seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图
一、散点图stripplot( ) 与swarmplot()
1.分类散点图stripplot( )
用法stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,jitter=True, dodge=False, orient=None,
color=None, palette=None,size=5, edgecolor="gray", linewidth=0, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- jitter 当点数据重合较多时用该参数做一些调整,可以设置为True或者间距0.1,否则会有重合的点
- dodge 如果有二次分类,二次分类是否拆分显示
tips = sns.load_dataset("tips") #导入系统数据 print(tips.head()) print(tips['day'].value_counts())


total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 Sat 87 Sun 76 Thur 62 Fri 19 Name: day, dtype: int64
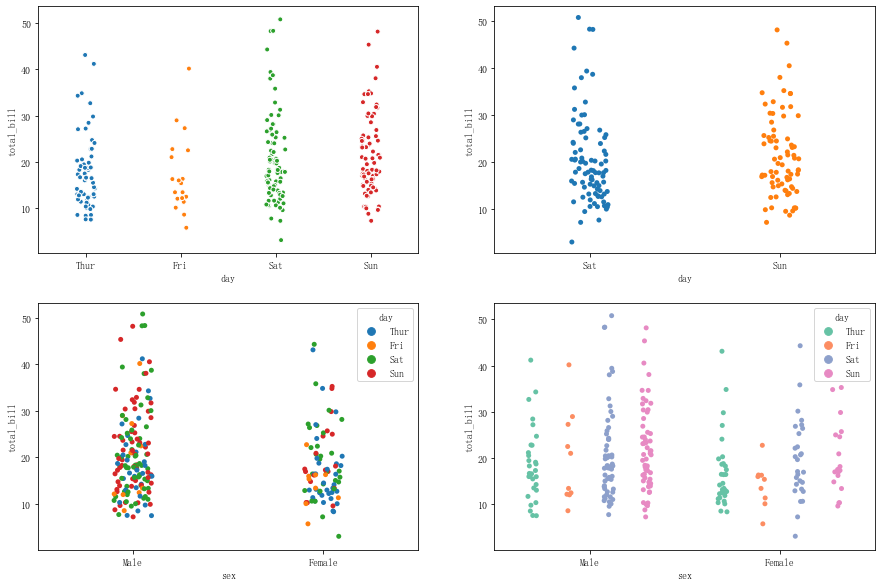
fig = plt.figure(figsize=(15,10)) ax1 = plt.subplot(221) # 对data数据按day分类,统计total_bill的分布,如果点重合较多适当显示开 sns.stripplot(x="day", y="total_bill", data=tips, jitter = True, size = 5, edgecolor = 'w',linewidth=1, marker = 'o', ax=ax1) ax2 = plt.subplot(222) # 对data数据按day分类,统计total_bill的分布,并且图表中只显示按day分类的中的Sat和Sun sns.stripplot(x="day", y="total_bill", data=tips,jitter = True, order = ['Sat','Sun'],ax=ax2) ax3 = plt.subplot(223) # 对data数据按sex分类后再按day分类,统计total_bill的分布 sns.stripplot(x="sex", y="total_bill", hue="day",data=tips, jitter=True,ax = ax3) ax4 = plt.subplot(224) # 对data数据按sex分类后再按day分类,统计total_bill的分布,并且不同的day拆分显示 sns.stripplot(x="sex", y="total_bill", hue="day",data=tips, jitter=True,palette="Set2",dodge=True,ax=ax4)
2.分簇散点图swarmplot()
用法swarmplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,dodge=False, orient=None, color=None,
palette=None,size=5, edgecolor="gray", linewidth=0, ax=None, **kwargs)
swarmplot()除了没有jitter参数,其他用法类似stripplot()。
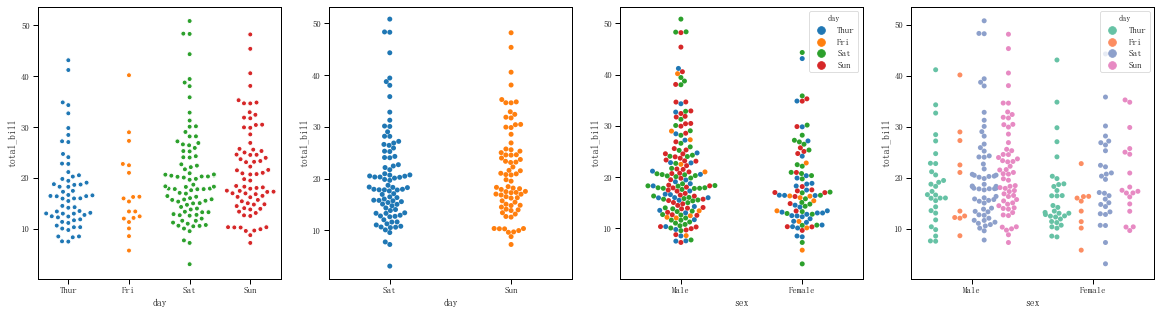
