
python 归类--玉蕴而珠藏
python 高级知识整理
重要概念
- *** python 语言概述 ***
*** python 中一切皆对象,type 产生 type 类本身的 实例 产生 object 类, dict 等内建类, class 为万物之始,包括 type(object), class 生 object 只道法自然 str <-- 'abc'
object 是所有对象的 基类包括 type.bases, object.bases 之上再无父类
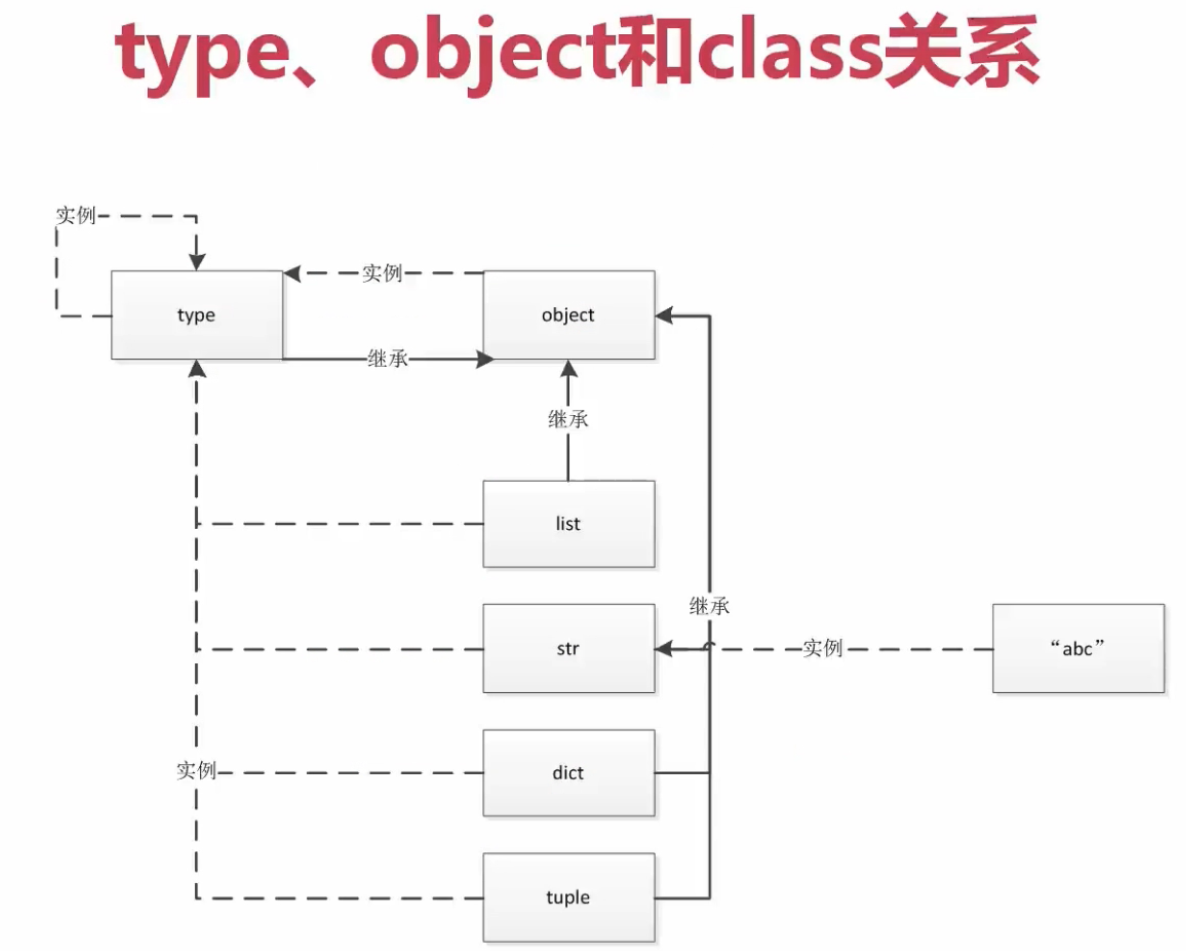
python 是基于协议的编程语言,因其动态语言的特性,也使得python开发效率极高,但同时也会容易产生很多问题,因为一切皆对象包括类本身,很多问题只有在运行时才能检测出来,
而像JAVA 这种静态语言,在编译时候就能够检测出问题,如:类型检测等
- GIL全局解释器锁
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
同一时刻,只可能有一个线程在 解释器(cpython) 上运行
- 属性查找过程,涉及到数据描述符
① getattribute(), 无条件调用
② 数据描述符:由 ① 触发调用 (若人为的重载了该 getattribute() 方法,可能会调职无法调用描述符)
③ 实例对象的字典(若与描述符对象同名,会被覆盖哦)
④ 类的字典
⑤ 非数据描述符
⑥ 父类的字典
⑦ getattr() 方法
class IntField:
def __get__(self, instance, owner):
print('get..data descriptor...')
return self.value
def __set__(self, instance, value):
print('set..data descriptor...')
self.value = value
def __delete__(self, instance):
pass
class NonDataField:
def __get__(self, instance, owner):
return 30
"""
问题5. 天天提属性查询优先级,就不能总结一下吗?
答:好的好的,客官稍等!
① __getattribute__(), 无条件调用
② 数据描述符:由 ① 触发调用 (若人为的重载了该 __getattribute__() 方法,可能会调职无法调用描述符)
③ 实例对象的字典(若与描述符对象同名,会被覆盖哦)
④ 类的字典
⑤ 非数据描述符
⑥ 父类的字典
⑦ __getattr__() 方法
"""
class Parent:
age = 88
# age1
class Test(Parent):
def __getattribute__(self, item):
return '道之始也, 无条件覆盖一切属性查找'
'''数据描述符'''
# age = IntField()
def __init__(self, name, info=None):
self.name = name
self.info = info
'''实例属性中'''
# self.age = 10
'''类属性字典中'''
# age = 20
'''非数据描述符'''
# age = NonDataField()
# 然后去父类字典里查找
def __getattr__(self, item):
# 实在没找到才进入本方法
return self.info.get(item, 'not found in info dictionary...')
# 若 这里都没有给值 则抛出 AttributeError 异常
if __name__ == '__main__':
test = Test('frank',{})
# test.age = 212
print(test.age)
# 属性查找顺序 __getattribute__ >> 数据描述符 >> 实例 test.__dict__ >> 类字典 Test.__dict__ >> 非数据描述符 >> 父类字典 >> 最后实在找不到 就去问 __getattr__ 要 >> 再没有抛出 AttributeError 异常
pass
视频作者回答
描述符分为数据描述符和非数据描述符。把至少实现了内置属性__set__()和__get__()方法的描述符称为数据描述符;把实现了除__set__()以外的方法的描述符称为非数据描述符。之所以要区分描述符的种类,主要是因为它在代理类属性时有着严格的优先级限制。例如当使用数据描述符时,因为数据描述符大于实例属性,所以当我们实例化一个类并使用该实例属性时,该实例属性已被数据描述符代理,此时我们对该实例属性的操作是对描述符的操作。描述符的优先级的高低如下:
类属性 > 数据描述符 > 实例属性 > 非数据描述符 > 找不到的属性触发__getattr__()
- 类的实例化过程 涉及到元类编程
from abc import abstractmethod, abstractstaticmethod, abstractclassmethod
import numbers
class Field:
def __init__(self, db_column=None):
self._db_column = db_column
@property
def db_column(self):
return self._db_column
@db_column.setter
def db_name(self, value):
self._db_column = value
@abstractmethod
def __get__(self, instance, owner):
pass
@abstractmethod
def __set__(self, instance, value):
pass
@abstractmethod
def __delete__(self, instance):
pass
class PositiveIntField(Field):
def __init__(self, db_column=None, min_value=None, max_value=None):
super().__init__(db_column)
if min_value:
if not isinstance(min_value, numbers.Integral):
raise ValueError('min value should be int')
elif min_value < 0:
raise ValueError('min value should be positive')
if max_value:
if not isinstance(max_value, numbers.Integral):
raise ValueError('max value should be int')
elif max_value < 0:
raise ValueError('max value should be positive')
if min_value > max_value:
raise ValueError('min value should be smaller than max value')
else:
self._min_value, self._max_value = min_value, max_value
def __get__(self, instance, owner):
return self._value
def __set__(self, instance, value):
if not isinstance(value, int):
raise ValueError('value should be int')
if not (self._min_value < value < self._max_value):
raise ValueError('value should between min value and max value')
self._value = value
def __delete__(self, instance):
pass
class CharField(Field):
def __init__(self, max_length, db_name=None):
super().__init__(db_name)
if max_length < 0:
raise ValueError('max length should be positive int')
self._max_length = max_length
def __get__(self, instance, owner):
return self._value
def __set__(self, instance, value):
if not isinstance(value, str):
raise ValueError('value should be str')
self._value = value
class ModelMeta(type):
def __new__(cls, name, bases, attrs, **kwargs):
if name == 'BaseModel':
return type.__new__(cls, name, bases, attrs, **kwargs)
table_name = None
_attr_dict = {}
fields = {}
# values = []
for key, value in attrs.items():
if isinstance(value, Field):
print(key, value)
fields[key] = value
# values.append(value)
table_name = attrs['_table_name'] if '_table_name' else name.lower()
attrs['fields'] = fields
attrs['table_name'] = table_name
return type.__new__(cls, name, bases, attrs, **kwargs)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
class BaseModel(metaclass=ModelMeta):
def __init__(self, **kwargs):
if kwargs:
for key, value in kwargs.items():
setattr(self, key, value)
super().__init__()
def save(self):
table_name = self.table_name
fields = getattr(self, 'fields')
columns = fields.keys()
values = [str(value._value) for value in fields.values()]
for key, value in fields.items():
print(key, '-sb-', getattr(self, key))
sql = f'insert {table_name}({",".join(columns)}) values({"".join(values)})'
print(sql)
pass
class User(BaseModel):
age = PositiveIntField('', 1, 100)
name = CharField(50)
_table_name = 'user323'
def __init__(self, **kwargs):
super().__init__(**kwargs)
def __str__(self):
return 'User({name}, {age})'.format(name=self.name, age=self.age)
if __name__ == '__main__':
user = User(name='frank', age=18)
print(user)
user.save()
### 新 orm
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from collections import UserDict
from numbers import Integral
class Field(object):
pass
class IntField(Field):
def __init__(self,db_column,min_value=None,max_value=None):
self._value = None
self.min_value = min_value
self.max_value = max_value
self.db_column = db_column
if min_value:
if not isinstance(min_value,Integral):
raise ValueError('min_value must be int')
elif min_value < 0:
raise ValueError('min_value must be positive int')
if max_value:
if not isinstance(max_value,Integral):
raise ValueError('max_value must be int')
elif max_value < 0:
raise ValueError('max_value should be positive int')
if min_value and max_value:
if min_value > max_value:
raise ValueError('min_value must be smaller than max_value')
def __get__(self, instance, owner):
return self._value
# 数据描述符的标志
def __set__(self, instance, value):
if not isinstance(value,Integral):
raise ValueError('value must be int')
if self.min_value and self.max_value:
if not (self.min_value <= self._value <= self.max_value):
raise ValueError('value should between min_value and max_value!')
