
待整理
青出于蓝的 requests >> urllib
Pillow(新) PIL(2.7 远古时代)
psutils <== process and system utilities
import chardet
from contextlib import contextmanager,closing
reload(sys)
sys.setdefaultencoding("utf-8")
在Python 3.x中不好使了 提示 name ‘reload’ is not defined
在3.x中已经被毙掉了被替换为
import importlib
importlib.reload(sys)
pylint
pyflakes
pysonar2
Fabric
import traceback
sys.argv与optparse与argparse与getopt
谷歌的 fire 模块
import dis 分析函数过程等...
代码统计 cloc
excel 读写 pandas + xlrd , xlsxwriter
lxml
shutil
f-string
P=NP?
import inspect
def a(a, b=0, *c, d, e=1, **f):
pass
aa = inspect.signature(a)
print("inspect.signature(fn)是:%s" % aa)
print("inspect.signature(fn)的类型:%s" % (type(aa)))
print("\n")
bb = aa.parameters
print("signature.paramerters属性是:%s" % bb)
print("ignature.paramerters属性的类型是%s" % type(bb))
print("\n")
for cc, dd in bb.items():
print("mappingproxy.items()返回的两个值分别是:%s和%s" % (cc, dd))
print("mappingproxy.items()返回的两个值的类型分别是:%s和%s" % (type(cc), type(dd)))
print("\n")
ee = dd.kind
print("Parameter.kind属性是:%s" % ee)
print("Parameter.kind属性的类型是:%s" % type(ee))
print("\n")
gg = dd.default
print("Parameter.default的值是: %s" % gg)
print("Parameter.default的属性是: %s" % type(gg))
print("\n")
ff = inspect.Parameter.KEYWORD_ONLY
print("inspect.Parameter.KEYWORD_ONLY的值是:%s" % ff)
print("inspect.Parameter.KEYWORD_ONLY的类型是:%s" % type(ff))
import inspect
def func_a(arg_a, *args, arg_b='hello', **kwargs):
print(arg_a, arg_b, args, kwargs)
class Fib:
def __init__(self,n):
a, b = 0, 1
i = 0
self.fib_list = []
while i<n:
self.fib_list.append(a)
a, b = b, a+b
i+=1
def __getitem__(self, item):
return self.fib_list[item]
if __name__ == '__main__':
fib = Fib(5)
print(fib[0:3])
# 获取函数签名
func_signature = inspect.signature(func_a)
func_args = []
# 获取函数所有参数
for k, v in func_signature.parameters.items():
# 获取函数参数后,需要判断参数类型
# 当kind为 POSITIONAL_OR_KEYWORD,说明在这个参数之前没有任何类似*args的参数,那这个函数可以通过参数位置或者参数关键字进行调用
# 这两种参数要另外做判断
if str(v.kind) in ('POSITIONAL_OR_KEYWORD', 'KEYWORD_ONLY'):
# 通过v.default可以获取到参数的默认值
# 如果参数没有默认值,则default的值为:class inspect_empty
# 所以通过v.default的__name__ 来判断是不是_empty 如果是_empty代表没有默认值
# 同时,因为类本身是type类的实例,所以使用isinstance判断是不是type类的实例
if isinstance(v.default, type) and v.default.__name__ == '_empty':
func_args.append({k: None})
else:
func_args.append({k: v.default})
# 当kind为 VAR_POSITIONAL时,说明参数是类似*args
elif str(v.kind) == 'VAR_POSITIONAL':
args_list = []
func_args.append(args_list)
# 当kind为 VAR_KEYWORD时,说明参数是类似**kwargs
elif str(v.kind) == 'VAR_KEYWORD':
args_dict = {}
func_args.append(args_dict)
print(func_args)
from collections import defaultdict
import logging
logging.basicConfig(level=logging.DEBUG)
def group_by_firstletter(words=None):
word_dict = {}
for word in words:
first_letter = word[0]
if first_letter in word_dict:
word_dict[first_letter] += 1
else:
word_dict[first_letter] = 1
return word_dict
def group_by_firstletter2(words=None):
default_word_dict = defaultdict(int)
for word in words:
default_word_dict[word[0]]+=1
return default_word_dict
def group_by_firstletter3(words=None):
words_dict = {}
for word in words:
if word[0] in words_dict:
words_dict[word[0]].append(word)
else:
words_dict[word[0]] = [word]
return words_dict
def group_by_firstletter4(words=None):
