认识实习——但是动态规划
动态规划
很有价值的博客:幺零做点正事吧-动态规划与贪心算法的区别和联系
Diluc and Kaeya(迪卢克和凯亚?)
先放一个自己想的比较朴素的想法,因为是归类在DP中,试着抽象了一下,表示了一下状态:
#include<iostream>
#include<string.h>
#include<string>
using namespace std;
const int MAX_NUM=10000;
struct woods{
int D=0;
int K=0;
double ratios;
int MAX_=0;
};
int main(){
int n,m;
string str;
scanf("%d",&n);
for(int i=0;i<n;i++){
if(i)
printf("\n");
scanf("%d",&m);
cin.get(); //帮getline函数过滤换行
woods *wd=new woods[m+1];
getline(cin,str);
for(int j=1;j<=m;j++){
switch(str[j-1]){
case 'D':{
wd[j].D=wd[j-1].D+1;
wd[j].K=wd[j-1].K;
break;
}
case 'K':{
wd[j].K=wd[j-1].K+1;
wd[j].D=wd[j-1].D;
}
}
}
for(int j=1;j<=m;j++){
// printf("\nj=%d ,jd=%d ,jk=%d ",j,wd[j].D,wd[j].K);
for(int p=0;p<j;p++){ //O(n^2)的复杂度
if(p==0) {
wd[j].MAX_=1;
if(wd[j].D==0) wd[j].ratios=0;
else
if(wd[j].K==0) wd[j].ratios=-1;
else
wd[j].ratios=double(wd[j].D)/wd[j].K;
continue;
}
int j_d=wd[j].D-wd[p].D,j_k=wd[j].K-wd[p].K;
// printf(" =>p=%d %d,%d ",p,j_d,j_k);
double ratios;
if(j_d==0) ratios=0; //计算比例,分子分母为0的情况分开表示
else
if(j_k==0) ratios=-1;
else
ratios=double(j_d)/j_k;
if(ratios==wd[p].ratios){
if(wd[p].MAX_+1>wd[j].MAX_){
// printf(" !! %f<->%f ",ratios,wd[p].ratios);
wd[j].MAX_=wd[p].MAX_+1; //状态转移
wd[j].ratios=ratios;
}
}
}
}
for(int j=1;j<=m;j++){
if(j>1) printf(" ");
printf("%d",wd[j].MAX_);
}
delete []wd;
}
return 0;
}
但实际上这种写法不是最好的,时间复杂度可以降到O(n)



不知道为什么CF上跑出来的结果和本地的结果不一样= =。这是一道假DP,看了网上的题解几乎都用不上DP。自己的思路基本能行,但是复杂度高了,标准解法如下:
#include <stdio.h>
#include <string>
#include <map>
#include <utility>
#include <iostream>
using namespace std;
int main(){
int n,m;
string str;
scanf("%d",&n);
while(n--){
map<pair<double,double>,int> mAp; //用来存储对应比值的出现次数
scanf("%d",&m);
cin.get();
getline(cin,str);
double d=0,k=0;
pair<double,double> pr; //注意这一片变量都是double类型,否则运算会出现问题
for(int i=0;i<m;i++){
switch(str[i]){
case 'D':{
d++;
if(k==0){ //0的特殊情况判定
pr.first=1;
pr.second=0;
mAp[pr]++;
} else {
pr.first=d/(d+k); //取比值,效果和取最大公约数做分母是一样的,只是储值变成了double类型
pr.second=k/(d+k); //相当于一种哈希重排序
mAp[pr]++; //计数加一
}
break;
}
case 'K':{
k++;
if(d==0){
pr.first=0;
pr.second=1;
mAp[pr]++;
} else {
pr.first=d/(d+k);
pr.second=k/(d+k);
mAp[pr]++;
}
}
}
if(i) printf(" ");
printf("%d",mAp[pr]); //本次的的比值对应的次数就是本位置可分的最大份数
} //正是这种单次遍历即可全部计数的特性使得时间复杂度能够优化为O(n)
printf("\n");
}
return 0;
}
使用 pair 需要包含文件头 utility ,使用 map 需要包含头文件 map 。

反转了,跑出来结果有问题是因为编译器版本不对,加上我用了动态数组..不过这段程序超时了,毕竟是O(n^2)的复杂度= =
参考:[
]
The Sports Festival
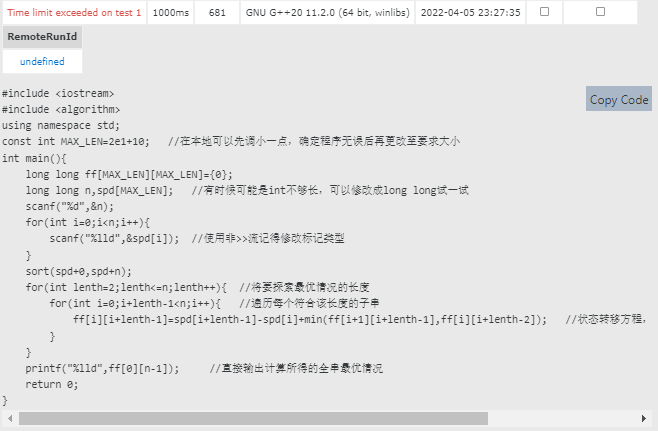
想了一下没什么很好的思路,又急着交作业,直接看题解,发现是正经DP:
