深度学习优化性能(转载)
转载自 https://blog.csdn.net/qq_16234613/article/details/79596609
注意
1、调参看验证集。trainset loss通常能够一直降低,但validation set loss在经过一段降低期后会开始逐渐上升,此时模型开始在训练集上过拟合。
2、着重关注val loss变化,val acc可能会突变,但loss衡量的整体目标,但是你的测试集是验证集的话还是看评判标准为佳。
3、优先调参学习率。
4、通过对模型预测结果,可以判断模型的学习程度,如果softmax输出在0或1边缘说明还不错,如果在0.5边缘说明模型有待提高。
5、调参只是为了寻找合适的参数。一般在小数据集上合适的参数,在大数据集上效果也不会太差。因此可以尝试采样部分数据集,以提高速度,在有限的时间内可以尝试更多参数。
6、使用深度框架编程时,尽量使用框架提供的API,如tensor index索引,不要用for循环啥的。速度不是一个级别的。
学习率(重要)
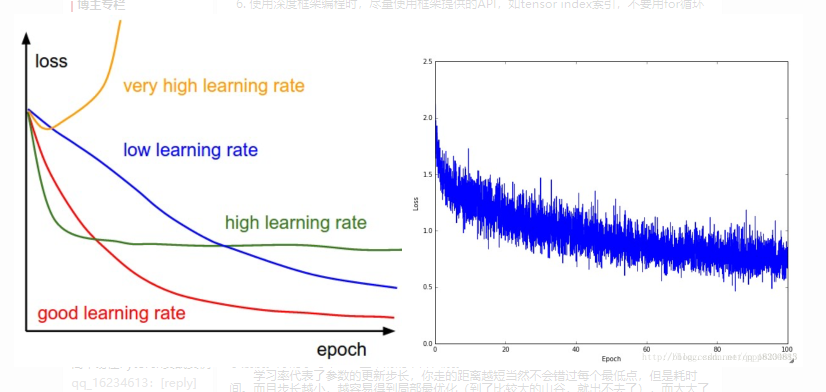
画图分析是种不错调参学习率的方式:学习率过大,loss曲线可能会上升,或者不能一直下降,出现震荡情况,由于学习率较大,导致参数在最优点附近徘徊,loss大小一下大一下小,就是却无法到达最优点,容易拟合在局部最小值。学习率太小loss曲线可能下降速度过于缓慢。好的学习率loss呈平滑的下降曲线。
学习率代表了参数的更新步长,你走的距离越短当然不会错过每个最低点,但是耗时间。而且步长越小,越容易得到局部最优化(到了比较大的山谷,就出不去了),而太大了可能会直接越过全局最优点。
1、lr:学习率太大,容易梯度爆炸,loss变nan。取1 0.1 0.01 .0001 … 10e-6(取对数变化)。常取0.1。通过对验证集的预测,可以选择一个较好的lr。如果当前的学习率不能在验证集上继续提高,可以将学习率除以2或者5试试。
2、decay:训练集的损失下降到一定的程度后就不再下降了,而且train loss在某个范围内来回震荡,不能进一步下降(也就是loss一下跳到最低点左侧,一下跳到最低点右侧,由于学习率过高就是不能继续下降)。可采用衰减学习率,学习率随着训练的进行逐渐衰减。取0.5。比如当val loss满足 no-improvement规则时,本来应该采取early stopping,但是可以不stop,而是让learning rate减半继续跑。如此反复。衰减方法有:衰减到固定最低学习率的线性衰减,指数衰减,或每次val loss停滞时衰减2-10倍。
3、fine-tuning的时候,可以把新加层的学习率调高,重用层的学习率可以设置的相对较低。
参数初始化
1、破坏不同单元间对称性,如果两个单元相同,接受相同的输入,必须使其具有不同的初始化参数,否则模型将一直以相同方式更新这两个单元。更大的初始化权重会更容易破坏对称性,且避免在梯度前向和反向传播过程中丢失信号,但如果权重初始化太大,很容易产生爆炸值(梯度爆炸可以使用梯度截断缓解);而在CNN中会导致模型对输入高度敏感,导致确定性的前向传播过程表现的随机;而且容易导致激活函数产生饱和的梯度,导致梯度丢失。
2、不可取:
初始化为0,模型无法更新,而且模型权重的相同,导致模型的高度对称性。
初始化为 very small random numbers(接近0,但不是0),模型效果不好,会导致梯度信息在传播中消失。
3、推荐:
一般bias全初始化为0,但在RNN中有可能取1(LSTM)。
random_uniform
random_normal
glorot_normal
glorot_uniform(无脑xavier,为了使得网络中信息更好的流动,每一层输出的方差尽量相等。)
