hdfs基本介绍
一、hdfs概述
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的简称,它的设计目标是把超大数据集存储到网络中的多台普通计算机上,并提供高可靠性和高吞吐率的服务。
HDFS的优点:
高容错性:数据自动保存多个副本,hdfs默认的副本数量是3
适合处理大数据:能够处理GB、TP甚至BP级别的数据,能够处理百万规模以上的文件数量
可构建在廉价机器上
HDFS的缺点:
不适合低延迟的数据访问:hdfs无法实现毫秒级别的数据存储和访问,hdfs提供高吞吐量但无法提供低延迟数据访问
无法高效处理大量的小文件:大量小文件会占用namenode大量的内存来存储元数据,且会导致寻址时间过长
不支持并发写入和随机修改:一个文件只能有一个写,不允许多个线程同时写;仅支持数据追加append,不支持随机修改
二、hdfs组织和架构
hdfs主要有3个组间构成,分别是NameNode、SecondaryNameNode和DataNode。
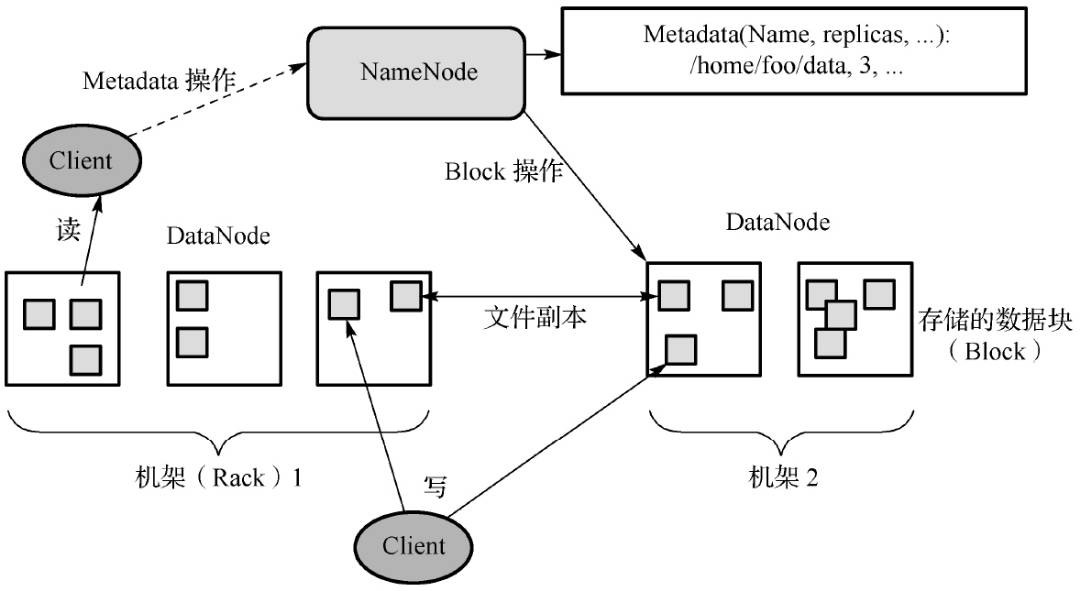
NameNode的主要功能:
管理文件系统的名称空间
配置副本策略
管理元数据,维护目录树,包括文件名、目录名及其层级关系,文件、目录的所有者及权限,每个文件的数据块名称及文件有哪些数据块
处理客户端的读写请求
NameNode实时通过心跳消息与DataNode交互,检查文件系统是否运行正常。
namenode中的元数据不包含每个数据块的位置信息,位置信息会在namenode启动时从datanode获取并保存在内存中,减少寻址时间。
DataNode的主要功能:
存储实际的数据块
执行数据块的读写操作
SecondaryNameNode的主要功能:
定期合并fsimage文件和edits文件
紧急情况辅助恢复NameNode。
client,就是客户端
与NameNode交互,获取文件位置信息
与DataNode交互,进行文件读写操作
NameNode上存储元数据的文件叫fsimage,NameNode启动时将fsimage加载到内存,对元数据的操作保存在内存中并被持久化到另一个文件edits,SecondaryNameNode合并fsimage和edits的过程:
合并之前通知NameNode将新的操作写到新的edits文件并将其命令为edits.new
SecondaryNameNode从NameNode请求fsimage和edits文件
SecondaryNameNode把fsimage和edits文件合并生成新的fsimage文件
NameNode从SecondaryNameNode获取合并好的fsimage并替换原来旧的fsimage,并用edits.new文件替换掉原来的edits文件
更新fstime文件中的检查点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号