CS224--1:语言模型和词向量
参考:
https://www.cnblogs.com/pinard/p/7243513.html
https://blog.csdn.net/cindy_1102/article/details/88079703
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
1、NLP简介
1.1、什么是自然语言?
用来表示某种意义或东西的符号
1.2、NLP任务
1)、简单
拼写检查
关键词提取
同义词查询
2)、中等
信息抽取
3)、高难
机器翻译
语义分析
指代
问答
2、词向量(word vectors)
2.1、ont-hot
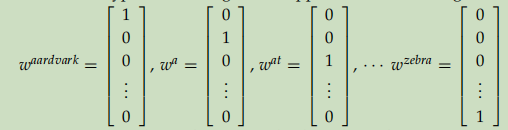

如图,每个词由V维的0,1向量组成,V是词典大小。有以下缺点:
1)、词之间凉凉正交,体现不出诸如男人、女人,中国、日本之间的相关性。
2)、当词典很大时,词向量太大。
那么我们是不是可以找到一种可以以低维的方式且能表示词之间相关性的词向量表示方法呢?
3、基于SVD的方法
4、基于迭代的方法-word2vector
4.1、语言模型
语言模型就是对一个语言序列进行建模。
比如
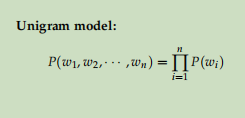
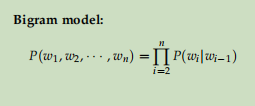
4.2、CBOW
模型思路:一个语言序列,通过某个词其周围的词预测中心词。
符号说明:
- wi : 词典里第i个词
- V : shape: (n, v), 输入的单词矩阵,n代表词向量的维度,v代表词典大小
- vi : V的第i列,shape=(n,1)
- U : shape=(v, n), 输出的单词矩阵
- ui : U的第i行,wi的输出向量表示
模型步骤:
- 对于一个序列,假设某词为x(c),其上下文为x(c-m), ...,x(c-1), x(c+1), ..., x(c+m),将其做one-hot表示
- 通过lookup得到上下文单词的嵌入词向量:v(c-m), v(c-m+1), ..., v(c+m)
- 对上下文词向量求平均:
![]()
- 将U与3中得到的向量做点乘,得到一个分。
![]()
- 对z做softmax进行分类,预测属于哪个词:
![]()
- 定义损失函数,交叉熵损失:
![]()
- 根据梯度下降法不断迭代反向传播,直到loss收敛。

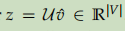
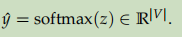

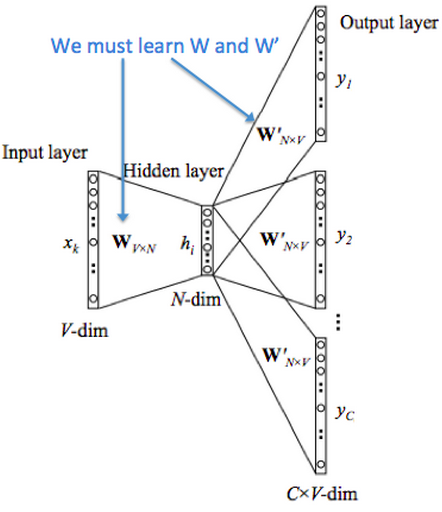
模型结构:

4.3、skip-gram model
模型思路:一个序列,通过中心词预测其上下文的词。
符号说明:
- wi : 词典里第i个词
- V : shape: (n, v), 输入的单词矩阵,n代表词向量的维度,v代表词典大小
- vi : V的第i列,shape=(n,1)
- U : shape=(v, n), 输出的单词矩阵
- ui : U的第i行,wi的输出向量表示
模型步骤:
- 得到中心词的one-hot表示
- lookup得到中心词的词向量
- 计算得分:
![]()
- 根据得分计算softmax, 预测上下文的词:
![]()
- 根据4得出的概率,计算预测出的词
- 同样采用交叉熵作为损失函数,此处值得留意的是,预测出的多个上下文单词之间假设是独立的,不因其与中心词的距离而受到影响,因此loss可以这么计算:
![]()
- 使用随机梯度下降法优化loss, 直到loss收敛。
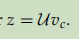


模型结构:
4.4、负采样
4.5、hierarchical softmax
词向量训练的时候,假如说词典的大小为v,那么每次前向传播通常需要进行v次的点击运算,然后算出每个词的概率,非常耗时。
这里采用了两个方法减少计算,一个是把词向量进来后经过线性运算通常会加的非线性激活函数给去掉,换成求平均值。第二个就是把词分类的softmax换成一颗二叉霍夫曼树。

和之前的神经网络语言模型相比,我们的霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
如何“沿着霍夫曼树一步步完成”呢?在word2vec中,我们采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:

其中xwxw是当前内部节点的词向量,而θθ则是我们需要从训练样本求出的逻辑回归的模型参数。
使用霍夫曼树有什么好处呢?首先,由于是二叉树,之前计算量为VV,现在变成了log2Vlog2V。第二,由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到,这符合我们的贪心优化思想。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号