Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
一、配置前置条件
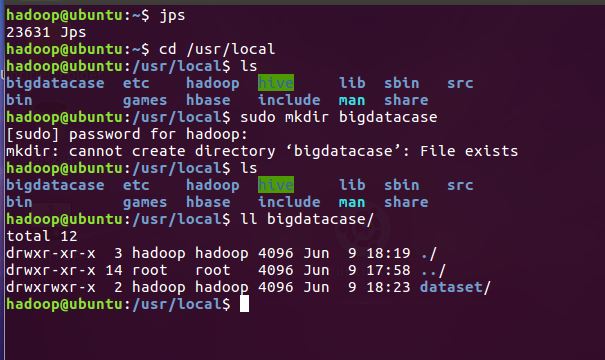
1.将爬虫大作业产生的csv文件上传到LINUX
首先把收集到的数据所生成的csv文件上传到装有MySQL、Hive以及Hadooplinux系
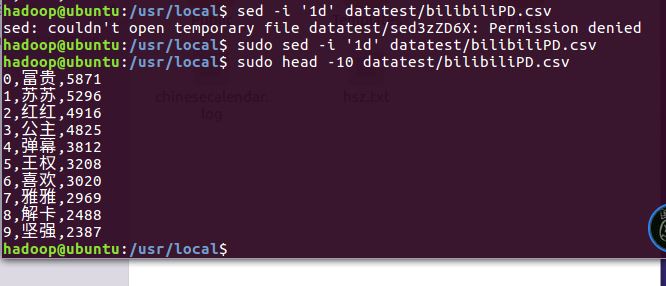
2.对CSV文件进行预处理生成无标题文本文件
利用sed命令删除标题
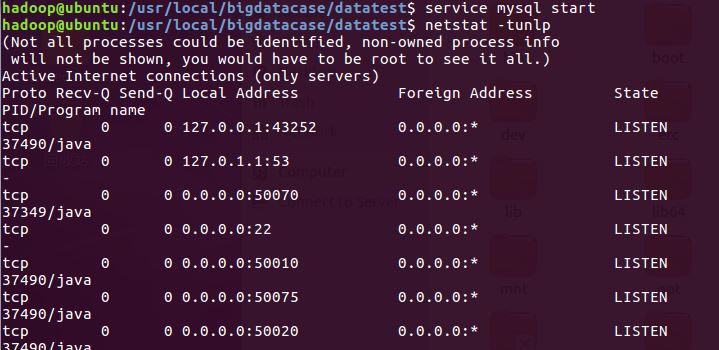
3.把hdfs中的文本文件最终导入到数据仓库Hive中
先启动mysql
后查看上传到hdfs 的文件
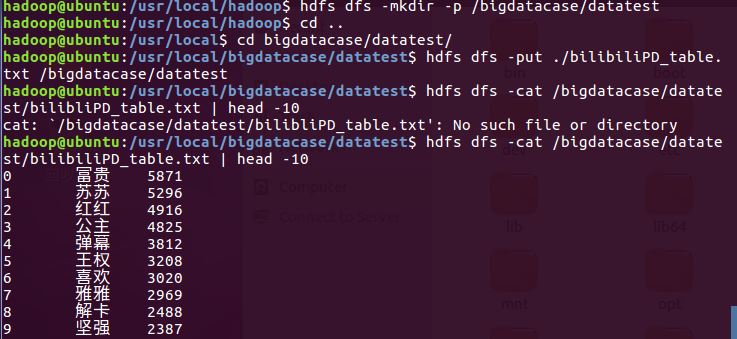
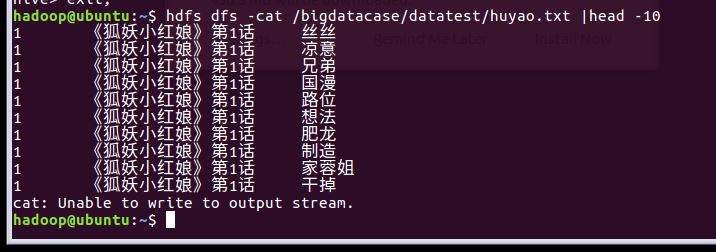
PS:在爬虫大作业期间爬取了大量弹幕数据,保存了两个csv文件,一个bilibiliPD是处理后的有合并排序,另一个yuyao文件是没有经过处理的如下:(将会在数据分析中使用,上传到hadoop以及之前的步骤与上一致)
二.在Hive中查看并分析数据
- 建立与hdfs 对应的数据库表
![]()
![]()


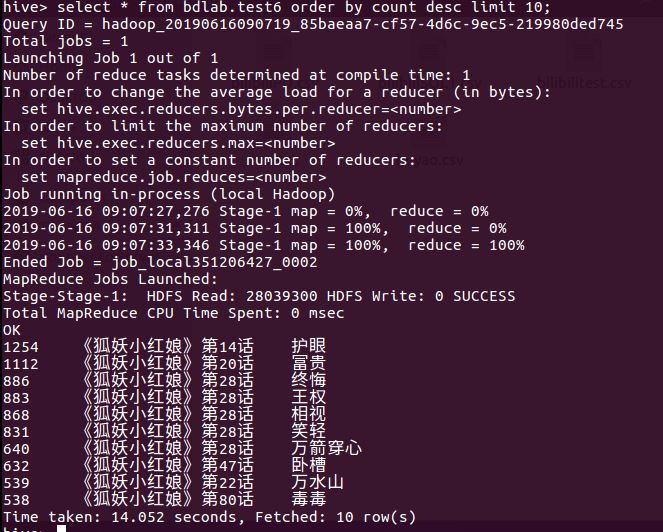
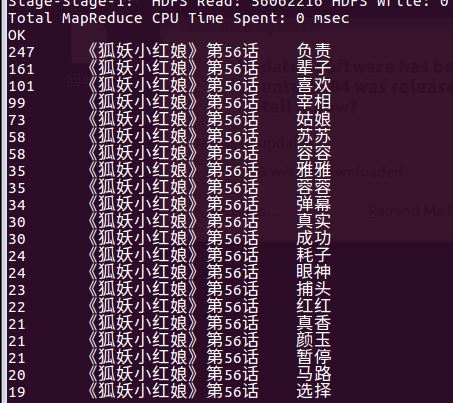