default_word_dict = defaultdict(list)
for word in words:
default_word_dict[word[0]].append(word)
return default_word_dict
if __name__ == '__main__':
words = ['apple', 'bat', 'bar', 'atom', 'book']
logging.info(group_by_firstletter(words))
logging.info(group_by_firstletter2(words))
logging.info(group_by_firstletter3(words))
logging.info(group_by_firstletter4(words))
from collections import Iterator, Iterable
from collections import defaultdict
from collections import Counter, ChainMap, OrderedDict, namedtuple, deque
from itertools import islice # 替代 切片,但是只能 是正数
from itertools import zip_longest # 替代 zip 可以 对不一样个数的 进行迭代
from concurrent.futures import ThreadPoolExecutor as Pool
from collections import namedtuple, deque, defaultdict, OrderedDict, ChainMap, Counter
Point = namedtuple('Poing',['x','y','z'])
p = Point(1,2,3)
print(p.x,'--',p.y,'--',p.z)
# 双向列表
dq = deque([1,2,3,4])
dq.append(5)
dq.appendleft('a')
dq.popleft()
default_dict = defaultdict(lambda:'N/A') # 多了一个默认值
default_dict['name']='frank'
default_dict['age']
od = OrderedDict([('b',1),('a',2),('c',3)]) # 按照插入的顺序有序
od.get('a')
# 可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print('remove:', last)
if containsKey:
del self[key]
print('set:', (key, value))
else:
print('add:', (key, value))
OrderedDict.__setitem__(self, key, value)
# 应用场景 设置参数优先级
from collections import ChainMap
import os, argparse
# 构造缺省参数:
defaults = {
'color': 'red',
'user': 'guest'
}
# 构造命令行参数:
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = { k: v for k, v in vars(namespace).items() if v }
# 组合成ChainMap:
combined = ChainMap(command_line_args, os.environ, defaults)
# 打印参数:
print('color=%s' % combined['color'])
print('user=%s' % combined['user'])
# itertools
from itertools import count, repeat, cycle, chain, takewhile, groupby
def times_count(base,n):
for x in count(base):
if n<=0:
break
yield str(x)
n-=1
def times_repeat(s,n):
return '-'.join(repeat(s,n))
def times_cycle(s,n):
for v in cycle(s):
if n<= 0:
break
yield s
n-=1
if __name__ == '__main__':
print(times_repeat('*',3))
for s in times_cycle('ABC',3):
print(s)
r = ','.join(chain('ABC', 'XYZ'))
print(r)
print(','.join(times_count(5,3)))
print(','.join( takewhile(lambda x:int(x)<10, times_count(1,30))))
group_dict = {key:list(group) for key, group in groupby(['abort','abandon','book','cook','bird'], lambda ch: ch[0].upper())}
print(group_dict)
# -*- coding: utf-8 -*-
import itertools
from functools import reduce
def pi(N):
' 计算pi的值 '
# step 1: 创建一个奇数序列: 1, 3, 5, 7, 9, ...
odd_iter = itertools.count(1, 2)
# step 2: 取该序列的前N项: 1, 3, 5, 7, 9, ..., 2*N-1.
odd_head = itertools.takewhile(lambda n: n <= 2 * N - 1, odd_iter)
# print(list(odd_head),end=',')
# step 3: 添加正负符号并用4除: 4/1, -4/3, 4/5, -4/7, 4/9, ...
odd_final = [4 / n * ((-1) ** i) for i, n in enumerate(odd_head)]
# step 4: 求和:
value = reduce(lambda x, y: x + y, odd_final)
return value
# 测试:
print(pi(10))
print(pi(100))
print(pi(1000))
print(pi(10000))
assert 3.04 < pi(10) < 3.05
assert 3.13 < pi(100) < 3.14
assert 3.140 < pi(1000) < 3.141
assert 3.1414 < pi(10000) < 3.1415
print('ok')
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server.bind(('127.0.0.1',6666))
clients = set()
print('server bind 127.0.0.1:6666...')
