Java | Set集合
Set集合
java.util.Set接口也是继承Collection接口,使用方法和Collection里面基本一样,没有太大的改变,所在在这里就不再说方法了,只是在规则上面比Collectioni接口更加的严格了,比如Set接口里面的元素不允许重复出现,并且不能再单独的取出某一个元素了。所以在Set集合中,取出元素的方法以用:迭代器,增强for循环。
Set集合的特点
1、不允许存储重复元素。
2、没有索引,没有带索引的方法,所以也就不能使用普通for循环。
取出set集合里面元素的方法:
Set<String> set = new HashSet<>();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
//迭代器
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//增强for循环
for (String s : set) {
System.out.println(s);
}
哈希表
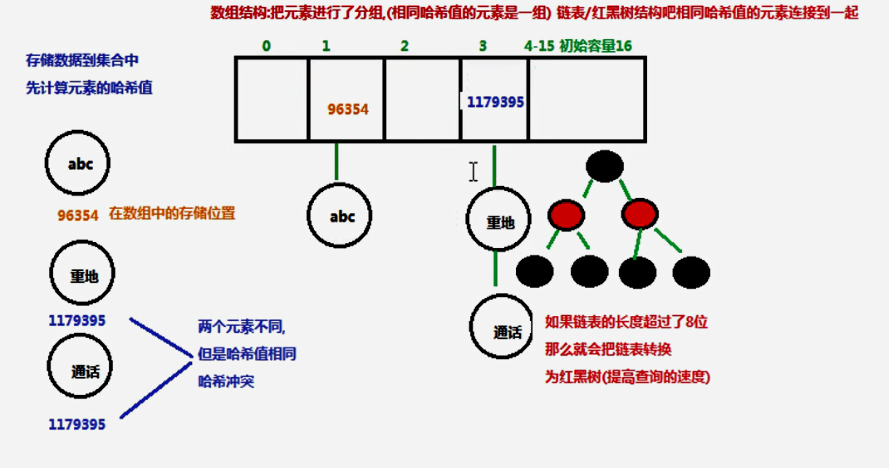
哈希表是是一种数据存储的结构,在java8之前,哈希表底层采用的是数组+链表的实现方法,即同一个hash值的元素存在同一个链表中,但是当hash值相等的元素过多的时候,通过key的查找效率就会变底。所以在java8之后,哈希表的结构就采用了数组+链表+红黑树来实现的,当一个链表元素长度超过8以后,就会自动转换为红黑树来存储,这样大大减少了查找时间。
在java中Object类里面就有取得哈希值的方法hashCode(),下面就看看这个方法的使用:
//创建一个Studet类
Student stu1 = new Student();
Student stu2 = new Student();
//因为所以的类都默认继承了object类,所以都可以使用hashCode方法
//同一个类,创建两个不同的对象,所以哈希值也不一样
System.out.println(stu1.hashCode()); //460141958
System.out.println(stu2.hashCode()); //1163157884
String str1 = new String("a");
String str2 = new String("a");
System.out.println(str1.hashCode()); //97
System.out.println(str2.hashCode()); //97
//在String类型中,哈希值是一样的,是因为String类重写了hashCode方法
//把字符编码转换为哈希值。所以只要内容相同,哈希值就会相同。
在java中基本数据类型,都会重写
hashCode()和equals()等方法。
HashSet集合
java.util.HashSet是Set接口的一个实现类,它的元素也是不可以重复的,并且无序,java.util.HashSet底层是用java.util.HashMap写的,也是一种集合,后面再说。
HastSet是根据对象的哈希值来确定元素在集合中的存储位置,所以存取和查询的速度特别的快。
HashSet集合的特点
1、不允许存储重复的元素。
2、没有索引,所以也就没有带索引的方法,所以就不能使用普通for循环。
3、HashSet是一个无序集合,存的顺序和取的顺序不一样。
4、底层是哈希表现实的。
HashSet集合为什么元素不会重复
先看一个String类型的Set集合:
Set<String> set = new HashSet<>();
set.add("a");
set.add("a");
set.add("b");
set.add("c");
set.add("重地"); //哈希值:1179395
set.add("通话"); //哈希值:1179395
System.out.println(set); //[a, b, 重地, 通话, c]
上面说过了,基本数据类型都会重写,hashCode方法,所以在存取元素的时候,就会比较一个值的哈希值,如果相同,并且内容相同就不会再存储相同的元素,所以说也重写了equals方法。
//如果是一个普通的对象,如果保证宽在Set集合里面是唯一呢?
//在set集合中,存取元素的时候,比较的是hash值,如果hash值相同
//比较的是内容,如果内容不相同就存储,如果内容相同就丢弃
Set<Student> set = new HashSet<>();
set.add(new Student("张三", 18));
set.add(new Student("张三", 18));
System.out.println(set.toString());
//[Student{name='张三', age=18}, Student{name='张三', age=18}]
//可以看出来,这两个对象是一样的,内容也一样,但是为什么全部存储了呢,
//是因为这两个对象的哈希值不一样,所以才会全部存储。
//如果想要不重复,就要重复这个对象里面的hashCode和equals方法
不重写完hashCode和equals方法之后:
Set<Student> set = new HashSet<>();
set.add(new Student("张三", 18));
set.add(new Student("张三", 18));
System.out.println(set.toString());
//[Student{name='张三', age=18}]
所以Set集合里面,如果想要保证自定义对象的唯一性,就必须要重写hashCode和equals方法。
LinkedHashSet集合
在HashSet集合中,元素是唯一的,但是元素存放进去是没有顺序的,如果我们有的时候要求集合必须有序的时候,我们就可以使用LinkedHashSet集合,这个集合,是有序的,并且还有Set集合的特性。
LinkedHashSet和HashSet不同的的是前者还维护着一个运行于所有条目的双重链接列表,这个链表定义了迭代顺序,就是按照元素插入的顺序迭代的。
底层结构是:数组+链表+红黑树,再加一个链表
这个方法的好处,就是提供有序的集合,并且又不引起与TreeSet关联的开销的增加。
LinkedHashSet的简单使用
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("a");
linkedHashSet.add("a");
linkedHashSet.add("c");
linkedHashSet.add("b");
System.out.println(linkedHashSet); //[a, c, b]
关注公众号,随时获取最新资讯

细节决定成败!
个人愚见,如有不对,恳请斧正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号