- 查询该系列剧集的全部弹幕数据排行,sql命令如下: select * form bdlab.test6 order by count desc limit 10;
这条查询对应的弹幕可以读出该剧的剧情大概是有古风的动漫,像是护眼,卧槽等词的高频出现是能够说明该剧实在雷人,切作画风格不受人喜爱。
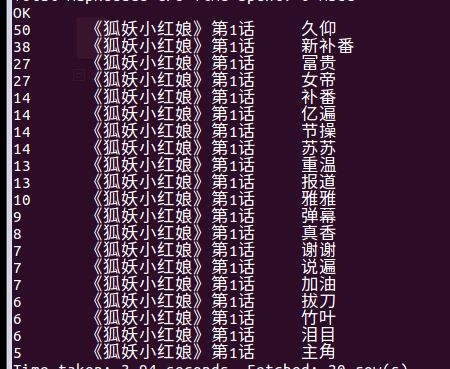
2. 查询关键集的弹幕数据进行对比:
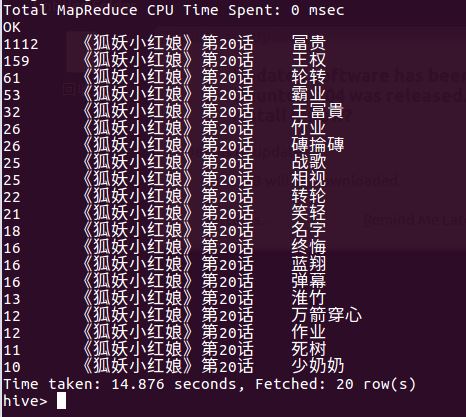
相关语句:select * from bdlab.testi where e_index like '%剧场版%' order by count desc limit 20;
select * from bdlab.testi where e_index = ‘《狐妖小红娘》第一话’ order by count desc limit 20;
在该剧中比较重要的集数就是第一话与剧场版。弹幕数量在普通的单元集中实时弹幕是最多3000条,而剧场版中是8000条,在过滤、筛选了大部分数据后得出也就一半左右的有效数据。
在另一个bilibiliPD的总弹幕统计中大多是人名为,从第一集中看也是确实是人名较多,至于打招呼的词语也是较多。
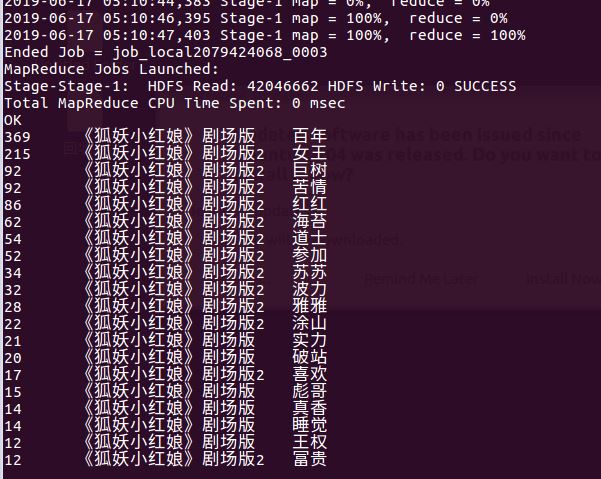
