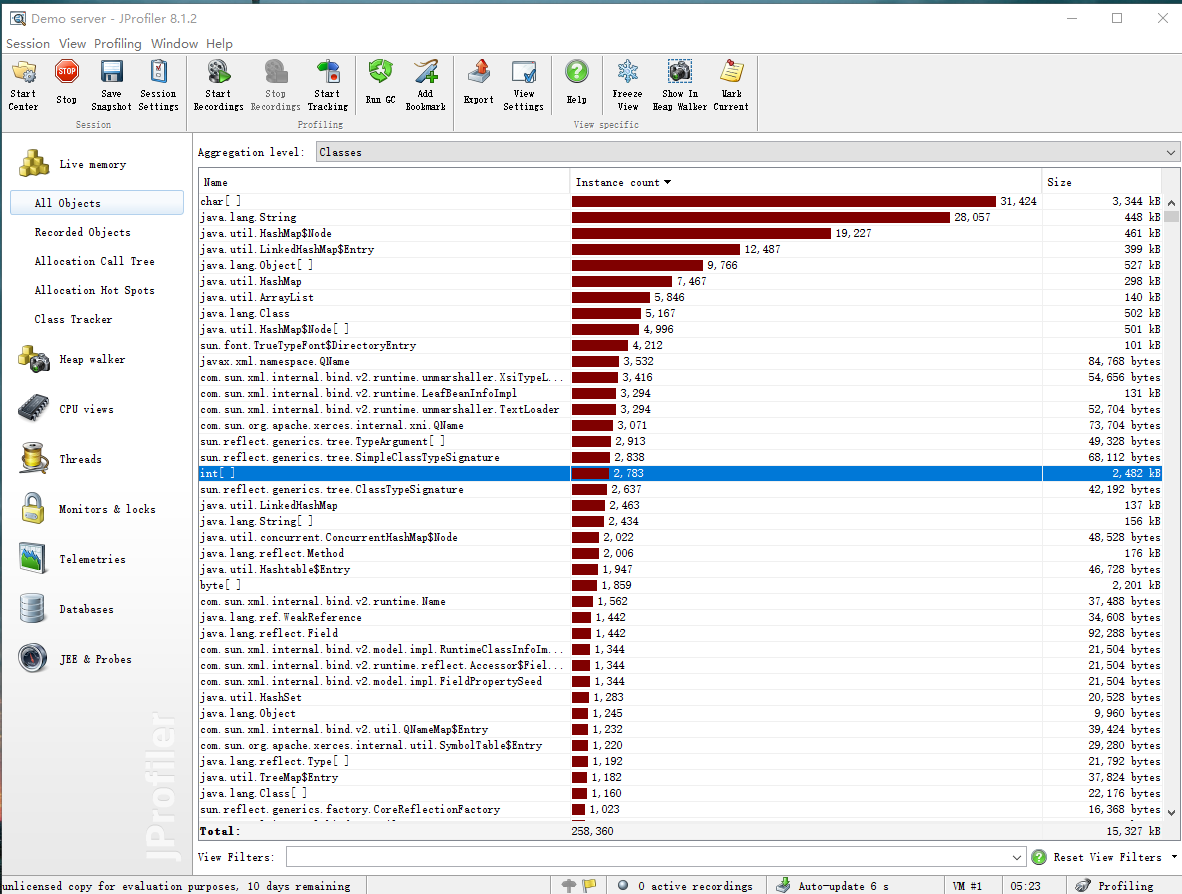
五、计算模块部分单元测试展示
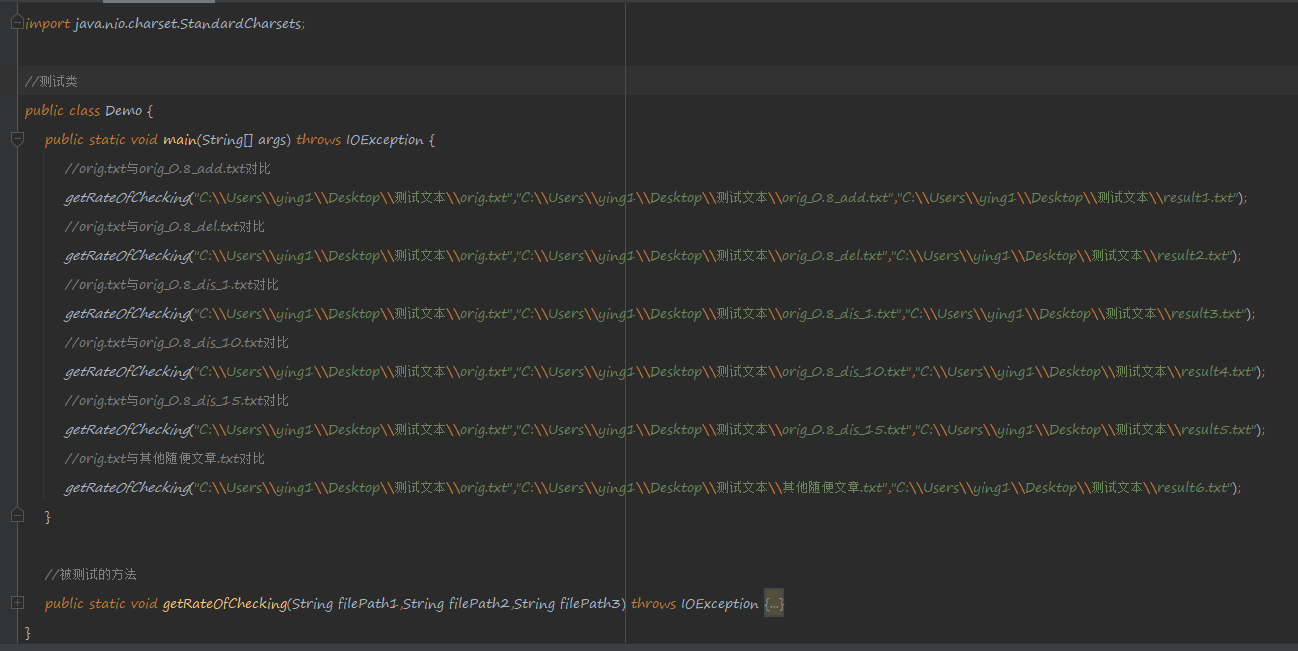
先创建一个测试类,把方法导进去进行测试,如图:
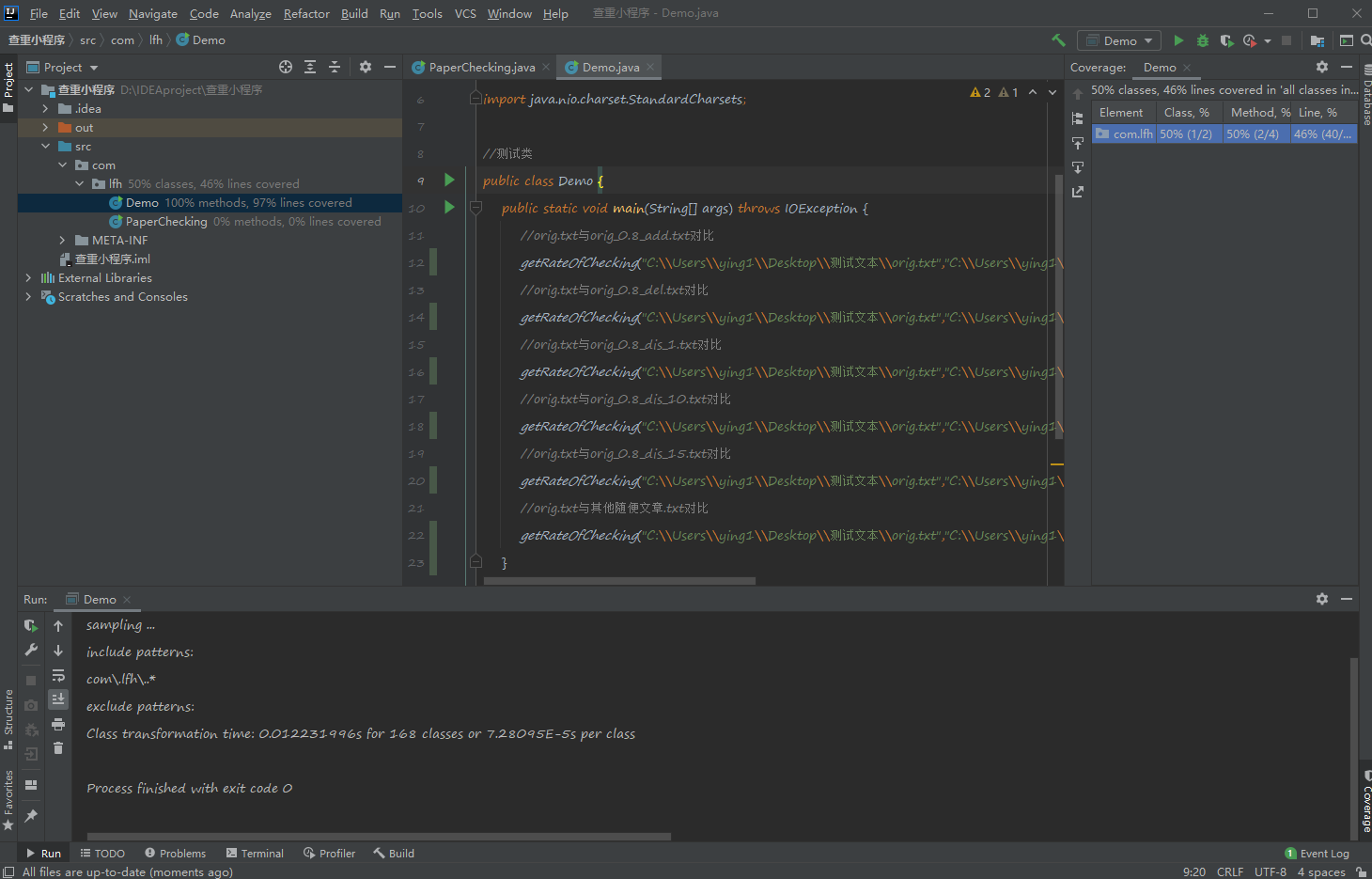