fig = plt.figure(figsize=(20,5)) ax1 = plt.subplot(141) # 对data数据按day分类,统计total_bill的分布,如果点重合较多适当显示开 sns.swarmplot(x="day", y="total_bill", data=tips, size = 5, edgecolor = 'w',linewidth=1, marker = 'o', ax=ax1) ax2 = plt.subplot(142) # 对data数据按day分类,统计total_bill的分布,并且图表中只显示按day分类的中的Sat和Sun sns.swarmplot(x="day", y="total_bill", data=tips, order = ['Sat','Sun'],ax=ax2) ax3 = plt.subplot(143) # 对data数据按sex分类后再按day分类,统计total_bill的分布 sns.swarmplot(x="sex", y="total_bill", hue="day",data=tips, ax = ax3) ax4 = plt.subplot(144) # 对data数据按sex分类后再按day分类,统计total_bill的分布,并且不同的day拆分显示 sns.swarmplot(x="sex", y="total_bill", hue="day",data=tips, palette="Set2",dodge=True,ax=ax4)
二、箱型图boxplot()
boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None, palette=None,
saturation=.75,width=.8, dodge=True, fliersize=5, linewidth=None,whis=1.5, notch=False, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类是否拆分显示
- width 箱的间隔的比例,值越大间隔越小
- filtersize 异常点大小
- whis 设置IQR
- notch 是否以中值做凹槽
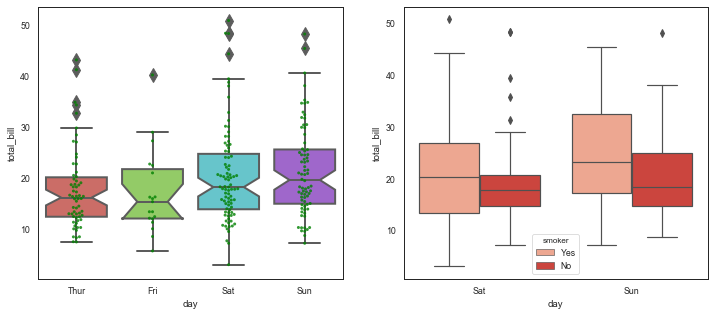
fig = plt.figure(figsize=(12,5)) ax1 = plt.subplot(121) sns.boxplot(x="day", y="total_bill", data=tips,linewidth = 2, width = 0.8, fliersize = 10, palette = 'hls',whis = 1.5,notch = True) sns.swarmplot(x="day", y="total_bill", data=tips, color ='g', size = 3, alpha = 0.8) #在箱型图上做分簇散点图 ax2 = plt.subplot(122) sns.boxplot(x="day", y="total_bill", data=tips, hue = 'smoker', order = ['Sat','Sun'],palette = 'Reds') #根据day分类,再根据smkker分类
三、小提琴图violinplot()
violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,bw="scott", cut=2,
scale="area", scale_hue=True, gridsize=100, width=.8, inner="box", split=False, dodge=True,
orient=None,linewidth=None, color=None, palette=None, saturation=.75,ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个小提琴位置是否错开,默认为True,False则多个小提琴会重复 (dodge=True与split=False效果相同)