4、推荐:使用方差缩放初始化。在 TensorFlow 中,该方法写作 tf.contrib.layers.variance_scaling_initializer()。根据我们的实验,这种初始化方法比常规高斯分布初始化、截断高斯分布初始化及 Xavier 初始化的泛化/缩放性能更好。粗略地说,方差缩放初始化根据每一层输入或输出的数量(在 TensorFlow 中默认为输入的数量)来调整初始随机权重的方差,从而帮助信号在不需要其他技巧(如梯度裁剪或批归一化)的情况下在网络中更深入地传播。Xavier 和方差缩放初始化类似,只不过 Xavier 中每一层的方差几乎是相同的;但是如果网络的各层之间规模差别很大(常见于卷积神经网络),则这些网络可能并不能很好地处理每一层中相同的方差。

激活函数
1、ReLu:通用激活函数,防止梯度弥散问题。最后一层慎用ReLu做激活。
2、Sigmoid的可微分的性质是传统神经网络的最佳选择,但在深层网络中会引入梯度消失和非零点中心问题。除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,。sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。输入0均值,sigmoid函数的输出不是0均值的。
3、tanh范围在-1到1之间,且zero-center,但比sigmoid要好,但仍有饱和时梯度消失问题。
4、relu比sigmoid和tanh好,导数易计算收敛速度快,不会饱和。唯一问题就是x小于0时梯度为0,可能会导致许多神经元死亡。使用时尤其注意lr的设置
5、Leaky_ReLu及ReLu变种,maxout可以试试。
6、通常使用ReLu,及其变种,PReLU and RReLU 效果挺好。tanh可以试试,但不要使用sigmoid。
7、原版rnn 只有tauh不会爆炸,所以有了lstm 在最后drop以及改进的GRU 靠阈值砍梯度。所以lstm/gru 无论用什么激活函数都不会爆。标准rnn 哪怕梯度是1,一路×下来不是消失就是爆炸;于是就有了irnn https://arxiv.org/abs/1504.00941就是把 权矩阵初始为单位阵;当然还有去年的ind rnn 不但解决了梯度爆炸的问题,顺便还解决了可解释性
maxout增加大量参数,计算图如下:
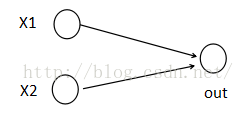
普通网络:
z=WX+b
out=f(z)
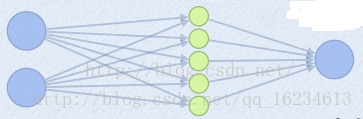
maxout层,其中z个数自定
z1=w1x+b1
z2=w2x+b2
z3=w3x+b3
z4=w4x+b4
z5=w5x+b5
out=max(z1,z2,z3,z4,z5)
模型
1、如果输入向量固定大小,可考虑使用全连接前馈网络,如果输入为图像等二维结构,可考虑卷积网络,如果输入为序列,可考虑循环神经网络。
2、BN:提高性能,加速训练,有时可省去dropout。注意BN在batch size过小时性能不是很好。删掉批归一化层。再将批处理大小减小为 1 时,这样做会暴露是否有梯度消失和梯度爆炸等问题。我们曾经遇到过一个好几个星期都没有收敛的网络,当我们删除了批归一化层(BN 层)之后,我们才意识到第二次迭代的输出都是 NaN。在这里使用批量归一化层,相当于在需要止血带的伤口上贴上了创可贴。批归一化有它能够发挥效果的地方,但前提是你确定自己的网络没有 bug。
3、尽量选择更多的隐层单元,小filter,利用非线性,而过拟合通过正则化的方法避免。
4、一开始需要验证模型是否有问题,可采取小量数据集、很深模型快速看模型是否能够对训练集很好的过拟合,而测试集准确率很低。
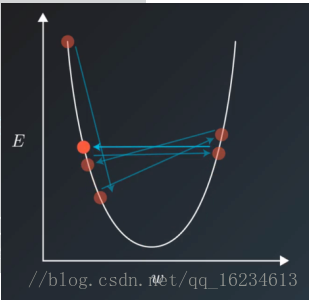