可观测其代码覆盖率:
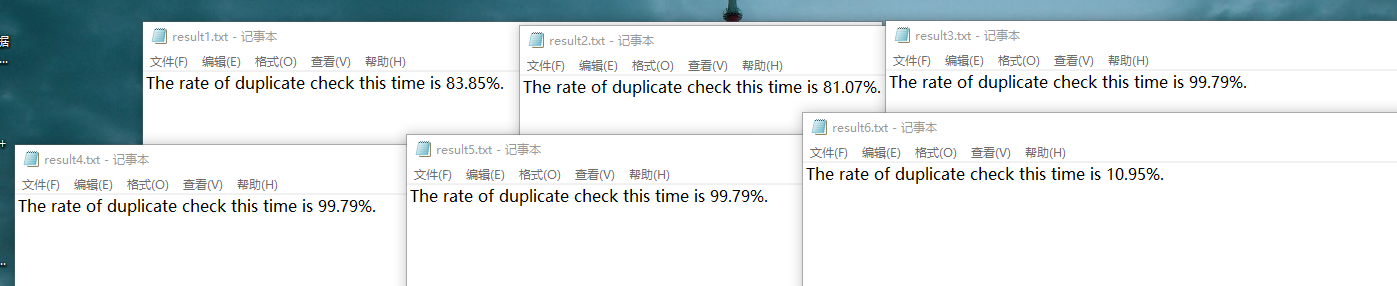
查重结果:(注:result6为两篇几乎完全不同文章的对比)
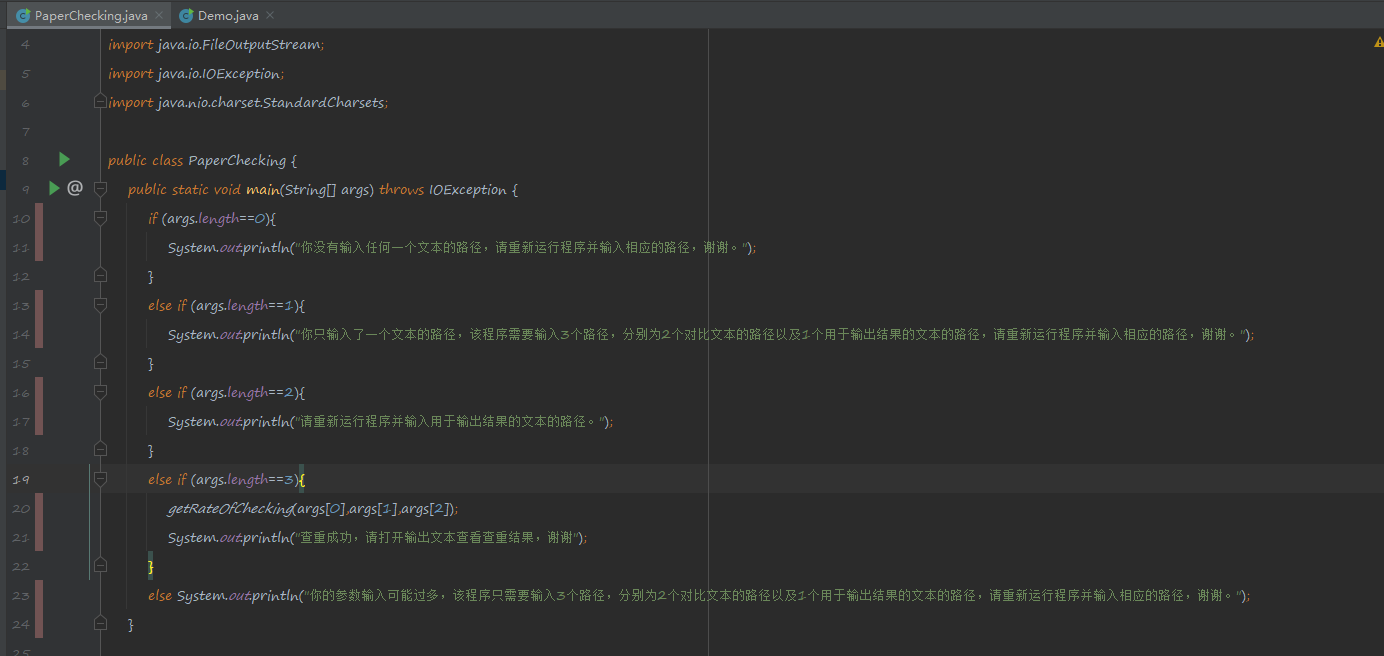
六、计算模块部分异常处理说明
异常处理如图:
七、结言
感谢大家的阅读,如有问题或者一些想法想与我探讨,欢迎发送邮件到lfh15819293595@outlook.com,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号