[图像]用edge impulse训练你的目标检测模型并部署至Linux
![[图像]用edge impulse训练你的目标检测模型并部署至Linux](https://img2022.cnblogs.com/blog/2702372/202204/2702372-20220418195355355-454129347.png) 没什么好摘要的-_-
没什么好摘要的-_-
从学长推荐这个到跑通大概也就一个下午,edge impulse把模型训练做的非常方便,标注和训练都是在网页端即可完成。在部署到Linux方便也是做的非常便捷,几乎没有遇到过很严重的问题。
这篇文章只是走一遍训练并部署的流程,并不会提及有关深度学习的知识
那么接下来直接开始
一、创建账号并新建一个工程
创建账号就不讲了
关于新建工程,新建第一个工程之后会弹出如下界面,我们因为要做目标检测,所以我们选择Images->Classify multiple objects
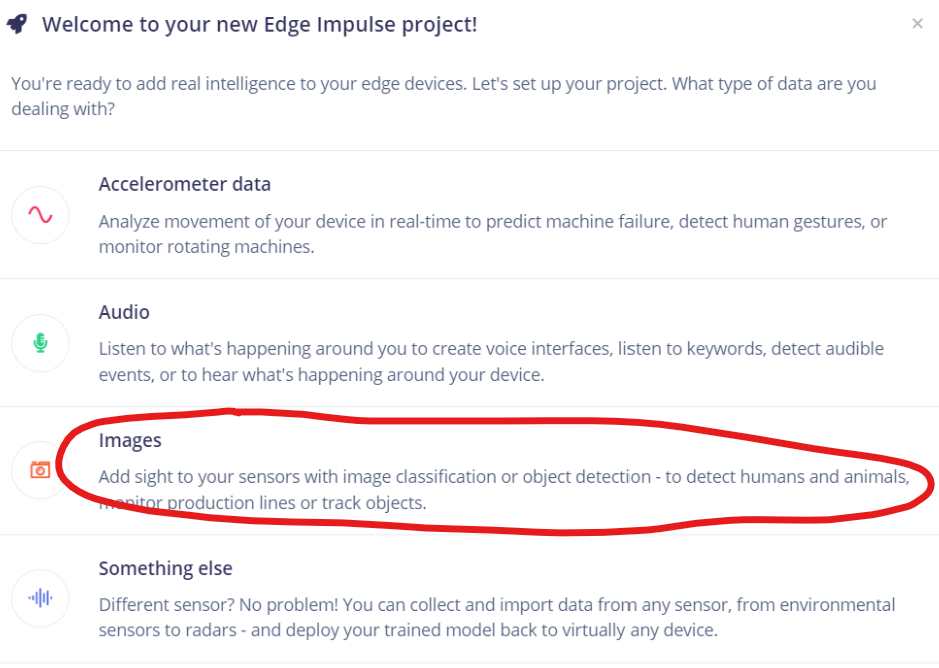
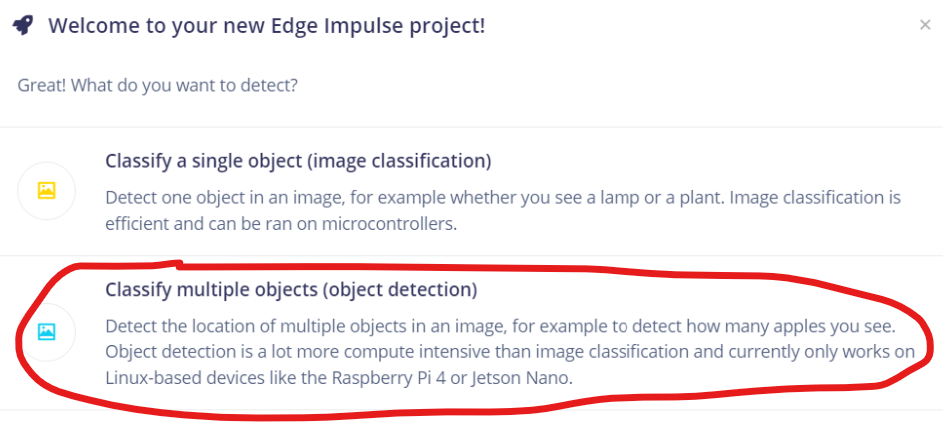
后面的界面不用选直接get started即可
然后一开始的界面是这样的:
