
python 正则指北之我的总结
本文经本人搜索网络加上个人理解整理而成,如有侵权,请告知,会立即删除!
正则引擎大体上可分为不同的两类:DFA和NFA,而NFA又基本上可以分为传统型NFA和POSIX NFA。
DFA Deterministic finite automaton 确定型有穷自动机
NFA Non-deterministic finite automaton 非确定型有穷自动机
Traditional NFA
POSIX NFA
DFA引擎因为不需要回溯,所以匹配快速,但不支持捕获组,所以也就不支持反向引用和$number这种引用方式,目前使用DFA引擎的语言和工具主要有awk、egrep 和 lex。
POSIX NFA主要指符合POSIX标准的NFA引擎,它的特点主要是提供longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯。同DFA一样,非贪婪模式或者说忽略优先量词对于POSIX NFA同样是没有意义的。
大多数语言和工具使用的是传统型的NFA引擎,它有一些DFA不支持的特性:
捕获组、反向引用和$number引用方式;
环视(Lookaround,(?<=…)、(?<!…)、(?=…)、(?!…)),或者有的有文章叫做预搜索;
忽略优化量词(??、*?、+?、{m,n}?、{m,}?),或者有的文章叫做非贪婪模式;
占有优先量词(?+、*+、++、{m,n}+、{m,}+,目前仅Java和PCRE支持),
固化分组(?>…)。==》 不支持。。。
条件匹配
(?(id)yes_exp|no_exp):对应id的子表达式如果匹配到内容,则这里匹配yes_exp,否则匹配no_exp
相关进阶知识
python属于perl风格,属于传统型NFA引擎,与此相对的是POSIX NFA和DFA等引擎。所以大部分讨论都针对传统型NFA
传统型NFA中的顺序问题
NFA是基于表达式主导的引擎,同时,传统型NFA引擎会在找到第一个符合匹配的情况下立即停止:即得到匹配之后就停止引擎。
而POSIX NFA 中不会立刻停止,会在所有可能匹配的结果中寻求最长结果。这也是有些bug在传统型NFA中不会出现,但是放到后者中,会暴露出来。
引申一点,NFA学名为”非确定型有穷自动机“,DFA学名为”确定型有穷自动机“
这里的非确定和确定均是对被匹配的目标文本中的字符来说的,在NFA中,每个字符在一次匹配中即使被检测通过,也不能确定他是否真正通过,因为NFA中会出现回溯!甚至不止一两次。图例见后面例子。而在DFA中,由于是目标文本主导,所有对象字符只检测一遍,到文本结束后,过就是过,不过就不过。这也就是”确定“这个说法的原因。
扩展型括号
(?aiLmsx)
a re.A
i re.I #忽略大小写
L re.L
m re.M
s re.S #点号匹配包括换行符
x re.X #可以多行写表达式
如:
re_lx = re.compile(r'(?iS)\d+$')
re_lx = re.compile(r'\d+',re.I|re.S) #这两个编译表达式等价
一图说尽正则 perl 风格