#include <iostream>
#include <algorithm>
using namespace std;
const int MAX_LEN=2e3+10; //在本地可以先调小一点,确定程序无误后再更改至要求大小。 <?-1
int main(){
long long s[MAX_LEN][MAX_LEN]={0};
long long n,a[MAX_LEN]; //有时候可能是int不够长,可以修改成long long试一试
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%lld",&a[i]); //使用非>>流记得修改标记类型
}
sort(a+0,a+n); //sort(a+n1,a+n2)表示从小到大排序a数组下标范围为[n1,n2)的所有元素
for(int lenth=2;lenth<=n;lenth++){ //将要探索最优情况的长度
for(int i=0;i+lenth-1<n;i++){ //遍历每个符合该长度的子串
int j=i+lenth-1;
s[i][j]=a[j]-a[i]+min(s[i+1][j],s[i][j-1]); //状态转移方程
}
}
printf("%lld",s[0][n-1]); //直接输出计算所得的全串最优情况
return 0;
}
<?-1这里有个奇怪的问题,当MAX_LEN的值小于30(不准确数字)时裁判机上会在第一组测试数据超时,而本地不会,没搞明白这是为什么
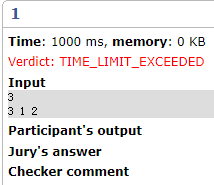
剖析一下这道DP的思路:
先将题目理清楚,给定n个运动员的速度分别为a1,a2,a3...an,将速度重新排列后,定义di=max(a1,a2...ai)-min(a1,a2...ai),si=sum(d1,d2..di)。
首先每道DP都可以抽象出一个状态,利用状态转移方程将上一个最优状态转化成下一个最优状态。先观察本题,如果我们定义在所有的a中,最大的差值为dmax,那么dn=dn-1 + dmax,道理很简单,如果在前面就出现dmax,那最终结果一定不是最小的,所以它一定是出现在最后面的。我们可以先将运动员按照速度排序,选择的时候为了让速度差之和最小,一定会选择邻近的值,比如有一个排序过的子串:a1,a2,a3,a4,a5。我们第一个选择了a3,那下一个肯定是选择a2,或者a4,假如我们选择了a2,那下一个就在a1与a4中选,会发现添加的元素总是位于两侧,这是因为他们的值与a3相差是最小的。于是我们就可以利用选择的个数,也就是子串的长度 i 来标记状态,而每一个状态的值是选择该子串所得的si。那么状态转移方式就是由si-1得到si。见代码中的状态转移方程:
int j=i+lenth-1;
s[i][j]=a[j]-a[i]+min(s[i+1][j],s[i][j-1]);
s[i][i+lenth-1] 代表的是下标从 i 到 i+lenth-1 的子串,取尾下标为 j=i+lenth-1 ,长度为 lenth ,其值是选取该子串所得的最小的 s 。它是由长度为Lenth-1的子串加上一个元素得来的,前面分析过,添加的元素总是位于两侧,所以该子串是从子串 [i+1,j] 或者 [i,j-1] 变来的,而这个变化过程所加的值是一个定值,即最大减最小: a[j]-a[i] ,所以只要前一个子串的 s 最小,那么该子串的 s就是最小的,这就是方程里 min() 的意义所在:选出掐头的子串和去尾的子串中 s 最小的。这样就实现了DP的一个重要目的:由前一个最优状态转移到后一个最优状态。
for(int lenth=2;lenth<=n;lenth++){ //将要探索最优情况的长度
for(int i=0;i+lenth-1<n;i++){ //遍历每个符合该长度的子串
int j=i+lenth-1;
s[i][j]=a[j]-a[i]+min(s[i+1][j],s[i][j-1]); //状态转移方程
}
}
虽然确定了得到si+1最优状态的办法,但是同样长度的子串之间是平行关系,彼此之间还需要比较,所以我们依次遍历长度为2,3,4...n的子串,从左往右将每一个该长度的子串的最优si确定,再将长度加一,由最优的si得到最优的si+1,从而就实现了完整的状态转移,确保最后得到的sn是全局的最优情况。
参考:[
]
Say No to Palindromes
受到前一题的影响一直在思考如何利用长度转移状态,几经尝试后发现不行,实在感觉没思路,就去看了题解,结果发现思考的很朴素,完全是在就事论事,限定字母只有"a"、"b"、"c",三种,要想不出现回文,加入第一个是a,那么第二个可以是b也可以是c,假如第二个是b,那么第三个只能是c,第四个只能是a,第五个只能是b,第六个只能是c....发现了吗,"abc"在不断循环,总结一下:
abc
acb
bca
bac
cab
cba
只有这六个是可能出现的循环节,那我们只要依次按照这六个修改并计算所需次数就行了。但是这里还没完,每给出一个子串就重新算一遍太麻烦了,也浪费时间,有没有省事也省时一点的办法?有,利用前缀和。也就是记录前n个子串所需修改次数为 dp[n] ,那么子串 i to j 的所需修改次数就为dp[j]-dp[i] ,这个是可以证明的,想明白也不难,某种意义上来说,这才是这道题唯一体现DP思想的地方...因为这个问题的解决核心完全是就事论事,而非利用DP的某些特性去构造一些结构,所以对于一些想偷懒的人(比如我),想找到一般规律轻松解决的人,这题目就突出一个一筹莫展。(其实只是菜= =) 前缀和帮我们大大优化了时间,我们只需分别存储六种情况的修改次数的前缀和,按区间得出各种情况的值再进行比较并取最小即可,时间复杂度甚至只有O(n),快的不可思议...
