
Stream是Java8中新加入的api,更准确的说:
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作 。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。
以前我们处理复杂的数据只能通过各种for循环,不仅不美观,而且时间长了以后可能自己都看不太明白以前的代码了,但有Stream以后,通过filter,map,limit等等方法就可以使代码更加简洁并且更加语义化。
Stream 创建
在使用流之前,首先需要拥有一个数据源,并通过StreamAPI提供的一些方法获取该数据源的流对象。有很多方法可以创建不同源的 stream 实例,stream 实例一旦创建,将不会修改其源,因此我们从单个源创建多个 stream 实例。
Empty Stream
如果我们想创建一个空的 Stream,可以使用 empty() 方法,具体如下:
Stream<String> iteblogEmptyStream = Stream.empty();
通常在 streams 没有元素然后不想返回 null 的情况下使用:
public Stream<String> streamOf(List<String> list) { return list == null || list.isEmpty() ? Stream.empty() : list.stream(); }
通过集合(Collection)创建 Stream
Java 中的任何继承 Collection 接口的类都可以创建 Stream:
List<String> list = Lists.newArrayList("iteblog", "iteblog_hadoop");
Stream<String> listStream = list.stream();
Set<String> set = Sets.newHashSet();
Stream<String> setStream = set.stream();
通过数组(Array)创建 Stream
数组也可以创建 Stream:
Stream<String> streamOfArray = Stream.of("a", "b", "c");
当然,我们也可以通过已有的数组来创建 Stream :
String[] iteblogArr = new String[]{"iteblog", "iteblog_hadoop", "java 8"}; Stream<String> streamOfArrayFull = Arrays.stream(iteblogArr); Stream<String> streamOfArrayPart = Arrays.stream(iteblogArr, 1, 3);
通过 Stream.builder() 创建 Stream Stream 提供了 builder 方法来创建 Stream:
Stream streamBuilder = Stream.builder().add("iteblog").add("iteblog_hadoop").add("java").build();
Stream<Object> streamBuilder = Stream.builder().add("iteblog").add("iteblog_hadoop").add("java").build();
上面创建的 Stream 类型是 Stream,如果我们想创建指定类型的 Stream,需要显示地指定类型
Stream<String> streamBuilder = Stream.<String>builder().add("iteblog").add("iteblog_hadoop").add("java").build();
通过 Stream.generate() 创建 Stream Stream.generate() 方法接收一个 Supplier 类型的参数来生成元素,生成的 stream 大小是无限的,所以我们需要指定 stream 生成的大小,以免出现内存不够的问题:
Stream<String> streamGenerated = Stream.generate(() -> "iteblog").limit(88);
通过 Stream.iterate() 创建 Stream 我们也可以通过 Stream.iterate() 来创建 Stream