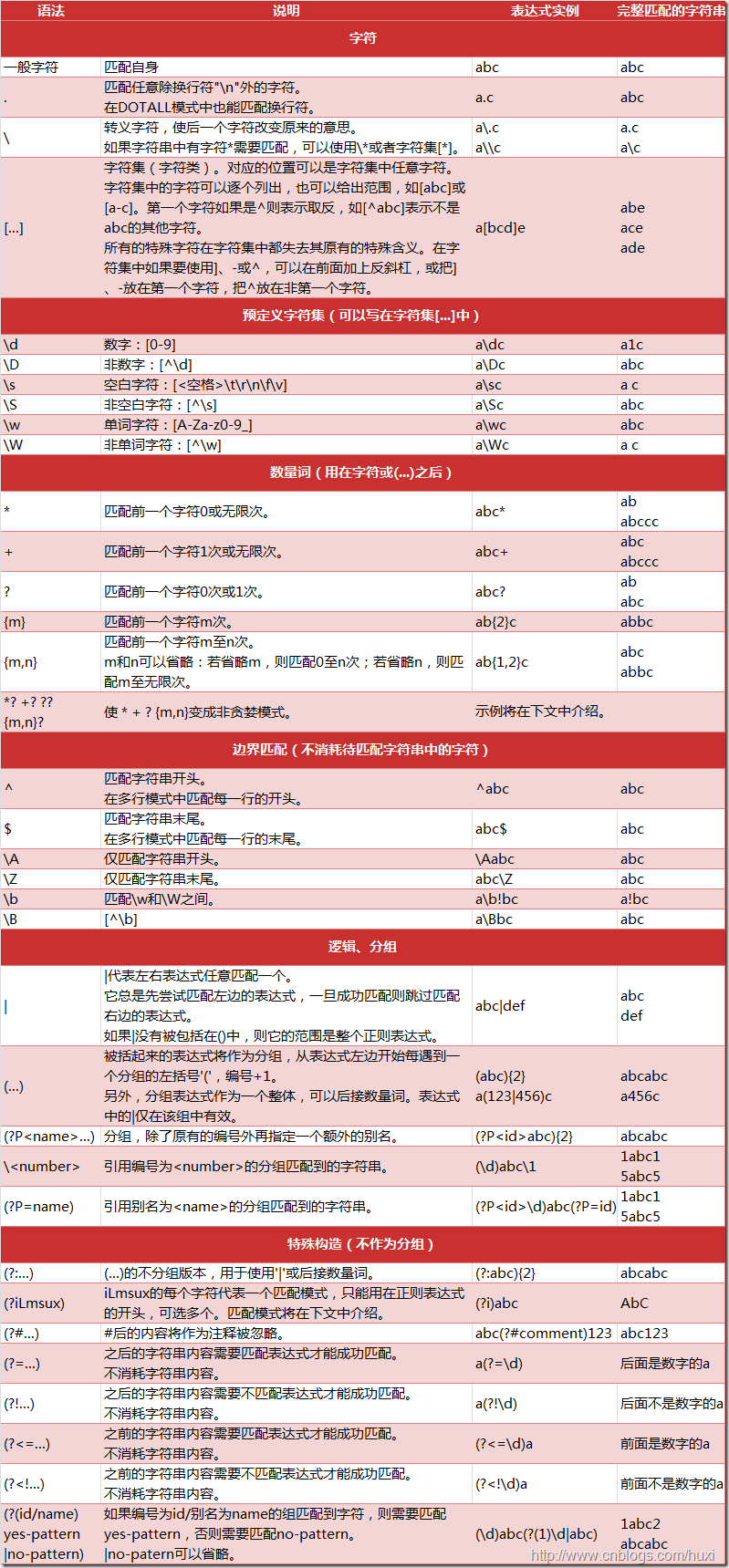
需要重点注意的地方
# 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
如下 加?为非贪婪匹配即尽可能少的匹配,不加则为贪婪匹配尽可能多的匹配,python 中总是默认贪婪匹配的
>>> import re
>>> re.findall(r'[a-z]*?','abcd')
['', '', '', '', '']
>>> re.findall(r'[a-z]+?','abcd')
['a', 'b', 'c', 'd']
>>> re.findall(r'[a-z]??','abcd')
['', '', '', '', '']
>>> re.findall(r'[a-z]*','abcd')
['abcd', '']
# 零宽断言以及不捕获分组,命名分组 ,注释型括号
(?=X ) 零宽度正先行断言。仅当子表达式 X 在 此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?!X) 零宽度负先行断言。仅当子表达式 X 不在 此位置的右侧匹配时才继续匹配。例如,例如,\w+(?!\d) 与后不跟数字的单词匹配,而不与该数字匹配 。
(?<=X) 零宽度正后发断言。仅当子表达式 X 在 此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?<!X) 零宽度负后发断言。仅当子表达式 X 不在此位置的左侧匹配时才继续匹配。例如,(?<!19)99 与不跟在 19 后面的 99 的实例匹配
(?:) 不捕获分组,对于 ‘abc’ 用正则 r'(?:a)bc' findall 或 search 得到 ‘bc’ ,a 不会被捕获
(?P<name>exp) --》 (?P=name) 比 匿名分组 () --》 \1 的 好处是 可以很直观看到是如何反向引用分组的
>>> re.findall(r'(?P<alpha>[a-z])\d+(?P=alpha)','a123a456a')
['a']
(?#...) #注释型括号,此括号完全被忽略
>>> re.match(r'(?#编译)(?P<last_name>[a-zA-Z]+)\s(?P<first_name>[a-zA-Z]+)',name).groupdict()
{'last_name': 'Frank', 'first_name': 'Li'}
# 例子
text = "问:我用的是Windows XP+Service Pack 2,为什么无法安装输入卡号和密码的控件? 答:在Windows XP+Service Pack 2、Windows 2003等操作系统中,用户可以自己选择是否安装控件。 问:为什么我看到的卡号输入框显示为*符号? 答:您的浏览器禁止下载执行ActiveX控件 , 对于这种情况 , 您必须打开浏览器的ActiveX的相关权限。 操作方法:在浏览器菜单中选择“工具”|“Internet选项”,在弹出的对话框中选择”安全” |”Internet”|”自定义级别”,在弹出的对话框中选择”重置为 安全级-中” , 点”重置”按钮,确定。 