hadoop集群安装
基础环境centos7.5,jdk-8u212-linux-x64、hadoop-3.1.3.tar.gz。
Hadoop 下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
集群规划

一、基础环境准备
准备三台虚拟机,使用NAT网络模式。
关闭防火墙:systemctl status firewalld;systemctl enable firewalld
关闭selinux:修改/etc/sysconfig/selinux,SELINUX=disabled
主机名分别修改为:hadoop102、hadoop103、hadoop104(修改/etc/hostname)
设置静态ip:192.168.229.102、 192.168.229.103、192.168.229.104(修改/etc/sysconfig/network-scripts/ifcfg-ens33)
主机名映射hosts文件:修改/etc/hosts
然后reboot重启
二、安装安装 epel-release工具包
EPEL的全称叫 Extra Packages for Enterprise Linux,是为“红帽系”的操作系统提供额外的软件包,适用于 RHEL、CentOS 和 Scientific Linux,相当于是一个软件仓库。我们在Centos下使用yum安装时往往会出现找不到rpm的情况,官方的rpm repository提供的rpm包也不够丰富,安装上 EPEL之后,就相当于添加了一个第三方源。
[root@localhost yum.repos.d]# yum -y install epel-release 已加载插件:fastestmirror, langpacks …… 已安装: epel-release.noarch 0:7-11
三、创建应用用户并配置免密登录
创建安装hadoop的应用用户
[root@localhost ~]# useradd hadoop [root@localhost ~]# passwd hadoop #按照提示输入用户hadoop的密码
给hadoop赋予sudo权限
[root@localhost ~]# vi /etc/sudoers #在%wheel下面加入一行 %wheel ALL=(ALL) ALL hadoop ALL=(ALL) NOPASSWD:ALL
对hadoop用户配置免密,hadoop102、hadoop103、hadoop104之间需要互相设置,各机器对自己也要设置。
即hadoop102、hadoop103、hadoop104分别对hadoop102、hadoop103、hadoop104配置免密。为了方便拷贝我这里还在hadoop102上配置了root对103和104的免密。
[root@hadoop102 ~]$ ssh-keygen -t rsa #一路回车,生成密钥 [root@hadoop102 ~]$ ssh-copy-id hadoop103 #拷贝公钥到hadoop103上,会提示输入hadoop103的密码
操作完成后,在每台机器都能在hadoop用户时通过ssh hadoop10x进行免密互相登录。
四、准备安装包
创建安装包路径和应用安装目录
[root@hadoop102 ~]# mkdir /opt/{module,software} #在/opt目录下创建module、software目录 #将jdk-8u212-linux-x64.tar.gz、hadoop-3.1.3.tar.gz上传到software目录 [root@hadoop100 ~]# chown hadoop.hadoop /opt/{module,software} #修改 module、software 文件夹的所有者和所属组均为 hadoop 用户
卸载系统自带jdk
[root@hadoop102 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
以下操作皆使用应用用户hadoop进行操作
五、安装JDK
解压jdk安装包到/opt/module目录
[hadoop@hadoop102 ~]$ cd /opt/software/ [hadoop@hadoop102 software]$ ls jdk-8u212-linux-x64.tar.gz、hadoop-3.1.3.tar.gz [hadoop@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
会在module目录下生成一个jdk1.8.0_212的目录