若是抛开具体事实不谈(啊对对对),这个不让出现回文的规定用长度组合转化很难解决,因为你无法保证修改某个子串的同时不影响到其他子串,更无法保证不出现新的回文子串,而若是一个个尝试...那我不敢想。这题目也体现了一点:DP不是解决问题的主要思路,他是一个优化时间的手段。如何处理回文不是由DP解决的,在有办法处理回文的情况下,通过DP思路保存子问题的解(前缀和)达到空间换时间的目的,这才是DP思想在这题中的作用。而单考虑如何修改字符串使之没有回文子串更像是一个搜索题目...虽然搜索也不好解决就是了。可以看出DP的一大特点就是题目的解决思路是很灵活的,需要各种经验与分析,这也许是因为DP扮演的角色更多是锦上添花,而非雪中送炭,做DP题是在解决各种技巧性的问题,而DP是规划这些技巧使他们快速有序的手段,两者都需要脑子,但不能只有其一。
放了这么多P话,上代码:
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main(){
string s[6]={"abc","acb","bac","bca","cab","cba"}, str;
int a,b;
cin>>a>>b;
cin>>str;
str=" "+str; //输入区间时是从1开始计数的,所以处理数组时尽量从1开始
int k=str.length();
vector< vector<int> > dp(6,vector<int>(k));
for(int i=0;i<6;i++){
for(int j=1;j<k;j++){
if(str[j]==s[i][j%3]){
dp[i][j]=dp[i][j-1]; //不需要更改
}
else{
dp[i][j]=dp[i][j-1]+1; //需要更改
}
}
}
long long k1,k2,ans;
while(b--){
ans=2e6;
cin>>k1>>k2;
for(int i=0;i<6;i++){
// cout<<"i="<<i<<",dp="<<dp[]
ans=min(ans,(long long)(dp[i][k2]-dp[i][k1-1])); //<!-1
/* min函数模板中两个参数的类型必须一致,否则无法正常初始化 */
}
cout<<ans<<endl;
}
return 0;
}
<!-1这里注意左边界要在给出的基础上减一,道理很简单,但是容易忽略,前缀和是计算到当前下标的结果,直接相减给出的下标范围,被减的下标本身的部分是会被减去的,而我们想要的区间时算上这部分的。
参考:[
]
Increase Subarray Sums
思考了一番自己的思路,觉得不太好,就去看了题解,一开始对题解的做法又惊讶又疑惑,惊讶是因为它将前缀和的一维进程按照K的变化拓展到了多维,疑惑是因为我很好奇一些比较有特点的情况在具体实现时的进程,简单推演后觉得没问题,编写代码成功AC,时间复杂度是O(n^2),先放网上的题解代码:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
int t;
cin>>t;
while(t--){
int n,x,tmp;
cin>>n>>x;
vector< vector<int> > dp(n+1,vector<int>(n+1)); //规模为n*n
vector<int> s(n+1),ans(n+1); //已确定规模下方切忌用push_back
for(int i=1;i<=n;i++){
cin>>tmp;
s[i]=tmp;
}
for(int i=1;i<=n;i++){
// cout<<"then:";
dp[i][0]=max(dp[i-1][0],0)+s[i];
ans[0]=max(ans[0],dp[i][0]);
// cout<<dp[i][0]<<" ";
for(int j=1;j<=n;j++){ //<!-1
int v1=max(dp[i-1][j],0)+s[i];
int v2=max(dp[i-1][j-1],0)+s[i]+x;
dp[i][j]=max(v1,v2); //<!-2
// cout<<dp[i][j]<<" ";
ans[j]=max(ans[j],dp[i][j]);
}
// cout<<endl;
}
for(int i=0;i<=n;i++){
cout<<ans[i]<<" ";
}
cout<<endl;
}
}