问:看了以上几个问题,还是不能登录,怎么办? 答:您的浏览器由于其他原因不能安装招商银行登录控件, 请下载并安装招商银行登录控件下载版。 问:无法出现个人网上银行大众版登录界面。 答:这种情况是由于您的机器无法和我行服务器建立安全连接,通常是因为代理服务器设置错误引起。如果您是拨号上网,请不要使用代理服务器;如果您过去安装过我行SSL安全代理,请调用“添加-删除程序”删除SSL安全代理;如果您是经过代理访问Internet,请联系您所在网的网络管理员设置代理服务器。IE5.0浏览器设置代理服务器的步骤: Internet选项–>连接–>局域网设置–>使用代理服务器–>高级。 问:我在输入账号和卡号时,总出错,该怎样输? 答:存折账号为10位,按存折本上的账号输入, 密码为6位。如果一卡通是12位卡号的,只需输入地区码后面的8位卡号,不需要输入前面4位的地区码,密码为6位。如果一卡通是16位卡号的,请将16位卡号全部输入,密码为6位。 问:我的存折没有设密码,怎样在个人网上银行大众版中查询余额? 答:存折必须设有密码方可在 个人网上银行大众版 中查询,因此请您到存折开户行给您的存折设置密码。 注:网上个人银行是招商银行为个人客户提供的网上银行。 本页面内容仅供参考,部分业务以当地网点的公告与具体规定为准。"
import re
for q,a in re.findall(r'(?<=问:)(.*?)答:(.*?)(?=问|\Z)',text):
print('Q: {}'.format(q))
print('A: {}'.format(a))
Q: 我用的是Windows XP+Service Pack 2,为什么无法安装输入卡号和密码的控件?
A: 在Windows XP+Service Pack 2、Windows 2003等操作系统中,用户可以自己选择是否安装控件。
Q: 为什么我看到的卡号输入框显示为*符号?
A: 您的浏览器禁止下载执行ActiveX控件 , 对于这种情况 , 您必须打开浏览器的ActiveX的相关权限。 操作方法:在浏览器菜单中选择“工具”|“Internet选项”,在弹出的对话框中选择”安全” |”Internet”|”自定义级别”,在弹出的对话框中选择”重置为 安全级-中” , 点”重置”按钮,确定。
Q: 看了以上几个问题,还是不能登录,怎么办?
A: 您的浏览器由于其他原因不能安装招商银行登录控件, 请下载并安装招商银行登录控件下载版。
Q: 无法出现个人网上银行大众版登录界面。
A: 这种情况是由于您的机器无法和我行服务器建立安全连接,通常是因为代理服务器设置错误引起。如果您是拨号上网,请不要使用代理服务器;如果您过去安装过我行SSL安全代理,请调用“添加-删除程序”删除SSL安全代理;如果您是经过代理访
Q: 我在输入账号和卡号时,总出错,该怎样输?
A: 存折账号为10位,按存折本上的账号输入, 密码为6位。如果一卡通是12位卡号的,只需输入地区码后面的8位卡号,不需要输入前面4位的地区码,密码为6位。如果一卡通是16位卡号的,请将16位卡号全部输入,密码为6位。
Q: 我的存折没有设密码,怎样在个人网上银行大众版中查询余额?