self._value = value
class CharField(Field):
def __init__(self,db_column=None,max_length=None):
self._value = None
self.db_column = db_column
if not max_length:
raise ValueError('you must spcify max_length for charfield ')
self.max_lenght = max_length
def __get__(self, instance, owner):
return self._value
def __set__(self, instance, value):
if not isinstance(value,str):
raise ValueError('value should be an instance of str')
if len(value) > self.max_lenght:
raise ValueError('value len excess len of max_length')
self._value = value
class ModelMetaclass(type):
def __new__(cls, name,bases,attrs):
if name == 'BaseModel':
return super().__new__(cls,name,bases,attrs)
fields = {}
for key, value in attrs.items():
if isinstance(value,Field):
fields[key] = value
attrs_meta = attrs.get("Meta", None)
_meta = {}
db_table = name.lower()
if attrs_meta:
table = getattr(attrs_meta,'db_table',None)
if table:
db_table = table
_meta["db_table"] = db_table
attrs["_meta"] = _meta
attrs['fields'] = fields
del attrs['Meta']
return super().__new__(cls,name,bases,attrs)
class BaseModel(metaclass=ModelMetaclass):
def __init__(self,**kwargs):
for key, value in kwargs.items():
setattr(self,key,value)
super(BaseModel,self).__init__()
def save(self):
fields = []
values = []
for key, value in self.fields.items():
db_column = value.db_column
if not db_column:
db_column = key.lower()
fields.append(db_column)
value = getattr(self,key)
values.append(str(value) if not isinstance(value,str) else "'{}'".format(value))
sql = 'insert into {db_table} ({field_list}) values({value_list})'.format(db_table=self._meta.get('db_table'),field_list=','.join(fields),value_list=','.join(values))
print(sql)
pass
class User(BaseModel):
age = IntField(db_column='age',min_value=0,max_value=100)
name = CharField(db_column='column',max_length=10)
class Meta:
db_table = 'user'
if __name__ == '__main__':
user = User()
user.name = 'frank'
user.age = 18
user.save()
LEGB 变量查找
LEGB
# enclosure
def num():
return [lambda x:i*x for i in range(4)]
if __name__ == '__main__':
logging.debug([func(2) for func in num()])
# 答案:[6, 6, 6, 6]
# 解析: 问题的本质在与python中的属性查找规则,LEGB(local,enclousing,global,bulitin),
# 在上面的例子中,i就是在闭包作用域(enclousing),而Python的闭包是
# 迟绑定 ,
# 这意味着闭包中用到的变量的值,是在内部函数被调用时查询得到的
# 所以:[lambda x: i * x for i in range(4)]
# 打印出来是含有四个内存地址的列表,每个内存地址中的i
# 在在本内存中都没有被定义,而是通过闭包作用域中的i值,当for循环执行结束后,i的值等于3,所以
# 再执行[m(2)
# for m in num()]时,每个内存地址中的i值等于3,当x等于2时,打印出来的结果都是6,
# 从而得到结果[6, 6, 6, 6]。
迭代器模式 iter() ==》 Iterator ,
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from collections import Iterator
class Company:
def __init__(self,employee_list=None):
if not isinstance(employee_list,(tuple,list)):
raise TypeError('employee_list should be a instance of tuple or list...')
self.employee_list = employee_list
def __iter__(self):
return CompanyIterator(self.employee_list) #iter(self.employee_list)
class CompanyIterator(Iterator): # 若不继承 ,则需要 覆写 __iter__ 协议
def __init__(self,employee_list):
self.employee_list = employee_list
self._index = 0
def __iter__(self): # 继承 Iterator 可以省略
return self
def __next__(self):
try:
word = self.employee_list[self._index]
except IndexError:
raise StopIteration
self._index+=1
return word
if __name__ == '__main__':
company = Company(['a','b','c'])
for c in company:
print(c)
def read_file_chunk(file_path,new_line='\n',chunk_size=4096):
buf = ''
with open(file_path) as f:
while True:
chunk = f.read(chunk_size)
while new_line in buf:
pos = buf.index(new_line)
yield buf[:pos]
buf = buf[pos+len(new_line):]
if not chunk:
yield buf
break
buf+=chunk
python 垃圾回收 内存管理
- Python是如何进行内存管理的?
从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
28、Python垃圾回收机制?
python采用的是引用计数机制为主,标记-清除和分代收集(隔代回收、分代回收)两种机制为辅的策略
计数机制
Python的GC模块主要运用了引用计数来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”
解决容器对象可能产生的循环引用的问题。通过分代回收以空间换取时间进一步提高垃圾回收的效率。
标记-清除:
标记-清除的出现打破了循环引用,也就是它只关注那些可能会产生循环引用的对象
缺点:该机制所带来的额外操作和需要回收的内存块成正比。
隔代回收
原理:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,
垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,
就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,
如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。
代码管理 git
git push --set-upstream origin dev
git clean -d -fx
git stash
git pull
git stash pop
当你多次使用’git stash’命令后,你的栈里将充满了未提交的代码,这时候你会对将哪个版本应用回来有些困惑,
’git stash list’ 命令可以将当前的Git栈信息打印出来,你只需要将找到对应的版本号,例如使用’git stash apply stash@{1}’就可以将你指定版本号为stash@{1}的工作取出来,当你将所有的栈都应用回来的时候,可以使用’git stash clear’来将栈清空。
git push origin --delete dev
git branch -d dev
常用模块
- os和sys模块的作用?
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;
sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。 - 常用模块
import random
random.shuffle
random.choice
random.sample
random.random
青出于蓝的 requests >> urllib
Pillow(新) PIL(2.7 远古时代)
psutils <== process and system utilities
import chardet
from contextlib import contextmanager,closing
reload(sys)
sys.setdefaultencoding("utf-8")
在Python 3.x中不好使了 提示 name ‘reload’ is not defined
在3.x中已经被毙掉了被替换为
import importlib
importlib.reload(sys)
pylint
pyflakes
pysonar2
Fabric
import traceback
sys.argv与optparse与argparse与getopt
谷歌的 fire 模块
import dis 分析函数过程等...
代码统计 cloc
excel 读写 pandas + xlrd , xlsxwriter
lxml
shutil
f-string
import string
import random
li = list(range(10))
li.extend(string.ascii_letters)
print(random.sample(li, 6))
import chardet
import requests
response = requests.get('http://www.baidu.com')
chardet.detect(response.content)
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
集合操作
from collections import namedtuple
User = namedtuple('User',['name','age','height','edu'])
user_tuple = ('Frank',18,180,'master')
user_dict = dict(name='Tom',age=20,height=175,edu='PHD')
user = User._make(user_tuple)
print(','.join(map(lambda x:str(x) if not isinstance(x,str) else x,user)))
ordered_user_dict = user._asdict()
print(ordered_user_dict)
from collections import namedtuple,defaultdict,deque,Counter,OrderedDict,ChainMap
# named_tuple
def test():
User = namedtuple('User',['name','age','height','edu'])
user_tuple = ('Frank',18,180,'master')
user_dict = dict(name='Tom',age=20,height=175,edu='PHD')
user = User._make(user_tuple)
user = User._make(user_dict)
print(','.join(map(lambda x:str(x) if not isinstance(x,str) else x,user)))
ordered_user_dict = user._asdict()
print(ordered_user_dict)
# default dict
def test2():
user_dict = {}
user_list = ['frank','tom','tom','jim','Tom']
for user in user_list:
u = user.lower()
user_dict.setdefault(u,0)
user_dict[u]+=1
# if not u in user_dict:
# user_dict[u] = 1
# else:
# user_dict[u]+=1
print(user_dict)
def gen_default_0():
return 0
def test3():
user_dict = defaultdict(int or gen_default_0 or (lambda :0))
user_list = ['frank','tom','Tom','jim']
for user in user_list:
u = user.lower()
user_dict[u]+=1
print(user_dict)
# deque 线程安全
def test4():
dq = deque(['a','b','c'])
dq.appendleft('1')
print(dq)
dq.extendleft(['e','f','g'])
print(dq)
dq.popleft()
print(dq)
dq.insert(0,'g')
print(dq)
# Counter
def test5():
user_list = ['frank','tom','tom','jim']
user_counter = Counter(user_list)
print(user_counter.most_common(2))
alpha_counter = Counter('abccddadfaefedasdfwewefwfsfsfadadcdffghethethklkijl')
alpha_counter.update('fsfjwefjoe9uefjsljdfljdsoufbadflfmdlmjjdsnvdljflasdj')
print(alpha_counter.most_common(3))
#OrderedDict 只是说按照插入顺序有序。。。!!!