[hadoop@hadoop102 software]$ cd ../module/ [hadoop@hadoop102 module]$ ll 总用量 0 drwxr-xr-x 7 hadoop hadoop 245 4月 2 2019 jdk1.8.0_212
配置JDK环境变量
[hadoop@hadoop102 ~]$ sudo echo "export JAVA_HOME=/opt/module/jdk1.8.0_212" >>/etc/profile [hadoop@hadoop102 ~]$ sudo echo "export PATH=$PATH:$JAVA_HOME/bin" >>/etc/profile [hadoop@hadoop102 ~]$ source /etc/profile
测试JDK安装是否成功
[hadoop@hadoop102 ~]$ java -version #如果看到以下结果表示Java安装成功 java version “1.8.0_212”
六、安装hadoop
解压hadoop安装包到/opt/module目录
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置hadoop环境变量
[hadoop@hadoop102 ~]$ sudo echo "export HADOOP_HOME=/opt/module/hadoop-3.1.3" >>/etc/profile [hadoop@hadoop102 ~]$ sudo echo "export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" >>/etc/profile [hadoop@hadoop102 ~]$ source /etc/profile
测试hadoop是否安装成功
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop version Hadoop 3.1.3
hadoop目录下的内容如下
[hadoop@hadoop102 hadoop-3.1.3]$ ll 总用量 180 drwxr-xr-x 2 hadoop hadoop 183 9月 12 2019 bin drwxrwxr-x 4 hadoop hadoop 37 11月 20 17:33 data drwxr-xr-x 3 hadoop hadoop 20 9月 12 2019 etc drwxr-xr-x 2 hadoop hadoop 106 9月 12 2019 include drwxr-xr-x 3 hadoop hadoop 20 9月 12 2019 lib drwxr-xr-x 4 hadoop hadoop 288 9月 12 2019 libexec -rw-rw-r-- 1 hadoop hadoop 147145 9月 4 2019 LICENSE.txt drwxrwxr-x 3 hadoop hadoop 4096 11月 21 14:54 logs -rw-rw-r-- 1 hadoop hadoop 21867 9月 4 2019 NOTICE.txt -rw-rw-r-- 1 hadoop hadoop 1366 9月 4 2019 README.txt drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 sbin drwxr-xr-x 4 hadoop hadoop 31 9月 12 2019 share
bin目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
data目录:存放hdfs数据文件,以及集群信息-------初始化之后才会有
etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
sbin目录:存放启动或停止Hadoop相关服务的脚本
share目录:存放Hadoop的依赖jar包、文档、和官方案例
logs目录:存放日志-----初始化之后才会有
七、hadoop集群配置
1、修改配置文件
修改配置文件的操作可以先在一台上进行,待一台机器全部修改完成后再将这些配置文件复制到另外两台机器上。
集群默认的配置文件有4个,core-default.xml、hdfs-default.xml、yarn-default.xml、mapred-default.xml,存放在hadoop-3.1.3/share/hadoop下
一般需要自定义这些配置文件,core-site.xml 、hdfs-site.xml 、yarn-site.xml 、mapred-site.xml,存放在$HADOOP_HOME/etc/hadoop下