- split 如果有二次分类,二次分类是否拆分整个提琴,默认为False显示为多个独立的小提琴,True则显示为一个小提琴,左右两侧表示二次分类
- scale = 'area' 设置小提琴图的宽度,area-保持小提琴面积相同,count-按照样本数量决定宽度,width-宽度一样
- gridsize = 100 设置小提琴图边线的平滑度,越高越平滑
- inner = 'box' 设置内部显示类型 → “box”箱型图, “quartile”分位数, “point”点, “stick”, None
- bw = 0.8 # 控制拟合程度,'scott'、'silverman'或者一个浮点数,一般可以不设置
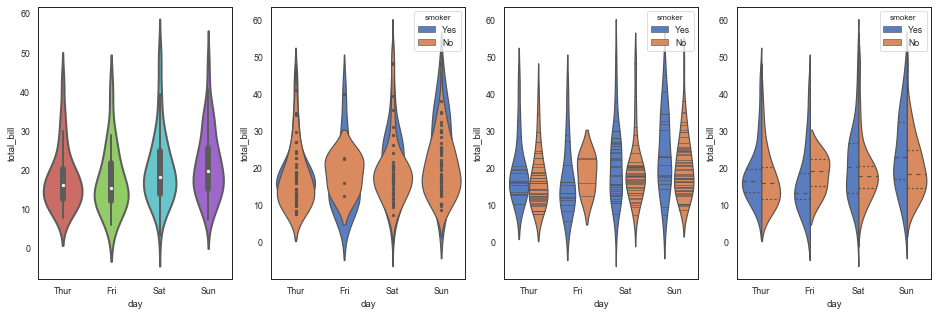
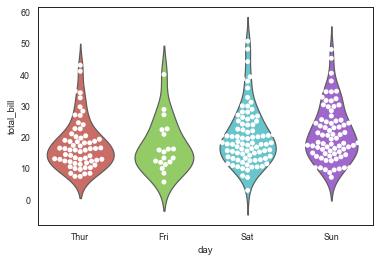
fig = plt.figure(figsize=(20,5)) ax1 = plt.subplot(141) sns.violinplot(x="day",y="total_bill",data=tips,linewidth=2,width=0.8,palette='hls',scale= 'area',gridsize=50,inner='box') ax2 = plt.subplot(142) sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",dodge=False,inner="point")#二次分类小提琴位置不错开 ax3 = plt.subplot(143) sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",split=False,inner="stick")#二次分类不拆分小提琴,显示为多个独立小提琴 ax4 = plt.subplot(144) sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",split=True,inner="quartile")#二次分类拆分小提琴,左右两侧分别表示二次
小提琴图与分簇散点图结合sns.violinplot()+ sns.swarmplot()
sns.violinplot(x="day", y="total_bill", data=tips, palette = 'hls',alpha=0.5, inner = None) sns.swarmplot(x="day", y="total_bill", data=tips, color="w")
四、增强箱图boxenplot()
boxenplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None,
palette=None, saturation=.75,width=.8,dodge=True, k_depth='proportion', linewidth=None,
scale='exponential', outlier_prop=None, ax=None, **kwargs)
(lv图表使用boxenplot(),lvplot()即将被遗弃)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个小提琴位置是否错开,默认为True,False则多个小提琴会重复 (dodge=True与split=False效果相同)
- scale = 'area' 设置lv图的宽度,“linear”、“exonential”、“area” (一般scale和k_depth保持默认就好)
- k_depth = 'proportion', # 设置框的数量 → “proportion”、“tukey”、“trustworthy”
- width 箱之间间隔
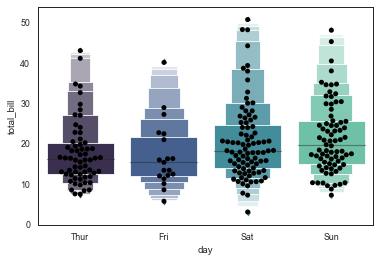