<!-1这是一个让人惊讶的点,直接在一个次序大循环下把多个K的情况都解决了,让我意识到它的实现只依赖前面而不依赖后面,我的直观思路是K为大循环,次序多走两轮,这两者的时间复杂度是一致的,但是推进的大方向是横纵之差,事实上横纵都可以实现。<!-2状态方程更是让人惊叹,如果以这个方程为核心,那这道题的解决思路确实是在DP核心思想的引导下能想到,也就是它的方法确实来自于DP,而不是"就事论事+DP省时"的思路。此处v2改成v2=max(dp[i][j-1])应该也是完全可行的,留意到它的DP数组值可以为负,在计算下一个DP数组的值时才会去负为零,这里虽没有实际作用,但和存储中直接去负为零的思路在效果上是有细节的不同的。严格来说这里也是遍历了截取某段子串、不同数量的K加在不同位置的所有情况,但是进行了比较从而获得局部最优的一个解,这也是为什么我一开始认为是纵轴推移。但我一开始确实没想到DP方程可以写的这么贴切直观,两维直接取两个变量,这其中的原因是这个DP方程保证了局部的比较能产生局部的最优,而我想不到有类似效果的思路。例如说这里的状态推移是:MAX( DP[i-1][j],DP[i-1][j-1] ) => DP[i][j],前置的两元间的比较既方便遍历又保证合理有效的优化,同时还没有遗漏一些极为特殊的情况,我感觉这是非常厉害的。
再琢磨了一下自己的思路:
- 先跑一遍前缀和,不做dp优化,单纯求和,获得一个数组,区间的和可以用下标之差取得,然后先开一个循环遍历不同的k,再开两重循环遍历所有子串,长度
len<=k则加上x*len,len>=k则加上k*x,最后是能得到最优解的,但是时间复杂度为O(n^3),大概率超时 - 先跑一遍DP优化的前缀和,求出
k=0时的最大值,并记录该最大值的子串长度len,然后依次遍历不同的k,若k<=len那么直接加上x*k,若k>=len则依次遍历长度l=len+1,len+2...k的子串,加上相应的值后求出最大值,显然这个时间复杂度也是O(n^3),不合格
参考:[
]
Just Eat It!
好简单的前缀合,但是有细节问题。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
int t,n,l,max_l,max_r;
cin>>t;
while(t--){
cin>>n;
long long s=0,ss=0,dp=0;
vector<long long> tmp(n);
for(int i=0;i<n;i++){
cin>>tmp[i];
s+=tmp[i];
if(dp<=0) l=i;
dp=max(dp,(long long)0)+tmp[i];
if(dp>ss){
max_l=l;
max_r=i;
}
ss=max(ss,dp);
}
if(max_l==0 && max_r==n-1){ //检测最佳子串是不是全串 <!-1
ss-=(tmp[0]<tmp[n-1])?tmp[0]:tmp[n-1]; //若是全串就去掉一个最小的
}
if(ss>=s) cout<<"NO"<<endl;
else cout<<"YES"<<endl;
}
return 0;
}
不知道是最近脑子动太多了还是太少了,思考这个 l r max_l max_r 让我头疼不已...但这题核心思路还是很简单的,就是前缀和求最大子串,只不过多了几步比较与处理。
<!-1这里很重要的一点是Adel不能选择全串,因此最佳子串要排除全串这个可能,因此要标记最佳子串的头和尾,这里我脑子不太好使想了好久,但其实不算复杂,检测时若dp归零则重置左端点l,每次更新最大值时同步max_l=l,而右端点直接取当前位置max_r=r,单独定义一个r的意义不大。最后检查一遍是否为头尾即可。最后注意一下题目要求是严格大于才会输出"YES"
总结
DP好难(呜呜呜呜),这次是认识实习的作业驱使才来写DP,结果发现DP都是神仙题目,不看题解都找不到最佳思路,而最简单的题目放在了最后...总之加油吧!学习算法还是很重要的,DP虽然难,但是很锻炼也很考验思维能力,它的题目很灵活,像在做数学题,甚至比数学题还要灵活。自我感觉DP分两类,一类核心思路与DP无关,DP只提供优化时间的办法;一类核心思路向着DP考虑,由DP的特点来创建模型解决问题。
Tip:补充一下认识实习PPT制作的一些收获
- 不突兀的橙黄色:(230,187,122)
- 舒服的文字藏青:(14,64,90)
- 推荐的字体大小24+,PPT上放关键字就行,废话用嘴(开局一段话,内容全靠编!)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号