while 1:
try:
data,addr = server.recvfrom(1024)
clients.add(addr)
if not data or data.decode('utf-8')=='pong':
continue
print('%s:%s >>> %s' % (addr[0],addr[1],data.decode('utf-8')))
for usr in clients:
if usr!=addr:
server.sendto(('%s:%s >>> %s' % (addr[0],addr[1],data.decode('utf-8'))).encode('utf-8'),usr)
except Exception as e:
pass
########################################################
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import socket,threading,os
client = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
client.sendto(b'pong',('127.0.0.1',6666))
def myinput():
while 1:
try:
msg = input('>>>')
yield msg
except Exception as e:
os._exit(0)
def getMsg(client):
while 1:
try:
r = client.recv(1024)
print('\n',r.decode('utf-8'),'\n>>>',end='')
except Exception as e:
pass
c = myinput()
def sendMsg(msg):
while 1:
msg = next(c)
client.sendto(msg.encode('utf-8'),('127.0.0.1',6666))
threading.Thread(target=sendMsg,args=(client,)).start()
threading.Thread(target=getMsg,args=(client,)).start()
def my_dict2obj(d=None):
if not isinstance(d,dict):
raise TypeError('only dict supported...')
class obj:
def __init__(self,d=None):
self.d = d
for key, value in d.items():
if isinstance(value,(tuple,list)):
setattr(self,key,[obj(i) if isinstance(i,dict) else i for i in value])
else:
setattr(self,key,obj(value) if isinstance(value, dict) else value)
# def __str__(self):
# return '{}'.format(self.d)
# __repr__ = __str__
return obj(d)
if __name__ == '__main__':
d = {'a': 1, 'b': {'c': 2}, 'd': ["hi", {'foo': "bar"}]}
x = my_dict2obj(d)
print(x.__dict__)
# 拆箱,解包
*p, q = d.items()
print(p)
print(q)
from html.parser import HTMLParser
from html.entities import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print('<%s>' % tag)
def handle_endtag(self, tag):
print('</%s>' % tag)
def handle_startendtag(self, tag, attrs):
print('<%s/>' % tag)
def handle_data(self, data):
print(data)
def handle_comment(self, data):
print('<!--', data, '-->')
def handle_entityref(self, name):
print('&%s;' % name)
def handle_charref(self, name):
print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('''<html>
<head></head>
<body>
<!-- test html parser -->
<p>Some <a href=\"#\">html</a> HTML tutorial...<br>END</p>
</body></html>''')
import lxml
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def start_element(self, name, attrs):
print('sax:start_element: %s, attrs: %s' % (name, str(attrs)))
def end_element(self, name):
print('sax:end_element: %s' % name)
def char_data(self, text):
print('sax:char_data: %s' % text)
xml = r'''<?xml version="1.0"?>
<ol>
<li><a href="/python">Python</a></li>
<li><a href="/ruby">Ruby</a></li>
</ol>
'''
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
# datetime
from datetime import datetime,timedelta
now = datetime.now()
# datetime 转 timestamp
now_timestamp = now.timestamp()
# timestampe 转本地 datetime
dt_local = datetime.fromtimestamp(now_timestamp)
# timestampe 转utc datetime
dt_utc = datetime.utcfromtimestamp(now_timestamp)
# 时间戳 没有时区, datetime中携带
print(dt_local.timestamp(),'<-->',dt_utc.timestamp())
print('{}\n{}\n{}\n{}'.format(now,now_timestamp,dt_local,dt_utc))
# 获取指定 日期和时间
year = 2019
month =3
day =3
hour = 15
minute = 7
dt_specified = datetime(year,month,day,hour,minute)
print(dt_specified)
# str 转 datetime str parse
datetime_str = '2019-03-03 15:22:00'
datetime_parse_format = '%Y-%m-%d %H:%M:%S'
cday = datetime.strptime(datetime_str,datetime_parse_format)
print(cday)
# datetime 转 str str format
print(cday.strftime('%Y/%m/%d'))
# 日期变化(delta) 用 timedelta
now = datetime.now()
now_next3_hours = now+timedelta(hours=3)
now_previous3_days = now+timedelta(days=-3)