在剧场版中大多是些剧场版中的关键词。剧场版是普通单元集的合集,即是炒冷饭。这与一个道理相符,爱炒冷饭的都是些硬核粉,核心粉。这是一部。。。(不想描述爱情片)。导致这些人都只会关注人物的本身,情情爱爱的事情估摸着就是人物刻画足够深刻才能够吸引更多的粉丝。在该剧中能够看出人物刻画受大众所信仰,整个系列都是奔着人设去的。
随机抽取了20集以及56集都是除了该单元剧中的重要剧情以外都是人物的名称刷榜了。
总结:
本次大作业使用了python爬虫编程,搭建了hadoop分布式文件系统,最后使用了Hive。在Hive利用HDFS存储数据,利用MapReduce查询数据实现大量数据的操作。
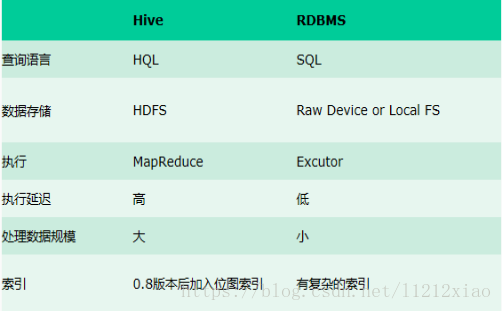
通过这次大作业练习运用了python爬取网页上的内容,熟练地运用hadoop分布式系统。在使用hive处理数据的时候,有明显地感觉到与普通sql的查询是有不同。输入sql查询语句会有MapReduce的处理过程。
关于处理弹幕的时候,能够清晰地发现弹幕文化是娱乐文化。在禁用词表中禁用的词语本人只禁用了一些通用的语气词和大量出现的无用词组,发现在处理后的弹幕中还是只是对人物进行描述,而没有其他令人印象深刻的描述。
在对应单元集中的弹幕是有对该集有概括性的弹幕,但是没有有意思的词成为高频词。作为一部超过80集的动漫来说,让一些仅仅刷无聊的梗成为高频词还是有点可惜。没有像一些百万播放数的短视频那样有肉眼可见的高频词。
是弹幕文化只是一种无聊的吐槽,还是爱好聚集的地方。还是需要更多的数据分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号