5、batch_size:常取2的n次方。 取 32 64 128 256 … 。batch越大,一般模型加速效果明显。不考虑时间成本的情况下,batch size=1可作为一个regularizer。将批处理大小减小到 1 可以向你提供与权重更新相关的更细粒度的反馈,你应该将该过程在 TensorBoard(或者其他的调试/可视化工具)中展示出来。尽管batch size越大,模型运行越快,但并不是越大,效果越好。batch size增大,模型训练越稳定,学习率可以些许调大,但是有时候小的batch size带来的噪声影响可能会使模型获得更好的泛化能力,更容易越过损失函数中的鞍点(损失函数在某个点的某个方向呈现已到达最小值的假象,其实在另一个方向是万丈深渊,这是小batch提供的随机性能够帮助模型跳过鞍点。),当然小batch size存在训练稳定性差的缺点。
6、不同尺寸的feature maps的concat,利用不同尺度的信息。
7、resnet的shortcut有作用,shortcut的支路一定要是identity。
8、可以利用Inception方法来提取不同抽象程度的高阶特征。
9、梯度归一化:计算出来梯度之后,除以Minibatch的数量。
10、利用pre-trained model和fine-tune可以实现很好的性能。
11、为每一层添加一个偏置项。偏置项将一个平面转换到最佳拟合位置。在 y=mx+b 式中,b 是偏置项,使直线能够向上或向下移动到最佳的拟合位置。
优化函数
1、Adam:收敛速度快。可以无脑用。在 TensorFlow 环境下使用 ADAM 时,请注意:如果你想要保存和恢复模型权重,请记住在设置完 AdamOptimizer 后设置 Saver,这是因为 ADAM 也有需要恢复的状态(即对应于每个权重的学习率)。在随机梯度下降(SGD)中,降低学习率是很常见的,但是 ADAM 天然地就考虑到了这个问题。可以不使用学习率衰减。
2、SGD+Momentum:效果比Adam可能好,但速度稍慢。m取值0.5 0.95 0.9 0.99
3、梯度截断: 限制最大梯度 或者设置阀值,让梯度强制等于5,10,20等。
卷积步幅,池化
1、strides:取小值,常取1,2,
2、filter数量翻倍(数量2^n,第一层不宜太少,n为层数)。反卷积相反。
3、kernel size:流行使用小size(3*3),注意对于大目标,感受野太小可能影响性能。尤其对于FCN,FC全连接毕竟具有全局视野。
4、pooling:常取2*2
数据集、输入预处理和输出
如何判断是否应该收集更多数据:
首先判断当前模型是否在该训练集上性能良好,如果在当前训练集上性能就很差,此时应该注重提高模型,增加网络层或隐藏单元等。如果使用更大模型后还是效果不佳,此时应考虑是否是数据集质量不佳(包含太多噪声等),或模型存在根本错误。
然后如果模型在训练集上性能可以接受,但在测试集上很差,此时可以考虑收集更多数据。但此时需要考虑收集数据的可行性和代价。如果代价太高,一个可行办法是降低模型大小,改进正则化,调参等。通常在对数尺度上收集数据。
1、尽可能获得更多的数据(百万级以上),移除不良数据(噪音、假数据或空值等,数据中出现nan值时会导致模型loss变成nan)。
2、数据不足时做好Data Augment。对于图像可以水平翻转,随机裁剪crop,旋转,扭曲,缩放,拉伸,改变色调,饱和度(HSV)等,还可以同时随机组合。需注意改变后的图片(垂直翻转)是否符合实际,是否丢失重要特征等问题。AlexNet对256的图片进行224的随机crop采样,对每一张图片,产生2048种不同的样本,使用镜像后,数据集翻了2048*2=4096倍。虽然大量的重采样会导致数据的相关性,但避免了过拟合。至少比多个epoch输入相同图像要好。AlexNet中还有一种Fancy PCA采样方法。
3、输入训练集一定要shuffle。注意keras中自带的shuflle针对的是batch内部的打乱。