print('next 3 hours: {}'.format(now_next3_hours))
print('now_previous3_days: {}'.format(now_previous3_days))
from datetime import timezone
tz_utc_8 = timezone(timedelta(hours=8))
now = datetime.now()
# 一开始 now 时区信息为 None
print(now.tzinfo)
# 暴力设置一个时区
now.replace(tzinfo=tz_utc_8)
print(now)
utc_now = datetime.utcnow()
# 一开始这玩意儿压根木有时区信息啊
print(utc_now.tzinfo)
# 暴力设置时区信息
utc_now = utc_now.replace(tzinfo=timezone.utc)
#北京日期时间 东八区
bj_dt = utc_now.astimezone(timezone(timedelta(hours=8)))
# 西八区
pst_dt = utc_now.astimezone(timezone(timedelta(hours=-8)))
# 东 9 区
tokyo_dt = utc_now.astimezone(timezone(timedelta(hours=9)))
print('bj_dt: ',bj_dt)
print('pst_dt: ',pst_dt)
print('tokyo_dt: ',tokyo_dt)
from datetime import datetime, timezone,timedelta
import re
def to_timestamp(dt_str,tz_str):
re_dt_str_1 = r'\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}'
re_tz_str = r'^UTC([+-])(\d{1,2}):\d{2}$'
tz_grps = re.match(re_tz_str,tz_str).groups()
sign = tz_grps[0]
hours = int(tz_grps[1])
if re.match(re_dt_str_1,dt_str):
dt = datetime.strptime(dt_str,'%Y-%m-%d %H:%M:%S')
if sign=='+':
tz_info_x = timezone(timedelta(hours=hours))
else:
tz_info_x = timezone(timedelta(hours=-hours))
dt = dt.replace(tzinfo=tz_info_x)
else:
print('re is wrong!')
return dt.timestamp()
# 测试:
t1 = to_timestamp('2015-6-1 08:10:30', 'UTC+7:00')
assert t1 == 1433121030.0, t1
t2 = to_timestamp('2015-5-31 16:10:30', 'UTC-09:00')
assert t2 == 1433121030.0, t2
print('ok')
digital_dict = {'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}
from functools import reduce
def str2int(s):
return reduce(lambda x,y:x*10+y,map(lambda x:digital_dict.get(x),s))
str2int('13579')
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
def _not_divisible(n):
return lambda x: x % n > 0
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
# 打印1000以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
break
def _odd_iter3():
n = 3
while True:
yield n
n+=2
def _not_divisible_3(n):
return lambda x:x%n>0
def prime_iter3():
yield 2
it = _odd_iter()
while True:
base_num = next(it)
yield base_num
it = filter(lambda x,y=base_num:x%y>0,it)
for i in prime_iter3():
if i>50:
break
else:
print(i,end=',')
# -*- coding: utf-8 -*-
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_score(x):
return x[1]
def by_name(x):
return x[0]
sorted(L,key=by_score,reverse=True)
sorted(L,key=by_name,reverse=True)
def createCounter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
def createCounter():
def f():
n=1
while True:
yield n
n +=1
g=f()
def counter():
return next(g)
return counter
# 测试:
counterA = createCounter()
print(counterA(), counterA(), counterA(), counterA(), counterA()) # 1 2 3 4 5
counterB = createCounter()
if [counterB(), counterB(), counterB(), counterB()] == [1, 2, 3, 4]:
print('测试通过!')
else:
print('测试失败!')
def createCounter():
x = 0
def counter():
nonlocal x
x += 1
return x
return counter
from collections import Counter
Counter(s=3, c=2, e=1, u=1)
Counter({'s': 3, 'c': 2, 'u': 1, 'e': 1})
some_data=('c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd')
Counter(some_data).most_common(2)
[('d', 3), ('c', 2)]
some_data=['c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd']
Counter(some_data).most_common(2)
[('d', 3), ('c', 2)]
some_data={'c', '2', 2, 3, 5, 'c', 'd', 4, 5, 'd', 'd'}
Counter(some_data).most_common(2)
[('c', 1), (3, 1)]
# 事实证明,所有序列操作都应该会先走特定的魔法函数,然后实在没有转入 __getitem__
from collections.abc import Iterable, Iterator
from types import GeneratorType
from contextlib import contextmanager
class Company:
def __init__(self,employee_list):
self.employee_list = employee_list
# 序列相关
def __getitem__(self, item):
print('getitem executed...')
