
转--Python标准库之一句话概括
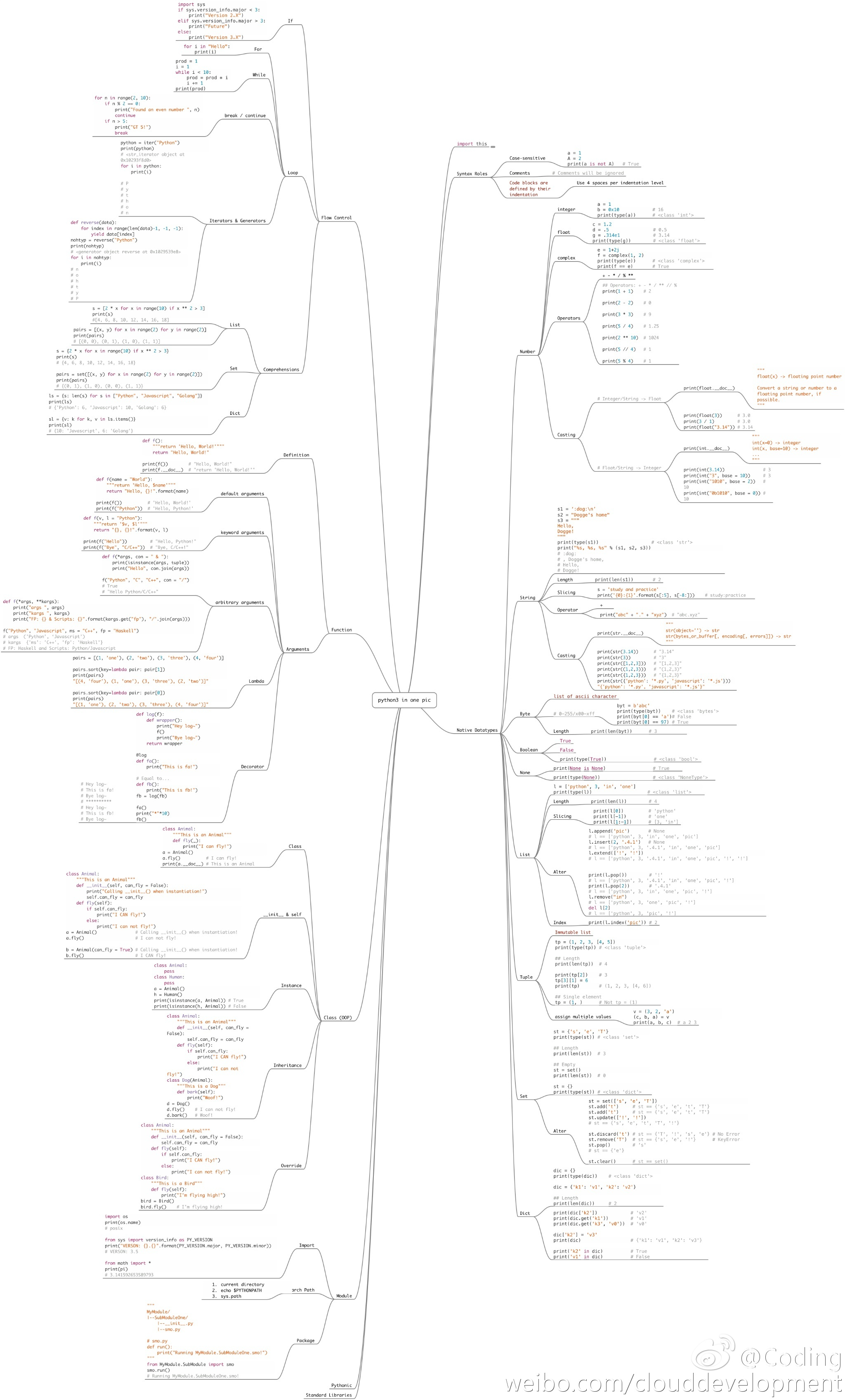
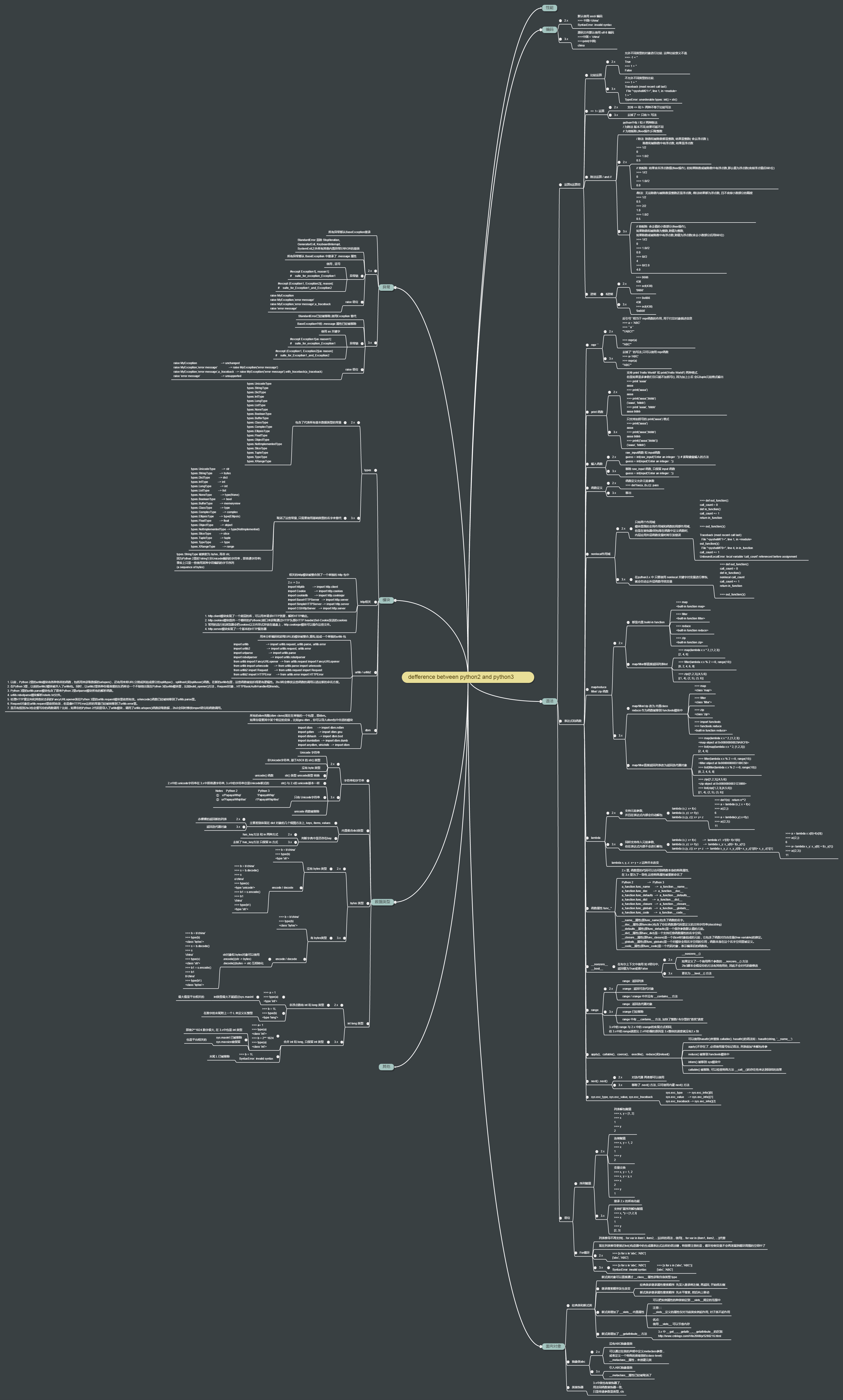
想掌握Python标准库,读它的官方文档很重要。本文并非此文档的复制版,而是对每一个库的一句话概括以及它的主要函数,由此用什么库心里就会有数了。
文本处理
string: 提供了字符集:ascii_lowercase, ascii_uppercase
re: 正则表达式支持(pattern, string):match, search, findall, sub, split, finditer
difflib: 序列的差异化比较: context_diff(s1, s2)
数据结构
datetime: 处理日期,可用arrow代替
calendar: 日历: Calendar
collections: 其他数据结构: deque, Counter, defaultdict, namedtuple
heapq: 堆排序实现: nlargest, nsmallest, merge
bisect: 二分查找实现: bisect, insort
array: 数列实现: array
copy: 浅拷贝和深拷贝: copy, deepcopy
pprint: 漂亮地输出文本: pprint
enum: 枚举类的实现: Enum
数学
math: 数学函数库,函数太多故不一一列举
fractions: 分数运算: Fraction as F
random: 随机数: choice, randint, randrange, sample, shuffle, gauss
statistics: 统计学函数: mean, median, mode, variance
函数式编程
itertools: 迭代器工具: permutations, combinations, product, chain, repeat, cycle, accumulate
functools: 函数工具: @wraps, reduce, partial, @lrucache, @singledispatch
operator: 基本运算符
文件目录访问
pahlib: 路径对象: Path
fileinput: 读取一个或多个文件并处理行: input
filecmp: 比较两个文件是否相同: cmp
glob: 文件通配符: glob
linecache: 读取文件的行,缓存优化: getline, getlines
shutil: 文件操作: copy, copytree, rmtree, move
数据持久化
pickle: 文件pickle序列化: dump, dumps, load, loads
sqlite3: sqlite数据库借口
文件格式
csv: 处理csv文件: reader, writeheader, writerow
configparser: 处理配置文件: ConfigParser, get, sections
密码学
hashlib: 哈希加密算法: sha256, hexdigest
操作系统
os: 操作系统,具体看文档
io: 在内存中读写str和bytes: StringIO, BytesIO, write, get_value
time: 计时器: time, sleep, strftime
argparse, getopt: 命令行处理,建议用click或docopt
logging: 打日志: debug, info, warning, error, critical