def test6():
ordered_dict = OrderedDict()
ordered_dict['b'] = '2'
ordered_dict['a'] = '1'
ordered_dict['c'] = '3'
# print(ordered_dict.popitem(last=False)) # last=True 从最后一个开始pop 否则从第一个开始
# print(ordered_dict.pop('a')) # 返回 被 pop 掉对应的 value
ordered_dict.move_to_end('b') #将指定 key 的 键值对移到最后位置
print(ordered_dict)
# 将多个 dict 串成链 车珠子。。。
def test7():
user_dict_1 = dict(a=1,b=2)
user_dict_2 = dict(b=3,c=5) # 两个出现同样key,采取第一次出现的value
chain_map = ChainMap(user_dict_1,user_dict_2)
new_chain_map = chain_map.new_child({'d': 6, 'e': 7, 'f': 8})
for key, value in chain_map.items():
print('{}--->{}'.format(key,value))
print('*'*100)
for key, value in new_chain_map.items():
print('{}--->{}'.format(key,value))
if __name__ == '__main__':
test()
test2()
test3()
test4()
test5()
test6()
test7()
自定义序列类 支持切片操作
# -*- coding: utf-8 -*-
import numbers
import bisect
class Group(object):
# 支持切片
def __init__(self,group_name,company_name,staffs):
self.group_name = group_name
self.company_name = company_name
self.staffs = staffs
def __reversed__(self):
self.staffs.reverse()
def __getitem__(self, item):
cls = type(self)
if isinstance(item,slice):
return cls(group_name=self.group_name,company_name=self.company_name,staffs=self.staffs[item])
elif isinstance(item,numbers.Integral):
return cls(group_name=self.group_name,company_name=self.company_name,staffs=[self.staffs[item]])
def __len__(self):
return len(self.staffs)
def __iter__(self):
return iter(self.staffs)
def __contains__(self, item):
return item in self.staffs
if __name__ == '__main__':
group = Group(group_name='AI Team',company_name='Intel',staffs=['Frank','Tom','Jim'])
print(len(group))
print(group[2].staffs)
reversed(group) # 反转
for item in group[1:]:
print(item)
使用 bisect 维护排序好的序列
# -*- coding: utf-8 -*-
import bisect
from collections import deque
def test():
insert_seq = deque()
bisect.insort(insert_seq,3)
bisect.insort(insert_seq,2)
bisect.insort(insert_seq,4)
return insert_seq
if __name__ == '__main__':
res = test()
print(res)
# 应该
print(bisect.bisect(res,7)) #bisect = bisect_right # backward compatibility
print(res)
如果 一个数组类型 都一样 建议使用 array ,因为其查找效率较高
import array
my_array = array.array('i')
for i in range(10):
my_array.append(i)
print(my_array)
my_list = ['person1','person2']
my_dict = dict.fromkeys(my_list,[{'name':'frank'},{'name':'tom'}])
print(my_dict)
from collections import Counter
"""
找出出现频率最高的数字
"""
def find_top1(t_list):
summary = {item:test.count(item)for item in test}
result = sorted(summary.items(), key=lambda t:t[1], reverse=True)
return result.pop(0)
def find_top(t_list):
result = {}
for item in t_list:
if item in result:
result[item] += 1
else:
result[item] = 1
return sorted(result.items(), key=lambda t:t[1], reverse=True).pop(0)
if __name__ == '__main__':
test = [1, 2, 3, 4, 2, 2, 3, 1, 4, 4, 4]
t = Counter(test)
print(t.most_common(1))
print(find_top(test))
print(max(set(test),key=test.count))
from collections import namedtuple,defaultdict,deque,Counter,OrderedDict,ChainMap
# named_tuple
def test():
User = namedtuple('User',['name','age','height','edu'])
user_tuple = ('Frank',18,180,'master')
user_dict = dict(name='Tom',age=20,height=175,edu='PHD')
user = User._make(user_tuple)
user = User._make(user_dict)
print(','.join(map(lambda x:str(x) if not isinstance(x,str) else x,user)))
ordered_user_dict = user._asdict()
print(ordered_user_dict)
# default dict
def test2():
user_dict = {}
user_list = ['frank','tom','tom','jim','Tom']
for user in user_list:
u = user.lower()
user_dict.setdefault(u,0)
user_dict[u]+=1
# if not u in user_dict:
# user_dict[u] = 1
# else:
# user_dict[u]+=1
print(user_dict)
def gen_default_0():
return 0
def test3():
user_dict = defaultdict(int or gen_default_0 or (lambda :0))
user_list = ['frank','tom','Tom','jim']
for user in user_list:
u = user.lower()
user_dict[u]+=1
print(user_dict)
# deque 线程安全
def test4():
dq = deque(['a','b','c'])
dq.appendleft('1')
print(dq)
dq.extendleft(['e','f','g'])
print(dq)
dq.popleft()
print(dq)
dq.insert(0,'g')
print(dq)
# Counter
def test5():
user_list = ['frank','tom','tom','jim']
user_counter = Counter(user_list)
print(user_counter.most_common(2))
alpha_counter = Counter('abccddadfaefedasdfwewefwfsfsfadadcdffghethethklkijl')
alpha_counter.update('fsfjwefjoe9uefjsljdfljdsoufbadflfmdlmjjdsnvdljflasdj')
print(alpha_counter.most_common(3))
#OrderedDict 只是说按照插入顺序有序。。。!!!
def test6():
ordered_dict = OrderedDict()
ordered_dict['b'] = '2'
ordered_dict['a'] = '1'
ordered_dict['c'] = '3'
# print(ordered_dict.popitem(last=False)) # last=True 从最后一个开始pop 否则从第一个开始
# print(ordered_dict.pop('a')) # 返回 被 pop 掉对应的 value
ordered_dict.move_to_end('b') #将指定 key 的 键值对移到最后位置
print(ordered_dict)
# 将多个 dict 串成链 车珠子。。。
def test7():
user_dict_1 = dict(a=1,b=2)
user_dict_2 = dict(b=3,c=5) # 两个出现同样key,采取第一次出现的value
chain_map = ChainMap(user_dict_1,user_dict_2)
new_chain_map = chain_map.new_child({'d': 6, 'e': 7, 'f': 8})
for key, value in chain_map.items():
print('{}--->{}'.format(key,value))
print('*'*100)
for key, value in new_chain_map.items():
print('{}--->{}'.format(key,value))
if __name__ == '__main__':
test()
test2()
test3()
test4()
test5()
test6()
test7()
from collections import defaultdict
import logging
logging.basicConfig(level=logging.DEBUG)
def group_by_firstletter(words=None):
word_dict = {}
for word in words:
first_letter = word[0]
if first_letter in word_dict:
word_dict[first_letter] += 1
else:
word_dict[first_letter] = 1
return word_dict
def group_by_firstletter2(words=None):
default_word_dict = defaultdict(int)
for word in words:
default_word_dict[word[0]]+=1
return default_word_dict
def group_by_firstletter3(words=None):
words_dict = {}
for word in words:
if word[0] in words_dict:
words_dict[word[0]].append(word)
else:
words_dict[word[0]] = [word]
return words_dict
def group_by_firstletter4(words=None):
default_word_dict = defaultdict(list)
for word in words:
default_word_dict[word[0]].append(word)
return default_word_dict
if __name__ == '__main__':
words = ['apple', 'bat', 'bar', 'atom', 'book']
logging.info(group_by_firstletter(words))
logging.info(group_by_firstletter2(words))
logging.info(group_by_firstletter3(words))
logging.info(group_by_firstletter4(words))
from collections import Iterator, Iterable
from collections import defaultdict
from collections import Counter, ChainMap, OrderedDict, namedtuple, deque
from itertools import islice # 替代 切片,但是只能 是正数
from itertools import zip_longest # 替代 zip 可以 对不一样个数的 进行迭代
from concurrent.futures import ThreadPoolExecutor as Pool
from collections import namedtuple, deque, defaultdict, OrderedDict, ChainMap, Counter
Point = namedtuple('Poing',['x','y','z'])
p = Point(1,2,3)
print(p.x,'--',p.y,'--',p.z)
# 双向列表
dq = deque([1,2,3,4])
dq.append(5)
dq.appendleft('a')
dq.popleft()
default_dict = defaultdict(lambda:'N/A') # 多了一个默认值
default_dict['name']='frank'
default_dict['age']
od = OrderedDict([('b',1),('a',2),('c',3)]) # 按照插入的顺序有序
od.get('a')
# 可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print('remove:', last)
if containsKey:
del self[key]
print('set:', (key, value))
else:
print('add:', (key, value))
OrderedDict.__setitem__(self, key, value)
# 应用场景 设置参数优先级
from collections import ChainMap
import os, argparse
# 构造缺省参数:
defaults = {
'color': 'red',
'user': 'guest'
}
# 构造命令行参数:
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = { k: v for k, v in vars(namespace).items() if v }
# 组合成ChainMap:
combined = ChainMap(command_line_args, os.environ, defaults)
# 打印参数:
print('color=%s' % combined['color'])
print('user=%s' % combined['user'])
itertools
from itertools import count, repeat, cycle, chain, takewhile, groupby
def times_count(base,n):
for x in count(base):
if n<=0:
break
yield str(x)
n-=1
def times_repeat(s,n):
return '-'.join(repeat(s,n))
def times_cycle(s,n):
for v in cycle(s):
if n<= 0:
break
yield s
n-=1
if __name__ == '__main__':
print(times_repeat('*',3))
for s in times_cycle('ABC',3):
print(s)
r = ','.join(chain('ABC', 'XYZ'))
print(r)
print(','.join(times_count(5,3)))
print(','.join( takewhile(lambda x:int(x)<10, times_count(1,30))))
group_dict = {key:list(group) for key, group in groupby(['abort','abandon','book','cook','bird'], lambda ch: ch[0].upper())}
print(group_dict)
# -*- coding: utf-8 -*-
import itertools
from functools import reduce
def pi(N):
' 计算pi的值 '
# step 1: 创建一个奇数序列: 1, 3, 5, 7, 9, ...
odd_iter = itertools.count(1, 2)
# step 2: 取该序列的前N项: 1, 3, 5, 7, 9, ..., 2*N-1.
odd_head = itertools.takewhile(lambda n: n <= 2 * N - 1, odd_iter)
# print(list(odd_head),end=',')
# step 3: 添加正负符号并用4除: 4/1, -4/3, 4/5, -4/7, 4/9, ...
odd_final = [4 / n * ((-1) ** i) for i, n in enumerate(odd_head)]
# step 4: 求和:
value = reduce(lambda x, y: x + y, odd_final)
return value
# 测试:
print(pi(10))
print(pi(100))
print(pi(1000))
print(pi(10000))
assert 3.04 < pi(10) < 3.05
assert 3.13 < pi(100) < 3.14
assert 3.140 < pi(1000) < 3.141
assert 3.1414 < pi(10000) < 3.1415
print('ok')
查找 两值之和 等于 目标值的 下标的生成器
def find_idx(tar, t_list):
low, high = 0, len(t_list) - 1
while low<high:
print(low,'--', high)
while low < high:
if t_list[low] + t_list[high] == tar:
print('found...')
