第三届智能决策论坛|决策大模型专题报告——随笔(1)
前言
这次汇报的有四位老师,其中我比较感兴趣的是上海交通大学张伟楠老师、北京大学梁一韬老师和清华大学高宸老师的报告,其中张老师之前已经记录过,本文主要作为对梁一韬老师的分享的记录与思考。
CRAFT JARVIS: Towards Generalist Agents in an Open World
Motivation
研究趋势:构造强化学习通用智能体,增强泛化能力,以突破Reward model的设计限制。
从专用性向通用性发展
- 在线学习方式如PPO和Q-learning可以定义出清楚的reward model
- 任务数量上升后,scalar形式的reward model无法unify所有的任务,限制了通用性
- 利用离线学习的大量数据集(状态、动作)通过模仿这个行为来创造决策大模型
- 以MineCraft为例
相关研究
VPT:Learning to Act by Watching Unlabeld Online Videos.(NIPS2022,OpenAI)
- 人工标注
- 训练VPT模型方式是Behaviroal Cloning(GATO采用的方法)
- 采用架构是decode=only,auto-regressively,预测接下来的动作甚至状态
- 环境是MineCraft
- 学会了挖钻石就不会建房子。即任务
泛化的概念:
- 同样的场景,完成不同的任务,是合理的
- 在新的场景做新的任务,需要多维科学领域合作,比较难以实行。
联想到最近读的论文:A Generalist Dynamics Model for Control,文中同样说了,RL领域对比NLP领域大语言模型的成功,目前所需要的是训练一个具有足够通用性的基准模型,在面临新的场景时,只需要few-shot而无需重新更新模型参数就可以实现比较好的应用。有点类似于大语言模型中的prompt提示工程。大语言模型的关键设计是它本质上是predict next token,那么对决策大模型而言,关键的就是如何定义任务,任务定义的足够简洁以至于可以产生预训练范式。
lyt老师对多模态决策模型的态度:跨模态对齐成本太贵了。
因此希望在决策这个单一模态上定义任务。
作为对比,GATO完全是在历史信息上(靠state预测action)做Auto-regressive prediction,是不能具有本质上多任务的能力