Stream<Integer> streamIterated = Stream.iterate(2, n -> n * 2).limit(88);
Stream.iterate 方法的第一个参数将是这个 Stream 的第一个值,第二个元素将是前一个元素乘以 2。和 Stream.generate() 方法一样,我们也需要指定 stream 生成的大小,以免出现内存不够的问题。
通过原子类型创建 Stream
Java 8 中的 int, long 和 double 三个原子类型可以用来创建 streams,对应的接口分别是 IntStream, LongStream, DoubleStream
IntStream intStream = IntStream.range(0, 10); LongStream longStream = LongStream.rangeClosed(0, 10); DoubleStream doubleStream = DoubleStream.of(1.0, 2.0); range(int startInclusive, int endExclusive)
相当于下面的代码:
for (long i = startInclusive; i < endExclusive ; i++) { ... } rangeClosed(int startInclusive, int endInclusive)
相当于下面的代码:
for (long i = startInclusive; i <= endInclusive ; i++) { ... }
区别大家应该看出来了:rangeClosed 生成的 Stream 包含最后一个元素,而 range 缺不是。当然,Java 8 中的 Random 类也为我们添加了生成上面三个原子类型对应的 Stream:
Random random = new Random(); IntStream intStream = random.ints(10); LongStream longs = random.longs(10); DoubleStream doubleStream = random.doubles(10);
通过字符串创建 Stream
Java 8 中的 String 类提供了 chars() 方法来创建 Stream:
IntStream streamOfChars = "abc".chars();
我们也可以通过下面方法来创建 Stream:
Stream<String> streamOfString = Pattern.compile(", ").splitAsStream("a, b, c");
通过文件创建 Stream
Java 8 的 Java NIO 类中 Files 允许我们通过 lines() 方法创建 Stream,文件中的每一行数据将变成 stream 中的一个元素:
Path path = Paths.get("/user/iteblog/test.txt");
Stream<String> streamOfStrings = Files.lines(path);
Stream<String> streamWithCharset = Files.lines(path, Charset.forName("UTF-8"));
Stream的分类
Stream可以分为串行与并行两种,串行流和并行流差别就是单线程和多线程的执行。
- default Stream stream() : 返回串行流
- default Stream parallelStream() : 返回并行流
stream()和parallelStream()方法返回的都是java.util.stream.Stream<E>类型的对象,说明它们在功能的使用上是没差别的。唯一的差别就是单线程和多线程的执行。
操作符
中间操作符
对于数据流来说,中间操作符在执行制定处理程序后,数据流依然可以传递给下一级的操作符。
中间操作符包含8种(排除了parallel,sequential,这两个操作并不涉及到对数据流的加工操作):
- map(mapToInt,mapToLong,mapToDouble) 转换操作符,把比如A->B,这里默认提供了转int,long,double的操作符。
