word2vector论文笔记
背景
很多当前的NLP系统和技术都把单词像ont-hot一样当做原子性的一个概念去对待,单纯就是一个索引,无法表示词之间的相似性。原因就是往往一个简单的、鲁棒的、可观测的模型在海量数据集上的学习效果要优于一个复杂模型在少量数据集上的学习效果。
然而,基于简单技术的模型有以下缺陷:比如语音识别和机器翻译等NLP任务,获取海量的可用数据是相当困难的,必须从根本上改进技术,使得利用海量的数据进行学习向量表示的成本更低更有效。
这几年基于神经网络的分布式词向量表示学习获得了不错的表现,超越了N-gram模型。
本文目的
介绍一种新的方法,其可以史无前例的在十亿量级的单词量及百万级的词典规模上学习出高质量的词向量表示。
惊喜的是,其不仅可以表示此之间的相似性及此法规则,还可以表达词语之间简单的代数计算,比如:vector(King)-vector(Queen) = vector(Man)-vector(Woman)
本文通过开发新的模型结构尝试最大化以上操作包括词法的准确率。我们设计了一个新的测试集来测量词法和句法、语义的准确性。此外也讨论了训练时间对词向量维度与数据量的依赖。
之前的工作
- NNLM:神经网络语言模型,就是用一个前馈神经网络去学习一段话下一个单词是什么。
![]()

不同模型结构的计算复杂度
NNLM
模型复杂度为:
Q = N*D + N*D*H + H*V
N是输入模型的词序列的长度,即词个数
D是词向量维度
H是隐藏层的节点数
V是词典大小
其中,计算量占大头的是隐藏层到输出层的H*V,词典都比较大,这一层的计算量也很大。为避免昂贵的计算,这一层通常用 hierarchical softmax来做输出,这一层的复杂度可以降低至log2(V)。因此,整个模型的复杂度通常为 N*D*H。
在我们的模型中,使用了霍夫曼二叉树的hierarchical softmax来做输出层,详见霍夫曼二叉树。
RNNLM
模型复杂度
Q = H*H + H*V
H是隐藏层节点数
V是词向量维度
同理,H*V的复杂度可通过hierarchical softmax降低至log2(V), 只要的计算复杂度来源于H*H。
并行训练
在大规模分布式集群进行多机多核并行训练。
New Log-linear Models
以上分析可知,模型复杂度通常集中在非线性隐藏层,下面两个模型在此处做了改进。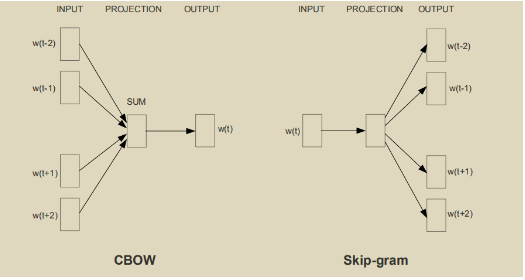
CBOW(Continuous Bag-of-Words Model)
模型结构如上图所示
- 使用
w(t)上下文的词w(t-2),w(t-1),w(t+1),w(t+1)预测当前词w(t)。 - 去掉隐藏层,词序列通过Embedding层得到词向量后求平均,然后接 softmax 输出层。当输入词序打乱后求平均得到的值是一样的,因此本质上是一个词袋模型。
模型复杂度:
Q = N*D +D*log2(V)
Skip-gram
模型结构如上图所示
- 同CBOW相反,skip-gram是用当前的词
w(t)预测它周围的词w(t-2),w(t-1),w(t+1),w(t+1)。 - 离当前词距离越远其与当前词的联系越弱,这里通过不同的采样权重在训练的时候给距离较远的词更小距离较近的词较大的权重。
模型复杂度
Q = C*(D + D*log2(V))
C代表取当前周围词的最大距离,本片文章取C=10。
Tricks
- 霍夫曼编码。
- Negative Sampling。
基本思路就是根据词频分布对不同的词进行采样,当做负样本。
Result
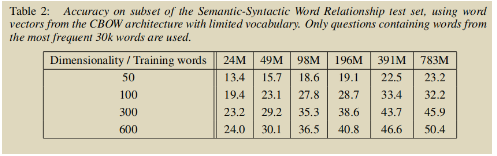
-
作者使用了不同的词向量维度大小以及不同规模的训练数据进行测试,结果显示明细当词向量维度更高、训练数据规模更大的时候,训练出来的词向量具有更高的质量。
![]()
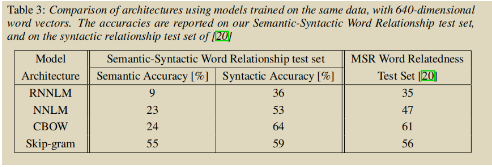
-
作者在相同的训练数据下,同样的词向量维度进行训练。几个不同的模型结构比较如下:
![]()
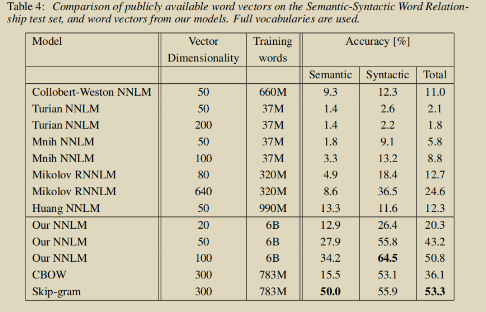
-
比较了不同的模型在不同训练语料、不同词向量维度下的表现:
![]()
-
在大规模语料Google News 6B级别数据上训练的精度和耗时
![]()
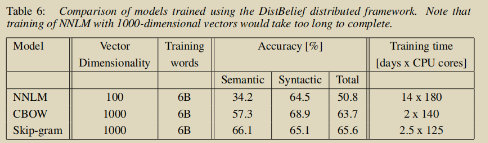
可以看到,在以上实验中,CBOW和skip-gram对以往模型无论是精度还是训练速度上都是碾压姿态。
Examples of the Learned Relationships
通过Paris - France + Italy = Rome这种计算方法来寻找具有某种关系的word pairs。sklip-gram在783M语料、300维词向量的设定上训练的词向量,案例如下,准去率60%左右,相信在更大的语料和更高的词向量维度上可以取得更优异的表现。
Conclusion
构建了两个复杂度更加简单的词向量模型
复杂度简单,得以在更大规模的语料上进行训练,从而训练得到更高质量的词向量。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号