4、输入特征归一化,zero-center和normalize。PCA whitening一般不需要。还有处理到-11之间或01之间。当网络的权重在各个方向上延伸和扩展的程度越小,你的网络就能更快、更容易地学习。保持数据输入以均值为中心且方差不变有助于实现这一点。
5、预测目标(label)都做好归一化。比如回归问题中,label相差过大(0.1和1000),做好normalization能统一量纲
6、数据集类别不平衡问题:上采样、下采样。或者使用data augment方式对较少类别数据进行采样。对类别不平衡进行loss,权重调整。或者将数据集按类别拆分,优先训练数量多的类别数据,再训练数量少的类别数据。
7、不仅训练集做好增强,测试集也最好做增强。保持二者分布的一致性。
8、label smoothing针对解决过拟合,不一定work。new_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes
9、数据过少问题:数据增广;半监督学习;迁移学习;领域自适应;主动学习。
10、NLP中的数据增强:随机删除词,同义词替换,词语顺序打乱,randomly change one letter in a word, randomly delete one letter in a word,randomise tokens position, subsample number of tokens,enrich tokens with synonyms
1 # zero-center normalize 2 X -= np.mean(X, axis = 0) 3 X /= np.std(X, axis = 0)
目标函数
1、多任务情况下, 各loss尽量限制在一个量级上, 初期可以着重一个任务的loss。
2、focal loss可能有点作用
正则化
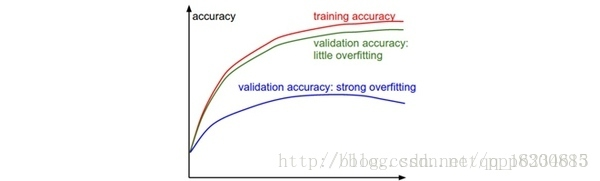
如何判断是否过拟合或者欠拟合:若训练集准确率一直大幅度高于验证集,说明模型过拟合,可以增大正则化强度,如增大L2正则惩罚,增加dropout的随机失活率等。如果训练集一直小幅度低于验证集,说明稍微过拟合,而如果训练集和验证集的准确率不相上下,说明此时模型有点欠拟合,没有很好地学习到特征,可以调整模型宽度、深度等。
在训练过程中L2范数使得权重分量尽可能均衡,即非0分量个数尽量稠密,而L1范数和L0范数尽可能使权重分量稀疏,即非0分量个数尽量少。
稀疏性能实现特征的自动选择。在我们事先假定的特征中,有很多特征对输出的影响较小,可以看作是不重要的特征。而正则化项会自动对特征的系数参数进行惩罚,令某些特征的权重系数为0或接近于0,自动选择主要自变量或特征。
如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。
建议开始将正则项惩罚系数λ设置为0,待确定比较好的learning rate后,固定该learning rate。给λ一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍进行粗调,然后进行细调。
1、注意除非数据集比较多(千万级),否则一开始最好采用温和一点的正则化。
2、Dropout:相当简单有效的一种方式,防止过拟合,取0.3 0.5(推荐,0.5时生成的组合网络最多) 0.7
3、L2正则:较为常用的正则方式。在目标函数中添加关于权重的部分。
4、L1正则:较为常用的正则方式。在目标函数中添加关于权重的部分。可以与L2连用。
5、Max norm Constraints:由于它限制了权重大小,使用这个约束后,网络一般不会出现“爆炸”问题。
Esemble
1、同样的参数,不同的初始化方式。使用cross-validation找出最佳超参,然后使用不同参数初始化方式训练多个模型。
2、不同的参数,通过cross-validation,选取最好的几组或性能较好的top-K组。