- flatmap(flatmapToInt,flatmapToLong,flatmapToDouble) 拍平操作比如把 int[]{2,3,4} 拍平 变成 2,3,4 也就是从原来的一个数据变成了3个数据,这里默认提供了拍平成int,long,double的操作符。
- limit 限流操作,比如数据流中有10个 我只要出前3个就可以使用。
- distint 去重操作,对重复元素去重,底层使用了equals方法。
- filter 过滤操作,把不想要的数据过滤。
- peek 挑出操作,如果想对数据进行某些操作,如:读取、编辑修改等。
- skip 跳过操作,跳过某些元素。
- sorted(unordered) 排序操作,对元素排序,前提是实现Comparable接口,当然也可以自定义比较器。
终止操作符
数据经过中间加工操作,就轮到终止操作符上场了;终止操作符就是用来对数据进行收集或者消费的,数据到了终止操作这里就不会向下流动了,终止操作符只能使用一次。
- collect 收集操作,将所有数据收集起来,这个操作非常重要,官方的提供的Collectors 提供了非常多收集器,可以说Stream 的核心在于Collectors。
- count 统计操作,统计最终的数据个数。
- findFirst、findAny 查找操作,查找第一个、查找任何一个 返回的类型为Optional。
- noneMatch、allMatch、anyMatch 匹配操作,数据流中是否存在符合条件的元素 返回值为bool 值。
- min、max 最值操作,需要自定义比较器,返回数据流中最大最小的值。
- reduce 规约操作,将整个数据流的值规约为一个值,count、min、max底层就是使用reduce。
- forEach、forEachOrdered 遍历操作,这里就是对最终的数据进行消费了。
- toArray 数组操作,将数据流的元素转换成数组。
Stream 的一系列操作必须要使用终止操作,否者整个数据流是不会流动起来的,即处理操作不会执行。
map
可以看到 map 操作符要求输入一个Function的函数是接口实例,功能是将T类型转换成R类型的。
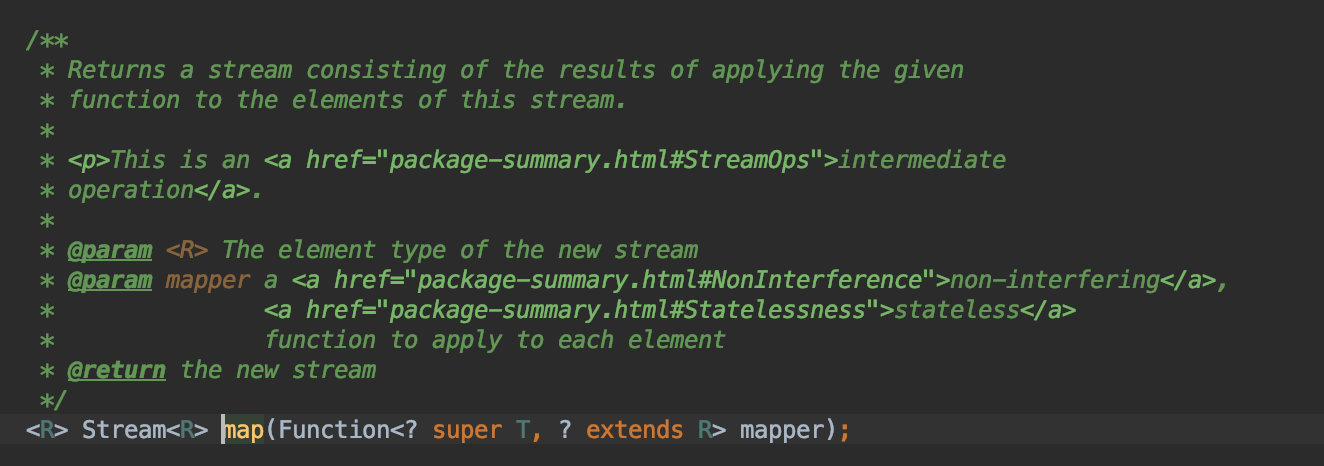
map操作将原来的单词 转换成了每个单的长度,利用了String自身的length()方法,该方法返回类型为int。
public class Main { public static void main(String[] args) { Stream.of("apple","banana","orange","waltermaleon","grape") .map(e->e.length()) //转成单词的长度 int .forEach(e->System.out.println(e)); //输出 } }
当然也可以这样,这里使用了成员函数引用。
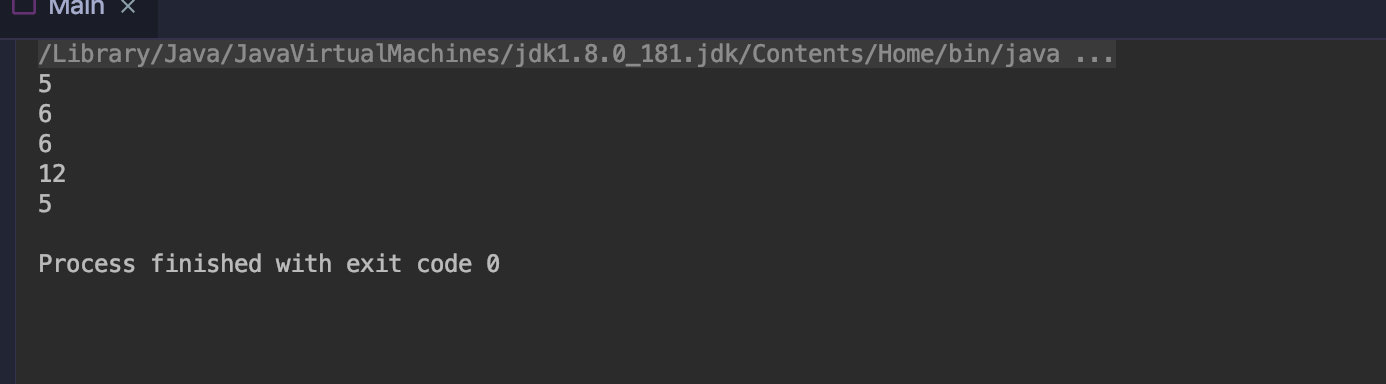
public class Main { public static void main(String[] args) { Stream.of("apple","banana","orange","waltermaleon","grape") .map(String::length) //转成单词的长度 int .forEach(System.out::println); } }
结果如图:
- mapToInt 将数据流中得元素转成Int,这限定了转换的类型Int,最终产生的流为IntStream,及结果只能转化成int。
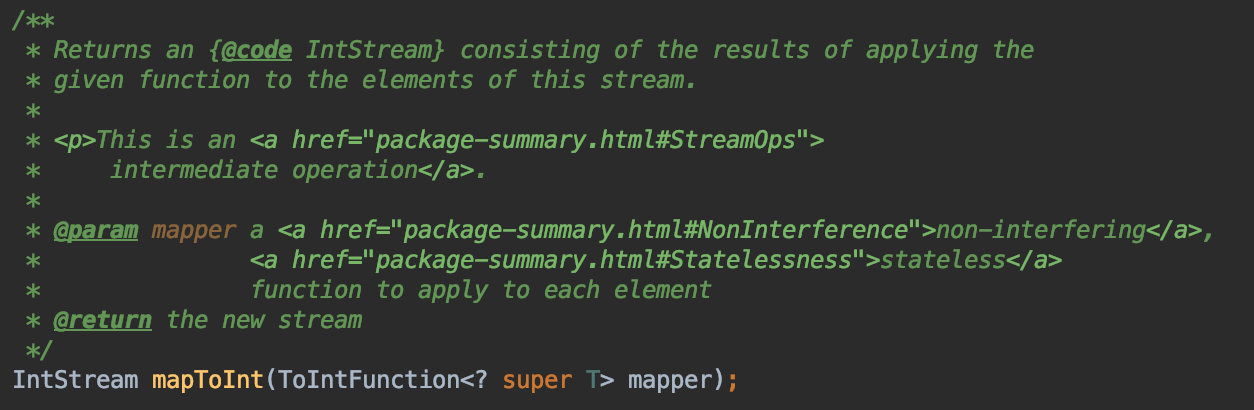
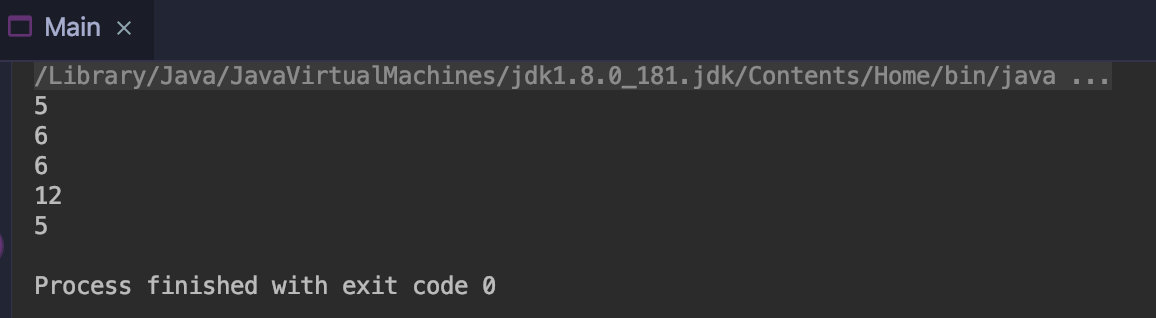
public class Main { public static void main(String[] args) { Stream.of("apple", "banana", "orange", "waltermaleon", "grape") .mapToInt(e -> e.length()) //转成int .forEach(e -> System.out.println(e)); } }
mapToInt如图:
mapToLong、mapToDouble 与mapToInt 类似。
- flatmap 作用就是将元素拍平拍扁 ,将拍扁的元素重新组成Stream,并将这些Stream 串行合并成一条Stream