getpass: 获取用户输入的密码: getpass
platform: 提供跨平台支持: uname, system
并发执行
threading: 多线程模型: Thread, start, join
multiprocessing: 多进程模型: Pool, map, Process
concurrent.futures: 异步执行模型: ThreadPoolExecutor, ProcessPoolExecutor
subprocess: 子进程管理: run
sched: 调度工具
queue: 同步队列: Queue
进程间通信和网络
socket: 套接字,常用于服务器开发
ssl: HTTPS访问
select, selector: 多路复用I/O
asyncio: 异步IO, eventloop, 协程: get_event_loop, run_until_complete, wait, async, await
网络数据处理
email: 处理email
json: 处理json: dumps, loads
base64: 处理base64编码: b64encode, b64decode
结构化标记语言工具
html: 转义html: escape, unescape
html.parser: 解析html
网络协议支持
webbrowser: 打开浏览器: open
wsgiref: 实现WSGI接口
uuid: 通用唯一识别码: uuid1, uuid3, uuid4, uuid5
ftplib, poplib, imaplib, nntplib, smptlib, telnetlib: 实现各种网络协议
其余库用requests代替
程序框架
turtle: 画图工具
cmd: 实现交互式shell
shlex: 利用shell的语法分割字符串: split
GUI
tkinter
开发工具
typing: 类型注解
pydoc: 查阅模块文档: python -m pydoc [name]
doctest: 文档测试: python -m doctest [pyfile]
unittest: 单元测试: python -m unittest [pyfile]
DEBUG和性能优化
pdb: Python Debugger: python -m pdb [pyfile]
cProfile: 分析程序性能: python -m cProfile [pyfile]
timeit: 检测代码运行时间: python -m timeit [pyfile]
软件打包发布
setuptools: 编写setup.py专用: setup, find_packages
venv: 创建虚拟环境: python -m venv venv
Python运行时服务
sys: 系统环境交互: argv, path, exit, stderr, stdin, stdout
builtins: 所有的内置函数和类,默认引进
main: 顶层运行环境,使得python文件既可以独立运行,也可以当做模块导入到其他文件。
warnings: 警告功能(代码过时等): warn
contextlib: 上下文管理器实现: @contextmanager
traceback: 打印堆栈
自定义Python解释器
code: 实现自定义的Python解释器(比如Scrapy的shell): interact
未提及的库
