
复合数据类型,英文词频统计
1.列表,元组,字典,集合分别如何增删改查及遍历。
- 列表
增:list是一个可变的有序表,所以,可以往list中追加元素到末尾:classmates.append('Adam')删:要删除list末尾的元素,用pop()方法;要删除指定位置的元素,用pop(i)方法,其中i是索引位置;改:要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:classmates[1] = 'Sarah'查:变量classmates就是一个list。用len()函数可以获得list元素的个数; - 元组
元组定义以后是不可以变的,没有删除,增加的机能。
改:不可以改tupple的元素,可以改指向的list的本身。
查:与list基本一致 - 字典
增:原有dict['key']="value",如
dict['School'] = "RUNOOB" # 添加
删:
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空词典所有条目
del dict # 删除词典
改:用赋值号进行修改其中的值
查:可根据key值查找 - 集合
增:set=set(["1","2","3","4","5"]);
删:set.remove(key)
改:str是不变对象,而list是可变对象。
查:可根据key值查找
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 列表
- 元组
- 字典
- 集合
列表(list):列表是一组有序项目的数字结构,列表的项目应该放在方括号[ ]中,列表是可以被改变和可重复的;按照索引的方式查找通过偏移存储并且元素可以任意类型存在。
元组(tuple):元组与列表十分相似,可重复也是通过偏移的方式进行存储,不过元组是不可变的即是你是不能对元组中的元素进行修改,而且用的是();元组的元素是固定的长度、异构,也是任意嵌套。
字典(dict):字典使用的是{},字典是无序的,但是可变可重复;使用键-值(key-value)进行存储,查找速度快;字典的key是不能变的,list不能作为key,字符串、元祖、整数等都可以。
集合(set):无序不可变,使用([ ]),与字典类似,但只包含键,而没有对应的值;元素可以是列表、元组、字典中的任意一个或多个。
存储与查找方式
| 列表(list) | 元组(tuple) | 集合(set) | 字典(dict) | |
| 括号 | [ ] | () | ([]) | {} |
| 有无序 | 有 | 有 | 无 | 有 |
| 可不可变 | 可变 | 不可变 | 可变 | 可变 |
| 是否重复 | 是 | 是 | 否 | 否 |
| 查找方式 | 索引 | 索引 | 无 | 键值 |
3.词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)
- 9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
if __name__ == '__main__':fo = open("oldman.txt", 'r' ,encoding="utf-8")
#读取英文文章
text = fo.read()
#大写转小写
text = text.lower()
#停用列表
strs = {",", '.', "?", "!", ';'}
stops = {'one','this','and','"i','them','what','will','am','from','when','who','him','do','had','no','if','they','as','all','so','very','is','his','by','but','to','of','he','that','you','was','it','the','a','i','in','my','not','have','are','me','for','be','at','on','with'}
#替换符号为空格
for str in strs:
text = text.replace(str, "")
#分割单词
text = text.split()
#转为集合
spliText = set(text)
spliText = spliText - stops
#统计词频
textS = {}#转化为字典
for i in spliText:
count = text.count(i)
textS[i] = count
#排序输出
textS = sorted(textS.items(), key=lambda text:text[1],reverse= True)
print(textS[0:10],"\n",textS[10:20])
#输出到csv文件
pd.DataFrame(data=textS).to_csv('out.csv',encoding='utf-8')
生成的词云
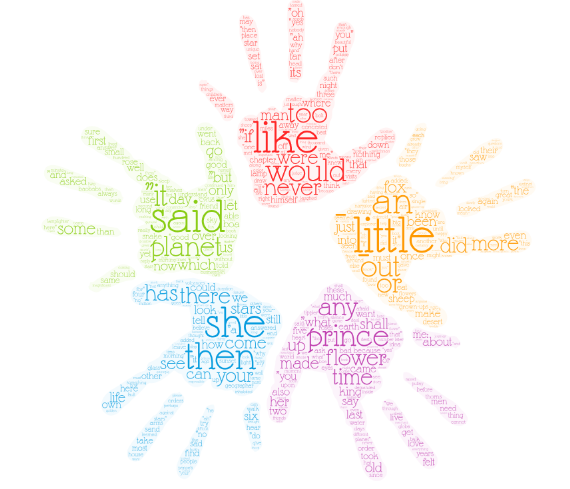
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create