yield low, high
high-=1
low+=1
if __name__ == '__main__':
li = [2, 7, 11, 15]
for low, high in find_idx(9,li):
print(low,'--',high)
**重置递归限制 **
Python 限制递归次数到 1000,我们可以重置这个值
import sys
print(sys.getrecursionlimit())
#1-> 1000
sys.setrecursionlimit(x)
print(sys.getrecursionlimit())
#2-> 1001
list 去重
# 给 list 去重
li = [1, 1, 1, 23, 3, 4, 4]
li_set = {}.fromkeys(li).keys() or set(li)
单例
- 装饰器实现单例
def singleton(cls):
instance_dict = {}
def singleton_wrapper(*args, **kwargs):
print(id(instance_dict))
if cls not in instance_dict:
instance_dict[cls] = cls(*args, **kwargs)
return instance_dict[cls]
return singleton_wrapper
@singleton
class SingleTest():
pass
if __name__ == '__main__':
s1 = SingleTest()
s2 = SingleTest()
assert s1 == s2
- 基于 new 方法的 单例
# 基于 __new__ 方法的 单例,跟 java 懒汉式一样需要考虑线程安全问题
import threading
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
class Person:
_instance_lock = threading.Lock()
def __new__(cls, *args, **kwargs):
if not hasattr(cls,'_instance'):
with cls._instance_lock:
cls._instance = object.__new__(cls)
return cls._instance
if __name__ == '__main__':
person_1 = Person()
person_2 = Person()
assert person_1 is person_2
二分查找
def bin_find(num,li=None):
li.sort() # 二分查找前提就是先要保证有序
low, high = 0, len(li)
indx = None
while low<=high:
mid = (low+high) // 2
if li[mid] > num:
high = mid-1
elif li[mid]<num:
low = mid+1
else:
indx = mid
break
return indx
if __name__ == '__main__':
lis = [0, 1, 3, 4, 5, 6, 7, 9, 10, 11, 12, 16, 17]
logging.debug(bin_find(12,lis))
# 模拟栈操作
class Stack(object):
def __init__(self):
self._stack = []
def push(self,element):
self._stack.append(element)
def pop(self):
self._stack.pop()
def is_empty(self):
return bool(self._stack)
def top(self):
try:
top_value = self._stack[0]
except Exception:
raise ValueError('empty stack...')
模拟发红包
81、代码实现随机发红包功能
import random
def red_packge(money,num):
li = random.sample(range(1,money*100),num-1)
li.extend([0,money*100])
li.sort()
return [(li[index+1]-li[index])/100 for index in range(num)]
ret = red_packge(100,10)
print(ret)
--------------------------生成器版-------------------------------------------
import random
def red_packge(money,num):
li = random.sample(range(1,money*100),num-1)
li.extend([0,money*100])
li.sort()
for index in range(num):
yield (li[index+1]-li[index])/100
ret = red_packge(100,10)
print(ret)
断言
assert list(map(lambda x:x**2,range(1,11))) == [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 使用 unittest 进行单元测试可以用 assertEquals
import unittest
class MyUnitTest(unittest.TestCase):
def test_assert(self):
self.assertEqual(list(map(lambda x:x**2,range(1,11))), [1, 4, 9, 16, 25, 36, 49, 64, 81, 100])
if __name__ == '__main__':
unittest.main()
import unittest
class MyUnitTest(unittest.TestCase):
def test_assert(self):
self.assertEqual(list(map(lambda x:x**2 , range(3))), [0,1,4])
if __name__ == '__main__':
suit = unittest.defaultTestLoader.loadTestsFromTestCase(MyUnitTest)
runner = unittest.TextTestRunner()
runner.run(suit)
inspect 内省
import inspect
def a(a, b=0, *c, d, e=1, **f):
pass
aa = inspect.signature(a)
print("inspect.signature(fn)是:%s" % aa)
print("inspect.signature(fn)的类型:%s" % (type(aa)))
print("\n")
bb = aa.parameters
print("signature.paramerters属性是:%s" % bb)
print("ignature.paramerters属性的类型是%s" % type(bb))
print("\n")
for cc, dd in bb.items():
print("mappingproxy.items()返回的两个值分别是:%s和%s" % (cc, dd))
print("mappingproxy.items()返回的两个值的类型分别是:%s和%s" % (type(cc), type(dd)))
print("\n")
ee = dd.kind
print("Parameter.kind属性是:%s" % ee)
print("Parameter.kind属性的类型是:%s" % type(ee))
print("\n")
gg = dd.default
print("Parameter.default的值是: %s" % gg)
print("Parameter.default的属性是: %s" % type(gg))
print("\n")
ff = inspect.Parameter.KEYWORD_ONLY
print("inspect.Parameter.KEYWORD_ONLY的值是:%s" % ff)
print("inspect.Parameter.KEYWORD_ONLY的类型是:%s" % type(ff))
import inspect
def func_a(arg_a, *args, arg_b='hello', **kwargs):
print(arg_a, arg_b, args, kwargs)
class Fib:
def __init__(self,n):
a, b = 0, 1
i = 0
self.fib_list = []
while i<n:
self.fib_list.append(a)
a, b = b, a+b
i+=1
def __getitem__(self, item):
return self.fib_list[item]
if __name__ == '__main__':
fib = Fib(5)
print(fib[0:3])
# 获取函数签名
func_signature = inspect.signature(func_a)
func_args = []
# 获取函数所有参数
for k, v in func_signature.parameters.items():
# 获取函数参数后,需要判断参数类型
# 当kind为 POSITIONAL_OR_KEYWORD,说明在这个参数之前没有任何类似*args的参数,那这个函数可以通过参数位置或者参数关键字进行调用
# 这两种参数要另外做判断
if str(v.kind) in ('POSITIONAL_OR_KEYWORD', 'KEYWORD_ONLY'):
# 通过v.default可以获取到参数的默认值
# 如果参数没有默认值,则default的值为:class inspect_empty
# 所以通过v.default的__name__ 来判断是不是_empty 如果是_empty代表没有默认值
# 同时,因为类本身是type类的实例,所以使用isinstance判断是不是type类的实例
if isinstance(v.default, type) and v.default.__name__ == '_empty':
func_args.append({k: None})
else:
func_args.append({k: v.default})
# 当kind为 VAR_POSITIONAL时,说明参数是类似*args
elif str(v.kind) == 'VAR_POSITIONAL':
args_list = []
func_args.append(args_list)
# 当kind为 VAR_KEYWORD时,说明参数是类似**kwargs
elif str(v.kind) == 'VAR_KEYWORD':
args_dict = {}
func_args.append(args_dict)
print(func_args)
import inspect
def func_a(arg_a, *args, arg_b='hello', **kwargs):
print(arg_a, arg_b, args, kwargs)
if __name__ == '__main__':
# 获取函数签名
func_signature = inspect.signature(func_a)
func_args = []
# 获取函数所有参数
for k, v in func_signature.parameters.items():
# 获取函数参数后,需要判断参数类型
# 当kind为 POSITIONAL_OR_KEYWORD,说明在这个参数之前没有任何类似*args的参数,那这个函数可以通过参数位置或者参数关键字进行调用
# 这两种参数要另外做判断
if str(v.kind) in ('POSITIONAL_OR_KEYWORD', 'KEYWORD_ONLY'):
# 通过v.default可以获取到参数的默认值
# 如果参数没有默认值,则default的值为:class inspect_empty
# 所以通过v.default的__name__ 来判断是不是_empty 如果是_empty代表没有默认值
# 同时,因为类本身是type类的实例,所以使用isinstance判断是不是type类的实例
if isinstance(v.default, type) and v.default.__name__ == '_empty':
func_args.append({k: None})
else:
func_args.append({k: v.default})
# 当kind为 VAR_POSITIONAL时,说明参数是类似*args
elif str(v.kind) == 'VAR_POSITIONAL':
args_list = []
func_args.append(args_list)
# 当kind为 VAR_KEYWORD时,说明参数是类似**kwargs
elif str(v.kind) == 'VAR_KEYWORD':
args_dict = {}
func_args.append(args_dict)
print(func_args)
解析 html
from html.parser import HTMLParser
from html.entities import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print('<%s>' % tag)
def handle_endtag(self, tag):
print('</%s>' % tag)
def handle_startendtag(self, tag, attrs):
print('<%s/>' % tag)
def handle_data(self, data):
print(data)
def handle_comment(self, data):
print('<!--', data, '-->')
def handle_entityref(self, name):
print('&%s;' % name)
def handle_charref(self, name):
print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('''<html>
<head></head>
<body>
<!-- test html parser -->
<p>Some <a href=\"#\">html</a> HTML tutorial...<br>END</p>
</body></html>''')
解析 xml
import lxml
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def start_element(self, name, attrs):
print('sax:start_element: %s, attrs: %s' % (name, str(attrs)))
def end_element(self, name):
print('sax:end_element: %s' % name)
def char_data(self, text):
print('sax:char_data: %s' % text)
xml = r'''<?xml version="1.0"?>
<ol>
<li><a href="/python">Python</a></li>
<li><a href="/ruby">Ruby</a></li>
</ol>
'''
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
日期操作
# datetime
from datetime import datetime,timedelta
now = datetime.now()
# datetime 转 timestamp
now_timestamp = now.timestamp()
# timestampe 转本地 datetime
dt_local = datetime.fromtimestamp(now_timestamp)
# timestampe 转utc datetime
dt_utc = datetime.utcfromtimestamp(now_timestamp)
# 时间戳 没有时区, datetime中携带
print(dt_local.timestamp(),'<-->',dt_utc.timestamp())
print('{}\n{}\n{}\n{}'.format(now,now_timestamp,dt_local,dt_utc))
# 获取指定 日期和时间
year = 2019
month =3
day =3
hour = 15
minute = 7
dt_specified = datetime(year,month,day,hour,minute)
print(dt_specified)
# str 转 datetime str parse
datetime_str = '2019-03-03 15:22:00'
datetime_parse_format = '%Y-%m-%d %H:%M:%S'
cday = datetime.strptime(datetime_str,datetime_parse_format)
print(cday)
# datetime 转 str str format
print(cday.strftime('%Y/%m/%d'))
# 日期变化(delta) 用 timedelta
now = datetime.now()
now_next3_hours = now+timedelta(hours=3)
now_previous3_days = now+timedelta(days=-3)
print('next 3 hours: {}'.format(now_next3_hours))
print('now_previous3_days: {}'.format(now_previous3_days))
from datetime import timezone
tz_utc_8 = timezone(timedelta(hours=8))
now = datetime.now()
# 一开始 now 时区信息为 None
print(now.tzinfo)
# 暴力设置一个时区
now.replace(tzinfo=tz_utc_8)
print(now)
utc_now = datetime.utcnow()
# 一开始这玩意儿压根木有时区信息啊
print(utc_now.tzinfo)
# 暴力设置时区信息
utc_now = utc_now.replace(tzinfo=timezone.utc)
#北京日期时间 东八区
bj_dt = utc_now.astimezone(timezone(timedelta(hours=8)))
# 西八区
pst_dt = utc_now.astimezone(timezone(timedelta(hours=-8)))
# 东 9 区
tokyo_dt = utc_now.astimezone(timezone(timedelta(hours=9)))
print('bj_dt: ',bj_dt)
print('pst_dt: ',pst_dt)
print('tokyo_dt: ',tokyo_dt)
from datetime import datetime, timezone,timedelta
import re
def to_timestamp(dt_str,tz_str):
re_dt_str_1 = r'\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}'
re_tz_str = r'^UTC([+-])(\d{1,2}):\d{2}$'
tz_grps = re.match(re_tz_str,tz_str).groups()
sign = tz_grps[0]
hours = int(tz_grps[1])
if re.match(re_dt_str_1,dt_str):
dt = datetime.strptime(dt_str,'%Y-%m-%d %H:%M:%S')
if sign=='+':
tz_info_x = timezone(timedelta(hours=hours))
else:
tz_info_x = timezone(timedelta(hours=-hours))
dt = dt.replace(tzinfo=tz_info_x)
else:
print('re is wrong!')