textwrap, unicodedata, stringprep, rlcompleter, struct, codecs, weakref, types, reprlib, numbers, cmath, decimal, stat, tempfile, fnmatch, macpath, copyreg, shelve, marshal, zlib, gzip, bz2, lzma, zipfile, tarfile, netrc, xdrlib, plistlib, audioop, aifc, sunau, wave, chunk, colorsys, imghdr, sndhdr, bdb, faulthandler, trace, tracemalloc, abc, atexit, gc, inspect, site, hmac, secrets, signal, mmap, mailcap, mailbox, mimetypes, binhex, binascii, quopri, uu, errn, ctypes
这个列表包含与网页抓取和数据处理的Python库
网络
通用
urllib -网络库(stdlib)。
requests -网络库。
grab – 网络库(基于pycurl)。
pycurl – 网络库(绑定libcurl)。
urllib3 – Python HTTP库,安全连接池、支持文件post、可用性高。
httplib2 – 网络库。
RoboBrowser – 一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup -一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。
socket – 底层网络接口(stdlib)。
Unirest for Python – Unirest是一套可用于多种语言的轻量级的HTTP库。
hyper – Python的HTTP/2客户端。
PySocks – SocksiPy更新并积极维护的版本,包括错误修复和一些其他的特征。作为socket模块的直接替换。
异步
treq – 类似于requests的API(基于twisted)。
aiohttp – asyncio的HTTP客户端/服务器(PEP-3156)。
网络爬虫框架
功能齐全的爬虫
grab – 网络爬虫框架(基于pycurl/multicur)。
scrapy – 网络爬虫框架(基于twisted),不支持Python3。
pyspider – 一个强大的爬虫系统。
cola – 一个分布式爬虫框架。
其他
portia – 基于Scrapy的可视化爬虫。
restkit – Python的HTTP资源工具包。它可以让你轻松地访问HTTP资源,并围绕它建立的对象。
demiurge – 基于PyQuery的爬虫微框架。
HTML/XML解析器
通用
lxml – C语言编写高效HTML/ XML处理库。支持XPath。
cssselect – 解析DOM树和CSS选择器。
pyquery – 解析DOM树和jQuery选择器。
BeautifulSoup – 低效HTML/ XML处理库,纯Python实现。
html5lib – 根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现在所有的浏览器上。
feedparser – 解析RSS/ATOM feeds。
MarkupSafe – 为XML/HTML/XHTML提供了安全转义的字符串。
xmltodict – 一个可以让你在处理XML时感觉像在处理JSON一样的Python模块。
xhtml2pdf – 将HTML/CSS转换为PDF。
untangle – 轻松实现将XML文件转换为Python对象。
清理