对“任务的定义”的研究
GROOT:Learning to Follow Instructions by Watching Gameplay Viedos.
任务的语义探究:不同的任务实际是改变未来遇到的状态的分布概率。 这个比较有意思,对任务的重新定义,此时一条轨迹本身就是一个任务。
继续之前,补充一下VAE的概念
VAE(Variational Autoencoder,变分自编码器),是一种生成模型,通过深度学习框架学习数据的潜在表示并可以用来生成类似数据的新样本。VEA组成:编码器、潜在空间、解码器、变分推理,变分推理是一种近似复杂概率分布的方法,由于传统贝叶斯推断中计算后验分布(即给定观测数据后的模型参数的分布)难以计算,变分推理最大化“证据下界,ELBO”目标函数以衡量选择的变分分布族作为近似分布(通常是参数化的分布)与真实后验分布之间的相似度。
- 训练阶段:VAE通过最小化重构误差和KL散度来训练模型,前者保证生成的数据与输入数据相似,后者确保潜在空间的结构是有规律的。
- 生成阶段:训练完成后,可以从潜在空间随机采样,经过解码器生成新样本。

任务A和任务B的状态分布存在差异,即公式中所述,用未来的状态空间来定义此时的任务,因而使用了VAE框架。
给定trajectory demo数据集,包含任务,将其压缩到Z空间,从z空间抽样又能复原原来的trajectory
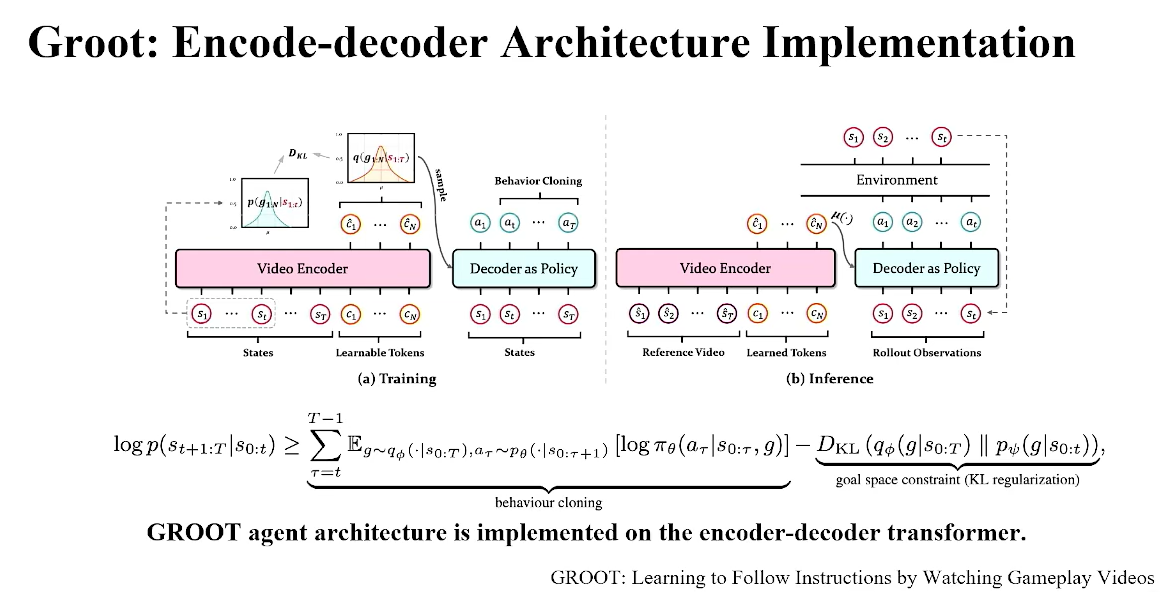
为什么说这里是VAE框架?观察不等式,第一项BC就是VAE中的reconstruction loss,即复原,第二项是KL regulation,代表能不能让z-space能不能处于一个易于被sample的空间下。
现在的困难:训练时提供未来信息容易导致后验坍塌,即模型看着未来预测未来,实际上并没有学习到泛化能力,没有理解trajectory的动作
正在做的工作:让这个z-space具有更强的泛化性
一些验证z-space具有structure,即语义特性的实验:
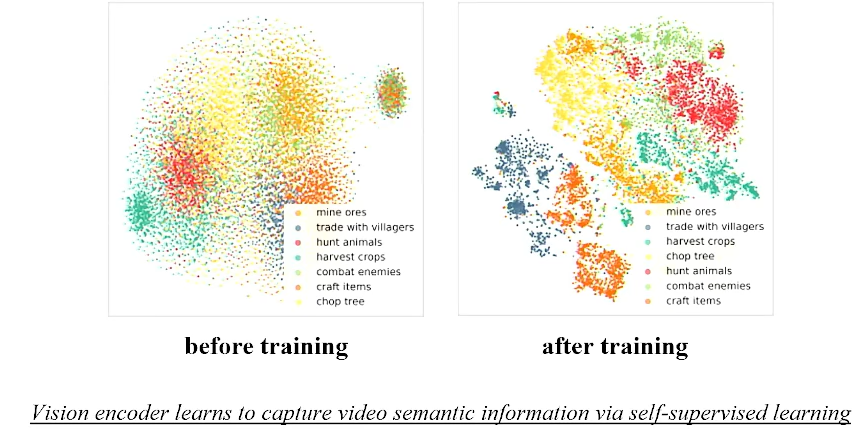
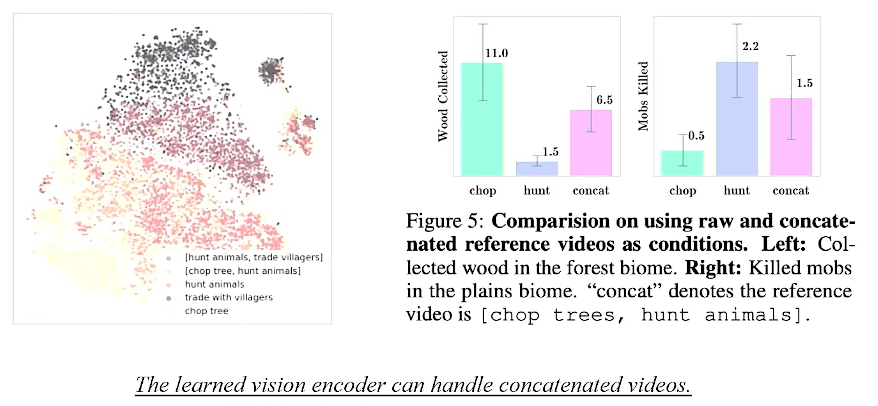