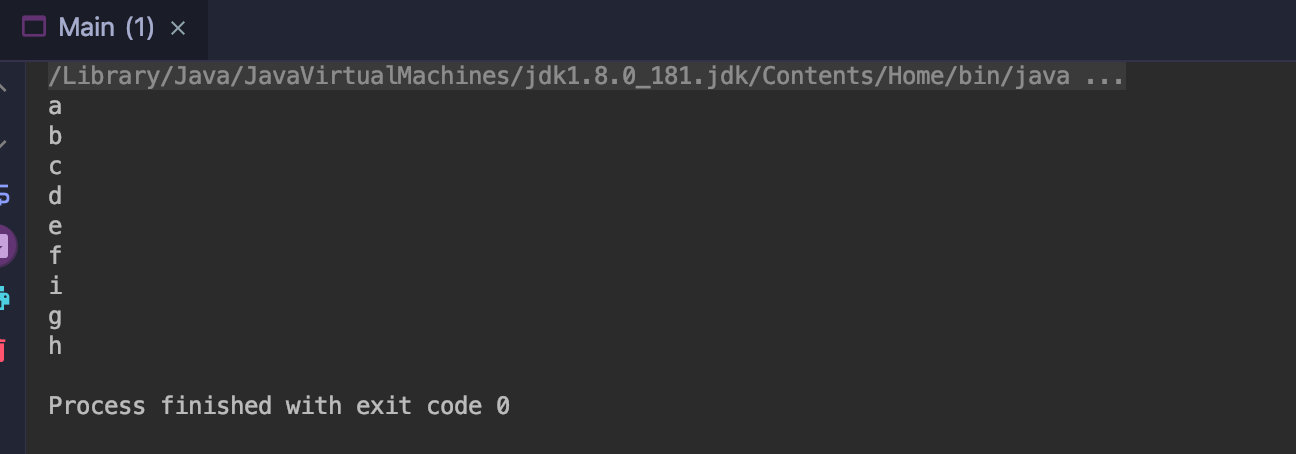
public class Main { public static void main(String[] args) { Stream.of("a-b-c-d","e-f-i-g-h") .flatMap(e->Stream.of(e.split("-"))) .forEach(e->System.out.println(e)); } }
flatmap 如图:
-
flatmapToInt、flatmapToLong、flatmapToDouble 跟flatMap 都类似的,只是类型被限定了,这里就不在举例子了。
-
limit 限制元素的个数,只需传入 long 类型 表示限制的最大数
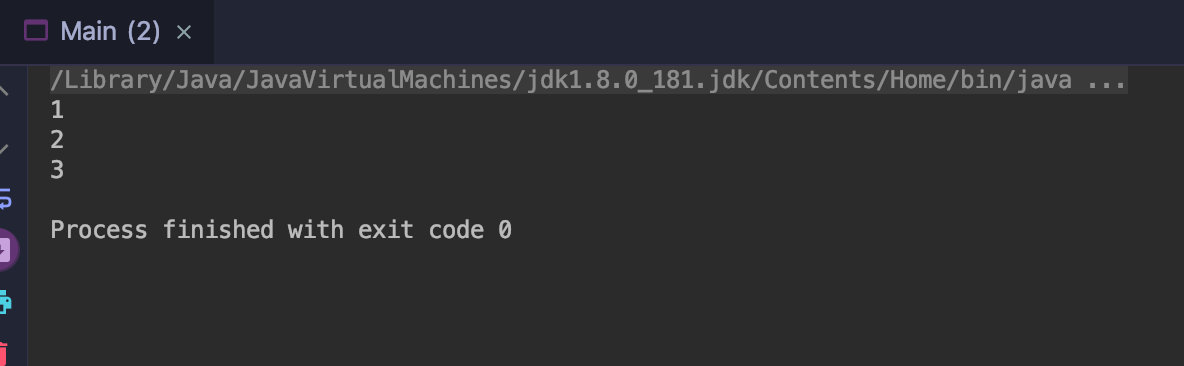
public class Main { public static void main(String[] args) { Stream.of(1,2,3,4,5,6) .limit(3) //限制三个 .forEach(e->System.out.println(e)); //将输出 前三个 1,2,3 } }
limit如图:
- filter 对某些元素进行过滤,不符合筛选条件的将无法进入流的下游
public class Main { public static void main(String[] args) { Stream.of(1,2,3,1,2,5,6,7,8,0,0,1,2,3,1) .filter(e->e>=5) //过滤小于5的 .forEach(e->System.out.println(e)); } }
- peek 挑选 ,将元素挑选出来,可以理解为提前消费
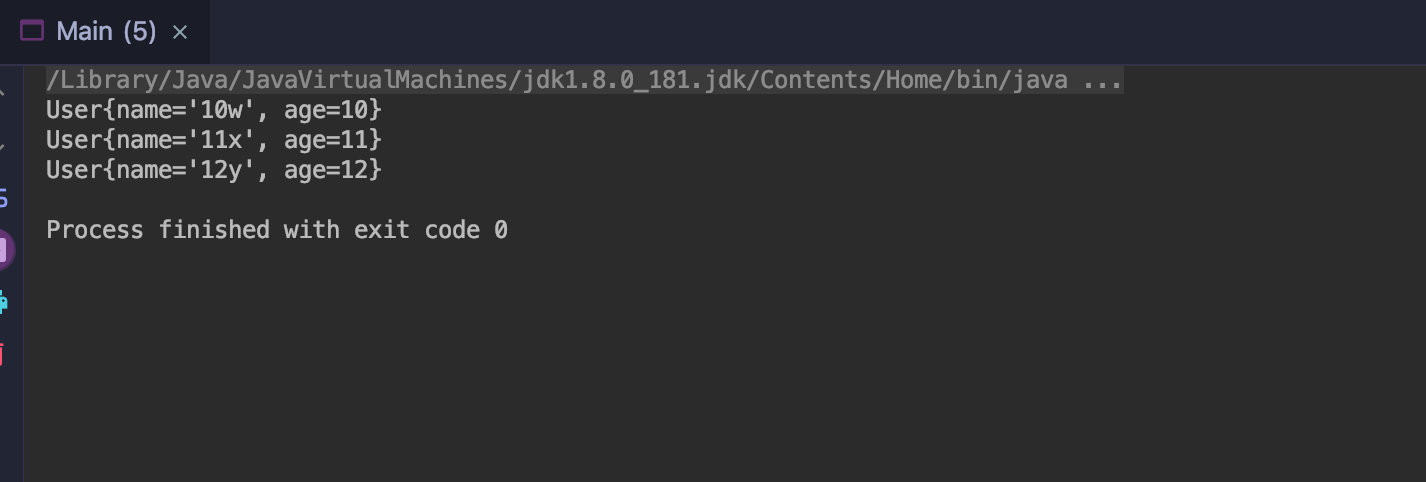
public static void main(String[] args) { User w = new User("w",10); User x = new User("x",11); User y = new User("y",12); Stream.of(w,x,y) .peek(e->{e.setName(e.getAge()+e.getName());}) //重新设置名字 变成 年龄+名字 .forEach(e->System.out.println(e.toString())); }
peek 如图:
- skip 跳过 元素
public class Main { public static void main(String[] args) { Stream.of(1,2,3,4,5,6,7,8,9) .skip(4) //跳过前四个 .forEach(e->System.out.println(e)); //输出的结果应该只有5,6,7,8,9 } }
- collect 收集,使用系统提供的收集器可以将最终的数据流收集到List,Set,Map等容器中。
这里我使用collect 将元素收集到一个list中
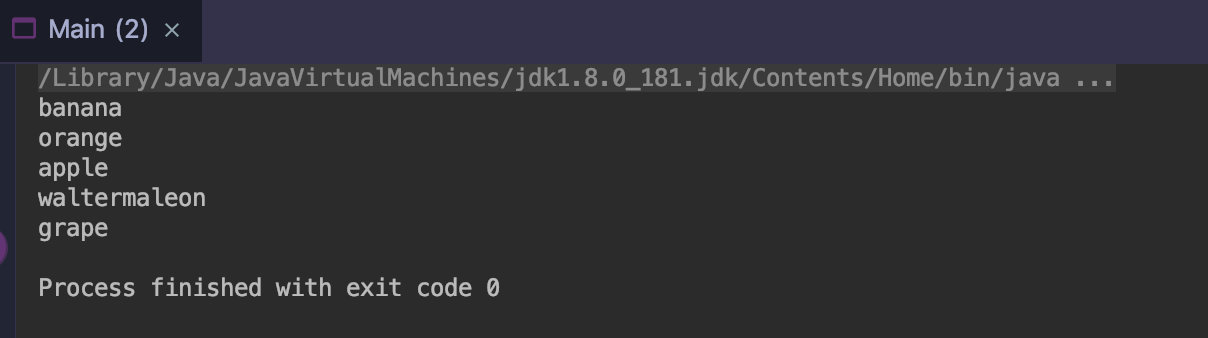
public class Main { public static void main(String[] args) { Stream.of("apple", "banana", "orange", "waltermaleon", "grape") .collect(Collectors.toList()) //list容器 .forEach(e -> System.out.println(e)); } }
不是说终止操作符只能使用一次吗,为什么这里调用了forEach 呢?forEach不仅仅是是Stream 中得操作符还是各种集合中得一个语法糖。
public class Main { public static void main(String[] args) { List<String> stringList = Stream.of("apple", "banana", "orange", "waltermaleon", "grape") .collect(Collectors.toList()); //收集的结果就是list stringList.forEach(e->System.out.println(e)); list的语法糖forEach }