A: 存折必须设有密码方可在 个人网上银行大众版 中查询,因此请您到存折开户行给您的存折设置密码。 注:网上个人银行是招商银行为个人客户提供的网上银行。 本页面内容仅供参考,部分业务以当地网点的公告与具体规定为准。
# 常用 正则表达式
汉字 [\u4e00 - \u9f5a]
# match 和 search 命名分组
>>> name = 'Frank Li'
>>> import re
>>> re.match(r'(?P<First_name>[a-zA-Z]+)\s(?P<Last_name>[a-zA-Z]+)',name).groupdict()
{'First_Name': 'Frank', 'Last_name': 'Li'}
python
import re
s1 = 'adkkdk'
s2 = 'abc123efg'
def is_lowercase(s):
print('{} is lower case',s) if re.match(r'[a-z]+$',s) else print('{} is not lower case!'.format(s))
is_lowercase(s1)
is_lowercase(s2)
import re
def get_abbr(s):
pattern = re.compile(r'[A-Z][a-z]+\s?')
tup_s = re.findall(pattern,s)
return ''.join(list(map(lambda tup_s:tup_s[:1],tup_s)))
print(get_abbr('Federal Emergency Management Agency'))
import re
s = '123,000,000'
sub_s_2 = s.replace(',','')
sub_s = re.sub(',','',s)
print(sub_s)
print(sub_s_2)
#_*_coding:utf-8_*_
import re
m0 = "在一九四九年新中国成立"
m1 = "比一九九零年低百分之五点二"
m2 = '人一九九六年击败俄军,取得实质独立'
def switch(s):
return {'一':1,'二':2,'三':3,'四':4,'五':5,'六':6,'七':7,'八':8,'九':9}.get(s)
# num_dict = {'一':1,'二':2,'三':3,'四':4,'五':5,'六':6,'七':7,'八':8,'九':9}
# sorted(num_dict.items(),key=lambda tupl_num:tupl_num[1])
# print('|'.join(num_dict.keys()))
def get_year(m):
num_dict = {'零':0,'一':1,'二':2,'三':3,'四':4,'五':5,'六':6,'七':7,'八':8,'九':9}
pattern_string = r'|'.join(num_dict.keys())
pattern_string = '['+pattern_string+']{4}'
return re.search(pattern_string,m).group(0)
print(get_year(m0))
print(get_year(m1))
print(get_year(m2))
扩展部分, 优化等
1. 正则表达式语法
1.1 字符与字符类
1 特殊字符:\.^$?+*{}[]()|
以上特殊字符要想使用字面值,必须使用\进行转义
2 字符类
1. 包含在[]中的一个或者多个字符被称为字符类,字符类在匹配时如果没有指定量词则只会匹配其中的一个。
2. 字符类内可以指定范围,比如[a-zA-Z0-9]表示a到z,A到Z,0到9之间的任何一个字符
3. 左方括号后跟随一个^,表示否定一个字符类,比如[^0-9]表示可以匹配一个任意非数字的字符。
4. 字符类内部,除了\之外,其他特殊字符不再具备特殊意义,都表示字面值。^放在第一个位置表示否定,放在其他位置表示^本身,-放在中间表示范围,放在字符类中的第一个字符,则表示-本身。
5. 字符类内部可以使用速记法,比如\d \s \w
3 速记法
. 可以匹配除换行符之外的任何字符,如果有re.DOTALL标志,则匹配任意字符包括换行
\d 匹配一个Unicode数字,如果带re.ASCII,则匹配0-9
\D 匹配Unicode非数字
\s 匹配Unicode空白,如果带有re.ASCII,则匹配\t\n\r\f\v中的一个
\S 匹配Unicode非空白
\w 匹配Unicode单词字符,如果带有re.ascii,则匹配[a-zA-Z0-9_]中的一个
\W 匹配Unicode非单子字符
1.2 量词
1. ? 匹配前面的字符0次或1次
2. * 匹配前面的字符0次或多次
3. + 匹配前面的字符1次或者多次
4. {m} 匹配前面表达式m次
5. {m,} 匹配前面表达式至少m次
6. {,n} 匹配前面的正则表达式最多n次
7. {m,n} 匹配前面的正则表达式至少m次,最多n次
注意点:
以上量词都是贪婪模式,会尽可能多的匹配,如果要改为非贪婪模式,通过在量词后面跟随一个?来实现
1.3 组与捕获
1 ()的作用:
1. 捕获()中正则表达式的内容以备进一步利用处理,可以通过在左括号后面跟随?:来关闭这个括号的捕获功能
2. 将正则表达式的一部分内容进行组合,以便使用量词或者|
2 反响引用前面()内捕获的内容:
1. 通过组号反向引用
每一个没有使用?:的小括号都会分配一个组好,从1开始,从左到右递增,可以通过\i引用前面()内表达式捕获的内容
2. 通过组名反向引用前面小括号内捕获的内容
可以通过在左括号后面跟随?P<name>,尖括号中放入组名来为一个组起一个别名,后面通过(?P=name)来引用 前面捕获的内容。如(? P<word>\w+)\s+(?P=word)来匹配重复的单词。
3 注意点:
反向引用不能放在字符类[]中使用。
1.4 断言与标记
断言不会匹配任何文本,只是对断言所在的文本施加某些约束
1 常用断言:
1. \b 匹配单词的边界,放在字符类[]中则表示backspace
2. \B 匹配非单词边界,受ASCII标记影响
3. \A 在起始处匹配
4. ^ 在起始处匹配,如果有MULTILINE标志,则在每个换行符后匹配
5. \Z 在结尾处匹配
6. $ 在结尾处匹配,如果有MULTILINE标志,则在每个换行符前匹配
7. (?=e) 正前瞻
8. (?!e) 负前瞻
9. (?<=e) 正回顾
10.(?<!e) 负回顾
2 前瞻回顾的解释
前瞻: exp1(?=exp2) exp1后面的内容要匹配exp2
负前瞻: exp1(?!exp2) exp1后面的内容不能匹配exp2
后顾: (?<=exp2)exp1 exp1前面的内容要匹配exp2
负后顾: (?<!exp2)exp1 exp1前面的内容不能匹配exp2
例如:我们要查找hello,但是hello后面必须是world,正则表达式可以这样写:"(hello)\s+(?=world)",用来匹配"hello wangxing"和"hello world"只能匹配到后者的hello
1.5 条件匹配
(?(id)yes_exp|no_exp):对应id的子表达式如果匹配到内容,则这里匹配yes_exp,否则匹配no_exp
1.6 正则表达式的标志
1. 正则表达式的标志有两种使用方法
1. 通过给compile方法传入标志参数,多个标志使用|分割的方法,如re.compile(r"#[\da-f]{6}\b", re.IGNORECASE|re.MULTILINE)
2. 通过在正则表达式前面添加(?标志)的方法给正则表达式添加标志,如(?ms)#[\da-z]{6}\b
2. 常用的标志
re.A或者re.ASCII, 使\b \B \s \S \w \W \d \D都假定字符串为假定字符串为ASCII
re.I或者re.IGNORECASE 使正则表达式忽略大小写
re.M或者re.MULTILINE 多行匹配,使每个^在每个回车后,每个$在每个回车前匹配
re.S或者re.DOTALL 使.能匹配任意字符,包括回车
re.X或者re.VERBOSE 这样可以在正则表达式跨越多行,也可以添加注释,但是空白需要使用\s或者[ ]来表示,因为默认的空白不再解释。如:
re.compile(r"""
<img\s +) #标签的开始
[^>]*? #不是src的属性
src= #src属性的开始
(?:
(?P<quote>["']) #左引号
(?P<image_name>[^\1>]+?) #图片名字
(?P=quote) #右括号
""",re.VERBOSE|re.IGNORECASE)
2. Python正则表达式模块
2.1 正则表达式处理字符串主要有四大功能
1. 匹配 查看一个字符串是否符合正则表达式的语法,一般返回true或者false
2. 获取 正则表达式来提取字符串中符合要求的文本
3. 替换 查找字符串中符合正则表达式的文本,并用相应的字符串替换
4. 分割 使用正则表达式对字符串进行分割。
2.2 Python中re模块使用正则表达式的两种方法
1. 使用re.compile(r, f)方法生成正则表达式对象,然后调用正则表达式对象的相应方法。这种做法的好处是生成正则对象之后可以多次使用。
2. re模块中对正则表达式对象的每个对象方法都有一个对应的模块方法,唯一不同的是传入的第一个参数是正则表达式字符串。此种方法适合于只使用一次的正则表达式。
2.3 正则表达式对象的常用方法
1. rx.findall(s,start, end):
返回一个列表,如果正则表达式中没有分组,则列表中包含的是所有匹配的内容,
如果正则表达式中有分组,则列表中的每个元素是一个元组,元组中包含子分组中匹配到的内容,但是没有返回整个正则表达式匹配的内容
2. rx.finditer(s, start, end):
返回一个可迭代对象
对可迭代对象进行迭代,每一次返回一个匹配对象,可以调用匹配对象的group()方法查看指定组匹配到的内容,0表示整个正则表达式匹配到的内容
3. rx.search(s, start, end):
返回一个匹配对象,倘若没匹配到,就返回None
search方法只匹配一次就停止,不会继续往后匹配
4. rx.match(s, start, end):
如果正则表达式在字符串的起始处匹配,就返回一个匹配对象,否则返回None
5. rx.sub(x, s, m):
返回一个字符串。每一个匹配的地方用x进行替换,返回替换后的字符串,如果指定m,则最多替换m次。对于x可以使用/i或者/g<id>id可以是组名或者编号来引用捕获到的内容。
模块方法re.sub(r, x, s, m)中的x可以使用一个函数。此时我们就可以对捕获到的内容推过这个函数进行处理后再替换匹配到的文本。
6. rx.subn(x, s, m):
与re.sub()方法相同,区别在于返回的是二元组,其中一项是结果字符串,一项是做替换的个数。
7. rx.split(s, m):分割字符串
返回一个列表
用正则表达式匹配到的内容对字符串进行分割
如果正则表达式中存在分组,则把分组匹配到的内容放在列表中每两个分割的中间作为列表的一部分,如:
rx = re.compile(r"(\d)[a-z]+(\d)")
s = "ab12dk3klj8jk9jks5"
result = rx.split(s)
返回['ab1', '2', '3', 'klj', '8', '9', 'jks5']
8. rx.flags():正则表达式编译时设置的标志
9. rx.pattern():正则表达式编译时使用的字符串
2.4 匹配对象的属性与方法
01. m.group(g, ...)
返回编号或者组名匹配到的内容,默认或者0表示整个表达式匹配到的内容,如果指定多个,就返回一个元组
02. m.groupdict(default)
返回一个字典。字典的键是所有命名的组的组名,值为命名组捕获到的内容
如果有default参数,则将其作为那些没有参与匹配的组的默认值。
03. m.groups(default)
返回一个元组。包含所有捕获到内容的子分组,从1开始,如果指定了default值,则这个值作为那些没有捕获到内容的组的值