Bleach – 清理HTML(需要html5lib)。
sanitize – 为混乱的数据世界带来清明。
文本处理
用于解析和操作简单文本的库。
通用
difflib – (Python标准库)帮助进行差异化比较。
Levenshtein – 快速计算Levenshtein距离和字符串相似度。
fuzzywuzzy – 模糊字符串匹配。
esmre – 正则表达式加速器。
ftfy – 自动整理Unicode文本,减少碎片化。
转换
unidecode – 将Unicode文本转为ASCII。
字符编码
uniout – 打印可读字符,而不是被转义的字符串。
chardet – 兼容 Python的2/3的字符编码器。
xpinyin – 一个将中国汉字转为拼音的库。
pangu.py – 格式化文本中CJK和字母数字的间距。
Slug化
awesome-slugify – 一个可以保留unicode的Python slugify库。
python-slugify – 一个可以将Unicode转为ASCII的Python slugify库。
unicode-slugify – 一个可以将生成Unicode slugs的工具。
pytils – 处理俄语字符串的简单工具(包括pytils.translit.slugify)。
通用解析器
PLY – lex和yacc解析工具的Python实现。
pyparsing – 一个通用框架的生成语法分析器。
人的名字
python-nameparser -解析人的名字的组件。
电话号码
phonenumbers -解析,格式化,存储和验证国际电话号码。
用户代理字符串
python-user-agents – 浏览器用户代理的解析器。
HTTP Agent Parser – Python的HTTP代理分析器。
特定格式文件处理
解析和处理特定文本格式的库。
通用
tablib – 一个把数据导出为XLS、CSV、JSON、YAML等格式的模块。
textract – 从各种文件中提取文本,比如 Word、PowerPoint、PDF等。
messytables – 解析混乱的表格数据的工具。
rows – 一个常用数据接口,支持的格式很多(目前支持CSV,HTML,XLS,TXT – 将来还会提供更多!)。
Office
python-docx – 读取,查询和修改的Microsoft Word2007/2008的docx文件。
xlwt / xlrd – 从Excel文件读取写入数据和格式信息。
XlsxWriter – 一个创建Excel.xlsx文件的Python模块。
xlwings – 一个BSD许可的库,可以很容易地在Excel中调用Python,反之亦然。
openpyxl – 一个用于读取和写入的Excel2010 XLSX/ XLSM/ xltx/ XLTM文件的库。
Marmir – 提取Python数据结构并将其转换为电子表格。
PDF
PDFMiner – 一个从PDF文档中提取信息的工具。
PyPDF2 – 一个能够分割、合并和转换PDF页面的库。
ReportLab – 允许快速创建丰富的PDF文档。
pdftables – 直接从PDF文件中提取表格。
Markdown
Python-Markdown – 一个用Python实现的John Gruber的Markdown。
Mistune – 速度最快,功能全面的Markdown纯Python解析器。
markdown2 – 一个完全用Python实现的快速的Markdown。
YAML
PyYAML – 一个Python的YAML解析器。
CSS
cssutils – 一个Python的CSS库。
