arxiv:https://arxiv.org/abs/1703.03400
来源:MoonOut
作者:Chelsea Finn, Pieter Abbeel, Sergey Levine
主要内容:提出了MAML meta-gradient 更新算法,涉及通过梯度的梯度(Gradient by Gradient)。该算法可以找到对任务变化敏感的模型参数,这样当沿着该算式的梯度方向改变时,参数的微小变化将对从数据分布得出的任何任务的损失函数产生很大的改进。
第一次梯度参数更新是为了第二次梯度参数更新,即先算一次梯度,但不作用于原模型,再算一次,才作用于原模型.
Meta-Learning领域非常经典的算法,朴实简洁
Reinforcement Learning Upside Down: Don't Predict Rewards -- Just Map Them to Actions
arxiv:https://arxiv.org/abs/1912.02875
好难读懂........大致和Decision Transformer思想类似,使用action为预测目标、state等为输入的监督学习范式,不过这里模型架构用的是RNN
另外一篇同系列的文章Training Agents using Upside-Down Reinforcement Learning
Plan Your Target and Learn Your Skills: Transferable State-Only Imitation Learning via Decoupled Policy Optimization
When does returnconditioned supervised learning work for offline reinforcement learning?
arxiv:https://arxiv.org/abs/2502.10473
来源:刷arxiv
主要内容:
这篇论文是follow的Trajectory Transformer的工作,属于对TT的改进。模型训练部分与TT完全一致,区别在于decoing阶段即PBS是inference-time算法
主要贡献:将TT中的Planing算法——Beam Search替代为Portfolio Beam Search(PBS),将经济学领域的投资组合优化理论用以改进BS算法。说实话我没有看太懂
作者强调PBS考虑expectation和分布变化的不确定性来确定要保留的相似性,促进多样性。考虑了平均值、协方差等因素。
BS算法是LLM中常用的用来挑选最优轨迹的decoding算法,即PLANNING,目前有很多同类变种。但我感觉这篇文章的工作量不太够
Efficient Exploration via State Marginal Matching
来源:openreview , 检索 state-action marginal时发现的文章(2019)
Off-Policy Deep Reinforcement Learning without Exploration
Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining(偏理论推导)
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Reinforcement Learning Upside Down: Don't Predict Rewards -- Just Map Them to Actions
Plan Your Target and Learn Your Skills: Transferable State-Only Imitation Learning via Decoupled Policy Optimization
来源:Decision-Pretrained Transformer的引文/Openreview
主要内容:对DT+Fewshot实现meta learning/通用性
Human-Timescale Adaptation in an Open-Ended Task Space(Ada)
来源:Decision-Pretrained Transformer的引文/Openreview
作者:Deepmind Adaptive Agnts Team
In-context Reinforcement Learning with Algorithm Distillation (AD)(ICLR2023)
来源:知乎/DPT引文
作者: Deepmind
主要内容
Motivation:Transformer驱动的决策模型,从单任务的DT,到通领域多任务的MGDT和跨领域多任务的GATO,这些都是从离线数据集中学习策略的方法。即Policy Distillation(PD),但PD算法没有体现trial-and-error的学习过程,它属于通过模仿学习从离线RLdata中学习策略。换言之,PD学习策略但不是RL算法,无法通过额外的与环境交互过程提升算法。(从数据集中训练无法体现学习过程)
Algorithm Distillation(AD):transformer represents not only a fixed policy,but a policy improvement operator
AD的目标是建模RL算法,即通过带有模仿损失的离线数据建模实现上下文强化学习,而PD目标是学习解决某具体任务的策略
AD原理:1)通过保存一个RL算法在许多单独任务上的训练过程从而形成一个大型多任务数据集;2)transformer适用前面的学习历史数据作为其上下文进行因果建模。由于源RL算法的策略在整个训练过程都会得到改进,因此AD被迫学习改进运算符(learn the improvement operator)以实现精确建模动作。值得注意的是,transformer模型的上下文长度必须足够大(Long enough to span learning updates,eg. across-episodic,跨场景的),才能捕获训练数据集的改进。
AD 对 state-action-reward token进行建模,并且不以 return 为条件
实验
AD的model可以适用任何序列模型如transformer、RNN、LSTM(见附录),文中主要用transformer,因为其可以并行训练,且效果更好
实验环境:1) Adversarial Bandit;2)Dark Room;3)Dark Key-to-Door ;4)DMLab Watermaze
AD属于 incremental in-context learning,不是 in-context learning。可以划归meta-RL
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning(AAAI2025)
MoM: Linear Sequence Modeling with Mixture-of-Memories(2025)
Rvs: What is essential for offline RL via supervised learning?(ICLR2022)
来源:ICRL综述
作者:Sergey Levine
Goalconditioned reinforcement learning: Problems and solutions
来源:ICRL 综述
作者:Weinan Zhang
来源:Arxiv
作者:Micah Rentschler , Jesse Roberts
主要内容:这篇工作属于ICRL的类别,领域发展脉络从Decision Transformer、到Algorithrm Distillation、再到Decision-Pretrained Transformer,属于监督学习的loss训练范式——最大对数似然估计。针对预训练知识未利用问题和DPT需要其它模型标注最佳动作label的问题,这篇工作提出Deep Q-Learning微调Llm3.1 8bTransformer模型,将DQN中深度神经网络估计Value-function的部分用transformer替代。
优点:使用DQN loss训练方式、Transformer提取上下文信息增强泛化性
缺点:测试环境为Frozen Lake,简单单一,未真正体现通用性
RL
来源:ICLR2017(reject)
Openreview 作者:Yan Duan†‡, John Schulman†‡, Xi Chen†‡, Peter L. Bartlett†, Ilya Sutskever‡, Pieter Abbeel
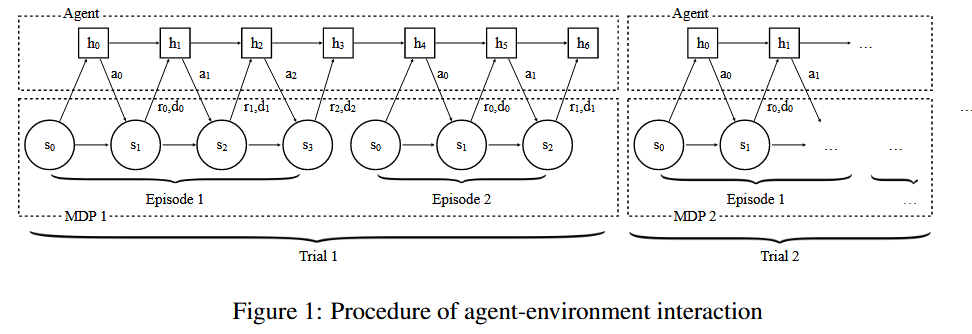
主要内容:Meta-RL领域的开山之作,将多个MDP组成一个trial,MDP中通过RNN(GRUs)输入序列信息,输出action;在trial层次,使用TRPO之类的RL算法从宏观训练,目标是最大化每个trial上的Return。
宏观上是RNN建模的黑盒预测
实验环境是MULTI-ARMED BANDITS、MDP、可视化迷宫
On Designing Effective RL Reward at Training Time for LLM Reasoning
来源:知乎探讨Processing Reward modeling(ICLR2025 Reject)
Openreview
posted @
2025-03-02 21:01
霜尘FrostDust
阅读(
19 )
评论()
编辑
收藏
举报
点击右上角即可分享




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?