sql开窗函数
mysql8.0之前的版本是不支持开窗函数的,8.0之后才支持。
开窗函数与聚合函数的计算方式一样,也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值。
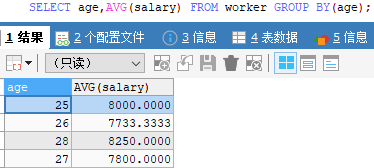
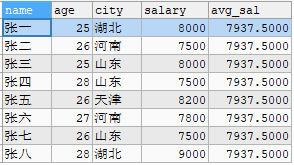
假设有一个员工信息表worker,数据如下图一。如果我们要计算所有人或者每个年龄的平均工资,可通过聚合函数avg(salary) …group by...实现,如下图二和图三。我们知道聚合函数select中的列除了聚合函数,其他列必须通过group by去分组,即通过聚合函数得到的结果,只能显示聚合列、和通过聚合列聚合出来的值,无法查看这之外的其他信息。如下图三,只能查看每个年龄和对应年龄的平均工资,无法同时查看每个人的姓名和城市(当然通过子查询可以实现)。开窗函数就可以解决这个问题。
SELECT AVG(salary) FROM worker ;SELECT age,AVG(salary) FROM worker GROUP BY(age);


开窗函数的语法为:
function(column1)
over( [partition by column2] -----分区元素
[order by column3] -----排序元素
[row|range ......] ) -----框架元素
partition by 和order by 可以省略也可以只出现一个。
开窗函数主要分为两类,聚合开窗函数和排名开窗函数。
一、聚合开窗函数
SQL 标准允许将所有聚合函数用做开窗函数,使用over()关键字来区分这两种用法,over()关键字表示把函数当成开窗函数而不是聚合函数。
1、over()
如果over()括号中的参数为空,开窗函数会对结果集中的所有行进行聚合运算。
SELECT *,AVG(salary) OVER() avg_sal FROM worker;
2、over(partition by column)
over()中的partition by子句用于定义行的分区来供进行聚合计算。与group by子句不同,partition by子句创建的分区独立于结果集,而且不同的开窗函数创建的分区互不影响。
SELECT *,AVG(salary) OVER(PARTITION BY age) avg_age_sal FROM worker;SELECT *,AVG(salary) OVER(PARTITION BY age) avg_age_sal,AVG(salary) OVER(PARTITION BY city) avg_city_sal FROM worker;


3、over(order by column)
over()中的order by子句用于指定排序规则,有的开窗函数要求必须指定排序规则。使用order by子子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。
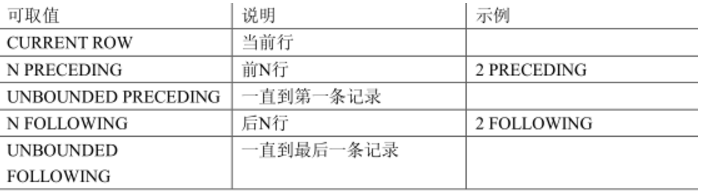
order by子句语法:order by column range|rows between 边界规则1 and 边界规则2,红色标记部分用来定位聚合计算范围,又被称为定位框架。
rows表示按照行的范围进行范围的定义,range表示按照值的范围进行范围的定义,边界规则的可取值如下:
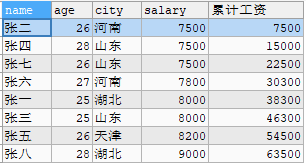
示例1:按工资排序,并求第一行到当前行的累计工资。
SELECT *,SUM(salary) OVER(ORDER BY salary ROWS BETWEEN unbounded preceding AND current ROW) 累计工资 FROM worker;
ROWS BETWEEN unbounded preceding AND current ROW是开窗函数中最常使用的定位框架,表示从第一行到当前行。
示例2:将示例中的row改成range,如下
/*方法1*/SELECT *,SUM(salary) OVER(ORDER BY salary RANGE BETWEEN unbounded preceding AND current ROW) 累计工资 FROM worker; /*方法2*/SELECT *,SUM(salary) OVER(ORDER BY salary) 累计工资 FROM worker;

rows是按行定位,range是按值定位,这两个不同的定位方式主要在于处理并列排序的情况。
4、over(partition by column order by column)
partition by和order by结合使用
二、排名开窗函数
主要有三个,ROW_NUMBER()、RANK()、DENSE_RANK(),它们的主要区别在于对并列值的处理规则不同。
使用上述三个函数,对员工信息表按照工资排序,sql语句和输出结果如下。
SELECT *, ROW_NUMBER() OVER(ORDER BY salary) rownumber_salary , RANK() OVER(ORDER BY salary) rank_salary, DENSE_RANK() OVER(ORDER BY salary) dense_rank_salary FROM worker;
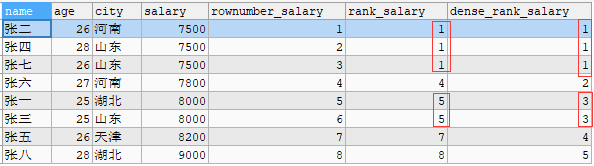
ROW_NUMBER():不处理并列的情况,得到的结果连续递增。
RANK():相同的值排序相同,但接下来的序号会跳过
DENSE_RANK():相同的值排序相同,接下来的序号顺序递增

 浙公网安备 33010602011771号
浙公网安备 33010602011771号