cls = type(self)
if isinstance(item,slice):
return cls(self.employee_list[item])
elif isinstance(item,int):
return cls([self.employee_list[item]])
def __setitem__(self, key, value):
self.employee_list[key] = value
def __delitem__(self, key):
del self.employee_list[key]
def __len__(self):
print('len executed...')
return len(self.employee_list)
def __contains__(self, item):
print('contains executed...')
return item in self.employee_list
# 迭代相关
# 实现了 __iter__ 仅仅是刻碟带对象 (Iterable)
def __iter__(self):
print('iter executed...')
return iter(self.employee_list)
# 实现 __next__ 仅仅只是迭代器(Iterator)不是生成器
def __next__(self):
print('next executed...')
pass
# 可调用
def __call__(self, *args, **kwargs):
print('__call__ executed...')
pass
# 上下文管理
def __enter__(self):
# self.fp = open('xxx')
print('__enter__ executed...')
pass
def __exit__(self, exc_type, exc_val, exc_tb):
print('__exit__ executed...')
pass
# 释放资源等操作 self.fp.close()
@contextmanager
def Resource(self):
self.fp = open('./sample.csv')
yield self.fp
self.fp.close()
def __repr__(self):
return ','.join(self.employee_list)
__str__ = __repr__
if __name__ == '__main__':
company = Company(['Frank','Tom','May'])
company()
for employee in company:
print(employee)
print(company[1:])
print(isinstance(company,Iterable))
print(isinstance(company,Iterator))
print(isinstance(company,GeneratorType))
print(isinstance((employee for employee in company),GeneratorType))
print(len(company))
print('Jim' in company)
class MyVector(object):
def __init__(self,x,y):
self.x = x
self.y = y
def __add__(self, other):
cls = type(self)
return cls(self.x+other.x, self.y+other.y)
def __repr__(self):
return '({},{})'.format(self.x,self.y)
def __str__(self):
return self.__repr__()
if __name__ == '__main__':
vector1 = MyVector(1,2)
vector2 = MyVector(2,3)
assert str(vector1+vector2) == '(3,5)'
assert (vector1+vector2).__repr__() == '(3,5)'
import abc
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod
def set(self,key):
pass
@abc.abstractmethod
def get(self,value):
pass
class RedisCache(CacheBase):
pass
# 实际用抽象基类不多,更多的是用的 mixin 做法 鸭子类型,可以参考 Django restfulAPI framework
if __name__ == '__main__':
redis_cache = RedisCache() # TypeError: Can't instantiate abstract class RedisCache with abstract methods get, set
from collections import namedtuple,defaultdict,deque,Counter,OrderedDict,ChainMap
# named_tuple
def test():
User = namedtuple('User',['name','age','height','edu'])
user_tuple = ('Frank',18,180,'master')
user_dict = dict(name='Tom',age=20,height=175,edu='PHD')
user = User._make(user_tuple)
user = User._make(user_dict)
print(','.join(map(lambda x:str(x) if not isinstance(x,str) else x,user)))
ordered_user_dict = user._asdict()
print(ordered_user_dict)
# default dict
def test2():
user_dict = {}
user_list = ['frank','tom','tom','jim','Tom']
for user in user_list:
u = user.lower()
user_dict.setdefault(u,0)
user_dict[u]+=1
# if not u in user_dict:
# user_dict[u] = 1
# else:
# user_dict[u]+=1
print(user_dict)
def gen_default_0():
return 0
def test3():
user_dict = defaultdict(int or gen_default_0 or (lambda :0))
user_list = ['frank','tom','Tom','jim']
for user in user_list:
u = user.lower()
user_dict[u]+=1
print(user_dict)
# deque 线程安全
def test4():
dq = deque(['a','b','c'])
dq.appendleft('1')
print(dq)
dq.extendleft(['e','f','g'])
print(dq)
dq.popleft()
print(dq)
dq.insert(0,'g')
print(dq)
# Counter
def test5():
user_list = ['frank','tom','tom','jim']
user_counter = Counter(user_list)
print(user_counter.most_common(2))
alpha_counter = Counter('abccddadfaefedasdfwewefwfsfsfadadcdffghethethklkijl')
alpha_counter.update('fsfjwefjoe9uefjsljdfljdsoufbadflfmdlmjjdsnvdljflasdj')
print(alpha_counter.most_common(3))
#OrderedDict 只是说按照插入顺序有序。。。!!!