04. m.lastgroup()
匹配到内容的编号最高的捕获组的名称,如果没有或者没有使用名称则返回None(不常用)
05. m.lastindex()
匹配到内容的编号最高的捕获组的编号,如果没有就返回None。
06. m.start(g):
当前匹配对象的子分组是从字符串的那个位置开始匹配的,如果当前组没有参与匹配就返回-1
07. m.end(g)
当前匹配对象的子分组是从字符串的那个位置匹配结束的,如果当前组没有参与匹配就返回-1
08. m.span()
返回一个二元组,内容分别是m.start(g)和m.end(g)的返回值
09. m.re()
产生这一匹配对象的正则表达式
10. m.string()
传递给match或者search用于匹配的字符串
11. m.pos()
搜索的起始位置。即字符串的开头,或者start指定的位置(不常用)
12. m.endpos()
搜索的结束位置。即字符串的末尾位置,或者end指定的位置(不常用)
2.5 总结
1. 对于正则表达式的匹配功能,Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
2. 对于正则表达式的搜索功能,如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
3. 对于正则表达式的替换功能,可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
4. 对于正则表达式的分割功能,可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# hello
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
m = re.match(r'hello', 'hello world!')
print m.group()
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
1.string: 匹配时使用的文本。
2.re: 匹配时使用的Pattern对象。
3.pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
4.endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
5.lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
6.lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
1.group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
2.groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
3.groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
4.start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
5.end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
6.span([group]):
返回(start(group), end(group))。
7.expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print "m.string:", m.string
print "m.re:", m.re
print "m.pos:", m.pos
print "m.endpos:", m.endpos
print "m.lastindex:", m.lastindex
print "m.lastgroup:", m.lastgroup
print "m.group(1,2):", m.group(1, 2)
print "m.groups():", m.groups()
print "m.groupdict():", m.groupdict()
print "m.start(2):", m.start(2)
print "m.end(2):", m.end(2)
print "m.span(2):", m.span(2)
print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')
### output ###
# m.string: hello world!
# m.re: <_sre.SRE_Pattern object at 0x016E1A38>
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
1.pattern: 编译时用的表达式字符串。
2.flags: 编译时用的匹配模式。数字形式。
3.groups: 表达式中分组的数量。
4.groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)
print "p.pattern:", p.pattern
print "p.flags:", p.flags
print "p.groups:", p.groups
print "p.groupindex:", p.groupindex
### output ###
# p.pattern: (\w+) (\w+)(?P<sign>.*)
# p.flags: 16
# p.groups: 3
# p.groupindex: {'sign': 3}
实例方法[ | re模块方法]:
1.match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
2.search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# world
3.