结果如图:
- count 统计数据流中的元素个数,返回的是long 类型
public class Main { public static void main(String[] args) { long count = Stream.of("apple", "banana", "orange", "waltermaleon", "grape") .count(); System.out.println(count); } }
- findFirst 获取流中的第一个元素
public class FindFirst { public static void main(String[] args) { Optional<String> stringOptional = Stream.of("apple", "banana", "orange", "waltermaleon", "grape") .findFirst(); //这里找到第一个元素 apple stringOptional.ifPresent(e->System.out.println(e)); } }
- noneMatch 数据流中得没有一个元素与条件匹配的
这里 的作用是是判断数据流中 一个都没有与aa 相等元素 ,但是流中存在 aa ,所以最终结果应该是false
public class NoneMatch { public static void main(String[] args) { boolean result = Stream.of("aa","bb","cc","aa") .noneMatch(e->e.equals("aa")); System.out.println(result); } }
- allMatch和anyMatch 一个是全匹配,一个是任意匹配 和noneMatch 类似,这里就不在举例了。
- min 最小的一个,传入比较器,也可能没有(如果数据流为空)
public class Main { public static void main(String[] args) { Optional<Integer> integerOptional = Stream.of(0,9,8,4,5,6,-1) .min((e1,e2)->e1.compareTo(e2)); integerOptional.ifPresent(e->System.out.println(e)); }
- max 元素中最大的,需要传入比较器,也可能没有(流为Empty时)
public class Main { public static void main(String[] args) { Optional<Integer> integerOptional = Stream.of(0,9,8,4,5,6,-1) .max((e1,e2)->e1.compareTo(e2)); integerOptional.ifPresent(e->System.out.println(e)); } }
- reduce 是一个规约操作,所有的元素归约成一个,比如对所有元素求和,乘啊等。
这里实现了一个加法,指定了初始化的值
public class Main { public static void main(String[] args) { int sum = Stream.of(0,9,8,4,5,6,-1) .reduce(0,(e1,e2)->e1+e2); System.out.println(sum); //31 } }
- toArray 转成数组,可以提供自定义数组生成器
public class ToArray { public static void main(String[] args) { Object[] objects=Stream.of(0,2,6,5,4,9,8,-1) .toArray(); for (int i = 0; i < objects.length; i++) { System.out.println(objects[i]); } } }
Collectors
Collectors是一个工具类,是JDK预实现Collector的工具类,它内部提供了多种Collector,我们可以直接拿来使用,非常方便。
-
toCollection