3、同样的参数,模型训练的不同阶段,即不同迭代次数的模型。
4、不同的模型,进行线性融合. 例如RNN和传统模型。
5、不同训练集训练的模型提取不同特征进行融合。
简单点:投票法、平均法、加权平均法
stacking法:
stacking的设计复杂,使用的时候要考虑时间的耗费,或者可以更改折数等;基模型除了是不同参数的相同模型之外,更重要的是要尽可能的多加一些不同种类的基模型进去。

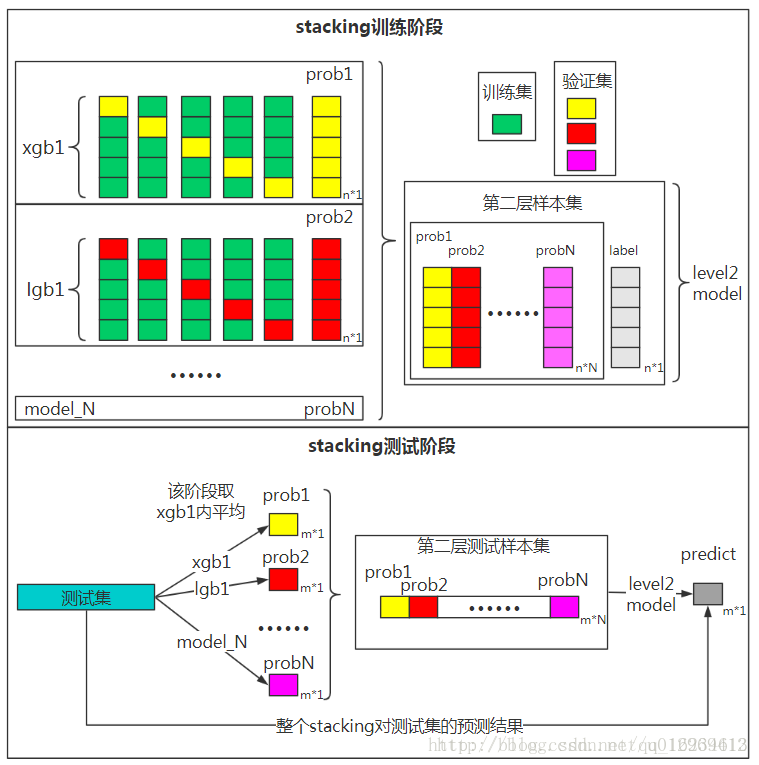
第一层你有模型M1和M3,首先对M1使用5-fold训练,得到5个模型,然后分别预测训练集(5折中某1折)合并后生成第二层的训练集F1,然后使用M1的5个子模型对测试集预测取均值T1,得到第二层的测试集。第一层模型M3同样采用此方法生成F3和T3。这样你的第二层模型M2就有训练集(F1,F2),测试集(T1,T2),使用第二层模型进行训练预测。
Blending法:
将数据划分成train,test,然后将train划分成不相交的两部分train_1,train_2。
使用不同的模型对train_1训练,对train_2和test预测,生成两个1维向量,有多少模型就生成多少维向量。
第二层使用前面模型对train_2生成的向量和label作为新的训练集,使用LR或者其他模型训练一个新的模型来预测test生成的向量。
图像可视化调参
1、可视化激活层、参数层
2、可视化分析1 可视化分析2
3、可视化输出错误:通过判断模型输出错误的样本,分析原因。
4、可视化激活函数值和梯度的直方图:隐藏单元的激活值可以告诉我们单元饱和程度;梯度的快速增长和消失不利于模型优化;在一次小批量参数更新过程中梯度参数的更新最好在原参数的1%左右,而不是50%或0.001%。注意如果数据是稀疏的(如自然语言),那么有些参数可能很少更新。
5、tensorboard
其他
1、早停
2、label smothing,在ground truth和predication之间加上一个随机值
3、batchsize和lr存在一定关系,更大batch,梯度更稳定。在大的lr导致loss nan时可以试试。
4、learning_rate/batch_size: see https://github.com/pjreddie/darknet/blob/master/src/convolutional_layer.c#L530
5、decay * batch_size: see https://github.com/pjreddie/darknet/blob/master/src/convolutional_layer.c#L529
6、检查你矩阵的重构「reshape」。大幅度的矩阵重构(比如改变图像的 X、Y 维度)会破坏空间局部性,使网络更不容易学习,因为这时网络也必须学习重构。使用多个图像/通道进行重构时要特别小心;可以使用 numpy.stack() 进行适当的对齐操作。
样本不平衡问题
1、过采样:随机采样、SMOTE、RAMO、Random Balance;Cluster-based oversampling;DataBoost-IM;class-aware sampling
2、欠采样:随机剔除、EasyEnsemble,one-sided selection;data decontamination
3、阈值移动:
4、代价敏感学习:
focalloss,OHEM等
自动调参
1、Random Search
2、Gird Search
3、Bayesian Optimization
减小内存
1、使用更大步态
2、使用1*1线性卷积核降维
3、使用池化降维
4、减小mini-batch大小
5、将数据类型由32为改成为16位
6、使用小的卷积核


 浙公网安备 33010602011771号
浙公网安备 33010602011771号