
python+selenium之XPATH定位
selenium定位元素的方法有很多种,像是通过id、name、class_name、tag_name、link_text等等,但是这些方法局限性太大,拿id属性来说,首先一定不会每个元素都有id属性,其次元素的id属性也不一定是固定不变的。所以这些方法了解一下即可,我们真正需要熟练掌握的是通过xpath和css定位,一般只要掌握一种就可以应对大部分定位工作了。
一、首先需要了解一下xpath的概念和基本语法
网上关于xpath的教程比较少,可以看一下菜鸟教程和w3cschool的相关资料:http://www.runoob.com/xpath/xpath-tutorial.html、http://www.w3school.com.cn/xpath/index.asp


二、常用的xpath定位方法
1.利用标签内的属性进行定位
(1)通过id属性
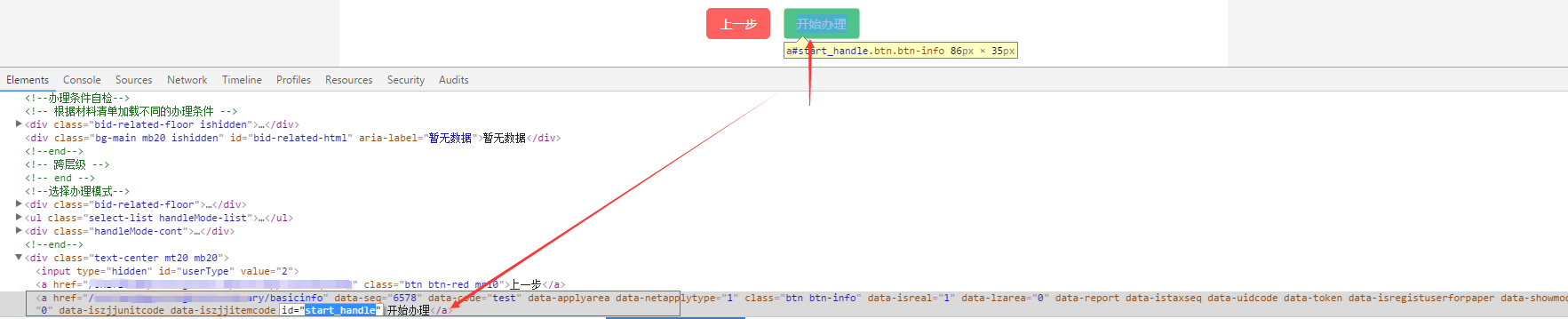
xpath = "//a[@id='start_handle']" //a 表示选取所有a元素,加上[@id='start_handle']表示选取id属性为'start_handle'的a元素
(2)通过name属性定位

xpath = "//input[@name='custName']"或者 xpath = "//*[@name='custName']
概括:
xpath = "//标签名[@属性='属性值']"
属性判断条件:最常见为id,name,class等等,属性的类别没有特殊限制,只要能够唯一标识一个元素即可。
当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,如下:
xpath= "//input[@type='XX' and @name='XX']"
2.利用text()方法定位

如上所示,在【上一步】按钮的<a></a>标签之间有一段文本“上一步”,那么可以通过下面这种方式来定位
xpath = "//a[text()='上一步']"
3.利用contains()方法定位,也叫模糊定位
xpath = "//标签名[contains(@属性, '属性值')]"

取href的关键信息'basicinfo',这样也可以定位到【开始办理】按钮
xpath = "//a[contains(@href, 'basicinfo')]"
4.如果一个元素无法通过自身属性直接定位到,则可以先定位它的父(或父的父,它爷爷)元素,然后再找下一级即可
例如定位百度搜索框,可以按照此种方式试验一下(主要是看一下这个思路)

百度搜索框对应<input>标签,定位<input>标签的话,可以先定位<form>标签,再定位<form>标签的子元素<span>标签,最后找到<input>标签
driver.find_element_by_xpath("//form[@id='form']/span[contains(@class,'s_ipt_wr')]/input").send_keys('python')
注意:在第二步定位<span>元素时,没有用<span>的id属性,因为在实际中发现通过webdriver打开的浏览器网页中<span>标签没有id属性了(所以选用<span>标签的class属性,并且通过contains()模糊定位),如下
总之,XPATH路径表达式需要多写多练,孰能生巧。还有当定位失败时不要慌,找下原因,眼见不一定为实,比如有的标签通过手动定位是/html/body/div[10],但是通过webdriver打开的网页进行定位i时,发现该标签的定位是/html/body/div[12]。