return dt.timestamp()
# 测试:
t1 = to_timestamp('2015-6-1 08:10:30', 'UTC+7:00')
assert t1 == 1433121030.0, t1
t2 = to_timestamp('2015-5-31 16:10:30', 'UTC-09:00')
assert t2 == 1433121030.0, t2
print('ok')
python 魔法函数也就是 协议(python 中实现了某些方法则他就可以等同该类型)
# 事实证明,所有序列操作都应该会先走特定的魔法函数,然后实在没有转入 __getitem__
from collections.abc import Iterable, Iterator
from types import GeneratorType
from contextlib import contextmanager
class Company:
def __init__(self,employee_list):
self.employee_list = employee_list
# 序列相关
def __getitem__(self, item):
print('getitem executed...')
cls = type(self)
if isinstance(item,slice):
return cls(self.employee_list[item])
elif isinstance(item,int):
return cls([self.employee_list[item]])
def __setitem__(self, key, value):
self.employee_list[key] = value
def __delitem__(self, key):
del self.employee_list[key]
def __len__(self):
print('len executed...')
return len(self.employee_list)
def __contains__(self, item):
print('contains executed...')
return item in self.employee_list
# 迭代相关
# 实现了 __iter__ 仅仅是刻碟带对象 (Iterable)
def __iter__(self):
print('iter executed...')
return iter(self.employee_list)
# 实现 __next__ 仅仅只是迭代器(Iterator)不是生成器
def __next__(self):
print('next executed...')
pass
# 可调用
def __call__(self, *args, **kwargs):
print('__call__ executed...')
pass
# 上下文管理
def __enter__(self):
# self.fp = open('xxx')
print('__enter__ executed...')
pass
def __exit__(self, exc_type, exc_val, exc_tb):
print('__exit__ executed...')
pass
# 释放资源等操作 self.fp.close()
@contextmanager
def Resource(self):
self.fp = open('./sample.csv')
yield self.fp
self.fp.close()
def __repr__(self):
return ','.join(self.employee_list)
__str__ = __repr__
if __name__ == '__main__':
company = Company(['Frank','Tom','May'])
company()
for employee in company:
print(employee)
print(company[1:])
print(isinstance(company,Iterable))
print(isinstance(company,Iterator))
print(isinstance(company,GeneratorType))
print(isinstance((employee for employee in company),GeneratorType))
print(len(company))
print('Jim' in company)
class MyVector(object):
def __init__(self,x,y):
self.x = x
self.y = y
def __add__(self, other):
cls = type(self)
return cls(self.x+other.x, self.y+other.y)
def __repr__(self):
return '({},{})'.format(self.x,self.y)
def __str__(self):
return self.__repr__()
if __name__ == '__main__':
vector1 = MyVector(1,2)
vector2 = MyVector(2,3)
assert str(vector1+vector2) == '(3,5)'
assert (vector1+vector2).__repr__() == '(3,5)'
import abc
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod
def set(self,key):
pass
@abc.abstractmethod
def get(self,value):
pass
class RedisCache(CacheBase):
pass
# 实际用抽象基类不多,更多的是用的 mixin 做法 鸭子类型,可以参考 Django restfulAPI framework
if __name__ == '__main__':
redis_cache = RedisCache() # TypeError: Can't instantiate abstract class RedisCache with abstract methods get, set
生成器 (协程的底层原理)
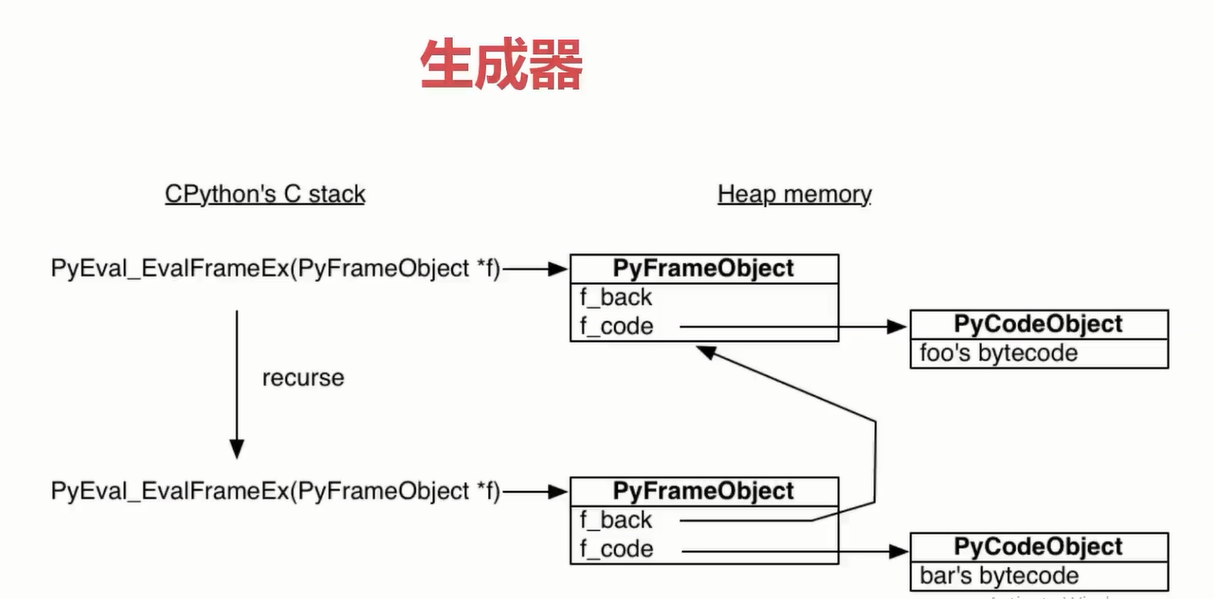
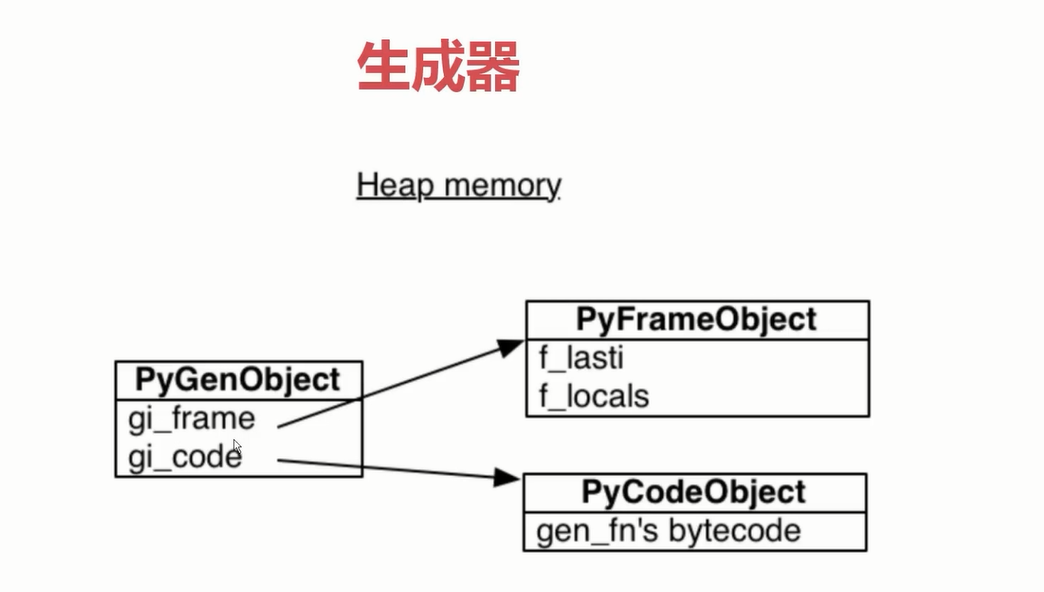
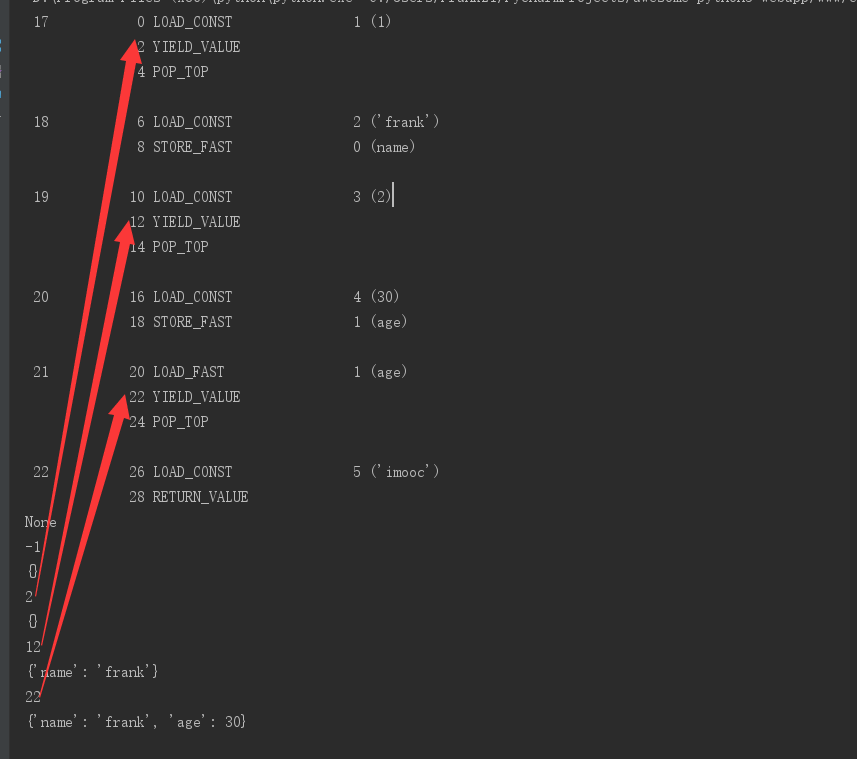
### 生成器原理 以及 协程的 最底层原理
import dis
def gen_func():
yield 1
name = 'frank'
yield 2
age = 30
yield age
return "imooc"
if __name__ == '__main__':
# print(dis.dis(foo))
# foo()
# print('*'*100)
# print(frame.f_code.co_name)
# caller_frame = frame.f_back
# print(caller_frame.f_code.co_name)
gen = gen_func()
print(dis.dis(gen))
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
彻底弄懂 函数 在 堆内存中 栈帧的 具体操作
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import dis
import inspect
frame = None
def foo():
bar()
pass
def bar():
global frame
frame = inspect.currentframe()
if __name__ == '__main__':
print(dis.dis(foo))
foo()
print('*'*100)
print(frame.f_code.co_name)
caller_frame = frame.f_back
print(caller_frame.f_code.co_name)
多线程 多进程
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server.bind(('127.0.0.1',6666))
clients = set()
print('server bind 127.0.0.1:6666...')
while 1:
try:
data,addr = server.recvfrom(1024)
clients.add(addr)
if not data or data.decode('utf-8')=='pong':
continue
print('%s:%s >>> %s' % (addr[0],addr[1],data.decode('utf-8')))
for usr in clients:
if usr!=addr:
server.sendto(('%s:%s >>> %s' % (addr[0],addr[1],data.decode('utf-8'))).encode('utf-8'),usr)
except Exception as e:
pass
########################################################
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import socket,threading,os
client = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
client.sendto(b'pong',('127.0.0.1',6666))
def myinput():
while 1:
try:
msg = input('>>>')
yield msg
except Exception as e:
os._exit(0)
def getMsg(client):
while 1:
try:
r = client.recv(1024)
print('\n',r.decode('utf-8'),'\n>>>',end='')
except Exception as e:
pass
c = myinput()
def sendMsg(msg):
while 1:
msg = next(c)
client.sendto(msg.encode('utf-8'),('127.0.0.1',6666))
threading.Thread(target=sendMsg,args=(client,)).start()
threading.Thread(target=getMsg,args=(client,)).start()