sns.lvplot(x="day", y="total_bill", data=tips, palette="mako", width = 0.8, scale = 'area',k_depth = 'proportion') sns.swarmplot(x="day", y="total_bill", data=tips, color ='k',size = 5)
五、柱状图barplot()
seaborn中的柱状图不是单纯的表示数量,而是表示了一个统计标准和对应的置信区间。
barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,estimator=np.mean, ci=95,
n_boot=1000, units=None,orient=None, color=None, palette=None, saturation=.75,errcolor=".26",
errwidth=None, capsize=None, dodge=True,ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- estimater 柱状图表示的统计量,默认和常使用均值
- ci 置信区间的误差,0-100之内、或sd标准差,或None,默认为95
- saturation 颜色饱和度
- errcolor与errwidth 误差线颜色与宽度
- capsize 误差线延长宽度
- dodge 如果有二次分类,二次分类的多个多个柱状图位置是否错开
- edgecolor 柱子的边框颜色
#导入泰坦尼克号、小费和汽车事故的3个表的数据结构,在不同窗口显示前5行 titanic = sns.load_dataset("titanic") titanic.head() tips = sns.load_dataset('tips') # tips.head() crashes = sns.load_dataset("car_crashes")# crashes.head()

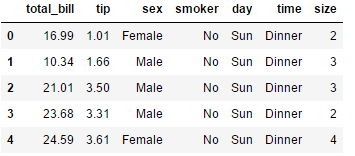
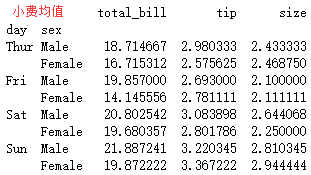
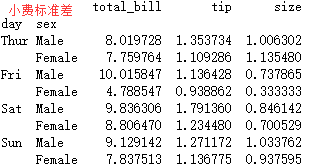
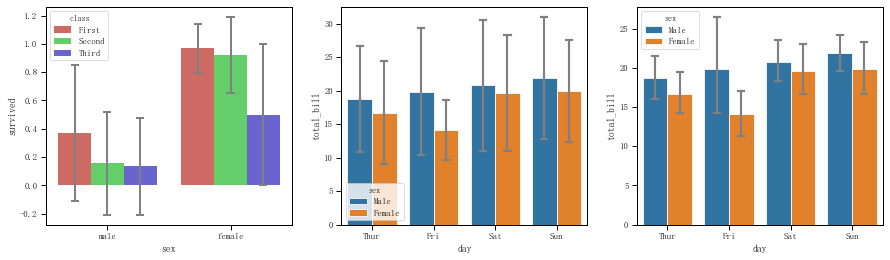
fig = plt.figure(figsize=(15,4)) ax1 = plt.subplot(131) #泰坦尼克,在性别分类的基础上再按舱级别分类,统计生还率 sns.barplot(x="sex",y="survived",hue="class",data=titanic,palette = 'hls',capsize = 0.05,saturation=.8,errcolor = 'gray',errwidth = 2,ci = 'sd') ax2 = plt.subplot(132) #小费,在日期分类的基础上再按性别分类,统计给的小费,置信区间的误差为标准差 sns.barplot(x="day", y="total_bill", hue="sex", data=tips,edgecolor = 'white',errcolor='gray',capsize=0.1,ci='sd') ax3 = plt.subplot(133) #小费,同上,置信区间的误差为默认的95 sns.barplot(x="day", y="total_bill", hue="sex", data=tips,edgecolor = 'white',errcolor='gray',capsize=0.1)
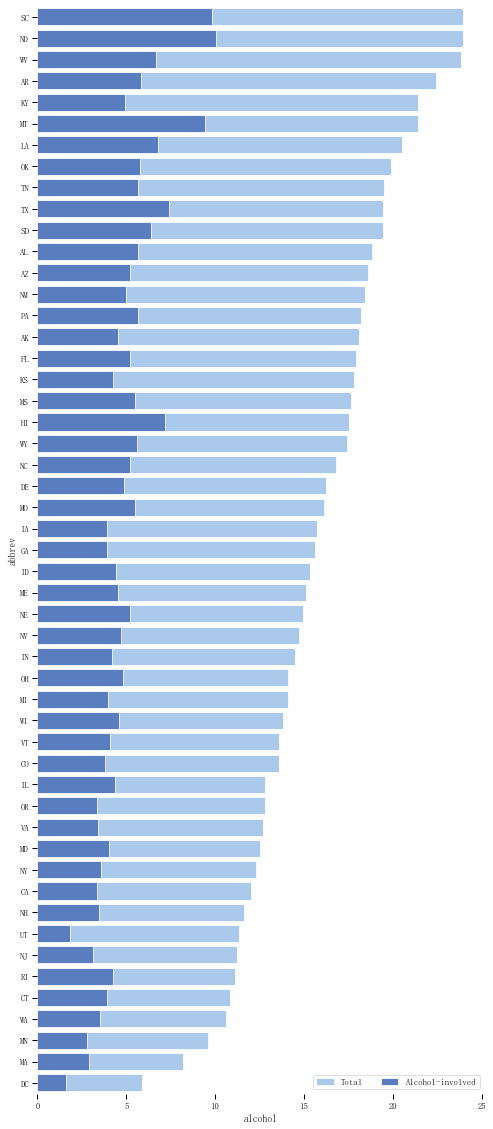