将流中的元素全部放置到一个集合中返回,这里使用Collection,泛指多种集合。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
List<String> ll = list.stream().collect(Collectors.toCollection(LinkedList::new));
-
toList
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
List<String> ll = list.stream().collect(Collectors.toList());
-
toSet
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
Set<String> ss = list.stream().collect(Collectors.toSet());
-
joining
joining的目的是将流中的元素全部以字符序列的方式连接到一起,可以指定连接符,甚至是结果的前后缀。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
// 无参方法
String s = list.stream().collect(Collectors.joining());
System.out.println(s);
// 结果:1234567891101212121121asdaa3e3e3e2321eew
// 指定连接符
String ss = list.stream().collect(Collectors.joining("-"));
System.out.println(ss);
// 结果:123-456-789-1101-212121121-asdaa-3e3e3e-2321eew
// 指定连接符和前后缀
String sss = list.stream().collect(Collectors.joining("-","S","E"));
System.out.println(sss);
// 结果:S123-456-789-1101-212121121-asdaa-3e3e3e-2321eewE
- mapping
这个映射是首先对流中的每个元素进行映射,即类型转换,然后再将新元素以给定的Collector进行归纳。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
List<Integer> ll = list.stream().limit(5).collect(Collectors.mapping(Integer::valueOf,Collectors.toList()));
实例中截取字符串列表的前5个元素,将其分别转换为Integer类型,然后放到一个List中返回。
-
collectingAndThen
该方法是在归纳动作结束之后,对归纳的结果进行再处理。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
int length = list.stream().collect(Collectors.collectingAndThen(Collectors.toList(),e -> e.size()));
- counting
该方法用于计数。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
long size = list.stream().collect(Collectors.counting());
- minBy/maxBy
生成一个用于获取最小/最大值的Optional结果的Collector。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
System.out.println(list.stream().collect(Collectors.maxBy((a,b) -> a.length()-b.length())));
// 输出结果:Optional[212121121]
System.out.println(list.stream().collect(Collectors.minBy((a,b) -> a.length()-b.length())));
// 输出结果:Optional[123]