多线程 第二种方法 ,继承 threading.Thread 覆写 run 方法 跟 java 一样 ,还有一种就是 t = Thread(target=func_name,args=(arg1,arg2,))
from threading import Thread
import time
import logging
logging.basicConfig(level=logging.DEBUG)
class Get_html(Thread):
def __init__(self, name):
super(Get_html,self).__init__(name=name)
def run(self):
logging.info('thread {name} started...'.format(name=self.name))
time.sleep(2)
logging.info('thread {name} ended...'.format(name=self.name))
class Parse_html(Thread):
def __init__(self, name):
super().__init__(name=name)
def run(self):
logging.info('Thread {name} started...'.format(name=self.name))
time.sleep(4)
logging.info('Thread {name} ended...'.format(name=self.name))
if __name__ == '__main__':
start = time.time()
get_html_thread = Get_html('get_html_thread')
parse_html_thread = Parse_html('parse_html_thread')
get_html_thread.start()
parse_html_thread.start()
get_html_thread.join()
parse_html_thread.join()
logging.info('cost {} in total...'.format(time.time()-start))
>>> import chardet
>>> import requests
>>> response = requests.get('http://www.baidu.com')
>>> chardet.detect(response.content)
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from threading import (Thread,Lock)
lock = Lock()
total=0
def ascend():
global total
global lock
for i in range(10**6):
with lock:
total+=1
def descend():
global total
global lock
for i in range(10**6):
lock.acquire()
total-=1
lock.release()
if __name__ == '__main__':
ascend_thread = Thread(target=ascend)
descend_thread = Thread(target=descend)
ascend_thread.start()
descend_thread.start()
ascend_thread.join()
descend_thread.join()
print(total)
可重入锁
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from threading import (Thread,Lock,RLock)
### 线程间同步问题 用 锁来保证安全, 但是要防止死锁的发生,所以在单个线程里引入 RLock(可重入锁)
# lock = Lock()
lock = RLock()
total=0
def ascend():
global total
global lock
for i in range(10**6):
with lock:
total+=1
def descend():
global total
global lock
for i in range(10**6):
lock.acquire()
lock.acquire() # lock 为 Lock 时候 死锁, RLock则不会
total-=1
lock.release() # 为了 防止线程间 死锁,这里释放一下
lock.release()
if __name__ == '__main__':
ascend_thread = Thread(target=ascend)
descend_thread = Thread(target=descend)
ascend_thread.start()
descend_thread.start()
ascend_thread.join()
descend_thread.join()
print(total)
(threading 模块下) Condition 用于线程间同步 wait ,notify(all) ,Semaphore 用于控制每次创建线程数,方便实用当然是线程池,进程池(concurrent.futures 下)
from threading import (Thread,Condition)
class XiaoAI(Thread):
def __init__(self,cond,name='小爱'):
super().__init__(name=name)
self.cond = cond
def run(self):
with self.cond:
self.cond.wait()
print('{name}: 在'.format(name=self.name))
self.cond.notify()
self.cond.wait()
print('{name}: 好啊!'.format(name=self.name))
self.cond.notify()
class TianMao(Thread):
def __init__(self,cond,name='天猫'):
super().__init__(name=name)
self.cond = cond
def run(self):
with cond:
print('{name}:小爱同学'.format(name=self.name))
self.cond.notify()
self.cond.wait()
print('{name}: 我们来对古诗吧。'.format(name=self.name))
self.cond.notify()
self.cond.wait()
if __name__ == '__main__':
cond = Condition()
xiao = XiaoAI(cond)
tian = TianMao(cond)
xiao.start()
tian.start()
xiao.join()
tian.join()
from threading import (Thread,Semaphore)
from urllib.parse import urlencode
import requests
import chardet
import logging
from os import path
import random
import re
logging.basicConfig(level=logging.DEBUG)
# https://tieba.baidu.com/f?kw=%E5%B8%83%E8%A2%8B%E6%88%8F&ie=utf-8&pn=100
class TieBaSpider(Thread):
def __init__(self,url,sem,name='TieBaSpider'):
super(TieBaSpider,self).__init__(name=name)
self.url = url
self.sem = sem
def _save(self,text):
parent_dir = r'D:\tieba'
file_name = path.join(parent_dir,path.split(re.sub(r'[%|=|&|?]','',self.url))[1])+'.html'
with open(file_name,'w',encoding='utf-8') as fw:
fw.write(text)
fw.flush()
return 1
def run(self):
# ua_list = ["Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
# "Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
# "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
# "Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
# "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"]
# header = {'User-Agent':random.choice(ua_list)}
response = requests.get(self.url)#header=header)
content = response.content
logging.info(response.encoding)
# result = chardet.detect(content)
# logging.info(result)
# code = result.get('encoding','utf-8')
self._save(content.decode(response.encoding))
self.sem.release()
class UrlProducer(Thread):
def __init__(self,tb_name,sem,pages_once=3,start_index=1,end_index=9):# end-start % pages_once == 0
super(UrlProducer,self).__init__(name=tb_name)
self.tb_name = urlencode(tb_name)
self.sem = sem
logging.info(self.tb_name)
self.pages_once = pages_once
self.start_index = start_index
self.end_index = end_index
def run(self):
for page_idx in range(self.start_index,self.end_index+1):
self.sem.acquire()
url_prefix = r'https://tieba.baidu.com/f?'