除此之外还要修改$HADOOP_HOME/etc/hadoop下的workers和hadoop-env.sh两个文件

配置核心配置文件 core-site.xml,主要内容如下
<property> <!--指定NameNode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<property> <!--指定hadoop的数据存储目录-->
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property> <!--配置hdfs网页登录使用的静态用户-->
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
配置hdfs配置文件hdfs-site.xml,主要内容如下
<property> <!--NameNode的web访问地址-->
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<property> <!--secondary NameNode的web访问地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
配置yarn配置文件yarn-site.xml,主要内容如下
<property> <!--指定mr走shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <!--指定ResourceManager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<property> <!--环境变量的继承-->
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCHCHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property> <!--设置开启日志聚集功能--><!--最后3项开启日志聚集功能的相关配置-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property> <!--设置日志聚集服务器地址-->
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<property> <!--设置日志保留时间为7天-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置mapreduce配置文件mapred-site.xml,主要内容如下
<property> <!--指定MapReduce程序运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property> <!--历史服务器地址--><!--最后两项是为了能从yarn的web界面看到每个调度任务的history-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property> <!--历史服务器web端地址-->
<name>>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
修改hadoop-env.sh的JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
配置workers,有几个节点就填写几个节点的主机名,注意文件结尾不能有空格,也不能有空行。
[hadoop@hadoop102 hadoop]$ vi /opt/module/hadoop-3.1.3/etc/hadoop/workers #3台都要修改 hadoop102 hadoop103 hadoop104
然后将hadoop102上的6个配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、hdfs-env.sh、workers复制到103和104的对应目录下
2、初始化集群
如果集群是第一次启动,需要在 hadoop102 节点格式化NameNode(注意:格式化NameNode会产生新的集群id,如果集群在运行过程中报错需要重新格式化NameNode,一定要先停止namenode和datanode进程,并且要删除所有机器上的data和logs目录,然后再进行格式化,否则NameNode和DataNode的集群id不一致,集群找不到以往数据)