-
summingInt/summingLong/summingDouble
生成一个用于求元素和的Collector,首先通过给定的mapper将元素转换类型,然后再求和。
参数的作用就是将元素转换为指定的类型,最后结果与转换后类型一致。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
int i = list.stream().limit(3).collect(Collectors.summingInt(Integer::valueOf));
// 结果:1368
long l = list.stream().limit(3).collect(Collectors.summingLong(Long::valueOf));
// 结果:1368
double d = list.stream().limit(3).collect(Collectors.summingDouble(Double::valueOf));
// 结果:1368.0
-
groupingBy
这个方法是用于生成一个拥有分组功能的Collector。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
Map<Integer,List<String>> s = list.stream().collect(Collectors.groupingBy(String::length));
// 结果:{3=[123, 456, 789], 4=[1101], 5=[asdaa], 6=[3e3e3e], 7=[2321eew], 9=[212121121]}
Map<Integer,List<String>> ss = list.stream().collect(Collectors.groupingBy(String::length, Collectors.toList()));
// 结果:{3=[123, 456, 789], 4=[1101], 5=[asdaa], 6=[3e3e3e], 7=[2321eew], 9=[212121121]}
Map<Integer,Set<String>> sss = list.stream().collect(Collectors.groupingBy(String::length,HashMap::new,Collectors.toSet()));
// 结果:{3=[123, 456, 789], 4=[1101], 5=[asdaa], 6=[3e3e3e], 7=[2321eew], 9=[212121121]}
-
partitioningBy
该方法将流中的元素按照给定的校验规则的结果分为两个部分,放到一个map中返回,map的键是Boolean类型,值为元素的列表List。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
Map<Boolean,List<String>> map = list.stream().collect(Collectors.partitioningBy(e -> e.length()>5));
// 结果:{false=[123, 456, 789, 1101, asdaa], true=[212121121, 3e3e3e, 2321eew]}
Map<Boolean,Set<String>> map2 = list.stream().collect(Collectors.partitioningBy(e -> e.length()>6,Collectors.toSet()));
// 结果:{false=[123, 456, 1101, 789, 3e3e3e, asdaa], true=[212121121, 2321eew]}
-
summarizingInt/summarizingLong/summarizingDouble
这三个方法适用于汇总的,返回值分别是IntSummaryStatistics,LongSummaryStatistics,DoubleSummaryStatistics。
在这些返回值中包含有流中元素的指定结果的数量、和、最大值、最小值、平均值。所有仅仅针对数值结果。
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