def test6():
ordered_dict = OrderedDict()
ordered_dict['b'] = '2'
ordered_dict['a'] = '1'
ordered_dict['c'] = '3'
# print(ordered_dict.popitem(last=False)) # last=True 从最后一个开始pop 否则从第一个开始
# print(ordered_dict.pop('a')) # 返回 被 pop 掉对应的 value
ordered_dict.move_to_end('b') #将指定 key 的 键值对移到最后位置
print(ordered_dict)
# 将多个 dict 串成链 车珠子。。。
def test7():
user_dict_1 = dict(a=1,b=2)
user_dict_2 = dict(b=3,c=5) # 两个出现同样key,采取第一次出现的value
chain_map = ChainMap(user_dict_1,user_dict_2)
new_chain_map = chain_map.new_child({'d': 6, 'e': 7, 'f': 8})
for key, value in chain_map.items():
print('{}--->{}'.format(key,value))
print('*'*100)
for key, value in new_chain_map.items():
print('{}--->{}'.format(key,value))
if __name__ == '__main__':
test()
test2()
test3()
test4()
test5()
test6()
test7()
import inspect
def func_a(arg_a, *args, arg_b='hello', **kwargs):
print(arg_a, arg_b, args, kwargs)
if __name__ == '__main__':
# 获取函数签名
func_signature = inspect.signature(func_a)
func_args = []
# 获取函数所有参数
for k, v in func_signature.parameters.items():
# 获取函数参数后,需要判断参数类型
# 当kind为 POSITIONAL_OR_KEYWORD,说明在这个参数之前没有任何类似*args的参数,那这个函数可以通过参数位置或者参数关键字进行调用
# 这两种参数要另外做判断
if str(v.kind) in ('POSITIONAL_OR_KEYWORD', 'KEYWORD_ONLY'):
# 通过v.default可以获取到参数的默认值
# 如果参数没有默认值,则default的值为:class inspect_empty
# 所以通过v.default的__name__ 来判断是不是_empty 如果是_empty代表没有默认值
# 同时,因为类本身是type类的实例,所以使用isinstance判断是不是type类的实例
if isinstance(v.default, type) and v.default.__name__ == '_empty':
func_args.append({k: None})
else:
func_args.append({k: v.default})
# 当kind为 VAR_POSITIONAL时,说明参数是类似*args
elif str(v.kind) == 'VAR_POSITIONAL':
args_list = []
func_args.append(args_list)
# 当kind为 VAR_KEYWORD时,说明参数是类似**kwargs
elif str(v.kind) == 'VAR_KEYWORD':
args_dict = {}
func_args.append(args_dict)
print(func_args)
import random
def random_line(cols):
alphabet_list = [chr(i) for i in range(65, 91, 1)] + [chr(i) for i in range(97, 123, 1)]
# for i in range(cols):
# yield random.choice(alphabet_list)
return (random.choice(alphabet_list) for i in range(cols))
def randome_generate_file(file_path='./sample.csv',lines=10000,cols=1000):
with open(file_path,'w') as fw:
for i in range(lines):
fw.write(','.join(random_line(cols)))
fw.write('\n')
fw.flush()