crashes = sns.load_dataset("car_crashes").sort_values("total", ascending=False) f,ax = plt.subplots(figsize=(8, 20))# 创建图表 sns.set_color_codes("pastel") sns.barplot(x="total", y="abbrev", data=crashes,label="Total", color='b',edgecolor = 'w')# 设置第一个柱状图 sns.set_color_codes("muted") sns.barplot(x="alcohol", y="abbrev", data=crashes, label="Alcohol-involved",color='b',edgecolor = 'w')# 设置第二个柱状图 ax.legend(ncol=2, loc="lower right") sns.despine(left=True, bottom=True)
六、计数柱状图countplot()
countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None,
palette=None, saturation=.75,dodge=True, ax=None, **kwargs)
- x,y 同时表示分类字段和显示方向,即在x轴上或在y轴上对指定的字段进行计数显示
- hue 在x分类或者y分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个多个柱状图位置是否错开
- edgecolor 柱子的边框颜色
fig = plt.figure(figsize=(12,4)) ax1 = plt.subplot(121) sns.countplot(x="day", hue="sex", data=tips, palette = 'muted') #竖直显示,在日期分类的基础上再按性别分类 ax2 = plt.subplot(122) sns.countplot(y="day", hue="sex", data=tips, palette = 'muted') #水平显示
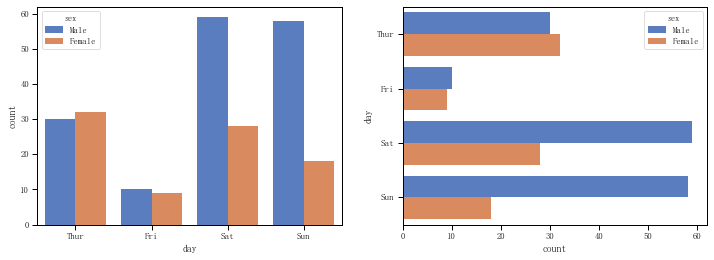
七、折线图pointbar()
折线图pointbar()和barplot()的用法类似,只是barplot()用柱状图表示均值,而pointbar()用一个点表示了均值。
pointplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,estimator=np.mean, ci=95,
n_boot=1000, units=None,markers="o", linestyles="-", dodge=False, join=True, scale=1,
orient=None, color=None, palette=None, errwidth=None,capsize=None, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- estimater 柱状图表示的统计量,默认和常使用均值
- ci 置信区间的误差,0-100之内、或sd标准差,或None,默认为95
- marker 均值的表示形式
- errwidth 误差线颜色与宽度
- capsize 误差线延长宽度
- dodge 如果有二次分类,二次分类的多个线是否分开
- joint 是否连线
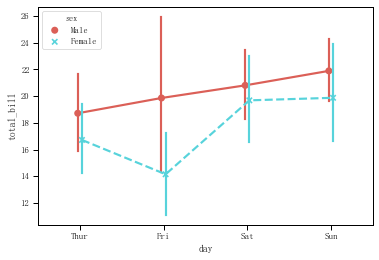
sns.pointplot(x="day",y="total_bill",hue = 'sex',data=tips,palette = 'hls',dodge = True,join = True,markers=["o", "x"],linestyles=["-", "--"]) tips.groupby(['day','sex']).mean()['total_bill']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号