IntSummaryStatistics intSummary = list.stream().collect(Collectors.summarizingInt(String::length));
// 结果:IntSummaryStatistics{count=8, sum=40, min=3, average=5.000000, max=9}
LongSummaryStatistics longSummary = list.stream().limit(4).collect(Collectors.summarizingLong(Long::valueOf));
// 结果:LongSummaryStatistics{count=4, sum=2469, min=123, average=617.250000, max=1101}
DoubleSummaryStatistics doubleSummary = list.stream().limit(3).collect(Collectors.summarizingDouble(Double::valueOf));
// 结果:DoubleSummaryStatistics{count=3, sum=1368.000000, min=123.000000, average=456.000000, max=789.000000}
实例应用
抽取一个对象数组electricFenceVehicleList的id属性组合成id数组
List<Long> idList = electricFenceVehicleList.stream().map(ElectricFenceVehicle::getId).collect(Collectors.toList());
根据对象中的gender属性的值,为genderStr设置不同的值(gender=0设置为男,gender1设置为女)
List<VehDriver> driverList = vehDriverServiceClient.listAll(vehDriver); driverList.stream().peek(e->{if(e.getGender()==0){ e.setGenderStr("男"); }else if(e.getGender()==1){ e.setGenderStr("女"); }else{ e.setGenderStr(""); }}).collect(Collectors.toList());
有一个id的集合driverIdList,还有一个对象集合vehDrivers ,排除对象的id属性包含在driverIdList中的对象并返回过滤后的集合
// 获取司机列表 List<VehDriver> vehDrivers = selectVehDriverList(vehDriverParam); // 根据车辆id查询已绑定的司机id列表 List<Long> driverIdList = getDriverIds(vehDriverParam.getVehicleId()); //排除id属性包含在driverIdList 中的对象 if(!driverIdList.isEmpty()){ return vehDrivers.stream().filter(e-> !driverIdList.contains(e.getId())).collect(Collectors.toList()); }
抽取对象集合的属性并以逗号隔开
Object[] objects = studentList.stream().map(Student::getName).toArray();
String nameData = StringUtils.join(objects, ",");
计算对象集合某个属性的和
List<String> offlineNumList = vehicleOfflineResultList.stream().map(VehicleOfflineResult::getOfflineNum).collect(Collectors.toList()); long totalOfflineNum = offlineNumList.stream().mapToLong(Long::valueOf).sum();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号