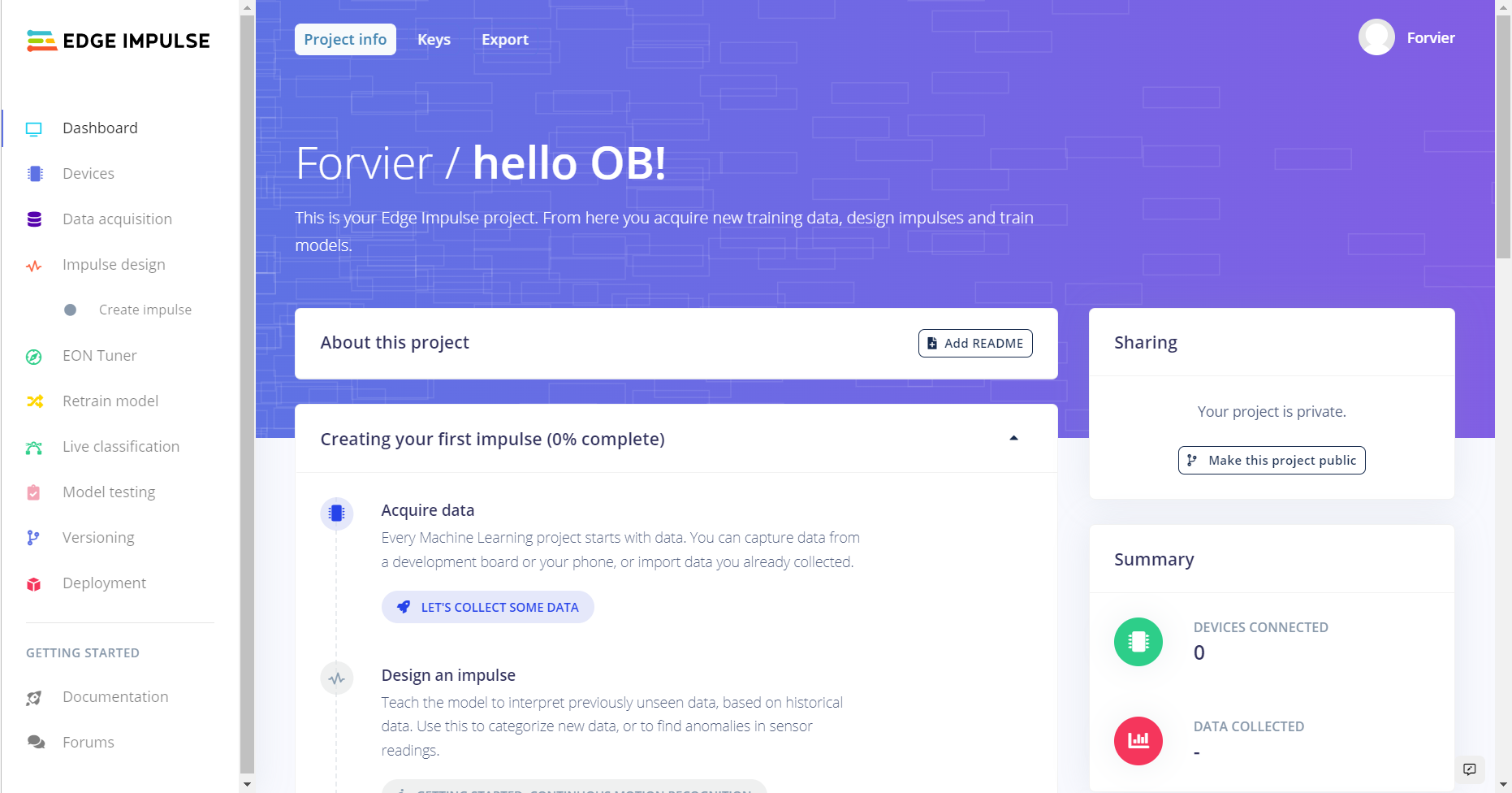
二、收集数据并标注
网站的引导做的很好,我们点击哪个蓝蓝的按钮就是收集数据了,给的收集方式也很多,你可以直接用连接上的板卡去收集数据,调用收集或电脑的摄像头都是可行的,也可以直接上传已经拍好的照片。这里的话就以直接上传拍好的数据为例子了。
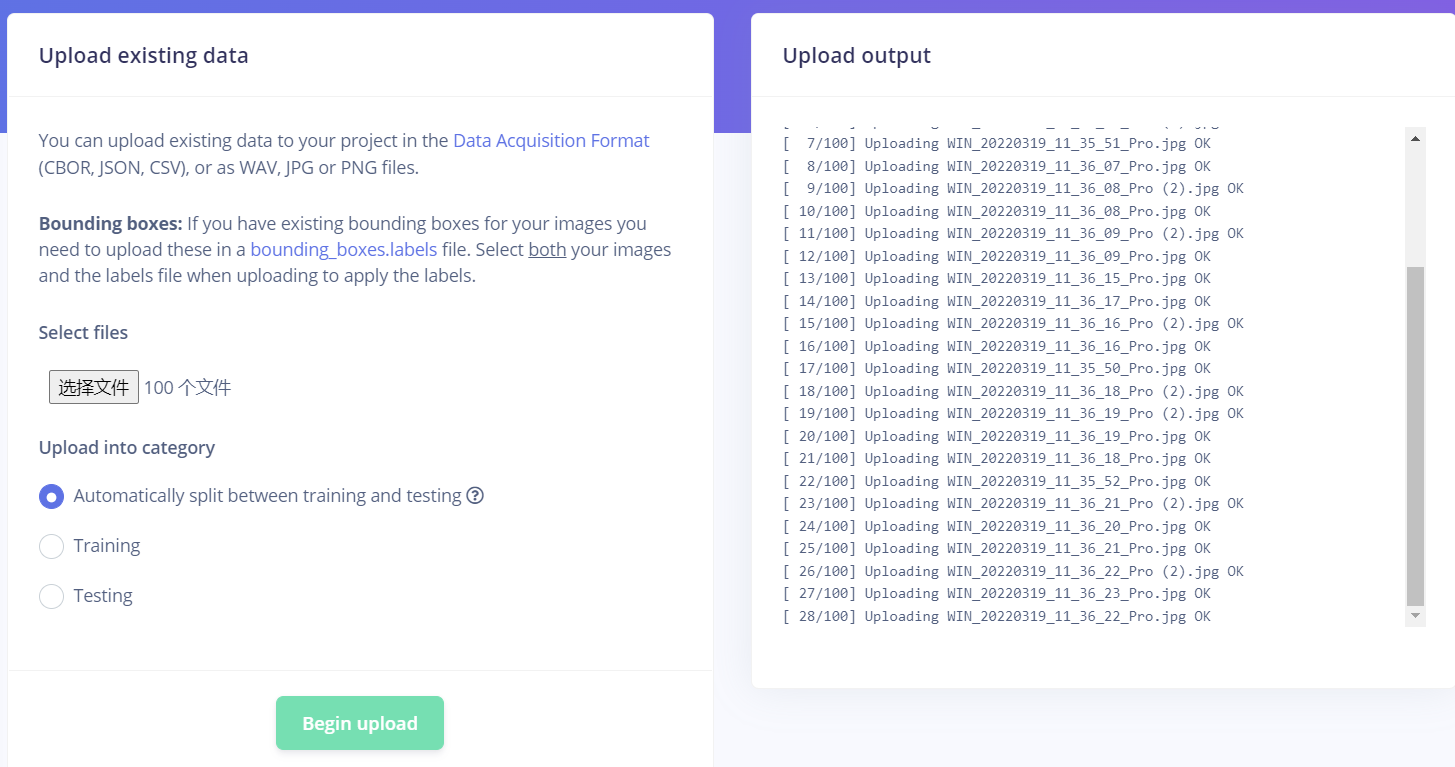
简洁明了
标注
我们点击侧边栏的Data acquisition然后点进去Labeling queue
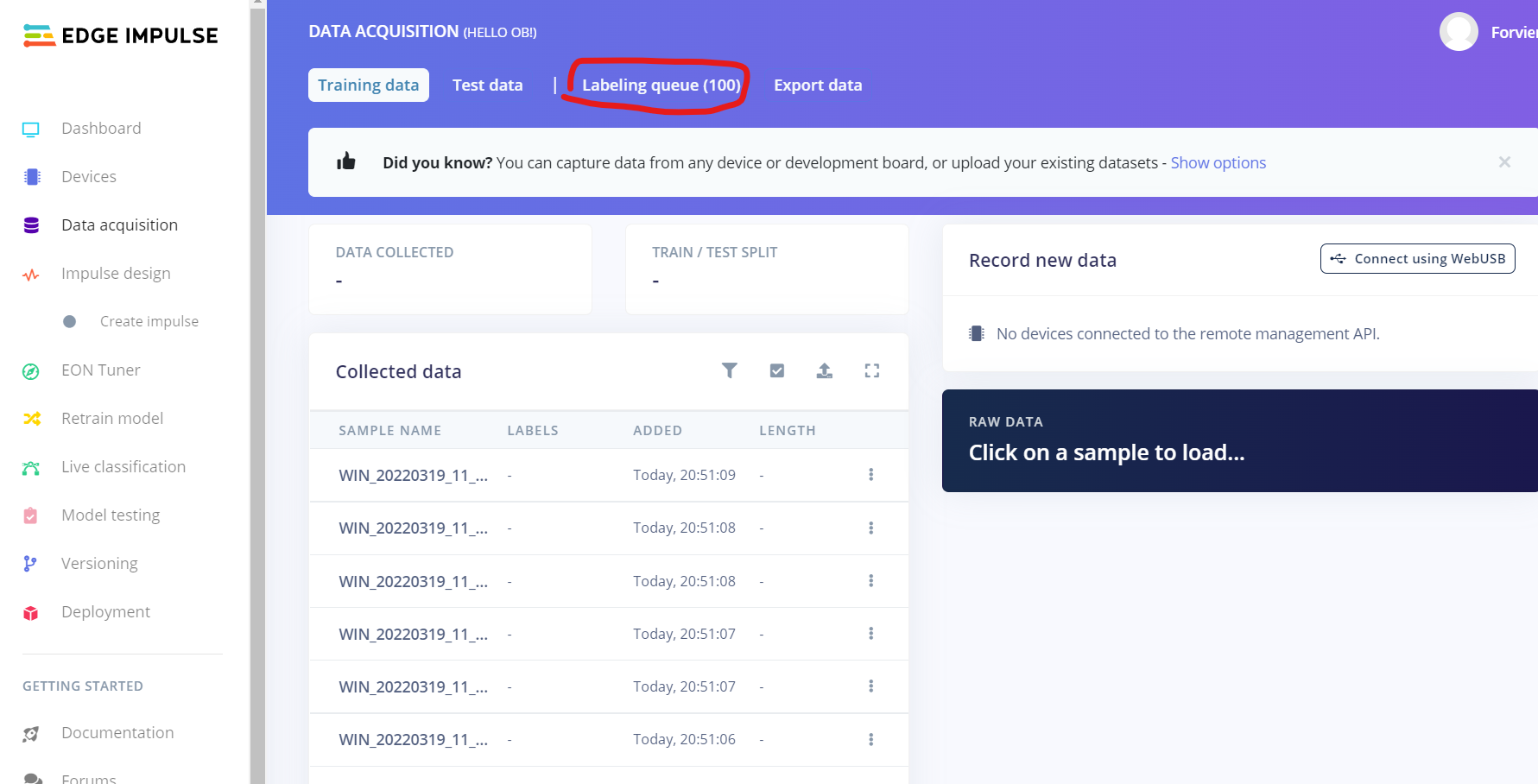
用鼠标拖动画框,每画完一个框就会让你输入标签名,完成之后点击Save labels,就会跳到下一张图片,重复操作即可。

带上耳机然后慢慢把数据集都标注上吧
三、Impulse design
Create impulse
我们点开侧边栏的Impulse design中的Create impulse
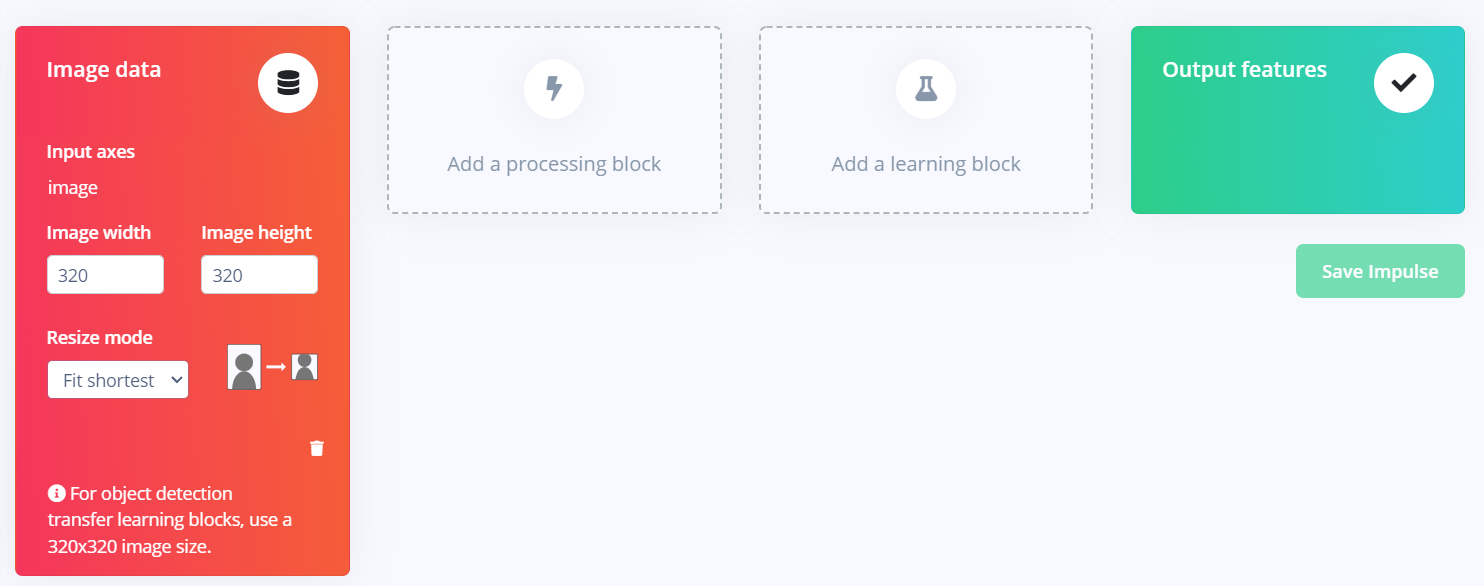
需要添加一个预处理块和深度学习块,在Processing block中我们可以选择Image或raw data,然后在Learning block中就只有一个目标检测的选项了。