[hadoop@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
初始化完毕后,源路径就多了两个路径data合logs
集群信息存储路径:/opt/module/hadoop-3.1.3/data/dfs/name/current/version
数据文件存储路径:/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-970996834-192.168.85.102-1637399381695/current/finalized/subdir0/subdir0
3、启动集群
在hadoop102上启动dfs
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
在hadoop103上启动yarn
[hadoop@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
如果要关闭集群的话,需要先关闭yarn,在关闭hdfs。
在hadoop102上启动历史服务器
[hadoop@hadoop102 hadoop-3.1.3]$ bin/mapred --daemon start historyserver
jps查看各服务器的进程,与原来集群的规划一致
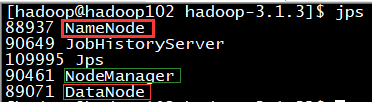
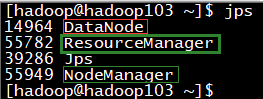
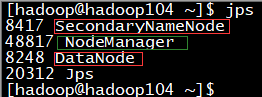
4、集群验证-web界面
Web 端查看HDFS相关信息,浏览器输入http://hadoop102:9870/
默认进入的Overview界面可查看整个hdfs基本信息,最常用的是Utilities-->Browse the file system,查看hdfs的文件及其结构。

Web 端查看YARN相关信息,浏览器输入http://hadoop103:8088
运行mapreduce程序后,如下红框位置会出现yarn上运行的job信息,点击右下方History,会跳转到具体的job信息界面,即历史服务器http://hadoop102:19888/,在该界面点击右下方logs,会显示job的详细日志。
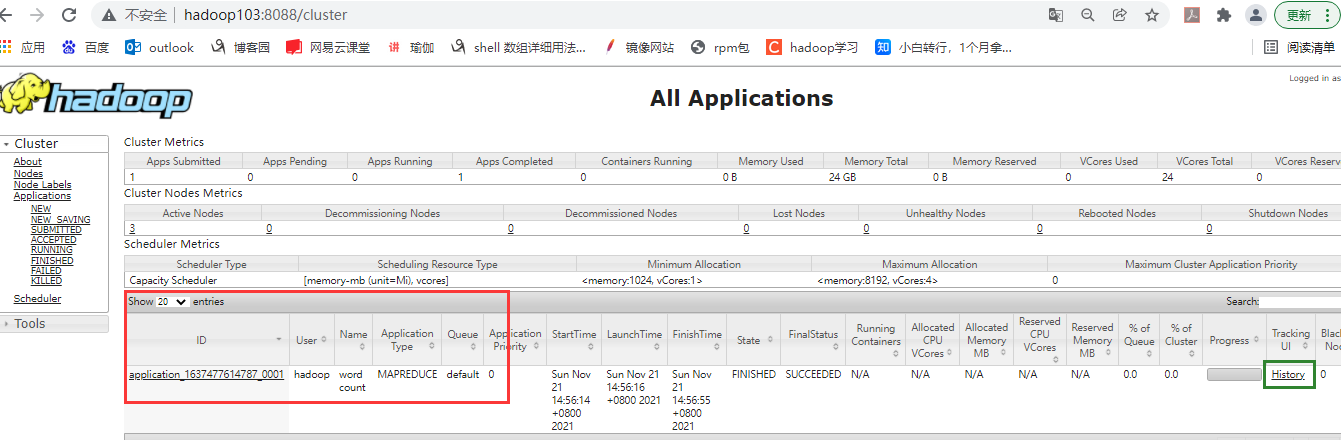
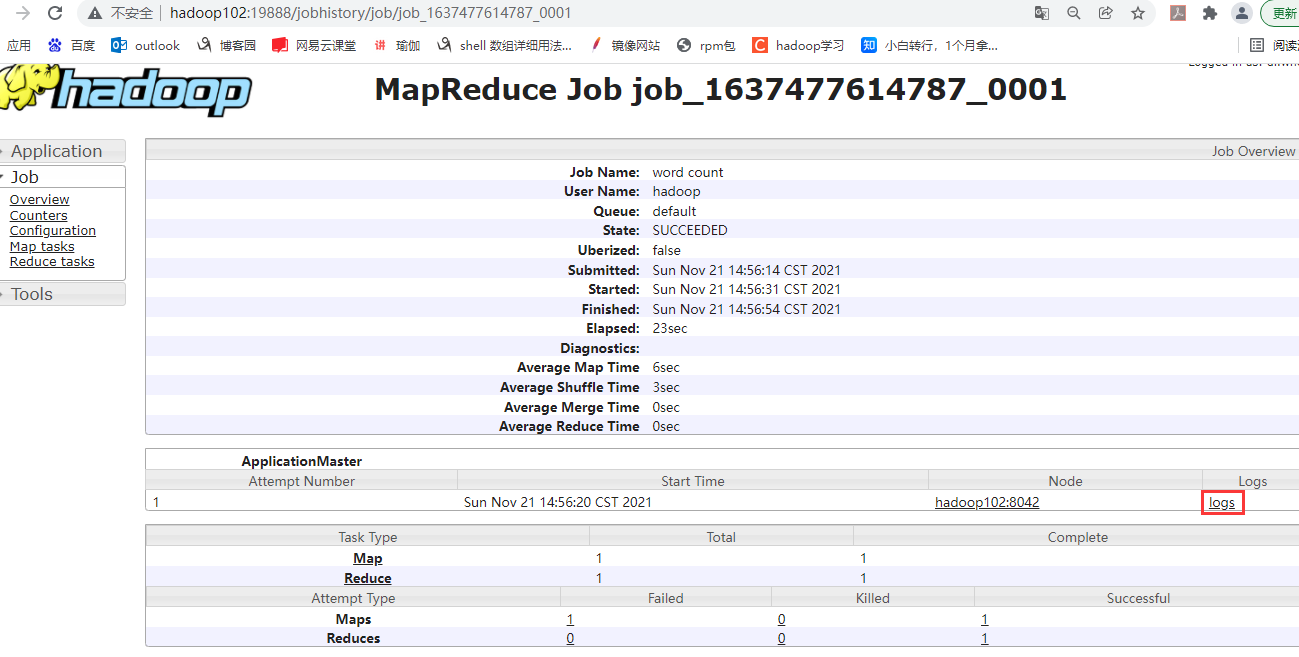
此处再来回顾一些配置文件
mapred-site.xml配置文件最后两项配置,是为了能从yarn的web界面通过History看到每个调度任务的历史,如果没有这2项配置,点界面的History不会有反应。
yarn-site.xml配置文件最后三项配置,是为了开启日志聚集功能并设置日志保留时间,如果没有这3项配置,点击Job页面的logs,会显示Aggregation is not enabled。
5、集群验证-运行mapreduce程序
hdfs的详细命令操作后续再细写,注意mapreduce的输出目录一定是不能存在的。
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input [hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /tmp/test.txt /input [hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input/test.txt /output/
总结:
格式化namenode:hdfs namenode -format
启动hdfs:sbin/start-dfs.sh 【hadoop102上】
启动yarn:sbin/start-yarn.sh 【hadoop103上】
关闭yarn:sbin/stop-yarn.sh 【hadoop103上】
关闭hdfs:sbin/stop-hdfs.sh 【hadoop102上】
启动历史服务:bin/mapred --daemon start historyserver 【hadoop102上】
上述操作是对整体集群进行的启停,还可以单独对某个机器上的服务进行启停
启动/停止hdfs服务:hdfs --daemon start/stop namenode/datanode/secorndarynamenode
启动/停止yarn服务:yarn --daemon start/stop resourcemanager/nodemanager

 浙公网安备 33010602011771号
浙公网安备 33010602011771号