def load_list_data(file_path='./sample.csv',total_num=10000,target_num=1000):
all_data = []
target_data = []
with open(file_path,'r') as fr:
for count, line in enumerate(fr):
if count > total_num:
break
else:
all_data.append(line)
while len(target_data)<=target_num:
index = random.randint(0,total_num)
if all_data[index] not in target_data:
target_data.append(all_data[index])
return all_data, target_data
def load_dict_data(file_path='./sample.csv',total_num=10000,target_num=1000):
all_data = {}
target_data = []
with open(file_path,encoding='utf8',mode='r') as fr:
for idx, line in enumerate(fr):
if idx>total_num:
break
all_data[line]=0
all_data_list = list(all_data)
while len(target_data)<=target_num:
random_index = random.randint(0,total_num)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
return all_data, target_data
def find_test(all_data,target_data):
test_times = 100
total_times_cnt = 0
import time
for t in range(test_times):
start = time.time()
for item in target_data:
if item in all_data:
pass
cost_once = time.time() - start
total_times_cnt+= cost_once
return total_times_cnt / test_times
if __name__ == '__main__':
# randome_generate_file()
# all_data, target_data = load_list_data()
all_data, target_data = load_dict_data()
last_time = find_test(all_data,target_data)
print(last_time)
# 第一章 一切皆对象
from functools import wraps
import time
def time_decor(func):
@wraps(func)
def wrapper_func(*args,**kw):
start = time.time()
result = func(*args,**kw)
end = time.time()
print('{} cost {:.2f} s '.format(func.__name__,end-start))
return result
return wrapper_func
@time_decor
def ask(name):
print(name)
class Person:
def __init__(self,name):
print('hi, '+name)
my_ask = ask
my_ask('frank')
print(type(my_ask))
person = Person('frank')
print(person)
print('*'*100)
class_list = []
class_list.append(my_ask)
class_list.append(Person)
for item in class_list:
item('tom')
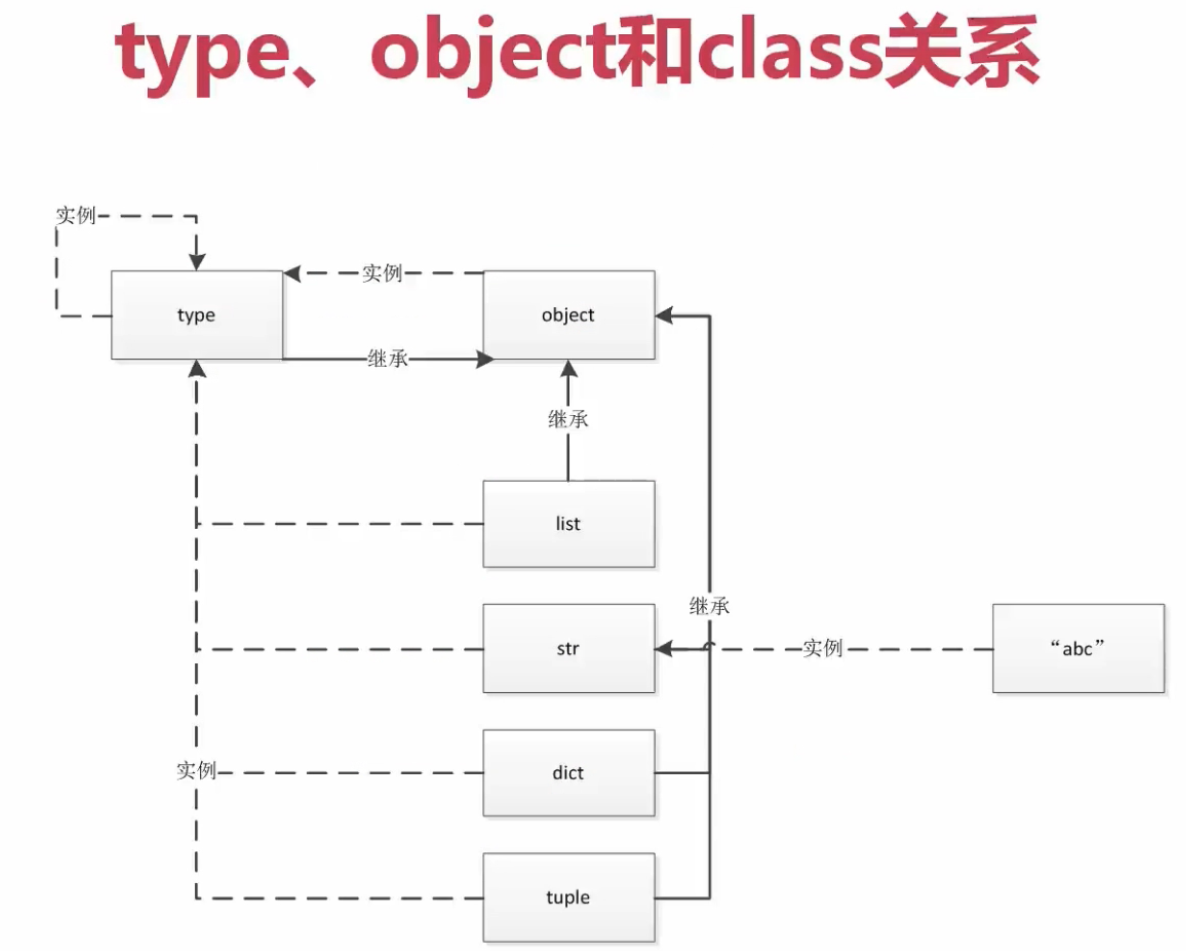
>>> type(type)
<class 'type'>
>>> object.__bases__
()
>>> type.__bases__
(<class 'object'>,)
>>> type(object)
<class 'type'>
type 产生 type 类本身的 实例 产生 object 类, dict 等内建类, class 为万物之始,包括 type(object), class 生 object 只道法自然 str <-- 'abc'
object 是所有对象的 基类包括 type.__bases__, object.__bases__ 之上再无父类
python 是基于协议的编程语言,因其动态语言的特性,也使得python开发效率极高,但同时也会容易产生很多问题,因为一切皆对象包括类本身,很多问题只有在运行时才能检测出来,