ATOM/RSS
feedparser – 通用的feed解析器。
SQL
sqlparse – 一个非验证的SQL语句分析器。
HTTP
HTTP
http-parser – C语言实现的HTTP请求/响应消息解析器。
微格式
opengraph – 一个用来解析Open Graph协议标签的Python模块。
可移植的执行体
pefile – 一个多平台的用于解析和处理可移植执行体(即PE)文件的模块。
PSD
psd-tools – 将Adobe Photoshop PSD(即PE)文件读取到Python数据结构。
自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern – Python的网络挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob – 为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba – 中文分词工具。
SnowNLP – 中文文本处理库。
loso – 另一个中文分词库。
genius – 基于条件随机域的中文分词。
langid.py – 独立的语言识别系统。
Korean – 一个韩文形态库。
pymorphy2 – 俄语形态分析器(词性标注+词形变化引擎)。
PyPLN – 用Python编写的分布式自然语言处理通道。这个项目的目标是创建一种简单的方法使用NLTK通过网络接口处理大语言库。
浏览器自动化与仿真
selenium – 自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器,IE浏览器)。
Ghost.py – 对PyQt的webkit的封装(需要PyQT)。
Spynner – 对PyQt的webkit的封装(需要PyQT)。
Splinter – 通用API浏览器模拟器(selenium web驱动,Django客户端,Zope)。
多重处理
threading – Python标准库的线程运行。对于I/O密集型任务很有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing – 标准的Python库运行多进程。
celery – 基于分布式消息传递的异步任务队列/作业队列。
concurrent-futures – concurrent-futures 模块为调用异步执行提供了一个高层次的接口。
异步
异步网络编程库
asyncio – (在Python 3.4 +版本以上的 Python标准库)异步I/O,时间循环,协同程序和任务。
Twisted – 基于事件驱动的网络引擎框架。
Tornado – 一个网络框架和异步网络库。
pulsar – Python事件驱动的并发框架。
diesel – Python的基于绿色事件的I/O框架。
gevent – 一个使用greenlet 的基于协程的Python网络库。
eventlet – 有WSGI支持的异步框架。
Tomorrow – 异步代码的奇妙的修饰语法。
队列
celery – 基于分布式消息传递的异步任务队列/作业队列。
huey – 小型多线程任务队列。
mrq – Mr. Queue – 使用redis & Gevent 的Python分布式工作任务队列。
RQ – 基于Redis的轻量级任务队列管理器。
simpleq – 一个简单的,可无限扩展,基于Amazon SQS的队列。
python-gearman – Gearman的Python API。
云计算