之后点保存即可
Image
同样点进Image中即可
其他一般不用动,我们点进上方的Generate Features,然后等待它生成
最后会有下面的图
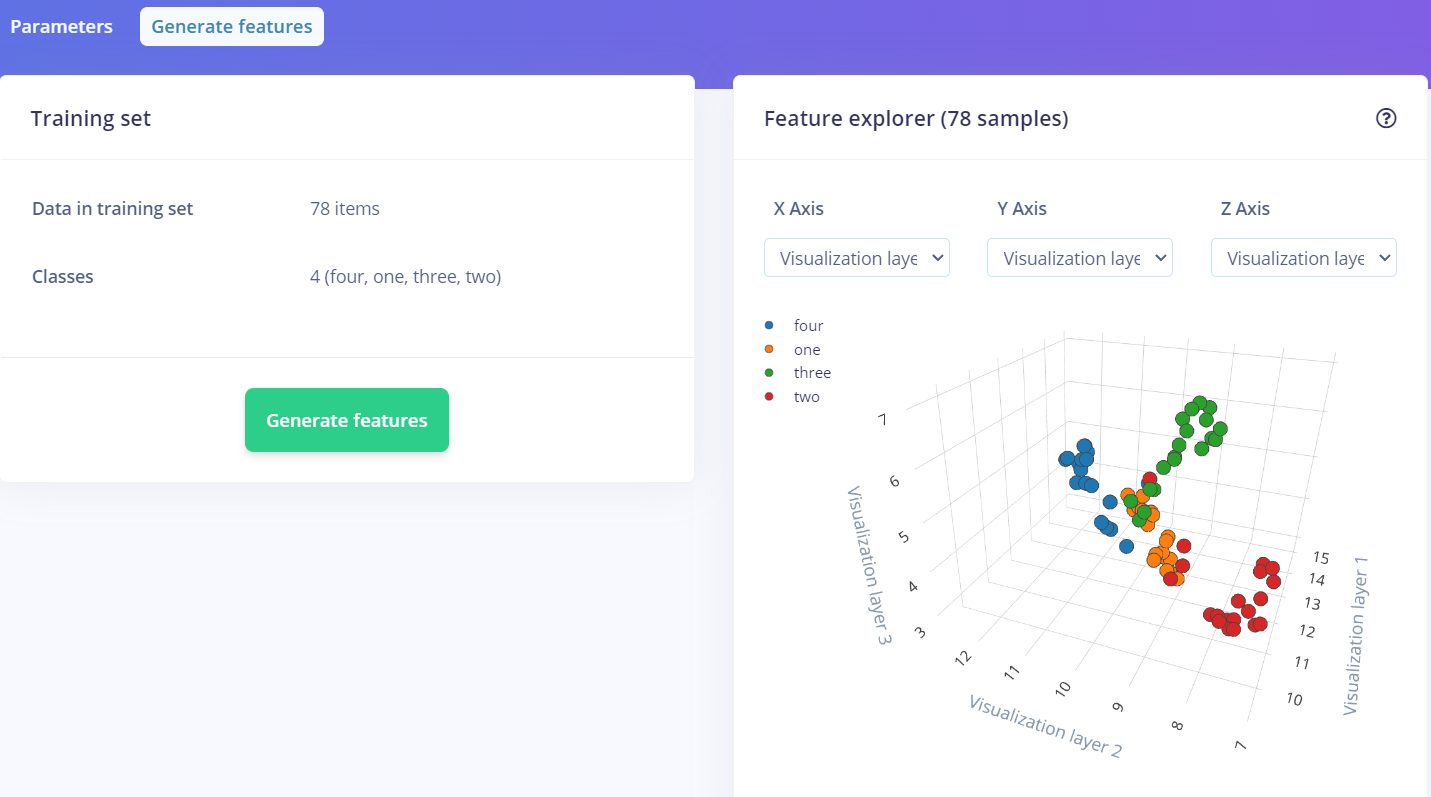
如果你的数据集比较好的话,同样颜色的点会聚集在同一片区域,通过这一点可以去检查你的数据集质量以及是否有标错的情况。
Object detection
不懂深度学习的知识的话,直接点绿油油的按钮就好了,后续可以通过学习来调整其中的参数。
稍候片刻即可。
四、Model testing
这里可以测试你训练的模型的好坏,同样点绿色按钮就一步到位。
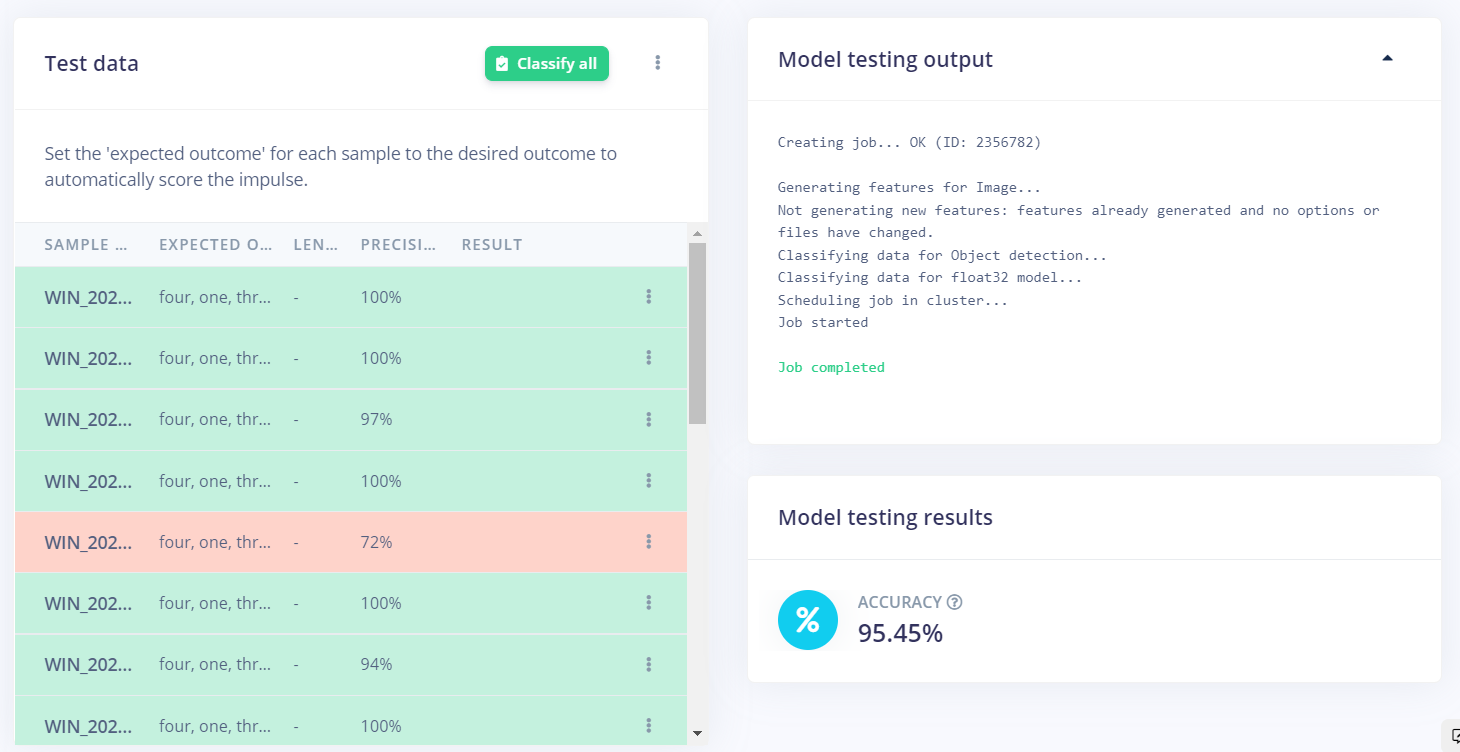
每张测试集中的图片都可以点进去具体看结果
五、部署!
5.1 安装sdk
我这里使用的是官方提供的Linux Python SDK
安装方法:
对于树莓派:
sudo apt-get install libatlas-base-dev libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev
pip3 install edge_impulse_linux