url_suffix = r'&fr=ala0&tpl='
self.url = url_prefix+self.tb_name+url_suffix+str(page_idx)
tb_spider = TieBaSpider(self.url,self.sem)
tb_spider.start()
if __name__ == '__main__':
kw_dict = dict(kw=r'国家地理')
sem = Semaphore(3) # 控制一次并发 3 个线程
url_producer = UrlProducer(kw_dict,sem=sem)
url_producer.start()
url_producer.join()
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
from concurrent.futures import Future
def get_html(times):
time.sleep(times)
print('get page {} success'.format(times))
return times
if __name__ == '__main__':
pool = ThreadPoolExecutor(max_workers=2)
task_2 = pool.submit(get_html,(2))
task_3 = pool.submit(get_html,(3))
# print(dir(task_2)) #Future
# print(task_3.done())
#
# if task_3.done():
# print(task_3.result())
#
# time.sleep(5)
# print(task_3.done())
# if task_3.done():
# print(task_3.result())
urls = [1,2,3,4]
all_tasks = [pool.submit(get_html,url) for url in urls]
for future in as_completed(all_tasks):
res = future.result()
print('get result {}'.format(res))
print('*'*100)
for res in pool.map(get_html,urls):
print('get result {} using map'.format(res))
线程池与进程池分别进行 模拟 cpu 计算 跟 IO 等待 并发 总结
'''
cpu 计算密集型, 多进程 消耗时间少于线程 因为 GIL 锁的存在
iO 密集型, 多线程其实因为 GIL 锁 本应该也要弱于多进程,但是切换线程的开销比较多进程切换而言更低
一个主机可以开的线程数与可以开的进程数是不可同日而语的,所以,python的多线程也并不是一无是处
io 主要花在时间等待上故可以用 time.sleep 来模拟, cpu 主要花在计算可以用斐波拉契数列来模拟
'''
cpu 运算密集,结果 多进程略优于多线程,当然由于时间限制,我们将数字调低了,如果有时间等待调高计算次数,那么差异应该很明显
先看 cpu 密集结果:
INFO:root:res: 75025
INFO:root:res: 121393
INFO:root:res: 196418
INFO:root:res: 317811
INFO:root:res: 514229
INFO:root:res: 832040
INFO:root:res: 1346269
INFO:root:res: 2178309
INFO:root:res: 3524578
INFO:root:res: 5702887
INFO:root:thread_cpu cost 4.97 s
INFO:root:****************************************************************************************************
INFO:root:res: 75025
省略 n 个
INFO:root:res: 196418
INFO:root:process_cpu cost 4.16 s
### 仔细看代码
from concurrent.futures import (ThreadPoolExecutor,
ProcessPoolExecutor,
as_completed)
from functools import wraps
import time
import logging
logging.basicConfig(level=logging.DEBUG)
'''
cpu 计算密集型, 多进程 消耗时间少于线程 因为 GIL 锁的存在
iO 密集型, 多线程其实因为 GIL 锁 本应该也要弱于多进程,但是切换线程的开销比较多进程切换而言更低
一个主机可以开的线程数与可以开的进程数是不可同日而语的,所以,python的多线程也并不是一无是处
io 主要花在时间等待上故可以用 time.sleep 来模拟, cpu 主要花在计算可以用斐波拉契数列来模拟
'''
def time_decor(func):
@wraps(func)
def wrapper_func(*args,**kw):
start = time.time()
result = func(*args,**kw)
logging.info('{} cost {:.2f} s'.format(func.__name__,(time.time()-start)))
return result
return wrapper_func
def fib(n):
if n<=2:
return 1
else:
return fib(n-1) + fib(n-2)
@time_decor
def thread_cpu(n):
with ThreadPoolExecutor(n) as executor:
all_tasks = [executor.submit(fib,(i)) for i in range(25,35)]
for feature in as_completed(all_tasks):
res = feature.result()
logging.info('res: {}'.format(res))
@time_decor
def process_cpu(n):
with ProcessPoolExecutor(n) as executor:
all_tasks = [executor.submit(fib,(i)) for i in range(25,35)]
# for res in executor.map(fib,range(25,35)):
# logging.info(''.format(res))
for future in as_completed(all_tasks):
res = future.result()
logging.info('res: {}'.format(res))
if __name__ == '__main__':
thread_cpu(3)
logging.info('*'*100)
process_cpu(3)
io 密集时候 ,线程池略优于 进程池
先看 io 密集 结果:
INFO:root:res: 2
INFO:root:res: 2
此处省略 n 次 中间结果。。。。。
INFO:root:res: 2
INFO:root:thread_io cost 20.01 s
INFO:root:****************************************************************************************************
INFO:root:res: 2
INFO:root:res: 2
此处省略 n 次 中间结果。。。。。
INFO:root:res: 2
INFO:root:process_io cost 20.52 s
### 具体代码
from concurrent.futures import (ThreadPoolExecutor,ProcessPoolExecutor,as_completed)
from functools import wraps
import time
import logging
logging.basicConfig(level=logging.DEBUG)
def time_decor(func):
@wraps(func)
def wrapper_func(*args,**kw):
start_time = time.time()
result = func(*args,**kw)
logging.info('{} cost {:.2f} s'.format(func.__name__,(time.time()-start_time)))
return result
return wrapper_func
def monitor_io(n):
time.sleep(n)
return n
@time_decor
def thread_io(n):
with ThreadPoolExecutor(n) as executor:
all_tasks = [executor.submit(monitor_io,i) for i in [2]*30]
for future in as_completed(all_tasks):
res = future.result()
logging.info('res: {}'.format(res))
return n
@time_decor
def process_io(n):
with ProcessPoolExecutor(n) as executor:
all_task = [executor.submit(monitor_io,i) for i in [2]*30]
for future in as_completed(all_task):
res = future.result()
logging.info('res: {}'.format(res))
if __name__ == '__main__':
thread_io(3)
logging.info('*'*100)
process_io(3)
第二版 非阻塞 采用循环 询问
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from urllib.parse import urlparse
import socket
import logging
logging.basicConfig(level=logging.DEBUG)
def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置非阻塞 IO , 但是这样 还是需要 不停地询问链接是否建立好,需要while 循环不停地去检查状态,
# 做计算任务或者再次发起其他的连接请求,如果接下来的跟连接是否建立好没有关系,那么这种非阻塞很好
client.setblocking(False)
try:
client.connect((host, 80))
except BlockingIOError:
pass
while True:
try:
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path,host).encode('utf8'))
break
except OSError as os_err:
continue
d = b""
while True:
try:
data = client.recv(1024)
if not data:
break
d += data
break
except BaseException as baseEx:
continue
logging.info('\n'+d.decode('utf-8'))
client.close()
if __name__ == '__main__':
get_url("http://www.baidu.com")
非阻塞 socket ,采用 select poll epoll 方式 读取操作
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
from urllib.parse import urlparse
import re
import socket
import logging
logging.basicConfig(level=logging.DEBUG)
from selectors import DefaultSelector, EVENT_WRITE,EVENT_READ
selector = DefaultSelector()
urls = ["http://www.baidu.com"]
STOP = False
class Fetcher:
def get_url(self,url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
if self.path == "":
self.path = "/"
self.data = b""
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置非阻塞 IO , 但是这样 还是需要 不停地询问链接是否建立好,需要while 循环不停地去检查状态,
# 做计算任务或者再次发起其他的连接请求,如果接下来的跟连接是否建立好没有关系,那么这种非阻塞很好
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except BlockingIOError:
pass
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
def connected(self,key):
selector.unregister(key.fd)
self.client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(self.path,self.host).encode('utf8'))
selector.register(self.client.fileno(), EVENT_READ, self.readable)
# 注册
def readable(self,key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode('utf8')
html_data = re.split(r'\r\n\r\n',data)[1]
logging.info(html_data)
self.client.close()
urls.remove(self.spider_url)
global STOP
if not urls:
STOP = True
def loop():
# 时间循环, 不停地请求 socket 的状态 并调用对应的回调函数
#1. select 本身不支持 register 模式, selector 提供注册
#2. socket 状态变化以后的 回调 是 由程序员完成的
while not STOP:
ready = selector.select()
for key, mask in ready:
call_back = key.data
call_back(key)
# 回调+ 时间循环+select(pool\epoll)
if __name__ == '__main__':
fetcher = Fetcher()
fetcher.get_url("http://www.baidu.com")
loop()
import socket
from selectors import (DefaultSelector
,EVENT_WRITE
,EVENT_READ)
from urllib.parse import urlparse
import logging
logging.basicConfig(level=logging.DEBUG)
selector = DefaultSelector()
urls = ["http:/www.baidu.com"]
STOP = False
class Fetcher:
"""
事件循环 + SELECT (状态查询) + 回调
"""
def get_url(self, url):
self._spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b""
if self.path=="":
self.path = "/"
self.client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except BlockingIOError:
pass
# 注册 连上后的 回调操作 , 因为 Send 是 写操作说以是 EVENT_WRITE
selector.register(self.client.fileno(),EVENT_WRITE,self.connected)
def connected(self,key):
"""
:param key: key.data ==> callback
:return:
"""
# 先移除回调
selector.unregister(key.fd)
logging.info("GET {path} HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n".format(path=self.path,host=self.host))
self.client.send("GET {path} HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n".format(path=self.path,host=self.host).encode('utf-8'))
# 准备接受服务器端数据,所以是 EVENT_READ 事件
selector.register(self.client.fileno(),EVENT_READ,self.readable)
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode('utf8')
html_data = data.split(r'\r\n\r\n')[1]
logging.info('\n'+html_data)
self.client.close()
urls.remove(self._spider_url)
if not urls:
STOP = True
def loop():
while not STOP:
ready = selector.select()
for key, mask in ready:
callback = key.data
callback(key)
if __name__ == '__main__':
fetcher = Fetcher()
fetcher.get_url("http:/www.baidu.com")
loop()


调用方 委托生成器 子生成器
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import requests
import json
import pprint
url_html = {}
def sub_gene(url):
while True:
url = yield
if not url:
break
response = requests.get(url)
code = response.encoding
html = response.content.decode(code)
return html[0:20] # 为了便于观看,这里就只返回前20个字符
def delegate_gene(url):
while True:
url_html[url] = yield from sub_gene(url)
def main(urls):
for url in urls:
print(url)
dele_g = delegate_gene(url)
dele_g.send(None) #预激 委托生成器
dele_g.send(url) # 直接将 url 通过 建立好的通道传给子生成器
dele_g.send(None) # 向子生成器发送 None 结束任务
if __name__ == '__main__':
urls = ['http://www.baidu.com','http://www.sina.com']
main(urls)
pprint.pprint(url_html)
异步 IO 启程
import asyncio
import logging
import time
from functools import wraps
logging.basicConfig(level=logging.DEBUG)
async def async_func(url):
await asyncio.sleep(2)
return 'url content: {}'.format(url)
async def get_url(url):
logging.debug('start to fetch html from: {}'.format(url))
result = await async_func(url)
logging.debug('finished fetch html from: {}'.format(url))
return result
def time_count(func):
@wraps(func)
def wrapper_func(*args,**kwargs):
start_time = time.time()
result = func(*args,**kwargs)
logging.debug('{} cost {:.2f} s'.format(func.__name__,time.time()-start_time))
return result
return wrapper_func
@time_count
def main():
# 获得事件循环
event_loop = asyncio.get_event_loop()
task1 = event_loop.create_task(get_url('https://www.baidu.com'))
event_loop.run_until_complete(task1)
logging.debug(task1.result())
if __name__ == '__main__':
main()
如果遇到 IO 阻塞耗费时间的,但又必须放入协程的,那么 可以使用如下 包装 task 为 协程 task
import asyncio
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urlparse
import socket
import logging
logging.basicConfig(level=logging.DEBUG)
def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if not path:
path = '/'
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80))
client.send('GET {path} HTTP/1.1\r\nHost: {host}\r\nConnection:close\r\n\r\n'.format(host=host,path=path).encode('utf-8'))
d = b''
while True:
data = client.recv(1024)
if not data:
break
d += data
logging.debug('\n')
logging.debug(d.decode())
if __name__ == '__main__':
loop = asyncio.get_event_loop()
executor = ThreadPoolExecutor(3)
tasks = []
for i in range(20):
url = 'http://shop.projectsedu.com/goods/{}/'.format(i)
task = loop.run_in_executor(executor, get_url, url)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
神奇的代码
def my_dict2obj(d=None):
if not isinstance(d,dict):
raise TypeError('only dict supported...')