这个图说明了zspace其具备与文字的模态对齐的可能性,另外它还具有泛化的可能性(中间的点:组合动作)
也揭露了zspace中插值补全点的make sense
实验结果:

Take Feedback into Acount => Interactive
Describe,explain,plan and select:Interactive planing with large language models enables open-world multi-task agents
拿视频生成Sora作为类比,稳定生成视频时长提高十倍代表其真实性能提高几万倍,因为每一帧的可能性都是指数增加。
同样的,决策模型能够稳定做出规划的步长也很有挑战性。目前使用end-end的决策模型是不可能生成太长预测的,因为受到数据和硬件资源的限制。
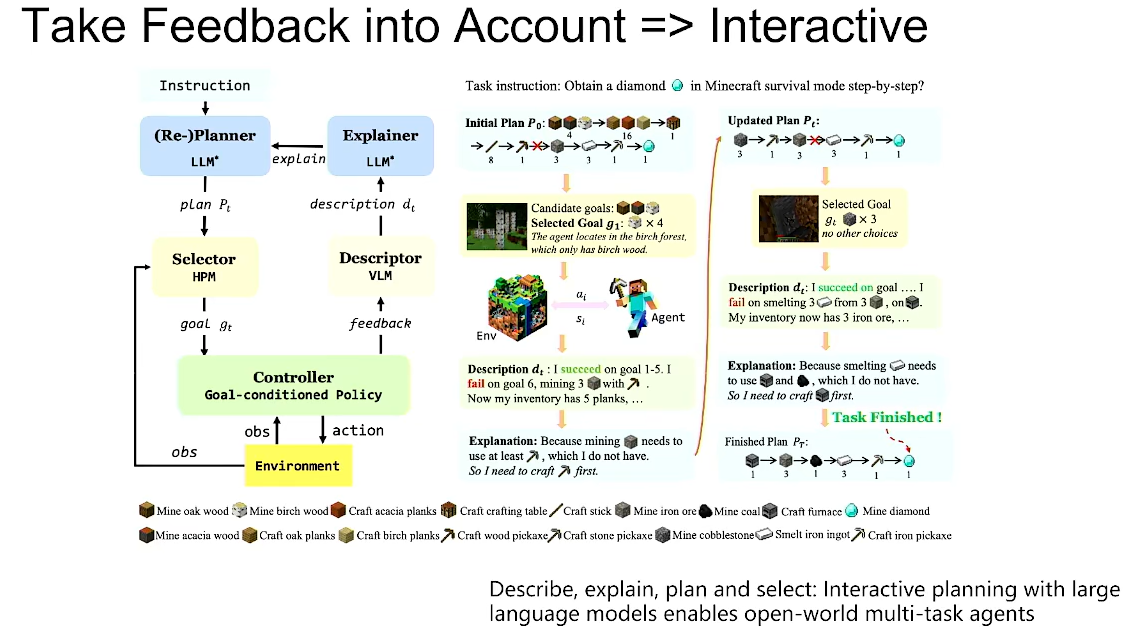
使用任务拆分来提高长期预测稳定性,可以基于大语言模型或者其它技术,偏向LLM的原因是LLM对不可预知性有更好的鲁棒性
Basci building blocks for acbitrary goals.(建立新的Benchmark)
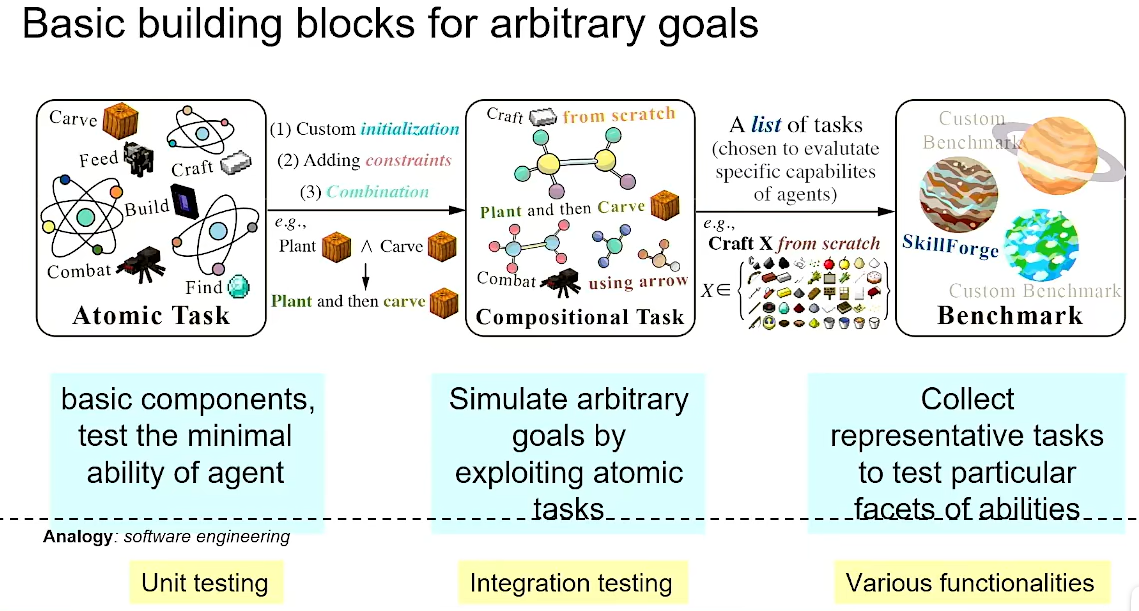
位于CRAFT JARVIS官网,可以完成Minecraft场景下的测试。
总结
- RL由于reward的设计局限性而向离线场景训练的通用智能体发展的趋势
- 在决策单一模态上重新定义任务的内涵,基于Zspace的VAE架构具有语义扩展前景,从而探索预训练范式
- 推荐阅读
- VPT:Learning to Act by Watching Unlabeld Online Videos.(NIPS2022,OpenAI)
- GROOT:Learning to Follow Instructions by Watching Gameplay Viedos.
- Describe,explain,plan and select:Interactive planing with large language models enables open-world multi-task agents

 浙公网安备 33010602011771号
浙公网安备 33010602011771号