picloud – 云端执行Python代码。
dominoup.com – 云端执行R,Python和matlab代码。
电子邮件
电子邮件解析库
flanker – 电子邮件地址和Mime解析库。
Talon – Mailgun库用于提取消息的报价和签名。
网址和网络地址操作
解析/修改网址和网络地址库。
URL
furl – 一个小的Python库,使得操纵URL简单化。
purl – 一个简单的不可改变的URL以及一个干净的用于调试和操作的API。
urllib.parse – 用于打破统一资源定位器(URL)的字符串在组件(寻址方案,网络位置,路径等)之间的隔断,为了结合组件到一个URL字符串,并将“相对URL”转化为一个绝对URL,称之为“基本URL”。
tldextract – 从URL的注册域和子域中准确分离TLD,使用公共后缀列表。
网络地址
netaddr – 用于显示和操纵网络地址的Python库。
网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper – 用Python进行新闻提取、文章提取和内容策展。
html2text – 将HTML转为Markdown格式文本。
python-goose – HTML内容/文章提取器。
lassie – 人性化的网页内容检索工具
micawber – 一个从网址中提取丰富内容的小库。
sumy -一个自动汇总文本文件和HTML网页的模块
Haul – 一个可扩展的图像爬虫。
python-readability – arc90 readability工具的快速Python接口。
scrapely – 从HTML网页中提取结构化数据的库。给出了一些Web页面和数据提取的示例,scrapely为所有类似的网页构建一个分析器。
视频
youtube-dl – 一个从YouTube下载视频的小命令行程序。
you-get – Python3的YouTube、优酷/ Niconico视频下载器。
维基
WikiTeam – 下载和保存wikis的工具。
WebSocket
用于WebSocket的库。
Crossbar – 开源的应用消息传递路由器(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython – 提供了WebSocket协议和WAMP协议的Python实现并且开源。
WebSocket-for-Python – Python 2和3以及PyPy的WebSocket客户端和服务器库。
DNS解析
dnsyo – 在全球超过1500个的DNS服务器上检查你的DNS。
pycares – c-ares的接口。c-ares是进行DNS请求和异步名称决议的C语言库。
计算机视觉
OpenCV – 开源计算机视觉库。
SimpleCV – 用于照相机、图像处理、特征提取、格式转换的简介,可读性强的接口(基于OpenCV)。
mahotas – 快速计算机图像处理算法(完全使用 C++ 实现),完全基于 numpy 的数组作为它的数据类型。
代理服务器
*** – 一个快速隧道代理,可帮你穿透防火墙(支持TCP和UDP,TFO,多用户和平滑重启,目的IP黑名单)。
tproxy – tproxy是一个简单的TCP路由代理(第7层),基于Gevent,用Python进行配置。
其他Python工具列表
awesome-python
pycrumbs
python-github-projects
python_reference
pythonidae

 浙公网安备 33010602011771号
浙公网安备 33010602011771号