
pandas 布尔值筛选总结
pandas中对DataFrame筛选数据的方法有很多的,以后会后续进行补充,这里只整理遇到错误的情况。
1.使用布尔型DataFrame对数据进行筛选
使用一个条件对数据进行筛选,代码类似如下:
复制代码
- 1
num_red=flags[flags['red']==1]
使用多个条件对数据进行筛选,代码类似如下:
不同的条件用()包裹起来,并或非分别使用&,|,~而非and,or,not
复制代码
- 1
stripes_or_bars=flags[(flags['stripes']>=1) | (flags['bars']>=1)]
常见的错误代码如下:
代码一:
条件没用(),或没有使用|
复制代码
- 1
stripes_or_bars=flags[flags['stripes']>=1 or flags['bars']>=1]
代码二:
没有使用()
复制代码
- 1
stripes_or_bars=flags[flags['stripes']>=1 | flags['bars']>=1].
代码三:
或没用用|
复制代码
- 1
stripes_or_bars=flags[(flags['stripes']>=1) or (flags['bars']>=1)]
以上这三种代码的错误提示都是:ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all(). 中括号里面的逻辑式如何解析的暂时不清楚。貌似不能使用and、or及not。
除了使用组合的逻辑表达式之外,使用返回类型为布尔型值的函数也可以达到筛选数据的效果。示例如下:
复制代码
- 1
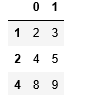
import pandas as pdimport numpy as npdf=pd.DataFrame(np.array(range(10)).reshape((5,-1)))df.columns=['0','1']df=df[df['1'].isin([3,5,9])]
其df的结果如下:
2.iloc()方法和iloc()方法的区别
首先dataframe一般有两种类型的索引:第一种是位置索引,即dataframe自带的从0开始的索引,这种索引叫位置索引。另一种即标签索引,这种索引是你在创建datafram时通过index关键字,或者通过其他index相关方法重新给dataframe设置的索引。这两种索引是同时存在的。一般设置了标签索引之后,就不在显示位置索引,但不意味着位置索引就不存在了。
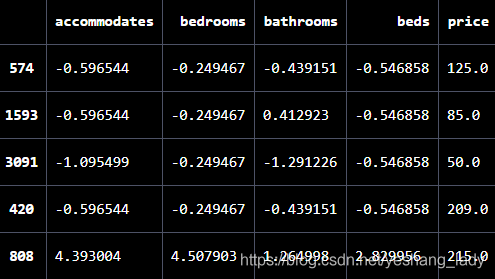
假设有如下几行数据(截图部分只是数据的一部分),很明显,以下显示的索引为标签索引。同时574(标签索引)行对应的位置索引则为0,1593行对应的位置索引为2, 以此类推。
先来看loc(),其API网址http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.htm,函数名下方有一行解释,Access a group of rows and columns by label(s) or a boolean array.. loc[] is primarily label based, but may also be used with a boolean array.
代码一:
复制代码
- 1
first_listing = normalized_listings.loc[[0,4]]
结果如下,可以看出其输出的是dataframe中标签索引为0和4的两行数据。注意,如果标签索引的类型为字符串,则在loc中也要用字符串的形式。

再来看iloc(),其API网址http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html,函数名下方的解释为 Purely integer-location based indexing for selection by position. .iloc[] is primarily integer position based ( from 0 to length-1 of the axis), but may also be used with a boolean array.
代码二:
复制代码
- 1
first_listing = normalized_listings.iloc[[0,4]]
结果如下,可以看出其输出的dataframe中第0行和第4行的数据,即按方法是按照位置索引取得数。注意使用位置索引的时候只能用整数(integer position,bool类型除外)

另外,还可以向loc和iloc中传入bool序列,这样就可以将前面介绍的boo表达式用到loc和iloc中。下面来看看怎么使用bool序列?
复制代码
- 1
- 2
- 3
- 4
- 5
- 6
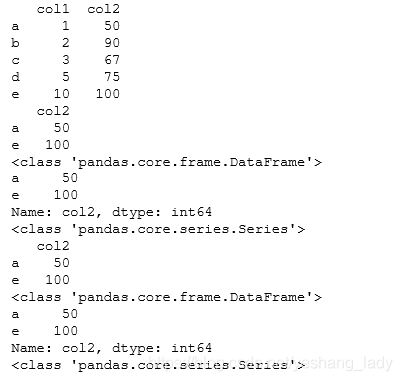
import pandas as pddata=pd.DataFrame(data={'col1':[1,2,3,5,10],'col2':[50,90,67,75,100]},\ index=['a','b','c','d','e'])
print(data)
#iloc[]示例,iloc似乎不能直接使用逻辑表达式的结果,我这里将其转置成list之后就可以用了,原因暂且不明data_1=data.iloc[list(data['col1']>5)]
print(data_1)
#loc[]示例,loc中可以直接使用逻辑表达式data_2=data.loc[data['col1']>5]
print(data_2)
在iloc[]中,如果直接使用loc中的逻辑表达式而不进行list()转化的话,会提示ValueError: iLocation based boolean indexing cannot use an indexable as a mask错误。
如果查看上述两段代码中得到的first_listing。我们会发现两处first_listing的类型均为datafrarm。loc和iloc除了能对行进行筛选,还可以筛选列。如果在loc和iloc中设定了对列的筛选,则筛选之后得到的数据可能是datafrme类型,也有可能是Series类型。下面直接以代码运行结果进行说明。
复制代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
import pandas as pddata=pd.DataFrame(data={'col1':[1,2,3,5,10],'col2':[50,90,67,75,100]},\ index=['a','b','c','d','e'])
print(data)
#iloc[]示例 ,在使用iloc的时候,[]里面无论是筛选行还是筛选列,都只能使用数字形式的行号或列号。#这里如果使用‘col2',这里会报错data_1=data.iloc[[0,4],[1]]#当需要筛选出多列或者希望返回的结果为DataFrame时,可以将列号用[]括起来。
print(data_1)
print(type(data_1))
data_2=data.iloc[[0,4],1]
#当只需要筛选出其中的一列时可以只写一个列号,不加中括号,这种方法得到的是一个Seriesprint(data_2)print(type(data_2))
#loc[]示例
data_3=data.loc[['a','e'],['col2']]
print(data_3)
print(type(data_3))
data_4=data.loc[['a','e'],'col2']
print(data_4)
print(type(data_4))
具体的代码执行结果如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步