4.split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
5.
6.findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
import re
p = re.compile(r'\d+')
print p.findall('one1two2three3four4')
### output ###
# ['1', '2', '3', '4']
7.
8.finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print m.group(),
### output ###
# 1 2 3 4
9.
10.sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.sub(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.sub(func, s)
### output ###
# say i, world hello!
# I Say, Hello World!
11.
12.subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.subn(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.subn(func, s)
### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
多选结构
多选结构在传统型NFA中, 既不是匹配优先也不是忽略优先。而是按照顺序进行的。所以有如下的利用方式
1.在结果保证正确的情况下,应该优先的去匹配更可能出现的结果。将可能性大的分支尽可能放在靠前。
2.不能滥用多选结构,因为当匹配到多选结构时,缓存会记录下相应数目的备用状态。举例子:[abcdef]和‘a|b|c|d|e|f’这两个表达式,虽然都能完成你的某个目的,但是尽量选择字符型数组,因为后者会在每次比较时建立6个备用状态,浪费资源。
一些优化的理念和技巧
平衡法则
好的正则表达式需寻求如下平衡:
1.只匹配期望的文本,排除不期望的文本。(善于使用非捕获型括号,节省资源)
2.必须易于控制和理解。避免写成天书。。
3.使用NFA引擎,必须要保证效率(如果能够匹配,必须很快地返回匹配结果,如果不能匹配,应该在尽可能短的时间内报告匹配失败。)
处理不期望的匹配
在处理过程中,我们总是习惯于使用星号等非硬性规定的量词(其实是个不好的习惯),
这样的结果可能导致我们使用的匹配表达式中没有必须匹配的字符,例子如下:
'[0-9]?[^*]*\d*' #只是举个例子,没有实际意义。
上面的式子就是这种情况,在目标文本是“理想”时,可能出现不了什么问题,但是如果本身数据有问题。那么这个式子的匹配结果就完全不可预知。
原因就在于他没有一部分是必须的!它匹配任何内容都是成功的。。。
对数据的了解和假设
其实在处理很多数据的时候,我们的操作数据情况都是不一样的, 有时会很规整,那么我们可以省掉考虑复杂表达式的情况, 但是反过来,当来源很杂乱的时候,就需要思考多一些,对各种可能的情形做相应的处理。
引擎中一般存在的优化项
编译缓存
反复使用编译对象时,应该在使用前,使用re.compile()方法来进行编译,这样在后面调用时不必每次重新编译。节省时间。尤其是在循环体中反复调用正则匹配时。
锚点优化
配合一些引擎的优化,应尽量将锚点单独凸显出来。对比^a|^b,其效率便不如^(a|b)
同样的道理,系统也会处理行尾锚点优化。所以在写相关正则时,如果有可能的话,将锚点使用出来。
量词优化
引擎中的优化,会对如.* 这样的量词进行统一对待,而不是按照传统的回溯规则,所以,从理论上说'(?:.)*' 和'.*'是等价的,不过具体到引擎实现的时候,则会对'.*'进行优化。速度就产生了差异。
消除不必要括号以及字符组
这个在python中是否有 未知。只是在支持的引擎中,会对如[.]中转化成\.,因为显然后者的效率更高(字符组处理引起额外开销)
以上是一些引擎带的优化,自然实际上是我们无法控制的的,不过了解一些后,对我们后面的一些处理和使用有很大帮助。
其他技巧和补充内容
过度回溯问题
消除指数级匹配
形如下面:
(\w+)*
这种情况的表达式,在匹配长文本的时候会遇到什么问题呢,如果在文本匹配失败时(别忘了,如果失败,则说明已经回溯了 所有的可能),想象一下,*号退一个状态,里面的+号就包括其余的 所有状态,验证都失败后,回到外面,*号 退到倒数第二个备用状态,再进到括号内,+号又要回溯一边比上一轮差1的 备用状态数,当字符串很长时, 就会出现指数级的回溯总数。系统就会'卡死'。甚至当有匹配时,这个匹配藏在回溯总数的中间时,也是会造成卡死的情况。所以,使用NFA的引擎时,必须要注意这个问题!