class obj:
def __init__(self,d=None):
self.d = d
for key, value in d.items():
if isinstance(value,(tuple,list)):
setattr(self,key,[obj(i) if isinstance(i,dict) else i for i in value])
else:
setattr(self,key,obj(value) if isinstance(value, dict) else value)
# def __str__(self):
# return '{}'.format(self.d)
# __repr__ = __str__
return obj(d)
if __name__ == '__main__':
d = {'a': 1, 'b': {'c': 2}, 'd': ["hi", {'foo': "bar"}]}
x = my_dict2obj(d)
print(x.__dict__)
# 拆箱,解包
*p, q = d.items()
print(p)
print(q)
digital_dict = {'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}
from functools import reduce
def str2int(s):
return reduce(lambda x,y:x*10+y,map(lambda x:digital_dict.get(x),s))
str2int('13579')
from functools import reduce
import json
def constructDigitalDict(n=10):
digital_List = []
for i in range(n):
digital_List.append('"'+str(i)+'":'+str(i))
result = '{'+','.join(digital_List)+'}'
return json.loads(result)
str2int = lambda s:reduce(lambda x,y:x*10+y,map(lambda c:constructDigitalDict().get(c),s))
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
def _not_divisible(n):
return lambda x: x % n > 0
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
# 打印1000以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
break
def _odd_iter3():
n = 3
while True:
yield n
n+=2
def _not_divisible_3(n):
return lambda x:x%n>0
def prime_iter3():
yield 2
it = _odd_iter()
while True:
base_num = next(it)
yield base_num
it = filter(lambda x,y=base_num:x%y>0,it)
for i in prime_iter3():
if i>50:
break
else:
print(i,end=',')
# -*- coding: utf-8 -*-
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_score(x):
return x[1]
def by_name(x):
return x[0]
sorted(L,key=by_score,reverse=True)
sorted(L,key=by_name,reverse=True)
def createCounter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
def createCounter():
def f():
n=1
while True:
yield n
n +=1
g=f()
def counter():
return next(g)
return counter
# 测试:
counterA = createCounter()
print(counterA(), counterA(), counterA(), counterA(), counterA()) # 1 2 3 4 5
counterB = createCounter()
if [counterB(), counterB(), counterB(), counterB()] == [1, 2, 3, 4]:
print('测试通过!')
else:
print('测试失败!')
def createCounter():
x = 0
def counter():
nonlocal x
x += 1
return x
return counter
from collections import Counter
Counter(s=3, c=2, e=1, u=1)
Counter({'s': 3, 'c': 2, 'u': 1, 'e': 1})
some_data=('c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd')
Counter(some_data).most_common(2)
[('d', 3), ('c', 2)]
some_data=['c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd']
Counter(some_data).most_common(2)
[('d', 3), ('c', 2)]
some_data={'c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd'}
Counter(some_data).most_common(2)
[('c', 1), (3, 1)]
# 测试 list 与 dict 查找效率
import random
def random_line(cols):
alphabet_list = [chr(i) for i in range(65, 91, 1)] + [chr(i) for i in range(97, 123, 1)]
# for i in range(cols):
# yield random.choice(alphabet_list)
return (random.choice(alphabet_list) for i in range(cols))
def randome_generate_file(file_path='./sample.csv',lines=10000,cols=1000):
with open(file_path,'w') as fw:
for i in range(lines):
fw.write(','.join(random_line(cols)))
fw.write('\n')
fw.flush()
def load_list_data(file_path='./sample.csv',total_num=10000,target_num=1000):
all_data = []
target_data = []
with open(file_path,'r') as fr:
for count, line in enumerate(fr):
if count > total_num:
break
else:
all_data.append(line)
while len(target_data)<=target_num:
index = random.randint(0,total_num)
if all_data[index] not in target_data:
target_data.append(all_data[index])
return all_data, target_data
def load_dict_data(file_path='./sample.csv',total_num=10000,target_num=1000):
all_data = {}
target_data = []
with open(file_path,encoding='utf8',mode='r') as fr:
for idx, line in enumerate(fr):
if idx>total_num:
break
all_data[line]=0
all_data_list = list(all_data)
while len(target_data)<=target_num:
random_index = random.randint(0,total_num)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
return all_data, target_data
def find_test(all_data,target_data):
test_times = 100
total_times_cnt = 0
import time
for t in range(test_times):
start = time.time()
for item in target_data:
if item in all_data:
pass
cost_once = time.time() - start
total_times_cnt+= cost_once
return total_times_cnt / test_times
if __name__ == '__main__':
# randome_generate_file()
# all_data, target_data = load_list_data()
all_data, target_data = load_dict_data()
last_time = find_test(all_data,target_data)
print(last_time)
def my_hex(num):
alpha_list = ['A', 'B', 'C', 'D', 'E', 'F']
hex_list = []
while True:
mod_, num = num%16, num//16
hex_list.append(alpha_list[mod_-10] if mod_>9 else mod_)
if num==0:
break
hex_list.append('0x')
hex_list.reverse()
return ''.join(map(lambda x:str(x) if not isinstance(x,str) else x,hex_list))
def my_octonary(num):
octonary_list = []
while True:
mod_, num = num%8, num//8
octonary_list.append(str(mod_))
if num==0:
break
octonary_list.append('0o')
octonary_list.reverse()
return ''.join(octonary_list)
print(hex(60))
print(my_hex(60))
print(oct(9))
print(my_octonary(9))
def fac(n,res):
if n==1:
return res
else:
return fac(n-1,n*res)
print(fac(6,1))
d = {'a': 1, 'b': {'c': 2}, 'd': ["hi", {'foo': "bar"}]}
def my_dict2obj(args):
class obj(object):
def __init__(self,d):
for key,value in d.items():
if not isinstance(value,(list,tuple)):
setattr(self,key,obj(value) if isinstance(value,dict) else value)
else:
setattr(self,key,[obj(i) if isinstance(i,dict) else i for i in value])
return obj(args)
x = my_dict2obj(d)
print(x.__dict__)
words = ['apple','bat','bar','atom','book']
alpha_dict = {}
for word in words:
word_list = []
if word[0] not in alpha_dict:
word_list.append(word)
alpha_dict[word[0]] = word_list
else:
alpha_dict[word[0]].append(word)
print(alpha_dict)
from collections import namedtuple
stock_list = [['AAPL','10.30','11.90'],['YAHO','9.23','8.19'],['SINA','22.80','25.80']]
stock_info = namedtuple('stock_info',['name','start','end'])
stock_list_2 = [stock_info(name,start,end) for name,start,end in stock_list ]
print(stock_list_2)
from collections import namedtuple
Card = namedtuple('Card',['suit','rank'])
class French_Deck():
rank = [i for i in range(2,11,1)]+['J','Q','K','A']
suit = 'Spade,Club,Heart,Diamond'.split(r',')
def __init__(self):
self._card = [Card(s,r) for r in French_Deck.rank for s in French_Deck.suit]
def __getitem__(self, item):
if isinstance(item,int):
return self._card[item]
elif isinstance(item,slice):
return self._card[item]
def __len__(self):
return len(self._card)
frenck_deck = French_Deck()
print(frenck_deck[1:3])
强大的 dataframe
# -*- coding: utf-8 -*-
from pandas import DataFrame
import numpy as np
def test():
df = DataFrame(np.arange(12).reshape(3,4),columns=['col1','col2','col3','col4'])
return df
if __name__ == '__main__':
df = test()
df.iloc[0:1,0:1] = None
print(df)
df.dropna(axis=0,how='all',subset=['col1'],inplace=True) # col for col in df.columns if col.startswith('col')
print(df)
gene_cols_tmp = [col for col in df.columns if col.startswith('gene_')]
for col in gene_cols_tmp:
df[col]=df.apply(lambda x: None if x==0 else x, axis=1)
df['zero_count'] = df.apply(lambda x:x.value_counts().get(0,0),axis=1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号