对于一般的单板:
pip3 install edge_impulse_linux
如果下载慢甚至下载失败的话记得换个源或者搞点科*上网
5.2 安装Linux-impulse-linux
笔者参照的是Linux x86_64,如果是树莓派或者jsnano的话官方有给更详细的教程
下面大概率用国内的网是无法完整安装完成的,所以建议上proxychains4或者其他工具
sudo apt install -y curl
curl -sL https://deb.nodesource.com/setup_12.x | sudo bash -
sudo apt install -y gcc g++ make build-essential nodejs sox gstreamer1.0-tools gstreamer1.0-plugins-good gstreamer1.0-plugins-base gstreamer1.0-plugins-base-apps
npm config set user root && sudo npm install edge-impulse-linux -g --unsafe-perm
5.3 连接至edge-impulse
在命令行中输入:
edge-impulse-linux
之后会让你去登录网站并选择工程啥啥的,看着提示来就行
成功的话可以在网站侧边栏Devices中看见自己的设备
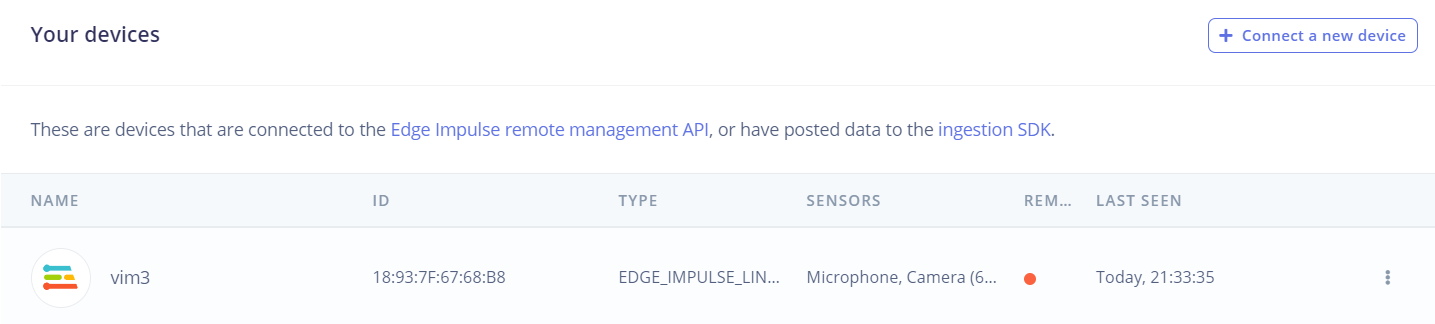
实际上如果这样连接上单板电脑的话就可以直接调用单板电脑的摄像头了
5.4 build模型
edge-impulse-linux-runner
这里官方是需要.eim文件的模型文件,但是我也出错了,查了查大概是官方用nodejs写的一个bug

其实我们直接手动把它提到转移失败的文件复制并重命名为.eim后缀的文件然后放到我们想要的位置,然后给一个777权限即可。
5.5 运行代码
我比较懒就直接贴我改的官方代码了
输入图像需要320*320,这取决于你训练时填的参数,如果不匹配的话会导致框出来的框比例不对
import numpy as np
from edge_impulse_linux.image import ImageImpulseRunner
def main():
model = 'test.eim'
dir_path = os.path.dirname(os.path.realpath(__file__))