我们采用如下思路去避免这个问题:
占有优先量词(python中使用前向断言加反向引用模拟)
道理很简单,既然庞大的回溯数量都是被储存的备用状态导致的,那么我们直接使引擎放弃这些状态。说到底是摆脱(regex*)* 这种形式。
import re
re_lx = re.compile(r'(?=(\w+))\1*\d')
效率测试代码
在测试表达式的效率时,可借助以下代码比较所需时间。在两个可能的结果中择期优者。
import reimport time
re_lx1 = re.compile(r'your_re_1')
re_lx2 = re.compile(r'your_re_2')
starttime = time.time()
repeat_time = 100for i in range(repeat_time):
s='test text'*10000
result = re_lx1.search(s)
time1 = time.time()-starttime
print(time1)
starttime = time.time()for i in range(repeat_time):
s='test text'*10000
result = re_lx2.search(s)
time2 = time.time()-starttime
print(time2)
量词等价转换
现在来看看大括号量词的效率问题
1,当大括号修饰的对象是类似于字符数组或者\d这种 非确定性字符时,使用大括号效率高于重复叠加对象。即:
\d{5}优于\d\d\d\d\d
经测试在python中后者优于前者。会快很多.
2,但是当重复的字符时确定的某一个字符时,则简单的重复叠加对象的效率会高一些。这是因为引擎会对单纯的字符串内部优化(虽然我们不知道具体优化是如何做到的)
aaaaa 优于a{5}
总体上说'\d' 肯定是慢于'1'
我使用的python3中的re模块,经测试,不使用量词会快。
综上,python中总体上使用量词不如简单的列出来!(与书中不同!)
锚点优化的利用
下面这个例子假设出现匹配的内容在字符串对象的结尾,那么下面的第一个表达式是快于第二个表达式的,原因在于前者有锚点的优势。
re_lx1 = re.compile(r'\d{5}$')
re_lx2 = re.compile(r'\d{5}') #前者快,有锚点优化
排除型数组的利用
继续,假设我们要匹配一段字符串中的5位数字,会有如下两个表达式供选择:
经过分析,我们发现\w是包含\d的,当使用匹配优先时,前面的\w会包含数字,之所以能匹配成功,或者确定失败,是后面的\d迫使前面的量词交还一些字符。
知道这一点,我们应该尽量避免回溯,一个顺其自然的想法就是不让前面的匹配优先量词涉及到\d
re_lx1 = re.compile(r'^\w+(\d{5})')
re_lx2 = re.compile(r'^[^\d]+\d{5}') #优于上面的表达式
总体来说,在我们没有时间去深入研究模块代码的时候,只能通过尝试和反复修改来得到最终的复合预期的表达式。
常识优化措施
然而我们利用可能的提升效果去尝试修改的时候很有可能 适得其反 , 因为某些我们看来缓慢的回溯在正则引擎内部会进行一定的优化 ,
“取巧”的修改又可能会关闭或者避开了这些优化,所以结果也许会令我们很失望。
以下是书中提到的一些 常识性优化措施:
避免重新编译(循环外创建对象)
使用非捕获型括号(节省捕获时间和回溯时状态的数量)
善用锚点符号
不滥用字符组
提取文本和锚点。将他们从可能的多选分支结构中提取出来,会提取速度。
最可能的匹配表达式放在多选分支前面
一个很好用的核心公式
’opening normal*(special normal*)* closing‘
这个公式 特别用来对于匹配在两个特殊分界部分(可能不是一个字符)内的normal文本,special则是处理当分界部分也许和normal部分混乱的情况。
有如下的三点避免这个公式无休止匹配的发生。
1.special部分和normal部分匹配的开头不能重合。一定保证这两部分在任何情况下不能匹配相同的内容,不然在无法出现匹配时遍历所有情况,此时引擎的路径就不能确定。
2.normal部分必须匹配至少一个字符
3.special部分必须是固定长度的
举个例子:
[^\\"]+(\\.[^\\"]+)* #匹配两个引号内的文本,但是不包括被转义的引号
[参考博客](https://www.cnblogs.com/sthu/p/7639589.html)
如果有来生,一个人去远行,看不同的风景,感受生命的活力。。。

