安装关系型数据库MySQL 安装大数据处理框架Hadoop
1.Hadoop的介绍
- Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
- ——分布式文件系统(GFS),可用于处理海量网页的存储
- ——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
- 狭义上来说,hadoop就是单独指代hadoop这个软件,
- 广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
2.Hadoop是什么?
- Hadoop: 适合大数据的分布式存储和计算平台
- Hadoop不是指具体一个框架或者组件,它是Apache软件基金会下用Java语言开发的一个开源分布式计算平台。实现在大量计算机组成的集群中对海量数据进行分布式计算。适合大数据的分布式存储和计算平台。
- Hadoop1.x中包括两个核心组件:MapReduce和Hadoop Distributed File System(HDFS)
- 其中HDFS负责将海量数据进行分布式存储,而MapReduce负责提供对数据的计算结果的汇总
3.Hadoop的起源
- 2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
- 2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
- 2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
- Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
- Hadoop的成长过程
- Lucene–>Nutch—>Hadoop
- 总结起来,Hadoop起源于Google的三大论文
- GFS:Google的分布式文件系统Google File System
- MapReduce:Google的MapReduce开源分布式并行计算框架
- BigTable:一个大型的分布式数据库
- 演变关系
- GFS—->HDFS
- Google MapReduce—->Hadoop MapReduce
- BigTable—->HBase
4.Hadoop的四大特性(优点)
- 1.扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点中。
- 2.成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 3.高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 4.可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖
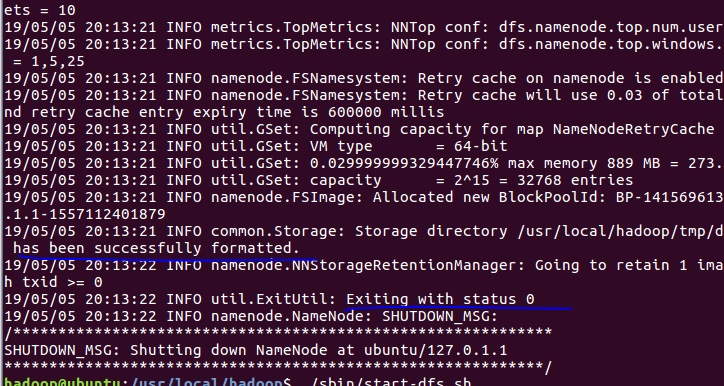
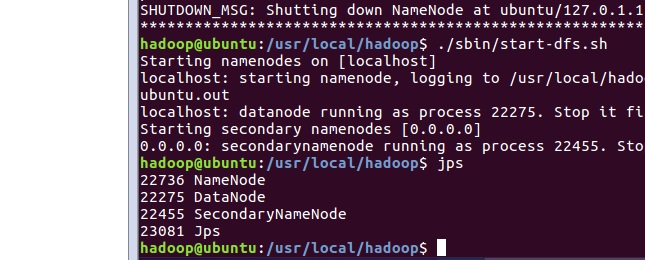
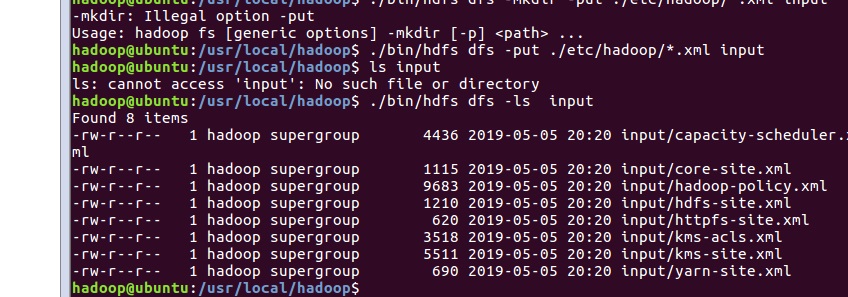
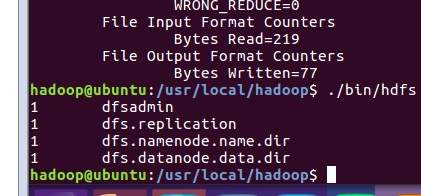
实验完成图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号