modelfile = os.path.join(dir_path, model)
print('MODEL:'+modelfile) # 记得要加777
with ImageImpulseRunner(modelfile) as runner:
try:
model_info = runner.init()
print('loaded runner for"' + model_info['project']['owner']+'/'+model_info['project']['name'] + '"')
labels = model_info['model_parameters']['labels']
cap = cv.VideoCapture(1) # 摄像头编号
if not cap.isOpened(): # 如果摄像头没有没打开就退出程序
print('cannot open the cam')
exit()
while True:
t = cv.getTickCount()
ret, frame = cap.read() # 第一个返回是否有图像
if not ret: # 如果没有获取图像退出
print('cam break!')
break
frame = cv.resize(frame,(320,320))
#frame = cv.resize(frame,None,fx=0.5,fy=0.5)
img = cv.cvtColor(frame,cv.COLOR_BGR2RGB)
features, cropped = runner.get_features_from_image(img)
res = runner.classify(features)
print('Found %d bounding boxes (%d ms.)' % (len(res["result"]["bounding_boxes"]), res['timing']['dsp'] + res['timing']['classification']))
for bb in res["result"]["bounding_boxes"]:
cv.rectangle(frame,(bb['x'],bb['y']),(bb['x']+bb['width'],bb['y']+bb['height']),(0,255,0),2)
cv.putText(frame,bb['label']+str(int(100*bb['value'])),(bb['x'],bb['y']),cv.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2,cv.LINE_AA)
# print('\t%s (%.2f): x=%d y=%d w=%d h=%d' % (bb['label'], bb['value'], bb['x'], bb['y'], bb['width'], bb['height']))
if cv.waitKey(1) == ord('q'):
break
t = cv.getTickCount()-t
fps = cv.getTickFrequency()/t
cv.putText(frame,'fps:'+str(int(fps)),(30,30),cv.FONT_HERSHEY_COMPLEX,0.7,(0,255,0))
cv.imshow('frame', frame)
cap.release()
cv.destroyAllWindows()
finally:
if(runner):
runner.stop()
if __name__ == '__main__':
main()
在仅有100张图片的数据集下的效果还不错但是帧数说实话不是很好看


 浙公网安备 33010602011771号
浙公网安备 33010602011771号