而像JAVA 这种静态语言,在编译时候就能够检测出问题,如:类型检测等
第三章 魔法函数
def my_hex(num):
alpha_list = ['A', 'B', 'C', 'D', 'E', 'F']
hex_list = []
while True:
mod_, num = num%16, num//16
hex_list.append(alpha_list[mod_-10] if mod_>9 else mod_)
if num==0:
break
hex_list.append('0x')
hex_list.reverse()
return ''.join(map(lambda x:str(x) if not isinstance(x,str) else x,hex_list))
def my_octonary(num):
octonary_list = []
while True:
mod_, num = num%8, num//8
octonary_list.append(str(mod_))
if num==0:
break
octonary_list.append('0o')
octonary_list.reverse()
return ''.join(octonary_list)
print(hex(60))
print(my_hex(60))
print(oct(9))
print(my_octonary(9))
def fac(n,res):
if n==1:
return res
else:
return fac(n-1,n*res)
print(fac(6,1))
d = {'a': 1, 'b': {'c': 2}, 'd': ["hi", {'foo': "bar"}]}
def my_dict2obj(args):
class obj(object):
def __init__(self,d):
for key,value in d.items():
if not isinstance(value,(list,tuple)):
setattr(self,key,obj(value) if isinstance(value,dict) else value)
else:
setattr(self,key,[obj(i) if isinstance(i,dict) else i for i in value])
return obj(args)
x = my_dict2obj(d)
print(x.__dict__)
words = ['apple','bat','bar','atom','book']
alpha_dict = {}
for word in words:
word_list = []
if word[0] not in alpha_dict:
word_list.append(word)
alpha_dict[word[0]] = word_list
else:
alpha_dict[word[0]].append(word)
print(alpha_dict)
from collections import namedtuple
stock_list = [['AAPL','10.30','11.90'],['YAHO','9.23','8.19'],['SINA','22.80','25.80']]
stock_info = namedtuple('stock_info',['name','start','end'])
stock_list_2 = [stock_info(name,start,end) for name,start,end in stock_list ]
print(stock_list_2)
from collections import namedtuple
Card = namedtuple('Card',['suit','rank'])
class French_Deck():
rank = [i for i in range(2,11,1)]+['J','Q','K','A']
suit = 'Spade,Club,Heart,Diamond'.split(r',')
def __init__(self):
self._card = [Card(s,r) for r in French_Deck.rank for s in French_Deck.suit]
def __getitem__(self, item):
if isinstance(item,int):
return self._card[item]
elif isinstance(item,slice):
return self._card[item]
def __len__(self):
return len(self._card)
frenck_deck = French_Deck()
print(frenck_deck[1:3])
如果有来生,一个人去远行,看不同的风景,感受生命的活力。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号