霍夫曼树
参考:https://www.cnblogs.com/pinard/p/7160330.html
word2vector 训练词向量时采用霍夫曼树来代替softmax,这里先看一下什么是霍夫曼树?
过一个案例来学习一棵霍夫曼树是怎么建立起来的
说总共有6个节点(a, b, c, d, e, f, g),节点的权值分布为(20,4,8,6,16,3)。
首先是最小的b和f合并,得到的新树根节点权重是7.此时森林里5棵树,根节点权重分别是20,8,6,16,7。此时根节点权重最小的6,7合并,得到新子树,依次类推,最终得到下面的霍夫曼树。
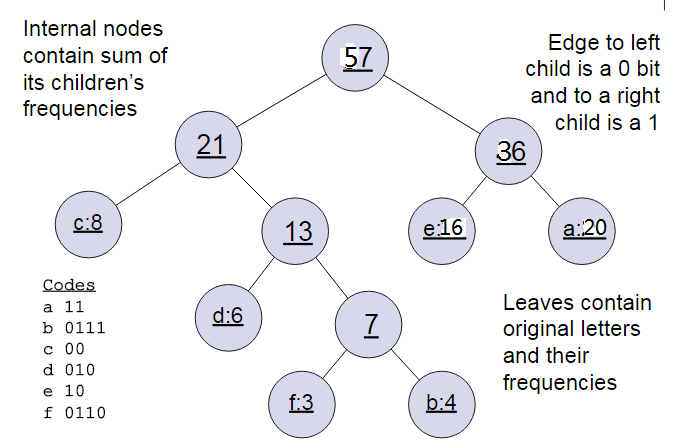
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.如上图,则可以得到c的编码是00。
在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号